

{kind=link}
[ad_1]
DALL·E is a 12-billion parameter model of GPT-3 skilled to generate pictures from textual content descriptions, utilizing a dataset of textual content–picture pairs. We’ve discovered that it has a various set of capabilities, together with creating anthropomorphized variations of animals and objects, combining unrelated ideas in believable methods, rendering textual content, and making use of transformations to present pictures.
an illustration of a child daikon radish in a tutu strolling a canine
an armchair within the form of an avocado. . . .
a retailer entrance that has the phrase ‘openai’ written on it. . . .
the very same cat on the highest as a sketch on the backside
GPT-3 confirmed that language can be utilized to instruct a big neural community to carry out quite a lot of textual content era duties. Picture GPT confirmed that the identical sort of neural community will also be used to generate pictures with excessive constancy. We prolong these findings to indicate that manipulating visible ideas via language is now inside attain.
Overview
Like GPT-3, DALL·E is a transformer language mannequin. It receives each the textual content and the picture as a single stream of information containing as much as 1280 tokens, and is skilled utilizing most chance to generate all the tokens, one after one other. This coaching process permits DALL·E to not solely generate a picture from scratch, but in addition to regenerate any rectangular area of an present picture that extends to the bottom-right nook, in a method that’s in line with the textual content immediate.
We acknowledge that work involving generative fashions has the potential for important, broad societal impacts. Sooner or later, we plan to investigate how fashions like DALL·E relate to societal points like financial impression on sure work processes and professions, the potential for bias within the mannequin outputs, and the long run moral challenges implied by this expertise.
Capabilities
We discover that DALL·E is ready to create believable pictures for a fantastic number of sentences that discover the compositional construction of language. We illustrate this utilizing a sequence of interactive visuals within the subsequent part. The samples proven for every caption within the visuals are obtained by taking the highest 32 of 512 after reranking with CLIP, however we don’t use any guide cherry-picking, apart from the thumbnails and standalone pictures that seem exterior.
Controlling Attributes
We take a look at DALL·E’s capability to switch a number of of an object’s attributes, in addition to the variety of instances that it seems.
Click on to edit textual content immediate or view extra AI-generated pictures
a pentagonal inexperienced clock. a inexperienced clock within the form of a pentagon.

navigatedownwide
For a number of of the visuals on this submit, we discover that repeating the caption, typically with different phrasings, improves the consistency of the outcomes.
a dice made from porcupine. a dice with the feel of a porcupine.

navigatedownwide
We discover that DALL·E can map the textures of varied vegetation, animals, and different objects onto three dimensional solids. As within the previous visible, we discover that repeating the caption with different phrasing improves the consistency of the outcomes.
a set of glasses is sitting on a desk

navigatedownwide
We discover that DALL·E is in a position to attract a number of copies of an object when prompted to take action, however is unable to reliably depend previous three. When prompted to attract nouns for which there are a number of meanings, resembling “glasses,” “chips,” and “cups” it typically attracts each interpretations, relying on the plural type that’s used.
Drawing A number of Objects
Concurrently controlling a number of objects, their attributes, and their spatial relationships presents a brand new problem. For instance, take into account the phrase “a hedgehog sporting a purple hat, yellow gloves, blue shirt, and inexperienced pants.” To accurately interpret this sentence, DALL·E should not solely accurately compose every bit of attire with the animal, but in addition type the associations (hat, purple), (gloves, yellow), (shirt, blue), and (pants, inexperienced) with out mixing them up. We take a look at DALL·E’s capability to do that for relative positioning, stacking objects, and controlling a number of attributes.
a small purple block sitting on a big inexperienced block

navigatedownwide
We discover that DALL·E accurately responds to some forms of relative positions, however not others. The alternatives “sitting on” and “standing in entrance of” typically seem to work, “sitting beneath,” “standing behind,” “standing left of,” and “standing proper of” don’t. DALL·E additionally has a decrease success charge when requested to attract a big object sitting on prime of a smaller one, when in comparison with the opposite method round.
a stack of three cubes. a purple dice is on the highest, sitting on a inexperienced dice. the inexperienced dice is within the center, sitting on a blue dice. the blue dice is on the underside.

navigatedownwide
We discover that DALL·E sometimes generates a picture with one or two of the objects having the proper colours. Nonetheless, just a few samples for every setting are inclined to have precisely three objects coloured exactly as specified.
an emoji of a child penguin sporting a blue hat, purple gloves, inexperienced shirt, and yellow pants

navigatedownwide
We discover that DALL·E sometimes generates a picture with two or three articles of clothes having the proper colours. Nonetheless, just a few of the samples for every setting are inclined to have all 4 articles of clothes with the required colours.
Whereas DALL·E does provide some degree of controllability over the attributes and positions of a small variety of objects, the success charge can rely upon how the caption is phrased. As extra objects are launched, DALL·E is liable to complicated the associations between the objects and their colours, and the success charge decreases sharply. We additionally word that DALL·E is brittle with respect to rephrasing of the caption in these eventualities: different, semantically equal captions typically yield no right interpretations.
Visualizing Perspective and Three-Dimensionality
We discover that DALL·E additionally permits for management over the perspective of a scene and the 3D fashion wherein a scene is rendered.
an excessive close-up view of a capybara sitting in a discipline

navigatedownwide
We discover that DALL·E can draw every of the animals in quite a lot of completely different views. A few of these views, resembling “aerial view” and “rear view,” require data of the animal’s look from uncommon angles. Others, resembling “excessive close-up view,” require data of the fine-grained particulars of the animal’s pores and skin or fur.
a capybara made from voxels sitting in a discipline

navigatedownwide
We discover that DALL·E is usually capable of modify the floor of every of the animals based on the chosen 3D fashion, resembling “claymation” and “made from voxels,” and render the scene with believable shading relying on the situation of the solar. The “x-ray” fashion doesn’t at all times work reliably, nevertheless it exhibits that DALL·E can typically orient the bones throughout the animal in believable (although not anatomically right) configurations.
To push this additional, we take a look at DALL·E’s capability to repeatedly draw the pinnacle of a widely known determine at every angle from a sequence of equally spaced angles, and discover that we will recuperate a clean animation of the rotating head.
{a photograph} of a bust of homer

navigatedownwide
We immediate DALL·E with each a caption describing a widely known determine and the highest area of a picture displaying a hat drawn at a selected angle. Then, we ask DALL·E to finish the remaining a part of the picture given this contextual data. We do that repeatedly, every time rotating the hat a number of extra levels, and discover that we’re capable of recuperate clean animations of a number of well-known figures, with every body respecting the exact specification of angle and ambient lighting.
DALL·E seems to have the ability to apply some forms of optical distortions to scenes, as we see with the choices “fisheye lens view” and “a spherical panorama.” This motivated us to discover its capability to generate reflections.
a plain white dice taking a look at its personal reflection in a mirror. a plain white dice gazing at itself in a mirror.

navigatedownwide
Just like what was finished earlier than, we immediate DALL·E to finish the bottom-right corners of a sequence of frames, every of which incorporates a mirror and reflective ground. Whereas the reflection within the mirror normally resembles the article exterior of it, it typically doesn’t render the reflection in a bodily right method. Against this, the reflection of an object drawn on a reflective ground is usually extra believable.
Visualizing Inside and Exterior Construction
The samples from the “excessive close-up view” and “x-ray” fashion led us to additional discover DALL·E’s capability to render inside construction with cross-sectional views, and exterior construction with macro images.
a cross-section view of a walnut
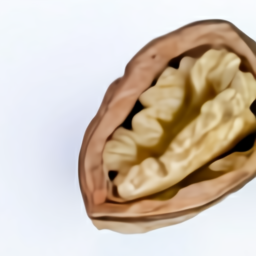
navigatedownwide
We discover that DALL·E is in a position to attract the interiors of a number of completely different sorts of objects.
a macro {photograph} of mind coral
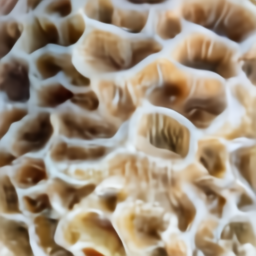
navigatedownwide
We discover that DALL·E is in a position to attract the fine-grained exterior particulars of a number of completely different sorts of objects. These particulars are solely obvious when the article is considered up shut.
Inferring Contextual Particulars
The duty of translating textual content to pictures is underspecified: a single caption usually corresponds to an infinitude of believable pictures, so the picture shouldn’t be uniquely decided. For example, take into account the caption “a portray of a capybara sitting on a discipline at dawn.” Relying on the orientation of the capybara, it might be essential to attract a shadow, although this element is rarely talked about explicitly. We discover DALL·E’s capability to resolve underspecification in three circumstances: altering fashion, setting, and time; drawing the identical object in quite a lot of completely different conditions; and producing a picture of an object with particular textual content written on it.
a portray of a capybara sitting in a discipline at dawn

navigatedownwide
We discover that DALL·E is ready to render the identical scene in quite a lot of completely different kinds, and may adapt the lighting, shadows, and surroundings based mostly on the time of day or season.
a retailer entrance that has the phrase ‘openai’ written on it. a retailer entrance that has the phrase ‘openai’ written on it. a retailer entrance that has the phrase ‘openai’ written on it. ‘openai’ retailer entrance.

navigatedownwide
Usually, the longer the string that DALL·E is prompted to put in writing, the decrease the success charge. We discover that the success charge improves when components of the caption are repeated. Moreover, the success charge typically improves because the sampling temperature for the picture is decreased, though the samples turn into easier and fewer reasonable.
With various levels of reliability, DALL·E gives entry to a subset of the capabilities of a 3D rendering engine through pure language. It may independently management the attributes of a small variety of objects, and to a restricted extent, what number of there are, and the way they’re organized with respect to 1 one other. It may additionally management the situation and angle from which a scene is rendered, and may generate recognized objects in compliance with exact specs of angle and lighting situations.
Not like a 3D rendering engine, whose inputs have to be specified unambiguously and in full element, DALL·E is usually capable of “fill within the blanks” when the caption implies that the picture should include a sure element that isn’t explicitly acknowledged.
Purposes of Previous Capabilities
Subsequent, we discover the usage of the previous capabilities for vogue and inside design.
a male model wearing an orange and black flannel shirt

navigatedownwide

DALL·E additionally appears to sometimes confuse much less frequent colours with different neighboring shades. For instance, when prompted to attract garments in “navy,” DALL·E typically makes use of lighter shades of blue, or shades very near black. Equally, DALL·E typically confuses “olive” with shades of brown or brighter shades of inexperienced.
a feminine model wearing a black leather-based jacket and gold pleated skirt

navigatedownwide

We discover DALL·E’s capability to render feminine mannequins in quite a lot of completely different outfits. We discover that DALL·E is ready to painting distinctive textures such because the sheen of a “black leather-based jacket” and “gold” skirts and leggings. As earlier than, we see that DALL·E sometimes confuses much less frequent colours, resembling “navy” and “olive,” with different neighboring shades.
a front room with two white armchairs and a portray of the colosseum. the portray is mounted above a contemporary fire.

navigatedownwide

We discover DALL·E’s capability to generate pictures of rooms with a number of particulars specified. We discover that it could generate work of a variety of various topics, together with real-world areas resembling “the colosseum” and fictional characters like “yoda.” For every topic, DALL·E displays quite a lot of interpretations. Whereas the portray is sort of at all times current within the scene, DALL·E typically fails to attract the fireside or the proper variety of armchairs.
a loft bed room with a white mattress subsequent to a nightstand. there’s a fish tank beside the mattress.

navigatedownwide

We discover DALL·E’s capability to generate bedrooms with a number of particulars specified. Even supposing we don’t inform DALL·E what ought to go on prime of the nightstand or shelf beside the mattress, we discover that it typically decides to put the opposite specified object on prime. As earlier than, we see that it typically fails to attract a number of of the required objects.
Combining Unrelated Ideas
The compositional nature of language permits us to place collectively ideas to explain each actual and imaginary issues. We discover that DALL·E additionally has the power to mix disparate concepts to synthesize objects, a few of that are unlikely to exist in the actual world. We discover this capability in two situations: transferring qualities from numerous ideas to animals, and designing merchandise by taking inspiration from unrelated ideas.
a snail made from harp. a snail with the feel of a harp.

navigatedownwide
In a earlier part, we noticed that as extra objects are launched into the scene, DALL·E is liable to confuse the associations between the objects and their specified attributes. Right here, we see a unique kind of failure mode: typically, slightly than binding some attribute of the required idea (say, “a faucet”) to the animal (say, “a snail”), DALL·E simply attracts the 2 as separate objects.
an armchair within the form of an avocado. an armchair imitating an avocado.

navigatedownwide
When producing a few of these objects, resembling “an armchair within the form of an avocado”, DALL·E seems to narrate the form of a half avocado to the again of the chair, and the pit of the avocado to the cushion. We discover that DALL·E is inclined to the identical sorts of errors talked about within the earlier visible.
Animal Illustrations
Within the earlier part, we explored DALL·E’s capability to mix unrelated ideas when producing pictures of real-world objects. Right here, we discover this capability within the context of artwork, for 3 sorts of illustrations: anthropomorphized variations of animals and objects, animal chimeras, and emojis.
an illustration of a child daikon radish in a tutu strolling a canine

navigatedownwide
We discover it attention-grabbing how DALL·E adapts human physique components onto animals. For instance, when requested to attract a daikon radish blowing its nostril, sipping a latte, or driving a unicycle, DALL·E typically attracts the kerchief, arms, and toes in believable areas.
knowledgeable prime quality illustration of a giraffe turtle chimera. a giraffe imitating a turtle. a giraffe made from turtle.

navigatedownwide
We additionally discover that inserting the phrase “skilled prime quality” earlier than “illustration” and “emoji” typically improves the standard and consistency of the outcomes.
knowledgeable prime quality emoji of a lovestruck cup of boba

navigatedownwide
We discover that DALL·E is typically capable of switch some emojis to animals and inanimate objects, resembling meals objects. As within the previous visible, we discover that inserting the phrase “skilled prime quality” earlier than “emoji” typically improves the standard and consistency of the outcomes.
Zero-Shot Visible Reasoning
GPT-3 could be instructed to carry out many sorts of duties solely from an outline and a cue to generate the reply provided in its immediate, with none extra coaching. For instance, when prompted with the phrase “right here is the sentence ‘an individual strolling his canine within the park’ translated into French:”, GPT-3 solutions “un homme qui promène son chien dans le parc.” This functionality known as zero-shot reasoning. We discover that DALL·E extends this functionality to the visible area, and is ready to carry out a number of sorts of image-to-image translation duties when prompted in the proper method.
the very same cat on the highest as a sketch on the underside

navigatedownwide
Different transformations, resembling “animal with sun shades” and “animal sporting a bow tie,” require inserting the accent on the proper a part of the animal’s physique. People who solely change the colour of the animal, resembling “animal coloured pink,” are much less dependable, however present that DALL·E is typically able to segmenting the animal from the background. Lastly, the transformations “a sketch of the animal” and “a cellular phone case with the animal” discover the usage of this functionality for illustrations and product design.
the very same teapot on the highest with ’gpt’ written on it on the underside

navigatedownwide
We discover that DALL·E is ready to apply a number of completely different sorts of picture transformations to pictures of teapots, with various levels of reliability. Except for having the ability to modify the colour of the teapot (e.g., “coloured blue”) or its sample (e.g., “with stripes”), DALL·E also can render textual content (e.g., “with ‘gpt’ written on it”) and map the letters onto the curved floor of the teapot in a believable method. With a lot much less reliability, it could additionally draw the teapot in a smaller dimension (for the “tiny” possibility) and in a damaged state (for the “damaged” possibility).
We didn’t anticipate that this functionality would emerge, and made no modifications to the neural community or coaching process to encourage it. Motivated by these outcomes, we measure DALL·E’s aptitude for analogical reasoning issues by testing it on Raven’s progressive matrices, a visible IQ take a look at that noticed widespread use within the twentieth century.
a sequence of geometric shapes.

navigatedownwide
DALL·E is usually capable of resolve matrices that contain persevering with easy patterns or primary geometric reasoning, resembling these in units B and C. It’s typically capable of resolve matrices that contain recognizing permutations and making use of boolean operations, resembling these in set D. The situations in set E are typically probably the most tough, and DALL·E will get nearly none of them right.
For every of the units, we measure DALL·E’s efficiency on each the unique pictures, and the pictures with the colours inverted. The inversion of colours ought to pose no extra issue for a human, but does usually impair DALL·E’s efficiency, suggesting its capabilities could also be brittle in sudden methods.
Geographic Information
We discover that DALL·E has discovered about geographic info, landmarks, and neighborhoods. Its data of those ideas is surprisingly exact in some methods and flawed in others.
a photograph of the meals of china

navigatedownwide
We take a look at DALL·E’s understanding of easy geographical info, resembling nation flags, cuisines, and native wildlife. Whereas DALL·E efficiently solutions many of those queries, resembling these involving nationwide flags, it typically displays superficial stereotypes for decisions like “meals” and “wildlife,” versus representing the total variety encountered in the actual world.
a photograph of alamo sq., san francisco, from a road at night time

navigatedownwide
We discover that DALL·E is typically able to rendering semblances of sure areas in San Francisco. For areas acquainted to the authors, resembling San Francisco, they evoke a way of déjà vu—eerie simulacra of streets, sidewalks and cafes that remind us of very particular areas that don’t exist.
a photograph of san francisco’s golden gate bridge

navigatedownwide
We will additionally immediate DALL·E to attract well-known landmarks. Actually, we will even dictate when the picture was taken by specifying the primary few rows of the sky. When the sky is darkish, for instance, DALL·E acknowledges it’s night time, and activates the lights within the buildings.
Temporal Information
Along with exploring DALL·E’s data of ideas that change over area, we additionally discover its data of ideas that change over time.
a photograph of a telephone from the 20s

navigatedownwide
We discover that DALL·E has discovered about primary stereotypical traits in design and expertise over the many years. Technological artifacts seem to undergo durations of explosion of change, dramatically shifting for a decade or two, then altering extra incrementally, turning into refined and streamlined.
Abstract of Strategy and Prior Work
DALL·E is a straightforward decoder-only transformer that receives each the textual content and the picture as a single stream of 1280 tokens—256 for the textual content and 1024 for the picture—and fashions all of them autoregressively. The eye masks at every of its 64 self-attention layers permits every picture token to take care of all textual content tokens. DALL·E makes use of the usual causal masks for the textual content tokens, and sparse consideration for the picture tokens with both a row, column, or convolutional consideration sample, relying on the layer. We offer extra particulars concerning the structure and coaching process in our paper.
Textual content-to-image synthesis has been an energetic space of analysis because the pioneering work of Reed et. al, whose strategy makes use of a GAN conditioned on textual content embeddings. The embeddings are produced by an encoder pretrained utilizing a contrastive loss, not not like CLIP. StackGAN and StackGAN++ use multi-scale GANs to scale up the picture decision and enhance visible constancy. AttnGAN incorporates consideration between the textual content and picture options, and proposes a contrastive text-image characteristic matching loss as an auxiliary goal. That is attention-grabbing to match to our reranking with CLIP, which is completed offline. Different work incorporates extra sources of supervision throughout coaching to enhance picture high quality. Lastly, work by Nguyen et. al and Cho et. al explores sampling-based methods for picture era that leverage pretrained multimodal discriminative fashions.
Just like the rejection sampling utilized in VQVAE-2, we use CLIP to rerank the highest 32 of 512 samples for every caption in all the interactive visuals. This process will also be seen as a type of language-guided search, and may have a dramatic impression on pattern high quality.
an illustration of a child daikon radish in a tutu strolling a canine
navigatedownwide
Reranking the samples from DALL·E utilizing CLIP can dramatically enhance consistency and high quality of the samples.
[ad_2]