

{kind=link}
[ad_1]
On this submit, we stroll you thru learn how to arrange automated notifications of question monitoring rule (QMR) violations in Amazon Redshift to a Slack channel, in order that Amazon Redshift customers can take well timed motion.
Amazon Redshift is a totally managed, petabyte-scale knowledge warehouse service within the cloud. With Amazon Redshift, you’ll be able to analyze your knowledge to derive holistic insights about your enterprise and your clients. One of many challenges is to guard the information warehouse workload from poorly written queries that may eat important assets. Amazon Redshift question monitoring guidelines are a characteristic of workload administration (WLM) that permit automated dealing with of poorly written queries. Guidelines which are utilized to a WLM queue permit queries to be logged, canceled, hopped (solely obtainable with guide WLM), or to alter precedence (solely obtainable with automated WLM). The explanation to make use of QMRs is to guard towards wasteful use of the cluster. You too can use these guidelines to log resource-intensive queries, which supplies the chance to ascertain governance for advert hoc workloads.
The Amazon Redshift cluster routinely collects question monitoring guidelines metrics. This handy mechanism enables you to view attributes like the next:
- Question runtime, in seconds
- Question return row rely
- The CPU time for a SQL assertion
It additionally makes Amazon Redshift Spectrum metrics obtainable, such because the variety of Redshift Spectrum rows and MBs scanned by a question.
When a question violates a QMR, Amazon Redshift logs the violation into the STL_WLM_RULE_ACTION system view. If the motion is aborted for the queries that violate a QMR, end-users see an error that signifies question failure attributable to violation of QMRs. We suggest that administrative staff members periodically study violations listed within the STL_WLM_RULE_ACTION desk and coach the concerned end-users on learn how to keep away from future rule violations.
Alternately, a centralized staff, utilizing a Slack channel for collaboration and monitoring, can configure Amazon Redshift occasions and alarms to be despatched to their channel, in order that they’ll take well timed motion. Within the following sections, we stroll you thru learn how to arrange automated notifications of QMR violations to a Slack channel by way of using Slack occasions and alarms. This permits Amazon Redshift customers to be notified and take well timed actions with out the necessity to question the system view.
Resolution overview
To show how one can obtain automated notification to a Slack channel for QMR violation, we’ve designed the next structure. As proven within the following diagram, we’ve combined workload extract, remodel, and cargo (ETL), enterprise intelligence (BI) dashboards, and analytics purposes which are powered by an Amazon Redshift cluster. The answer depends on AWS Lambda and Amazon Easy Notification Service (Amazon SNS) to ship notifications of Amazon Redshift QMR violations to Slack.

To implement this resolution, you create an Amazon Redshift cluster and fasten a customized outlined parameter group.
Amazon Redshift supplies one default parameter group for every parameter group household. The default parameter group has preset values for every of its parameters, and it may’t be modified. If you wish to use completely different parameter values than the default parameter group, you will need to create a customized parameter group after which affiliate your cluster with it.
Within the parameter group, you should use automated WLM and outline just a few workload queues, reminiscent of a queue for processing ETL workloads and a reporting queue for person queries. You possibly can identify the default queue adhoc. With automated WLM, Amazon Redshift determines the optimum concurrency and reminiscence allocation for every question that’s operating in every queue.
For every workload queue, you’ll be able to outline a number of QMRs. For instance, you’ll be able to create a rule to abort a person question if it runs for greater than 300 seconds or returns greater than 1 billion rows. Equally, you’ll be able to create a rule to log a Redshift Spectrum question that scans greater than 100 MB.
The Amazon Redshift WLM evaluates metrics each 10 seconds. It data particulars about actions that end result from QMR violation that’s related to user-defined queues within the STL_WLM_RULE_ACTION system desk. On this resolution, a Lambda operate is scheduled to watch the STL_WLM_RULE_ACTION system desk each jiffy. When the operate is invoked, if it finds a brand new entry, it publishes an in depth message to an SNS matter. A second Lambda operate, created because the goal subscriber to the SNS matter, is invoked every time any message is revealed to the SNS matter. This second operate invokes a pre-created Slack webhook, which sends the message that was obtained by way of the SNS matter to the Slack channel of your selection. (For extra info on publishing messages through the use of Slack webhooks, see Sending messages utilizing incoming webhooks.)
To summarize, the answer includes the next steps:
- Create an Amazon Redshift customized parameter group and add workload queues.
- Configure question monitoring guidelines.
- Connect the customized parameter group to the cluster.
- Create a SNS matter.
- Create a Lambda operate and schedule it to run each 5 minutes through the use of an Amazon EventBridge rule.
- Create the Slack assets.
- Add an incoming webhook and authorize the Slack app to submit messages to a Slack channel.
- Create the second Lambda operate and subscribe to the SNS matter.
- Take a look at the answer.
Create an Amazon Redshift customized parameter group and add workload queues
On this step, you create an Amazon Redshift customized parameter group with automated WLM enabled. You additionally create the next queues to separate the workloads within the parameter group:
- reporting – The
reportingqueue runs BI reporting queries which are carried out by any person who belongs to the Amazon Redshift database group namedreporting_group - adhoc – The default queue, renamed
adhoc, performs any question that’s not despatched to every other queue
Full the next steps to create your parameter group and add workload queues:
- Create a parameter group, named
csblog, with automated WLM enabled. - On the Amazon Redshift console, choose the customized parameter group you created.
- Select Edit workload queues.
- On the Modify workload queues web page, select Add queue.
- Fill within the Concurrency scaling mode and Question precedence fields as wanted to create the
reportingqueue. - Repeat these steps so as to add the
adhocqueue.
For extra details about WLM queues, discuss with Configuring workload administration.
Configure question monitoring guidelines
On this step, you add QMRs to every workload queue. For directions, discuss with Creating or modifying a question monitoring rule utilizing the console.
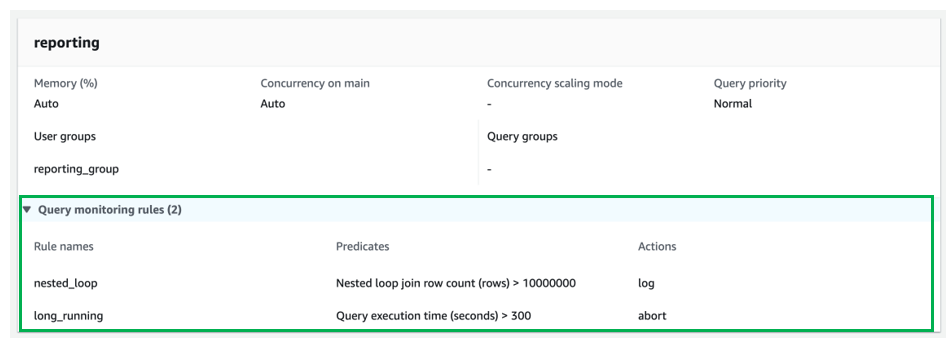
For the reporting queue, add the next QMRs:
- nested_loop – Logs any question concerned in a nested loop be part of that leads to a row rely greater than 10,000,000 rows.
- long_running – Stops queries that run for greater than 300 seconds (5 minutes).
For the adhoc queue, add the next QMRs:
- returned_rows – Stops any question that returns greater than 1,000,000 rows again to the calling shopper utility (this isn’t sensible and might degrade the end-to-end efficiency of the appliance).
- spectrum_scan – Stops any question that scans greater than 1000 MB of information from an Amazon Easy Storage Service (Amazon S3) knowledge lake through the use of Redshift Spectrum.

Connect the customized parameter group to the cluster
To connect the customized parameter group to your provisioned Redshift cluster, observe the directions in Associating a parameter group with a cluster. In case you don’t have already got a provisioned Redshift cluster, discuss with Create a cluster.
For this submit, we connected our customized parameter group csblog to an already created provisioned Amazon Redshift cluster.

Create an SNS matter
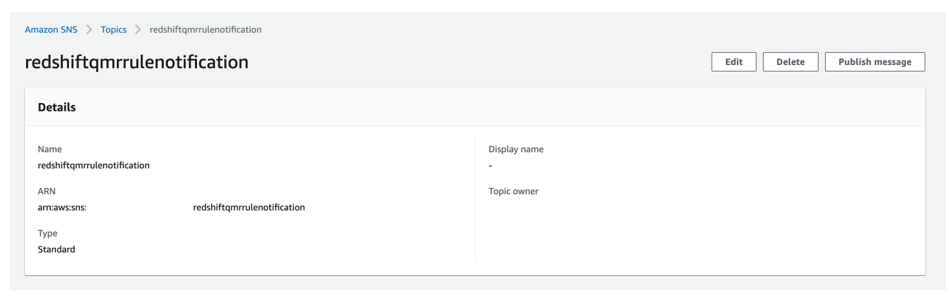
On this step, you create an SNS matter that receives an in depth message of QMR violation from the Lambda operate that checks the Amazon Redshift system desk for QMR violation entries. For directions, discuss with Creating an Amazon SNS matter.
For this submit, we created an SNS matter named redshiftqmrrulenotification.
Create a Lambda operate to watch the system desk
On this step, you create a Lambda operate that displays the STL_WLM_RULE_ACTION system desk. Every time any file is discovered within the desk because the final time the operate ran, the operate publishes an in depth message to the SNS matter that you simply created earlier. You additionally create an EventBridge rule to invoke the operate each 5 minutes.
For this submit, we create a Lambda operate named redshiftqmrrule that’s scheduled to run each 5 minutes by way of an EventBridge rule named Redshift-qmr-rule-Lambda-schedule. For directions, discuss with Constructing Lambda features with Python.
The next screenshot reveals the operate that checks the pg_catalog.stl_wlm_rule_action desk.

To create an EventBridge rule and affiliate it with the Lambda operate, discuss with Create a Rule.
The next screenshot reveals the EventBridge rule Redshift-qmr-rule-Lambda-schedule, which calls the operate each 5 minutes.

We use the next Python 3.9 code for this Lambda operate. The operate makes use of an Amazon Redshift Knowledge API name that makes use of GetClusterCredentials for momentary credentials.
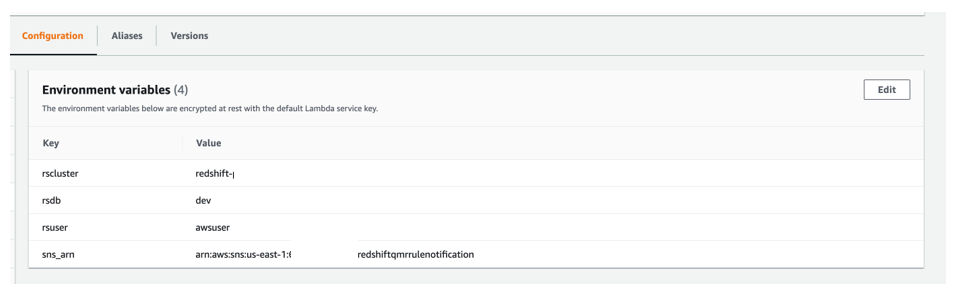
We use 4 atmosphere variables for this Lambda operate:
- rscluster – The Amazon Redshift provisioned cluster identifier
- rsdb – The Amazon Redshift database the place you’re operating these assessments
- rsuser – The Amazon Redshift person who has the privilege to run queries on
pg_catalog.stl_wlm_rule_action - sns_arn – The Amazon Useful resource Identify (ARN) of the SNS matter that we created earlier
Create Slack assets
On this step, you create a brand new Slack workspace (when you don’t have one already), a brand new personal Slack channel (provided that you don’t have one or don’t wish to use an present one), and a brand new Slack app within the Slack workspace. For directions, discuss with Create a Slack workspace, Create a channel, and Creating an app.
For this submit, we created the next assets within the Slack web site and Slack desktop app:
- A Slack workspace named
RedshiftQMR*****
- A non-public channel, named
redshift-qmr-notification-*****-*******, within the newly created Slack workspace
- A brand new Slack app within the Slack workspace, named
RedshiftQMRRuleNotification(utilizing the From Scratch possibility)
Add an incoming webhook and authorize Slack app
On this step, you allow and add an incoming webhook to the Slack workspace that you simply created. For full directions, discuss with Allow Incoming Webhooks and Create an Incoming Webhook. You additionally authorize your Slack app in order that it may submit messages to the personal Slack channel.
- Within the Slack app, underneath Settings within the navigation pane, select Primary Data.
- Select Incoming Webhooks.
- Activate Activate Incoming Webhooks.

- Select Add New Webhook to Workspace.
- Authorize the Slack app
RedshiftQMRRuleNotificationin order that it may submit messages to the personal Slack channelredshift-qmr-notification-*****-*******.
The next screenshot reveals the main points of the newly added incoming webhook.

Create a second Lambda operate and subscribe to the SNS matter
On this step, you create a second Lambda operate that’s subscribed to the SNS matter that you simply created earlier. For full directions, discuss with Constructing Lambda features with Python and Subscribing a operate to a subject.
For this submit, we create a second operate named redshiftqmrrulesnsinvoke, which is subscribed to the SNS matter redshiftqmrrulenotification. The second operate sends an in depth QMR violation message (obtained from the SNS matter) to the designated Slack channel named redshift-qmr-notification-*. This operate makes use of the incoming Slack webhook that we created earlier.

We additionally create an SNS subscription of the second Lambda operate to the SNS matter that we created beforehand.

The next is the Python 3.9 code used for the second Lambda operate:
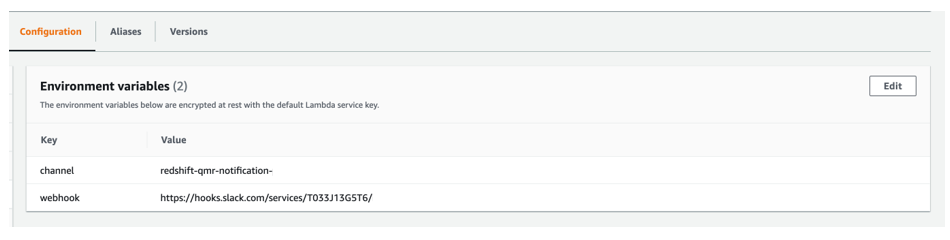
We use two atmosphere variables for the second Lambda operate:
- channel – The Slack channel that we created
- webhook – The Slack webhook that we created
Take a look at the answer
To indicate the impact of the QMRs, we ran queries that violate the QMRs we arrange.
Take a look at 1: Returned rows
Take a look at 1 appears for violations of the returned_rows QMR, during which the return row rely is over 1,000,000 for a question that ran within the adhoc queue.
We created and loaded a desk named lineitem in a schema named aquademo, which has greater than 18 billion data. You possibly can discuss with the GitHub repo to create and cargo the desk.
We ran the next question, which violated the returned_rows QMR, and the question was stopped as specified within the motion set within the QMR.
The next screenshot reveals the view from the Amazon Redshift shopper after operating the question.

The next screenshot reveals the view on the Amazon Redshift console.

The next screenshot reveals the notification we obtained in our Slack channel.

Take a look at 2: Lengthy-running queries
Take a look at 2 appears for violations of the long_running QMR, during which question runtime is over 300 seconds for a person who belongs to reporting_group.
Within the following code, we created a brand new Amazon Redshift group named reporting_group and added a brand new person, named reporting_user, to the group. reporting_group is assigned USAGE and SELECT privileges on all tables within the retail and aquademo schemas.
We set the session authorization to reporting_user so the question runs within the reporting queue. We ran the next question, which violated the long_running QMR, and the question was stopped as specified within the motion set within the QMR:
The next screenshot reveals the view from the Amazon Redshift shopper.

The next screenshot reveals the view on the Amazon Redshift console.

The next screenshot reveals the notification we obtained in our Slack channel.

Take a look at 3: Nested loops
Take a look at 3 appears for violations of the nested_loop QMR, during which the nested loop be part of row rely is over 10,000,000 for a person who belongs to reporting_group.
We set the session authorization to reporting_user so the question runs within the reporting queue. We ran the next question, which violated the nested_loop QMR, and the question logged the violation as specified within the motion set within the QMR:
Earlier than we ran the unique question, we additionally checked the clarify plan and famous that this nested loop will return greater than 10,000,000 rows. The next screenshot reveals the question clarify plan.

The next screenshot reveals the notification we obtained in our Slack channel.

Take a look at 4: Redshift Spectrum scans
Take a look at 4 appears for violations of the spectrum_scan QMR, during which Redshift Spectrum scans exceed 1000 MB for a question that ran within the adhoc queue.
For this instance, we used store_sales knowledge (unloaded from an Amazon Redshift desk that was created through the use of the TPC-DS benchmark knowledge) loaded in an Amazon S3 location. Knowledge in Amazon S3 is non-partitioned underneath one prefix and has a quantity round 3.9 GB. We created an exterior schema (qmr_spectrum_rule_test) and exterior desk (qmr_rule_store_sales) in Redshift Spectrum.
We used the next steps to run this take a look at with the pattern knowledge:
- Run an unload SQL command:
- Create an exterior schema from Redshift Spectrum:
- Create an exterior desk in Redshift Spectrum:
- Run the next question:
The question violated the spectrum_scan QMR, and the question was stopped as specified within the motion set within the QMR.
The next screenshot reveals the view from the Amazon Redshift shopper.
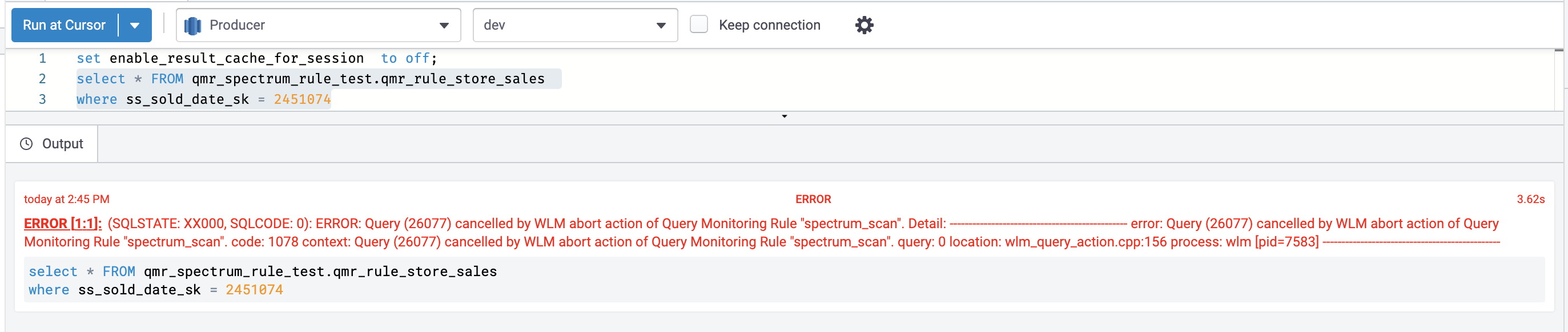
The next screenshot reveals the view on the Amazon Redshift console.

The next screenshot reveals the notification we obtained in our Slack channel.

Clear up
While you’re completed with this resolution, we suggest deleting the assets you created to keep away from incurring any additional fees.
Conclusion
Amazon Redshift is a robust, totally managed knowledge warehouse that may provide considerably elevated efficiency and decrease value within the cloud. On this submit, we mentioned how one can automate notification of misbehaving queries on Slack through the use of question monitoring guidelines. QMRs can assist you maximize cluster efficiency and throughput when supporting combined workloads. Use these directions to arrange your Slack channel to obtain automated notifications out of your Amazon Redshift cluster for any violation of QMRs.
Concerning the Authors
 Dipankar Kushari is a Senior Specialist Options Architect within the Analytics staff at AWS.
Dipankar Kushari is a Senior Specialist Options Architect within the Analytics staff at AWS.
 Harshida Patel is a Specialist Senior Options Architect within the Analytics staff at AWS.
Harshida Patel is a Specialist Senior Options Architect within the Analytics staff at AWS.
[ad_2]