

{kind=link}
[ad_1]
It is that point of yr once more: Studies on the state of AI for 2021 are out. A couple of days again, it was the Machine studying, Synthetic Intelligence and Information report by Matt Turck, that ZDNet Large on Information colleague Tony Baer coated. This week, it is the State of AI 2021 report, by Nathan Benaich and Ian Hogarth.
After releasing what most likely was essentially the most complete report on the State of AI in 2020, Air Road Capital and RAAIS founder Nathan Benaich and AI angel investor and UCL IIPP visiting professor Ian Hogarth are again for extra.
In what’s turning into a valued yearly custom, we caught up with Benaich and Hogarth to debate subjects that stood out for us within the report.
MLOps, machine studying in manufacturing
First off, there’s overlap with the subjects that Turck coated and Baer reported on, and for good cause. As Baer identified, the wave of IPOs and proliferation of unicorns is popping this market into its personal sector, and that’s not possible to disregard. For an outline of market developments, we encourage readers to take a look at Baer’s protection.
That stated, our feeling is that the State of AI 2021 report covers extra subjects: the most recent developments in AI analysis, {industry}, expertise, and politics, whereas it additionally ventures on predictions. Actually, Benaich and Hogarth maintain monitor of their predictions, and they’re doing fairly effectively. For instance, in 2020 they accurately predicted the obstacles in Arm’s acquisition by Nvidia, and AI and biotech-related IPOs.
As Benaich famous, by advantage of being traders at completely different principally early levels machine studying corporations, they’ve entry to main AI labs, tutorial teams, up and coming startups, larger corporations, in addition to individuals who work in authorities. So that they attempt to synthesize all these completely different angles in a public good product that’s open supply and goals to holistically inform all stakeholders.
We picked some overarching themes that stood out for us within the report, as we now have additionally recognized them all year long. The primary one is MLOps — the artwork and science of bringing machine studying to manufacturing. In operationalizing AI, the emphasis is shifting from shiny new fashions to maybe extra mundane, however sensible elements.

With the growing energy and availability of machine studying fashions, positive factors from mannequin enhancements have change into marginal. On this context, the machine studying neighborhood is rising more and more conscious of the significance of higher knowledge practices, and extra typically higher MLOps, to construct dependable machine studying merchandise.
Hazy Analysis, Stanford
With the growing energy and availability of machine studying fashions, positive factors from mannequin enhancements have change into marginal. On this context, the machine studying neighborhood is rising more and more conscious of the significance of higher knowledge practices, and extra typically higher MLOps, to construct dependable machine studying merchandise.
Benaich famous that they thought it necessary to focus on renewed consideration in additional {industry} minded tutorial work round knowledge high quality and varied points that may reside inside knowledge that in the end propagate in the direction of ML fashions, figuring out whether or not fashions predicts effectively or not:
“A whole lot of academia was centered on competing on static benchmarks, displaying mannequin efficiency offline on these benchmarks, after which transferring into {industry}. So technology one was rather a lot about — let’s simply get a mannequin that works for a particular downside, after which take care of any points or any adjustments each time they occur.
There’s been an enormous amount of cash and curiosity and engineering time that is been thrown into MLOps. And that is motivated by the concept machine studying will not be like a static software program product which you could write as soon as and overlook about. You need to continuously replace it, and it is not simply [about] updating the mannequin.
You need to have a look at how your lessons would possibly drift over time, or when you’re nonetheless utilizing the suitable benchmarks to find out whether or not a brand new mannequin that you simply educated goes to work in manufacturing or not. You may even see points like selecting completely different random seeds in your mannequin after which seeing utterly completely different habits on actual world knowledge, and even that knowledge that you have been utilizing is rubbish”.
That sounds intuitively proper, and possibly resonates with anybody who has labored with machine studying fashions and knowledge pipelines. Now persons are giving names to that phenomena, similar to distribution shifts (mismatches in dataset variations) and knowledge cascades (points with knowledge influencing downstream operations). As naming issues is step one to start out analyzing them and taking them extra significantly, that is an excellent factor.
Information-centric AI: good knowledge, unhealthy knowledge, distribution shifts and knowledge cascades
A distribution shift occurs when knowledge at take a look at/deployment time is completely different from the coaching knowledge. In manufacturing, this usually occurs within the type of idea drifts, the place the take a look at knowledge steadily adjustments over time.
As machine studying is more and more utilized in real-world functions, the necessity for a stable understanding of distributional shifts turns into paramount. This begins with designing difficult benchmarks, Benaich and Hogarth state within the report.
Benaich believes that it is onerous to pin particular distribution shift examples in the true world, as a result of organizations would most likely not need the world to know they had been affected by such points. However one of many areas this might have an effect on could be round pricing on varied retail web sites.
Incessantly, there’s a machine-learning powered dynamic pricing engine within the back-end, and its output will depend on how a lot data they’ve about you, famous Benaich. So distribution shift might imply you find yourself getting a really, very completely different worth for a selected product that you are looking at, relying on which knowledge is being utilized. Apparently, this precise observe is focused by China’s market regulator.
Benaich emphasised the very fact that there have been not less than two main new datasets launched aiming to take care of distributions shifts, WILDS and Shifts, developed by quite a lot of American and Japanese universities and corporations and Yandex, respectively.
Having extra industry-oriented datasets being utilized in academia means the in the end tutorial initiatives are extra probably to reach the manufacturing atmosphere, as a result of there’s much less distribution shift whenever you transfer from {industry} to academia and vice versa, famous Benaich.
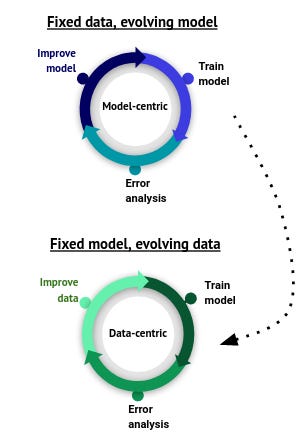
The significance of information will not be new — there are well-established mathematical, algorithmic, and programs methods for working with knowledge, which have been developed over many years.
What’s new is how you can construct on and re-examine these methods in mild of recent AI fashions and strategies. Just some years in the past, we didn’t have long-lived AI programs or the present breed of highly effective deep fashions.
Google researchers outline knowledge cascades as “compounding occasions inflicting damaging, downstream results from knowledge points”. Supported by a survey of 53 practitioners from the US, India, East and West African nations, they warn that present practices undervalue knowledge high quality and lead to knowledge cascades.
It is a pretty intuitive concept — the domino impact. You probably have an issue firstly, it should probably come down by the point you get to the final domino. What’s notable is that the overwhelming majority of information scientists experiences having skilled one in every of these points.
When attempting to attribute why these points really occurred, it was principally resulting from lack of recognition of the significance of information throughout the context of their work in AI, or lack of coaching within the area, or not having access to sufficient specialised knowledge for the actual downside that they had been fixing.
What that factors to is that on the earth of machine studying there’s extra nuance than “good knowledge” and “unhealthy knowledge”. As datasets are multi-faceted, with completely different subsets utilized in completely different contexts, and completely different variations evolving, context is vital in defining knowledge high quality. The insights from machine studying in manufacturing incite a shift of focus from model-centric to data-centric AI.
Information-centric AI is a notion developed in Hazy Analysis, Chris Ré’s Analysis Group at Stanford. As famous, the significance of information will not be new — there are well-established mathematical, algorithmic, and programs methods for working with knowledge, which have been developed over many years.
What’s new is how you can construct on and re-examine these methods in mild of recent AI fashions and strategies. Just some years in the past, we didn’t have long-lived AI programs or the present breed of highly effective deep fashions.
Be a part of us subsequent week as we proceed the dialog with Benaich and Hogarth, to cowl subjects similar to language fashions, AI commercialization, and AI-powered biotechnology.:
[ad_2]