

{kind=link}
[ad_1]
Our Cloud Suppliers supply Catastrophe Restoration providers and backup and restore providers utilizing all kinds of applied sciences, these are sometimes measured towards one another for his or her related advantages or shortfalls. Particularly, Catastrophe Restoration, there are two key applied sciences that you should utilize to copy information; journaling & snapshots, every has its professionals and cons. On this weblog we are going to go searching every and hopefully detract from a few of the myths round each.
Firstly, snapshots. What are
snapshots?
Snapshots are a cut-off date of the state and information of a Digital Machine
(VM), they shouldn’t be thought-about a backup. The state consists of the VM’s energy
state on the time of snapshot and information consists of all information and folders that
represent the VM, together with VM file gadgets like reminiscence and vNIC, vmdk and many others, this
sometimes is achieved by ‘gorgeous’ the VM or quiescing. (Gorgeous a VM makes
the VM quickly unavailable for operations like vMotion, snapshot, and many others and
unreachable, which means there may be utility outage.)
At all times contemplate the ‘state’ of a replication, if the OS doesn’t assist
quiescing, then you need to be fastidiously contemplating the method to get better in
the occasion of a Catastrophe to make sure continuity on your utility kind – don’t
neglect this!
Why ought to they not be thought-about a backup? Properly merely put, they’re helpful
for a fast rollback level, as they primarily document delta between the unique
supply disk from a sure cut-off date, additionally the mother or father have to be on the identical storage
infrastructure for this to work. Backups should be individually and entire (not
dependant on mother or father), and definitely not on the identical infrastructure they’re
defending from failure. Snapshots are subsequently inherently – brief time period.
Does VMware Cloud Director
Availability use snapshots?
In a nutshell, no, we don’t. We use Delta vmdk on the supply and Level in Time (PIT) situations on the vacation spot, these aren’t the identical as snapshots. A number of Level in Time (PIT), mPIT, are based mostly on deltas from the supply disk, these are despatched through the Host Based mostly Replication agent (HBR) IO Filter on the ESXi host. VMware Cloud Director Availability doesn’t stun the VM for the supply replication subsequently it’s not the identical as a snapshot.
vSphere Replication, has a number of elements which are utilized by VMware
Cloud Director Availability; the Knowledge Mover and the Host Based mostly Replicator (HBR)
providers on ESXi hosts, these basically filter the IO from the operating VM to
the light-weight delta syncs, which is then replicated to the goal website through a
Replicator Equipment. You possibly can have
a number of PITS (mPITS) and vSphere Replication helps 24 situations – that’s 23
light-weight deltas from the preliminary sync earlier than they’re cycled and
overwritten.
For the preliminary sync, solely the written areas of the ‘base’ disk of the
VM are marked as ‘soiled’ and the entire vmdk is copied, this does trigger a small
improve in IO as disk is being replicated, and the time it’s going to take will
rely loads on the supply and goal datastore varieties. From this level on solely delta
adjustments are marked as soiled and needing copy.
Let’s outline what’s an preliminary full
sync
When replication is first configured utilizing
VMware Cloud Director Availability for a powered on digital machine. The complete
contents of a supply digital disk (VMDK) are copied to its goal empty digital
disk (which is created on the goal location), these are in contrast utilizing
checksums. This course of identifies the variations between the supply and
goal digital disks, which in a brand new replication is zero, requiring only a few
CPU cycles. Whereas checksum comparisons are being calculated and in contrast,
vSphere Replication will periodically ship any variations that had been
found. The period of time it takes to finish a full sync primarily
will depend on the dimensions of the digital disk(s) that make up a digital machine, the
quantity of knowledge that have to be replicated, and the community bandwidth accessible for
replication.
How about light-weight delta syncs?
After a full sync is accomplished, the vSphere
Replication agent constructed into vSphere tracks adjustments to digital disks belonging
to digital machines configured for replication. A light-weight delta sync
replicates these adjustments regularly relying on the restoration level
goal (RPO) configured for replication of a digital machine. For instance,
modified information in a digital machine with an RPO of 4 hours can be replicated each
4 hours. Knowledge on the 4hr window will go into the light-weight delta vmdk, so
something added and eliminated inside the 4hrs won’t be within the delta, this
reduces networking visitors as a number of writes to the identical block inside the RPO
interval will solely consequence within the final worth being despatched at sync time. This
schedule can change based mostly on a lot of components reminiscent of information change charges, how
lengthy every replication cycle takes, and what number of digital machines are configured
for replication on the identical vSphere host. vSphere Replication makes use of an algorithm
that considers these components and schedules replication accordingly to assist
make sure the RPO for every replicated digital machine will not be violated.
Thanks @jhuntervmware for the weblog referring to this.
What about efficiency?
The extra light-weight delta sync vmdk you have got, the extra potential variant
information between the deltas, the longer it’s going to take to revive because the extra delta
‘drift’ from the bottom, the extra compute and storage can be wanted to consolidate
all of the variations. Additionally, the extra you keep, the extra disk house can be
used. If the vacation spot datastore runs out of house, no new delta situations
could be created, however the current situations are unaffected. When free house turns into
accessible a brand new incremental occasion is created (albeit probably with some RPO
violation), however there aren’t any re-syncs.
With VMware Cloud Director Availability, we use SLA insurance policies to regulate
what’s allowed for replication retention insurance policies (variety of PIT situations) and
an overarching Restoration Level Goal. Bear in mind a PIT is a light-weight delta sync,
a vmdk delta document, however it’s
not an entire vmdk as there was no gorgeous or cloning, it’s a subset of
the chain from the bottom disk to a designative occasion and is an impartial
flat vmdk.
Light-weight vmdk delta sync are cascading and
interdependent, there for every time an occasion expires some disk house is
freed. You possibly can retire situations explicitly, or you’ll be able to urgently reclaim house
after uncommon I/O occasions that create bigger situations, by adjusting the Cloud
Director Availability retention coverage. It will retire (a.okay.a. consolidate)
the situations. Then you’ll be able to restore your regular retention coverage when the house
is out there. Suppliers can monitor all elements of IAAS consumption and look at storage
allotted vs utilized by tenant group.
Saved situations – are these backups
or snapshots?
Saved Situations in VMware Cloud Director Availability are delta vmdk.
They’re deltas which have been ‘taken out’ of the retention cycle and subsequently
wants the mother or father disk for use for a restore function. A VMware Cloud Director
Availability replication can have each saved situations and rotated situations (mPITS)
and these are managed by insurance policies. These can be comparatively quick to revive
compared with ongoing deltas (they are going to be nearer to the supply mother or father)
that can develop (‘drift’) as time strikes on.
Does consolidating disks assist improve
restoration velocity?
Sure and no. Consolidating takes the bottom disk and all of the deltas into
account, this disk hierarchy consolidation course of runs to the restore level
required. It’s a compute and storage intensive activity to mixture and evaluate
the deltas, and from that time on all deltas are created with the consolidated
disk because the mother or father. For a failover, consolidating when there’s a disk
hierarchy of deltas won’t be faster if there are numerous delta vmdk
to check, particularly if there’s a excessive information change price. Nevertheless, from that
level on restoration can be quick because the ‘drift’ between the bottom vmdk and delta
vmdk can be much less. VMware Cloud Director Availability lets you power
consolidation as part of restoration, or later whatever the VM energy state.
What about RPO & RTO?
Some distributors state a really quick RPO with journaling, that is true the place
each modified information block is written continuously to the goal, why then would I
use delta situations? The everyday VM generates invaluable information that must be
replicated, utilizing break up IO whereby IO goes to 2 factors; the VM and the goal
restoration delta or journal, there may be nearly zero restoration time goal
(RTO), till information is generated. After all, information is generated, in any case you might be
guaranteeing restoration of an essential workload, so there may be little probability it’s going to
keep nonetheless. When information is generated, journaling, which delivers final
granularity, significantly will increase in RTO, the extra information written, the longer
the restoration time goal (RTO) to consolidate. With MPITs there may be additionally an
RTO affect, the affect is as massive because the time to compute the delta distinction
between the supply mother or father and the specified MPIT to revive, not like journaling,
many of the consolidation can be already completed within the delta. As already said,
the extra MPITs in between the longer the RTO. Bear in mind the information remains to be at a granular
RPO (VMware Cloud Director Availability helps 5min RPO), however the time to
restore (RTO) is longer as compute is required in each journaling and MPITs to
get better the information.
A very good rule of thumb for top information intensive workloads can be to consolidate often and preserve the variety of MPITs low so they’re by no means too distant from the mother or father base disk. For low information intensive VMs you’ll be able to considerably increase the variety of MPITs and consolidate on rotation as required.
One other level to notice about RPO and information technology. When information runs
although the IO Filter, it’s directed to the VM datastore and (relying on the
know-how you might be utilizing) to a light-weight delta vmdk or to a journal. The
path to that vacation spot must be quick, particularly for journaling and the
visitors quantity can be excessive if each block of knowledge change is being written
24/7. Nevertheless, Delta situations solely execute on the replication schedule, therefore
visitors is low and quantity of knowledge is low, normally this radically simplifies
networking and makes for a a lot less complicated deployment and operational answer to
assist.
The consideration?
Velocity of restoration (RTO) and acceptable information loss (RPO) for a VM
vs
Minimizing information loss (RPO), however rising restoration time (RTO)
What about rehydration?
Similar to animals have to rehydrate, so too information, which must be
accessible, must be decompressed to be helpful. Some distributors level out that the
restoration rehydration course of is ‘prompt’, there is no such thing as a ‘prompt’ in
decompression, which makes use of compute; impacts efficiency and disk space for storing
utilization. When information is rehydrated the information blocks are rendered on the disk
of their unique type. This may be ‘optimized’ to negate long run disk affect
by distributors supporting rehydrate on learn features, nevertheless this can nonetheless
have an effect on the storage used while the information is rehydrated.
Journaling has a
rehydration course of that’s compute and storage intensive (imitates file system
and must convert information to vSphere format) so, in abstract, there may be an affect
on efficiency to make use of journaling with rehydration.
VMware Cloud Director Availability makes use of native vmdk, so there is no such thing as a have to covert the information to a vmdk format, it’s already on this format and therefore is optimized out of the field.
Firstly, let’s
have a look at the restoration level. Journaling tech provides granular flexibility in
restoration, as restoration could be instantiated from any level. Whereas PITs are set
at common intervals.
Let’s take an instance, your VM has a 4hr RPO, you uncover ransomware in your VM at 12.30 submit infestation (level B) on the graph under.
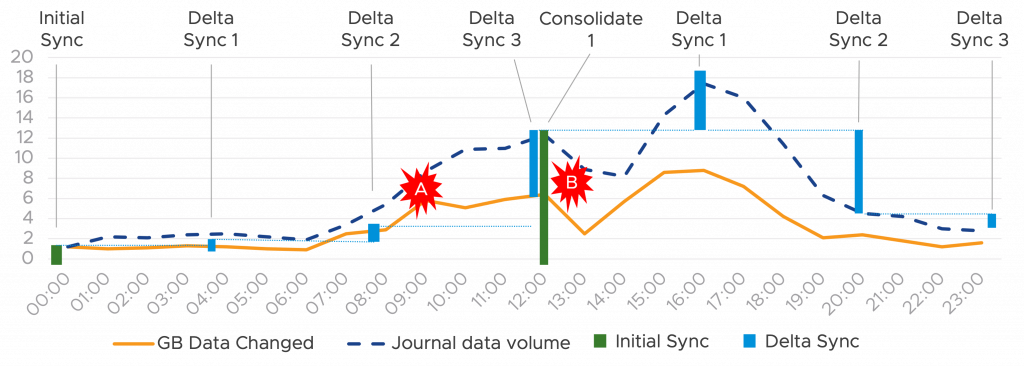
The precise
an infection was delivered by a malicious program at 9AM however didn’t activate till 13:00.
Subsequently, the ransomware malicious program was replicated within the light-weight delta
sync at Noon, you would want to return to the earlier delta 4hrs earlier than at
8AM, which means 4hrs of knowledge is misplaced, however the ransomware wouldn’t be current. Is 4hr
information loss acceptable? That is the granularity affect and aligned to RPO.
Nevertheless, the velocity of restoration is essential, on this case you have got a number of restore factors to select from. You’d begin with a restore the earlier delta, which on this case is a consolidated vmdk, not a delta, and therefore the compute comparability towards modified blocks on the consolidated delta can be nothing as there may be nothing to check. This might be a quick restoration, however the Malicious program remains to be current. Going again to the subsequent delta can be at 8:00AM and wouldn’t comprise the malicious program, this could should be in contrast towards the final deltas and consolidated supply disk, however given the amount of delta adjustments is small, once more this could be a quick RTO. Though you have got some information loss you might be up and operating once more quick.
As a rule, the granularity
RPO needs to be aligned to the criticality of the VM. VMware Cloud Director
Availability helps a 5min RPO, however the precise restoration time can be the important thing
distinction and that might rely how far the delta is away from the supply
consolidated disk. Holding the variety of restoration factors low will guarantee
a sooner restoration as consolidation will occur sooner and there may be much less information
drift between supply and the final delta. Our suggestion is to search out an
acceptable RPO and variety of mPIT, then use backup to take a everlasting copy.
Journaling then again gives 100% granularity, with each block modified, replicated, there may be potential for zero information loss, however this doesn’t enable for utility consistency, as with light-weight delta, until quiescing is used (and even then) there is no such thing as a assure of success, notably with reminiscence resident purposes. As I discussed at the beginning of the weblog, ‘all the time contemplate the ‘state’ of a replication’.
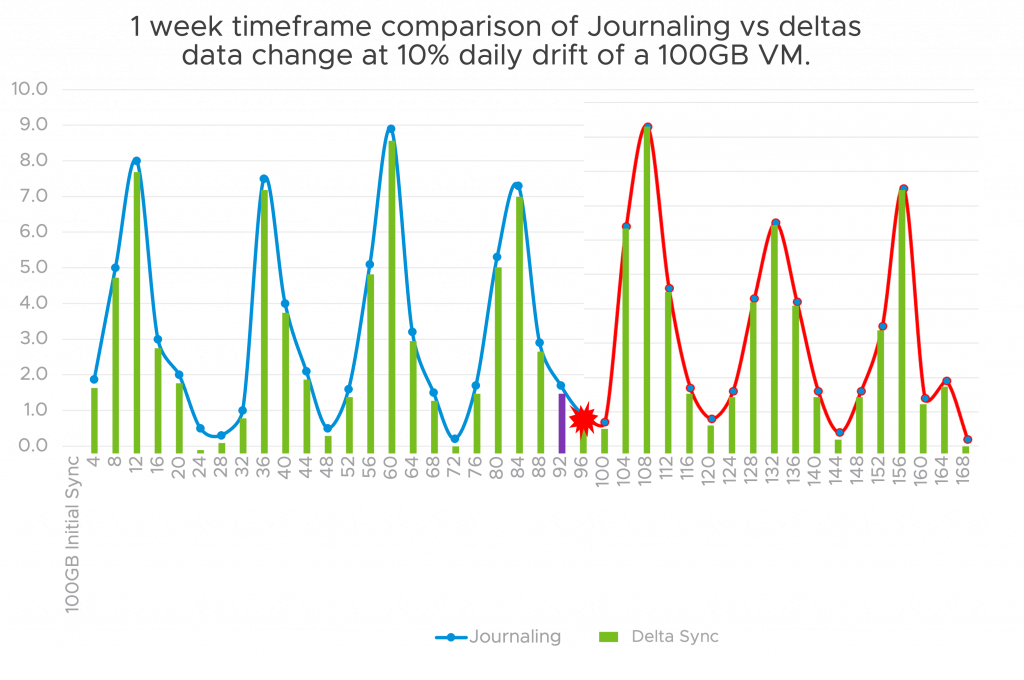
Nevertheless, with
journaling you’ll be able to rewind and get better from any cut-off date, if there was
malware detected within the chart above, you could possibly ‘rewind’ to any level on the
blue line, earlier than the occasion. You can even do file degree restore, which is an
benefit over light-weight delta. As you’ll be able to see the deltas solely run on the 4hr
window and never constantly like journals, therefore the closest delta would then
be measured towards the supply vmdk on the final consolidation. As with
every part there’s a tradeoff; journaling can carry granularity, however at what
price?
- Networking: Journaling requires quick
community speeds to repeat every byte, that is usually completed domestically to keep away from this
overhead, additionally usually journal information can be compressed at supply; that is wanted
to attenuate bandwidth necessities. This provides the added potential to get better domestically
additionally and sooner, however that is depending on the kind of catastrophe you might be
recovering from. Quicker networks price extra and are extra complicated, this implies you
can count on to spend extra for this answer. A core distinction with Light-weight
Deltas is that a number of writes to the identical block inside the RPO interval will
lead to solely the final worth being despatched. This reduces the community utilization.
- Storage: while each use storage, the quantity used will rely upon the granularity of sync, the extra granular the extra information must be saved. On this case journaling will create essentially the most storage overhead as on the goal website the information disk + the journal can be stored, however the flip facet is a extra granular restore functionality.
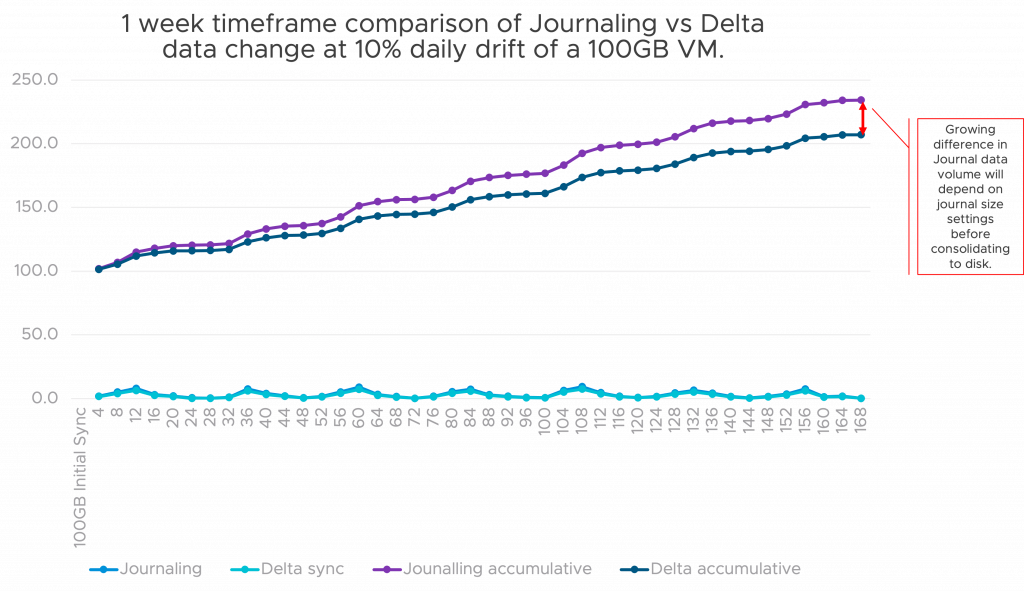
Because the diagram above
reveals, while the amount of knowledge for journaling
and Delta sync processes will not be actually a storage issue (extra a networking one),
the aggregated storage quantity is. The additional alongside the timeframe, the extra
there’s a distinction between aggregated storage of journal vs delta.
Be aware that this
will not be together with any deduplication storage applied sciences on the goal website however
is an correct illustration of quantity.
Hopefully what I
have laid out is that there is no such thing as a easy reply to this, a lot of the
efficiency will depend on the information change price you should have and the granularity
of restore you need. Don’t be mistaken. There isn’t any clear winner, every strategy
to replication and restoration has constructive and damaging factors, and there’s a
industrial price that I’ve not explored right here additionally.
I believe the
main take house to make is that there is no such thing as a actual per second RPO (with out synchronous
replication with costly storage arrays and really expensive networking), this
solely exists if there is no such thing as a information change, after which, that might maybe apply to
all merchandise. Would the quickest be the native VMDK answer that doesn’t want
conversion? It’s a moot level as there may be little or no probability of zero information
change in actuality.
Actuality means giant volumes of knowledge, actuality means unpredictable
eventualities, actuality means communication ups and downs, and surprising spikes in
utilization. Similar to your cloud selections, it’s the precise DR answer for the
workload, that’s what is essential. Bear in mind
the important thing levers:
- Compute assets: Journaling will in all probability require extra compute than deltas however that is depending on consolidation schedules. Holding smaller journals and fewer deltas will decrease compute overhead when comparability operations are required for restore.
- Storage: Once more, the
extra granularity, the extra storage wanted. You’ll want to assign the proper degree
of granularity to the VM criticality.
- Community: Journaling,
replicating off website constantly might want to have assigned bandwidth reserved
in order that replication will not be affected. Native replication will decrease WAN prices
however won’t present regional safety.
- Granularity
RPO: How
a lot are you able to afford to lose? Nothing, then journaling is your reply, 5 min or
extra, then light-weight deltas can be an acceptable answer. Once more, you’ll want to
assign the proper degree of granularity to the VM criticality.
- Time to
get better RTO: For Deltas, this can be depending on information drift and the quantity
of deltas between the final one and the final consolidated vmdk. For journaling
this can once more be depending on the quantity of journal information that must be
consolidated and transformed to vmdk format.
As with many
technical options, there is no such thing as a proper and mistaken about journaling or deltas,
these are simply the everyday DR replication varieties. There may be nevertheless a value
consideration, in case you want the granularity of journaling, then there may be probably
to be greater prices in storage and critically networking.
[ad_2]