

[ad_1]
Over the past a number of years, enterprises have collected huge quantities of information. Information volumes have elevated at an unprecedented charge, exploding from terabytes to petabytes and generally exabytes of information. More and more, many enterprises are constructing extremely scalable, accessible, safe, and versatile information lakes on AWS that may deal with extraordinarily giant datasets. After information lakes are productionized, to measure the efficacy of the info lake and talk the gaps or accomplishments to the enterprise teams, enterprise information groups want instruments to extract operational insights from the info lake. These insights assist reply key questions comparable to:
- The final time a desk was up to date
- The whole desk depend in every database
- The projected development of a given desk
- Essentially the most continuously queried desk vs. least queried tables
On this publish, I stroll you thru an answer to construct an operational metrics dashboard (like the next screenshot) in your enterprise AWS Glue Information Catalog on AWS.

Answer overview
This publish reveals you the way to acquire metadata info out of your information lake’s AWS Glue Information Catalog assets (databases and tables) and construct an operational dashboard on this information.
The next diagram illustrates the general answer structure and steps.
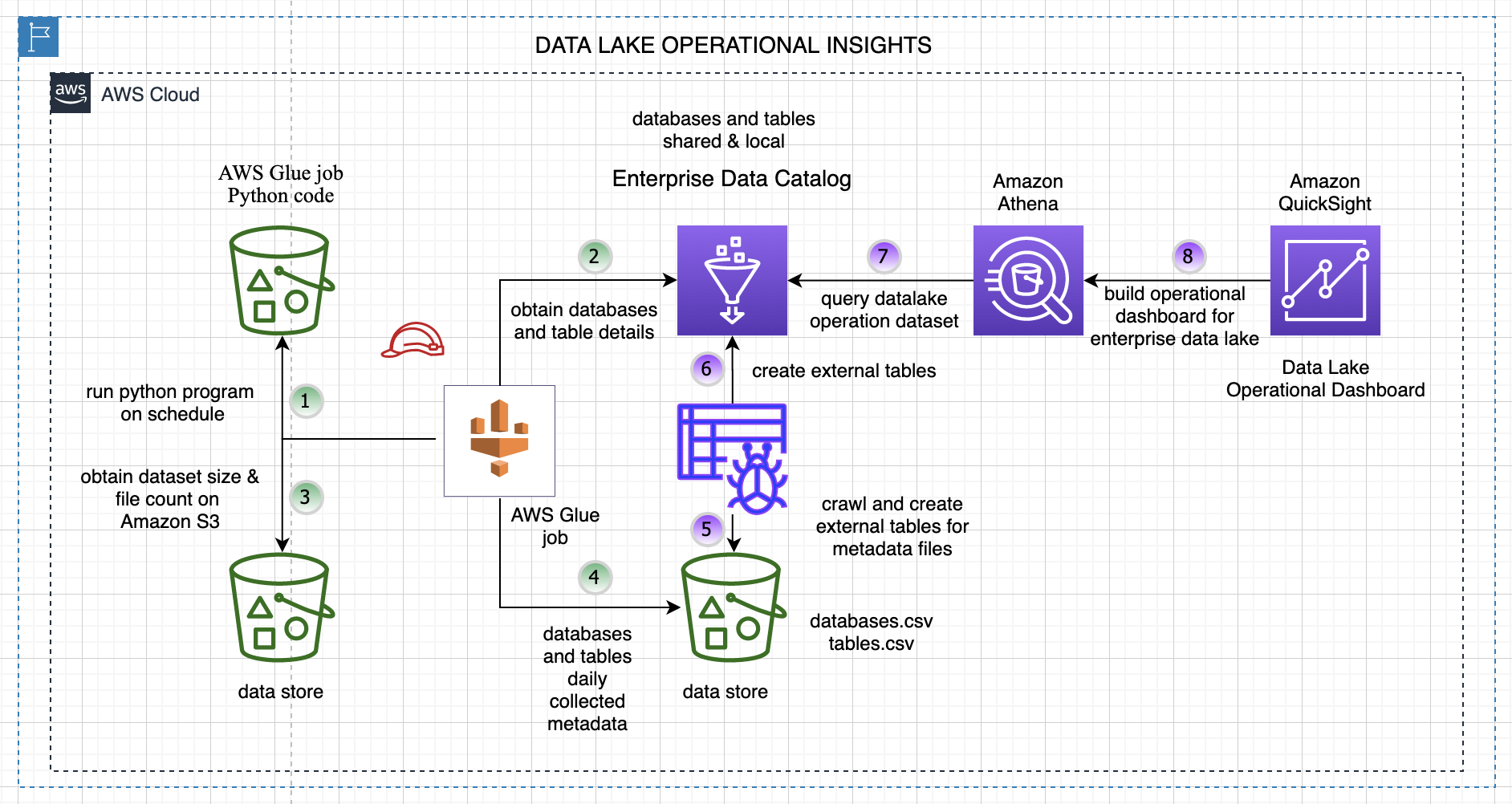
The steps are as follows:
- A knowledge collector Python program runs on a schedule and collects metadata particulars about databases and tables from the enterprise Information Catalog.
- The next key information attributes are collected for every desk and database in your AWS Glue Information Catalog.
| Desk Information | Database Information |
| TableName | DatabaseName |
| DatabaseName | CreateTime |
| Proprietor | SharedResource |
| CreateTime | SharedResourceOwner |
| UpdateTime | SharedResourceDatabaseName |
| LastAccessTime | Location |
| TableType | Description |
| Retention | |
| CreatedBy | |
| IsRegisteredWithLakeFormation | |
| Location | |
| SizeInMBOnS3 | |
| TotalFilesonS3 |
- This system reads every desk’s file location and computes the variety of information on Amazon Easy Storage Service (Amazon S3) and the scale in MB.
- All the info for the tables and databases is saved in an S3 bucket for downstream evaluation. This system runs each day and creates new information partitioned by 12 months, month, and day on Amazon S3.
- We crawl the info created in Step 4 utilizing an AWS Glue crawler.
- The crawler creates an exterior database and tables for our generated dataset for downstream evaluation.
- We will question the extracted information with Amazon Athena.
- We use Amazon QuickSight to construct our operational metrics dashboard and acquire insights into our information lake content material and utilization.
For simplicity, this program crawls and collects information from the Information Catalog for the us-east-1 Area solely.
Walkthrough overview
The walkthrough consists of the next steps:
- Configure your dataset.
- Deploy the core answer assets with an AWS CloudFormation template, and arrange and set off the AWS Glue job.
- Crawl the metadata dataset and create exterior tables within the Information Catalog.
- Construct a view and question the info by means of Athena.
- Arrange and import information into QuickSight to create an operational metrics dashboard for the Information Catalog.
Configure your dataset
We use the AWS COVID-19 information lake for evaluation. This information lake is comprised of information in a publicly readable S3 bucket.
To make the info from the AWS COVID-19 information lake accessible in your AWS account, create a CloudFormation stack utilizing the next template. Should you’re signed in to your AWS account, the next hyperlink fills out many of the stack creation type for you. Make certain to alter the Area to us-east-1. For directions on making a CloudFormation stack, see Get began.
This template creates a COVID-19 database in your Information Catalog and tables that time to the general public AWS COVID-19 information lake. You don’t must host the info in your account, and you’ll depend on AWS to refresh the info as datasets are up to date by means of AWS Information Alternate.
For extra details about the COVID-19 dataset, see A public information lake for evaluation of COVID-19 information.
Your surroundings could have already got present datasets within the Information Catalog. This system collects the aforementioned attributes for these datasets as nicely, which can be utilized for evaluation.
Deploy your assets
To make it simpler to get began, we created a CloudFormation template that robotically units up a number of key parts of the answer:
- An AWS Glue job (Python program) that’s triggered primarily based on a schedule
- The AWS Id and Entry Administration (IAM) function required by the AWS Glue job so the job can acquire and retailer particulars about databases and tables within the Information Catalog
- A brand new S3 bucket for the AWS Glue job to retailer the info information
- A brand new database within the Information Catalog for storing our metrics information tables
The supply code for the AWS Glue job and the CloudFormation template can be found within the GitHub repo.
You could first obtain the AWS Glue Python code from GitHub and add it to an present S3 bucket. The trail of this file must be supplied when operating the CloudFormation stack.
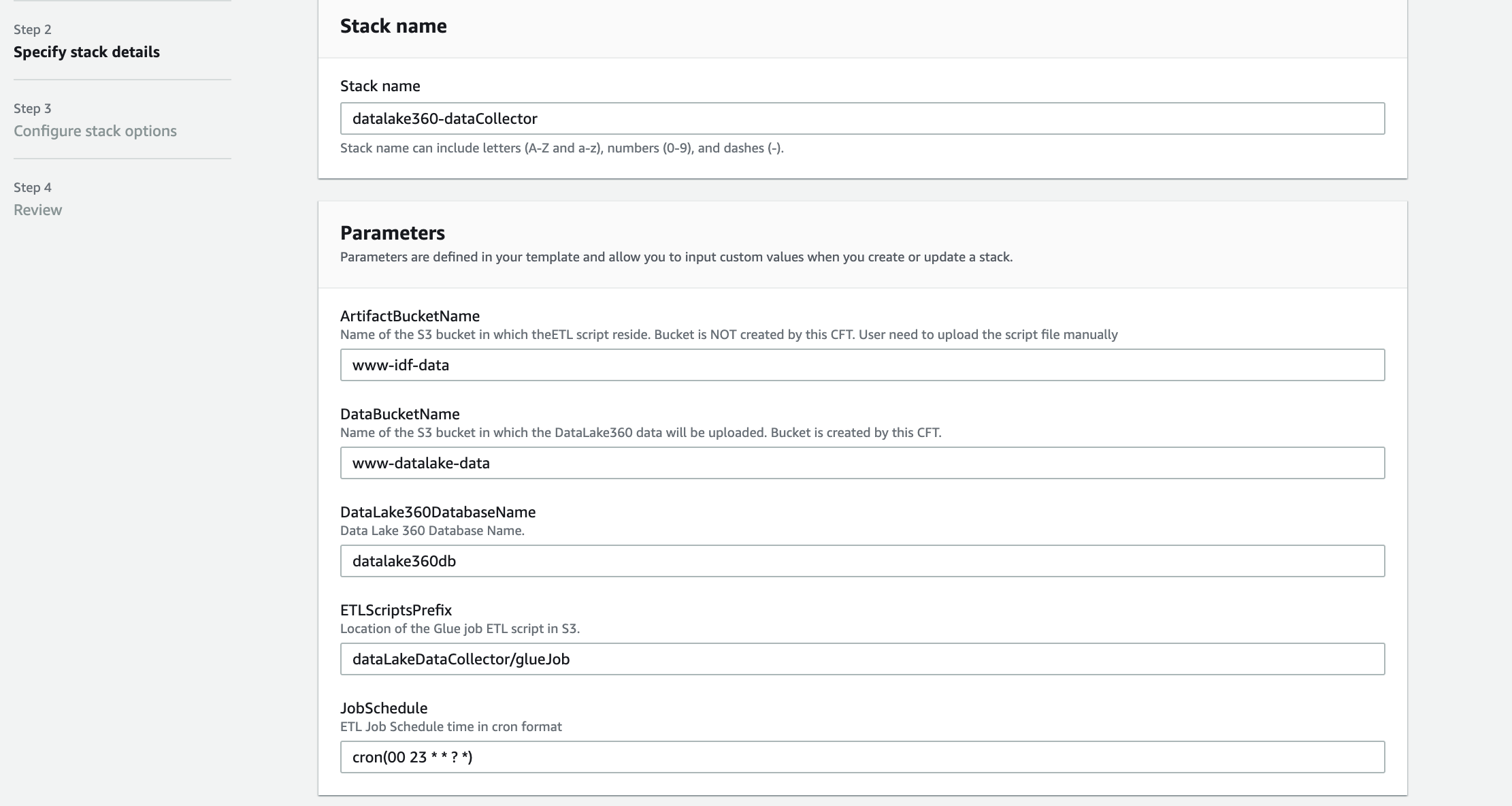
- Launch the stack:

- Present values in your parameters as proven within the following screenshot.
After the stack is deployed efficiently, you possibly can test the assets created on the stack’s Assets tab.
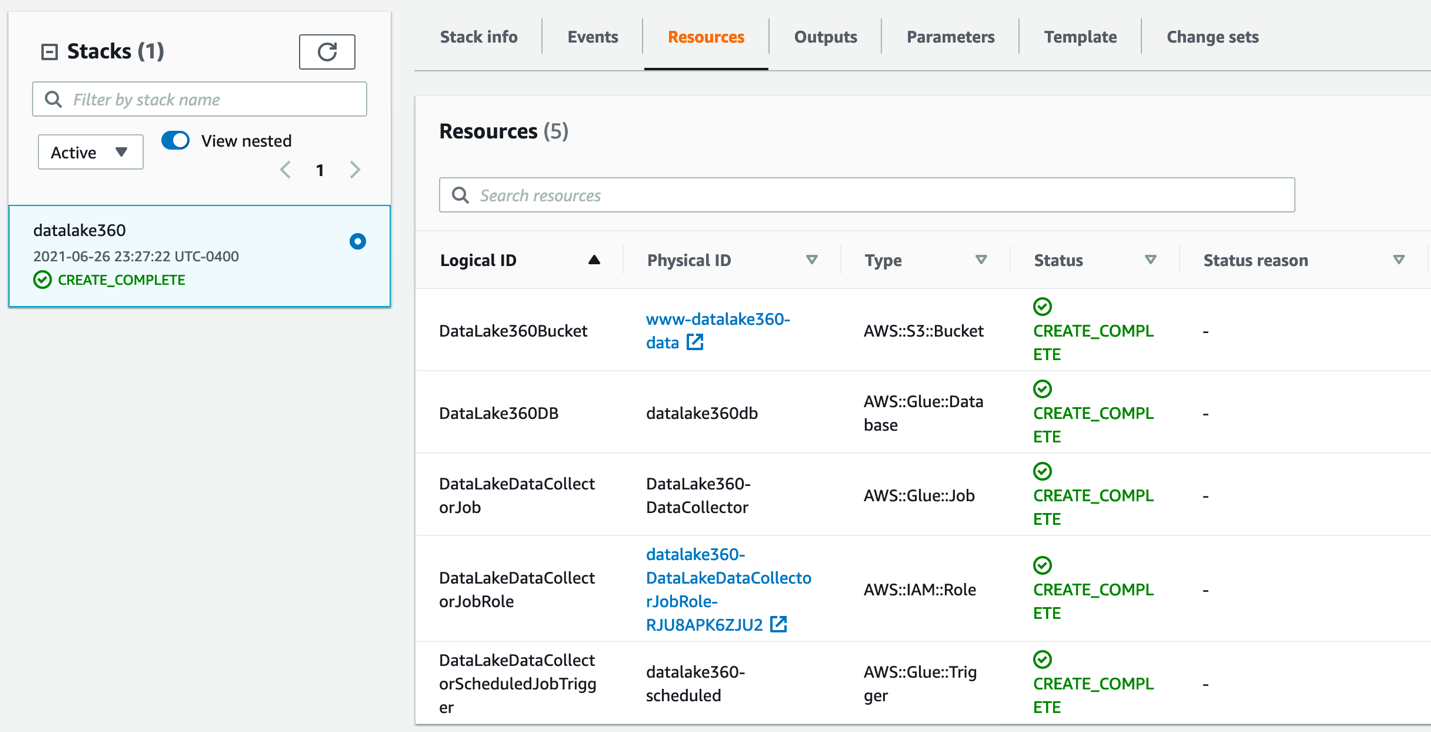
You possibly can confirm and test the AWS Glue job setup and set off, which is scheduled as per your specified time.
Now that we’ve verified that the stack is efficiently arrange, we will run our AWS Glue job manually and acquire key attributes for our evaluation.
- On the AWS Glue console, select AWS Glue Studio within the navigation pane.

- Within the AWS Glue Studio Console, click on on Jobs and choose the
DataCollectorjob and Run the job.
The AWS Glue job collects information and shops it within the S3 bucket created for us by means of AWS CloudFormation. The job creates separate folders for database and desk information, as proven within the following screenshot.

Crawl and arrange exterior tables for the metrics information
Comply with these steps to create tables within the database by utilizing AWS Glue crawlers on the info saved on Amazon S3. Be aware that the database has been created for us utilizing the CloudFormation stack.
- On the AWS Glue console, underneath Databases within the navigation pane, select Tables.
- Select Add tables.
- Select Add tables utilizing a crawler.
- Enter a reputation for the crawler and select Subsequent.
- For Add crawler, select Create supply sort.
- Specify the crawler supply sort by selecting Information shops and select Subsequent.
- Within the Add an information retailer part, for Select an information retailer, select S3.
- For Crawl information in, choose Specified path.
- For Embrace path, enter the trail to the
tablesfolder generated by the AWS Glue job:s3://<information bucket created utilizing CFN>/datalake/tables/.
- When requested if you wish to create one other information retailer, choose No after which select Subsequent.
- On the Select an IAM Position web page, choose Select an Present IAM Position.
- For IAM function, select the IAM function created by means of the CloudFormation stack.
- Select Subsequent.
- On the Output web page, for Database, select the AWS Glue database you created earlier.
- Select Subsequent.
- Evaluation your alternatives and select End.
- Choose the crawler you simply created and select Run crawler.
The crawler ought to take just a few minutes to finish. Whereas it’s operating, standing messages could seem, informing you that the system is trying to run the crawler after which is definitely operating the crawler. You possibly can select the refresh icon to test on the present standing of the crawler.
- Within the navigation pane, select Tables.
The desk known as tables, which was created by the crawler, needs to be listed.

Question information with Athena
This part demonstrates the way to question these tables utilizing Athena. Athena is a serverless, interactive question service that makes it straightforward to research the info within the AWS COVID-19 information lake. Athena helps SQL, a standard language that information analysts use for analyzing structured information. To question the info, full the next steps:
- Register to the Athena console.
- If that is your first time utilizing Athena, you have to specify a question consequence location on Amazon S3.
- On the drop-down menu, select the
datalake360dbdatabase. - Enter your queries and discover the datasets.
Arrange and import information into QuickSight and create an operational metrics dashboard
Arrange QuickSight earlier than you import the dataset, and just remember to have no less than 512 MB of SPICE capability. For extra info, see Managing SPICE Capability.
Earlier than continuing, be sure your QuickSight account has IAM permissions to entry Athena (see Authorizing Connections to Amazon Athena) and Amazon S3.
Let’s first create our datasets.
- On the QuickSight console, select Datasets within the navigation pane.
- Select New dataset.
- Select Athena from the checklist of information sources.
- For Information supply title, enter a reputation.

- For Database, select the database that you simply arrange within the earlier step (
datalake360db). - For Tables, choose databases.
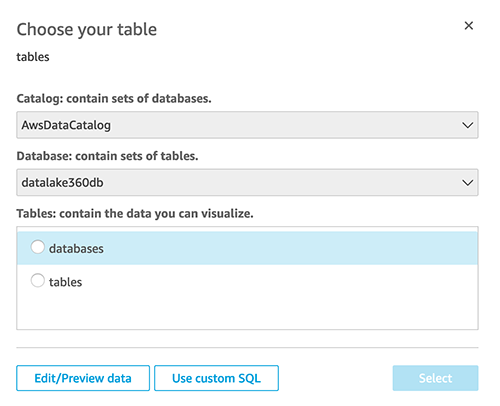
- End creating your dataset..
- Repeat identical steps to create a
tablesdataset.
Now you edit the databases dataset.
- From the datasets checklist, select the
databasesdataset. - Select Edit dataset.

- Change the
createtimearea sort from string up to now.
- Enter the date format as
yy/MM/dd HH:mm:ss. - Select Replace.

- Equally, change the tables dataset fields
createtime,updatetime, andlastaccessedtimeto the date sort. - Select Save and Publish to save lots of the adjustments to the dataset.
Subsequent, we add calculated fields for the depend of databases and tables.
- For the
tablesdataset, select Add calculation.
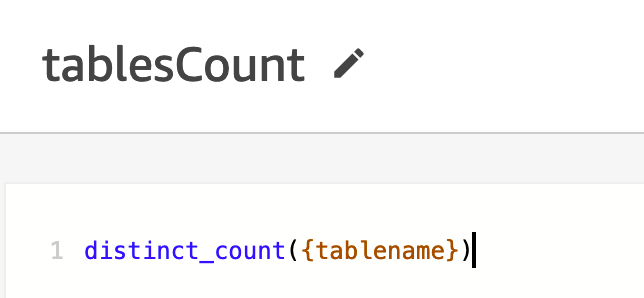
- Add the calculated area
tablesCountasdistinct_count({tablename}.
- Equally, add a brand new calculated area
databasesCountasdistinct_count({databasename}.
{kind=link}
Now let’s create a brand new evaluation.
- Within the navigation pane, select Evaluation.
- Select the
tablesdataset. - Select Create evaluation.

Let’s create our first visible for the depend of variety of databases and tables in our information lake Information Catalog.
- Create a brand new visible and add
databasesCountfrom the fields checklist.
This gives us with a depend of databases in our Information Catalog.
- Equally, add a visible to show the whole variety of tables utilizing the
tablesCountarea.
Let’s create second visible for the whole variety of information on Amazon S3 and complete storage measurement on Amazon S3.
- Much like the earlier step, we add a brand new visible and select the
totalfilesons3andsizeinmbons3fields to show Amazon S3-related storage particulars.
Let’s create one other visible to test that are the least used datasets.
- Add a visible utilizing the
LastAccessTimeinformation ingredient.
Lastly, let’s create another visible to test if databases are shared assets from completely different accounts.
- Choose the
databasesdataset. - We create a desk visible sort and add
databasename,sharedresource, anddescriptionfields.
Now you’ve got an concept of what sorts of visuals are doable utilizing this information. The next screenshot is one instance of a completed dashboard.

Clear up
To keep away from ongoing expenses, delete the CloudFormation stacks and output information in Amazon S3 that you simply created throughout deployment. It’s a must to delete the info within the S3 buckets earlier than you possibly can delete the buckets.
Conclusion
On this publish, we confirmed how one can arrange an operational metrics dashboard in your Information Catalog. We arrange our program to gather key information parts about our tables and databases from the AWS Glue Information Catalog. We then used this dataset to construct our operational metrics dashboard and gained insights on our information lake.
Concerning the Authors
 Sachin Thakkar is a Senior Options Architect at Amazon Internet Companies, working with a number one International System Integrator (GSI). He brings over 22 years of expertise as an IT Architect and as Expertise Advisor for big establishments. His focus space is on Information & Analytics. Sachin gives architectural steering and helps the GSI companion in constructing strategic business options on AWS
Sachin Thakkar is a Senior Options Architect at Amazon Internet Companies, working with a number one International System Integrator (GSI). He brings over 22 years of expertise as an IT Architect and as Expertise Advisor for big establishments. His focus space is on Information & Analytics. Sachin gives architectural steering and helps the GSI companion in constructing strategic business options on AWS
[ad_2]