
{kind=link}
[ad_1]
AWS Glue DataBrew gives over 250 pre-built transformations to automate knowledge preparation duties (corresponding to filtering anomalies, standardizing codecs, and correcting invalid values) that might in any other case require days or even weeks writing hand-coded transformations.
Now you can write cleaned and normalized knowledge instantly into JDBC-supported databases and knowledge warehouses with out having to maneuver giant quantities of information into middleman knowledge shops. In only a few clicks, you’ll be able to configure recipe jobs to specify the next output locations: Amazon Redshift, Snowflake, Microsoft SQL Server, MySQL, Oracle Database, and PostgreSQL.
On this put up, we stroll you thru join and rework knowledge from an Amazon Easy Storage Service (Amazon S3) knowledge lake and write ready knowledge instantly into an Amazon Redshift vacation spot on the DataBrew console.
Answer overview
The next diagram illustrates our answer structure.

In our answer, DataBrew queries gross sales order knowledge from an Amazon S3 knowledge lake and performs the information transformation. Then the DataBrew job writes the ultimate output to Amazon Redshift.
To implement the answer, you full the next high-level steps:
- Create your datasets.
- Create a DataBrew challenge with the datasets.
- Construct a metamorphosis recipe in DataBrew.
- Run the DataBrew recipe.
Stipulations
To finish this answer, you need to have an AWS account. Be sure you have the required permissions to create the sources required as a part of the answer.
For our use case, we use a mock dataset. You’ll be able to obtain the information recordsdata from GitHub.
Full the next prerequisite steps:
- On the Amazon S3 console, add all three CSV recordsdata to an S3 bucket.
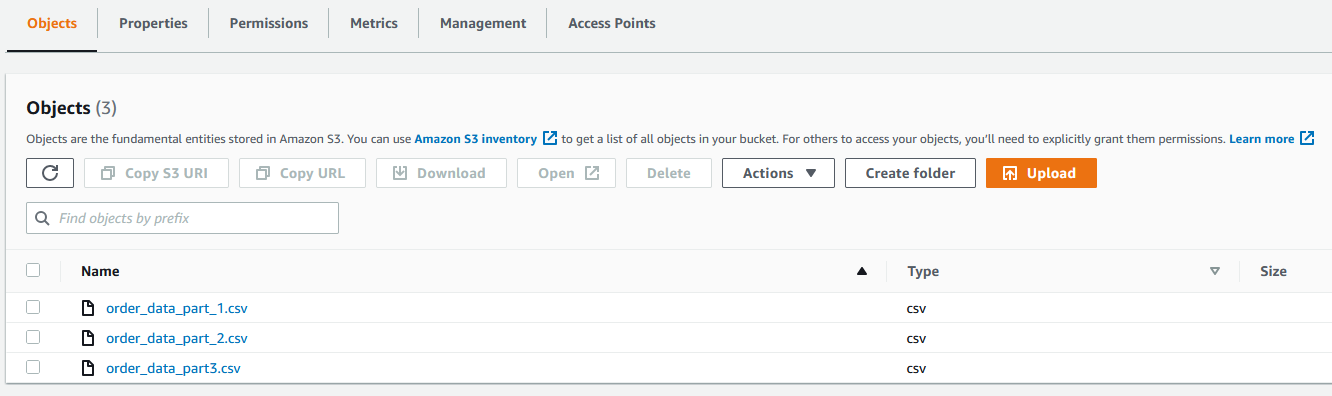
- Create the Amazon Redshift cluster to seize the product sensible gross sales knowledge.
- Arrange a safety group for Amazon Redshift.
- Create a schema in Amazon Redshift if required. For this put up, we use the prevailing
publicschema.
Create datasets
To create the datasets, full the next steps:
- On the Datasets web page of the DataBrew console, select Join new dataset.

- For Dataset title, enter a reputation (for instance,
order). - Enter the S3 bucket path the place you uploaded the information recordsdata as a part of the conditions.
- Select Choose the whole folder.
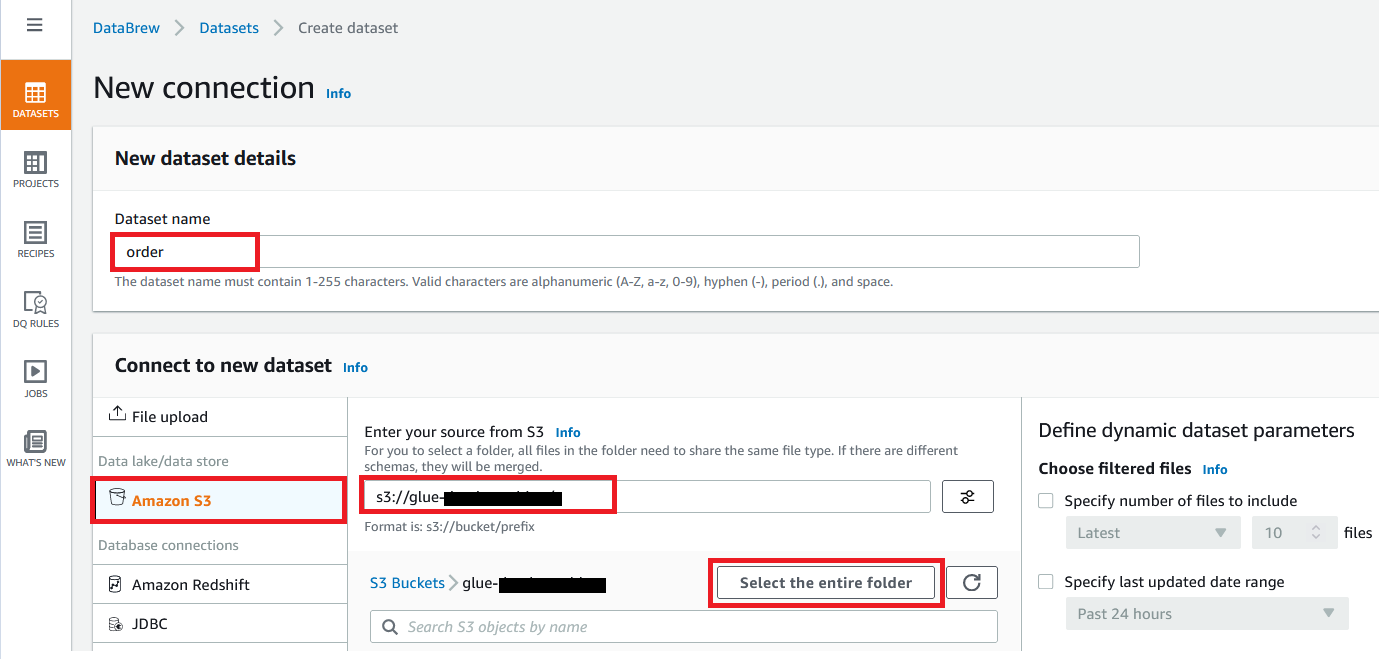
- For Chosen file sort, choose CSV.
- For CSV delimiter, select Comma.
- For Column header values, choose Deal with first row as header.
- Select Create dataset.

Create a challenge utilizing the datasets
To create your DataBrew challenge, full the next steps:
- On the DataBrew console, on the Tasks web page, select Create challenge.

- For Undertaking Title, enter
order-proj. - For Connected recipe, select Create new recipe.
The recipe title is populated mechanically.
- For Choose a dataset, choose My datasets.
- Choose the
orderdataset.
- For Position title, select the AWS Id and Entry Administration (IAM) position for use with DataBrew.
- Select Create challenge.
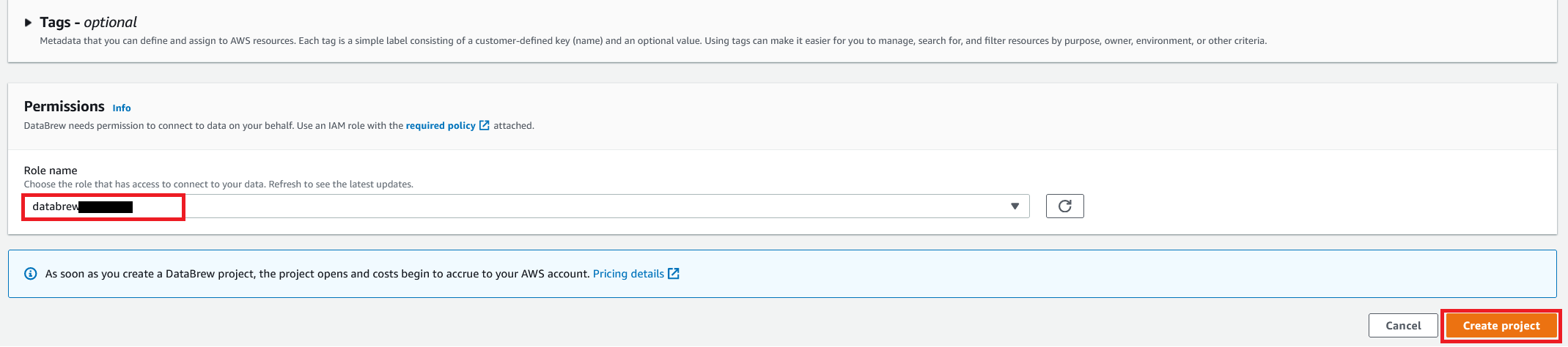
You’ll be able to see successful message together with our Amazon S3 order desk with 500 rows.
After the challenge is opened, a DataBrew interactive session is created. DataBrew retrieves pattern knowledge based mostly in your sampling configuration choice.
Construct a metamorphosis recipe
In a DataBrew interactive session, you’ll be able to cleanse and normalize your knowledge utilizing over 250 pre-built transformations. On this put up, we use DataBrew to carry out a couple of transforms and filter solely legitimate orders with order quantities better than $0.
To do that, you carry out the next steps:
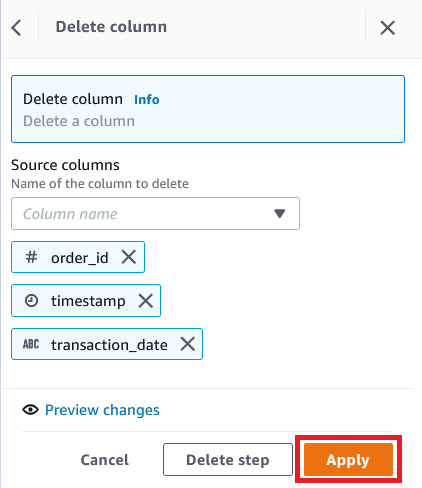
- On the Column menu, select Delete.

- For Supply columns, select the columns
order_id,timestamp, andtransaction_date. - Select Apply.
- We filter the rows based mostly on an
quantityworth better than $0. - Select Add to recipe so as to add the situation as a recipe step.
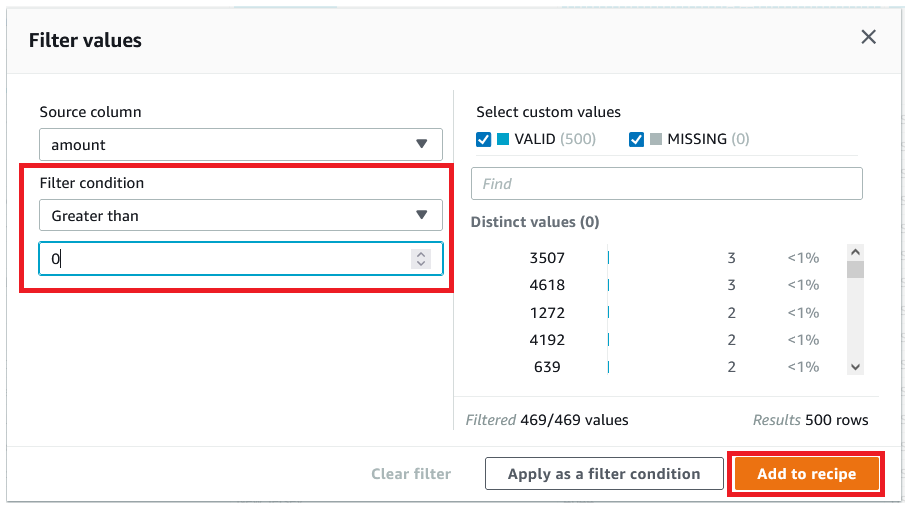
- To carry out a customized kind based mostly on state, on the Kind menu, select Ascending.

- For Supply, select
state_name. - Choose Kind by customized
values. - Specify an ordered record of state names separated by commas.
- Select Apply.

The next screenshot reveals the total recipe that we utilized to our dataset.
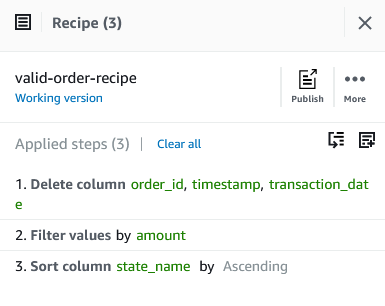
Run the DataBrew recipe job on the total knowledge
Now that we now have constructed the recipe, we are able to create and run a DataBrew recipe job.
- On the challenge particulars web page, select Create job.
- For Job title, enter
product-wise-sales-job.
- For Output to, select JDBC.
- For connection title, select Browse.
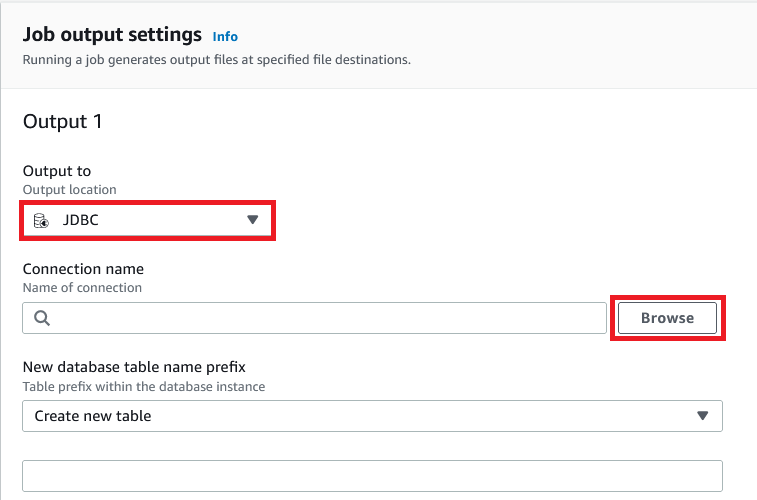
- Select Add JDBC connection.

- For Connection title, enter a reputation (for instance,
redshift-connection). - Present particulars just like the host, database title, and login credentials of your Amazon Redshift cluster.

- Within the Community choices part, select the VPC, subnet, and safety teams of your Amazon Redshift cluster.
- Select Create connection.

- Present a desk prefix with schema title (for instance,
public.product_wise_sales).
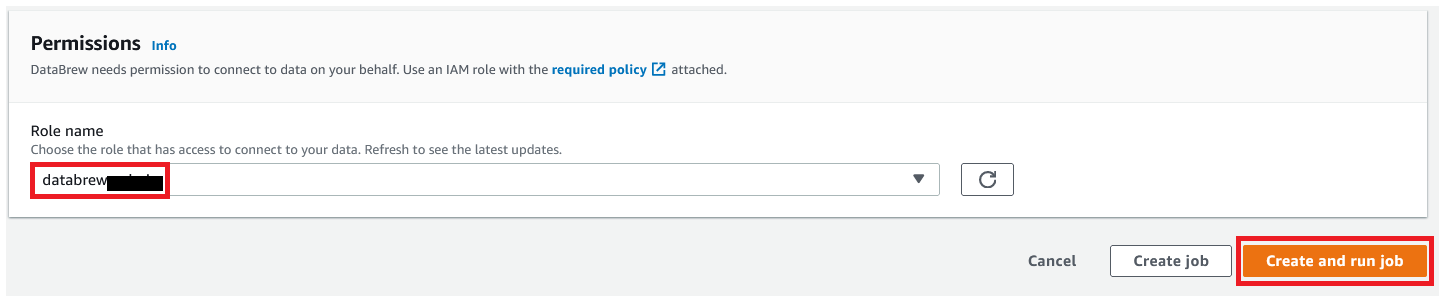
- For Position title, select the IAM position for use with DataBrew.
- Select Create and run job.
- Navigate to the Jobs web page and watch for the
product-wise-sales-jobjob to finish.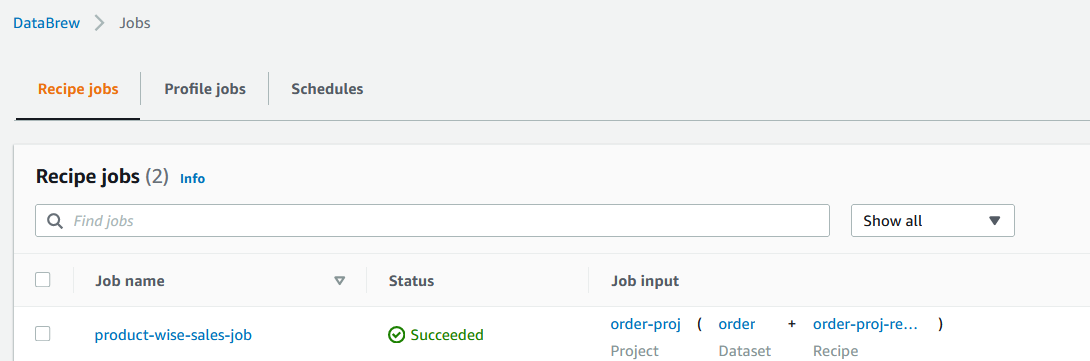
- Navigate to the Amazon Redshift cluster to substantiate the output desk begins with
product_wise_sales_*.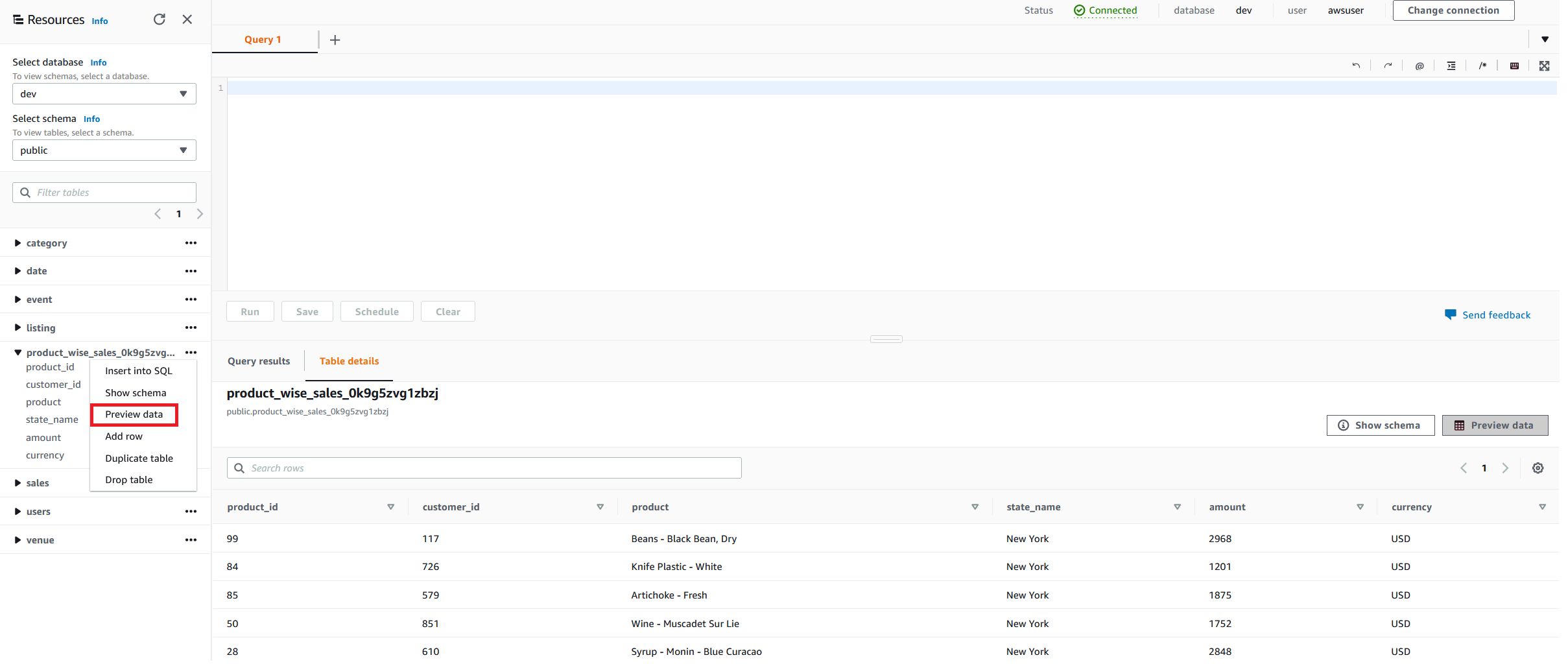
Clear up
Delete the next sources that may accrue price over time:
- The Amazon Redshift cluster
- The recipe job
product-wise-sales-job - Enter recordsdata saved in your S3 bucket
- The job output saved in your S3 bucket
- The IAM roles created as a part of tasks and jobs
- The DataBrew challenge order-proj and its related recipe
order-proj-recipe - The DataBrew datasets
Conclusion
On this put up, we noticed join and rework knowledge from an Amazon S3 knowledge lake and create a DataBrew dataset. We additionally noticed how simply we are able to carry knowledge from an information lake into DataBrew, seamlessly apply transformations, and write ready knowledge instantly into an Amazon Redshift vacation spot.
To be taught extra, check with the DataBrew documentation.
Concerning the Writer
 Dhiraj Thakur is a Options Architect with Amazon Net Providers. He works with AWS prospects and companions to supply steering on enterprise cloud adoption, migration, and technique. He’s enthusiastic about know-how and enjoys constructing and experimenting within the analytics and AI/ML area.
Dhiraj Thakur is a Options Architect with Amazon Net Providers. He works with AWS prospects and companions to supply steering on enterprise cloud adoption, migration, and technique. He’s enthusiastic about know-how and enjoys constructing and experimenting within the analytics and AI/ML area.
 Amit Mehrotra is a Answer Structure chief with Amazon Net Providers. He leads an org that prospects cloud journey.
Amit Mehrotra is a Answer Structure chief with Amazon Net Providers. He leads an org that prospects cloud journey.
[ad_2]