

{kind=link}
[ad_1]
Voice Fingerprints in Webex
Speaker Diarization solutions the query, “Who spoke when?” At present, audio system in a gathering are recognized via channel endpoints whether or not via PSTN or VOIP. When audio system in the identical assembly are talking from the identical room/machine, they’re recognized as one speaker within the assembly transcript. As a result of Webex Conferences recordings are supplied with transcriptions, with the ability to reply “Who spoke when?” would permit colleagues who might need missed the assembly to shortly meet up with what was stated in addition to present computerized highlights and summaries. That is very helpful, however with out figuring out who stated what, it’s harder for people to skim via the content material, and for AI options to supply extra correct outcomes.
Overview of our resolution
- A Fingerprint in your voice: we’ll talk about our strategy to constructing the deep neural community answerable for reworking audio inputs to voice fingerprints.
- Clustering: after reworking a sequence of audio inputs in a sequence of voice fingerprints, we’ll present how we solved the issue of assigning a speaker label to every phase and group segments from the identical audio system collectively.
- Information pipeline: all AI fashions require information in an effort to study the duty and on this part we’ll share insights on the info we’ve obtainable and the methods we adoped to label it mechanically.
- Integration with Webex: On this part we’ll discuss concerning the work we’ve performed in an effort to deploy the speaker diarization system to manufacturing as a further module to our assembly transcriptions pipeline.
Speaker Diarization in 3 steps
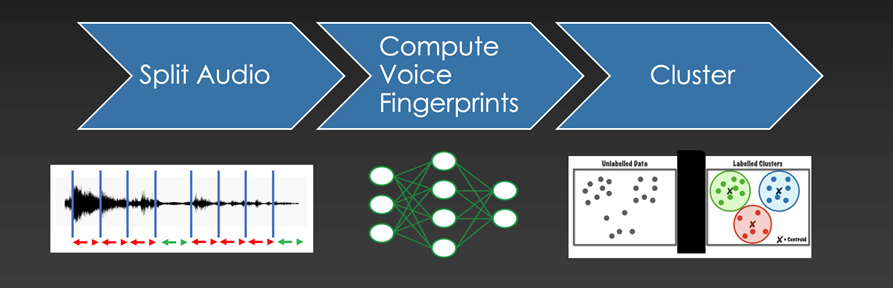 Assigning speaker labels to an audio file might be divided into 3 steps
Assigning speaker labels to an audio file might be divided into 3 steps
Assigning speaker labels
The method to assign speaker labels to an audio file is straightfoward and might be divided into 3 steps:
- Cut up Audio: The very first thing we wish to do is to separate the audio enter into smaller audio chunks of the identical size, and discard all segments that don’t comprise voice. We’re due to this fact discarding silence and background noise. We use an off the shelf resolution: WebRTC Voice Exercise Detector.
- Compute Voice Fingerprints: The following step includes reworking every audio chunk to a “Voice Fingerprint”. These fingerprints are 256-dimensional vectors, i.e. an inventory of 256 numbers. The target is to be sure that vectors produced from totally different audio chunks belonging to the identical speaker can be related to one another in response to some mathematical measurement.
- Cluster related vectors collectively: The result of the earlier step produces an inventory of 256-dimensional vectors for every voiced phase. The target of this step is to group collectively segments which might be related to one another.
Computing Voice Fingerprints
The aim and the options
We don’t wish to prohibit the standard of the diarization based mostly on language, accent, gender or age as a result of conferences can happen in assorted settings with totally different microphones and background noises. We designed the neural community accountable to compute the voice fingerprints to be strong to those components. That is made attainable by choosing the right neural structure, an enormous quantity of coaching information, and information augmentation methods.
The structure
The structure of the neural community might be cut up into 2 elements: preprocessing and have extraction. The preprocessing half transforms the 1-dimensional audio enter right into a 2-dimensional illustration. The usual strategy is to compute the Spectrogram or the Mel-frequency cepstral coefficients (MFCCs). Our strategy is to let the neural community study this transformation as a sequence of three 1-D convolutions. The reasoning behind this alternative is twofold. First off, given sufficient information, our hope is that the transformation can be of upper high quality for the downstream job. The second cause is sensible. We export the community to the ONNX format in an effort to pace up inference and as of now the operations wanted to compute the MFCCs will not be supported.
For the function extraction we depend on a standard neural community structure generally used for Pc Imaginative and prescient duties: ResNet18. We modified the usual structure to enhance efficiency and to extend inference pace.
Clustering: assigning a label to every speaker
The aim of this step is to assign a label to every audio phase in order that audio segments from the identical speaker will get assigned the identical label. Grouping collectively is finished by function similarity and is less complicated stated than performed. For instance: given a pile of Lego Blocks how would we group them? It might be by coloration, by form, by measurement, and so forth… Moreover, the objects we wish to group may even have options that aren’t simply recognizable. For our use case, we try to group collectively 256-dimensional vectors, in different phrases “objects” with 256 options, and we’re relying on the neural community answerable for producing these vectors to do job. On the core of every clustering algorithm there’s a solution to measure how related two objects are. For our case we measure the angle between a pair of vectors: cosine similarity. The selection of this measurement shouldn’t be random however is a consequence of how the neural community is skilled.
Clustering might be performed on-line or offline
On-line clustering signifies that we assign a speaker label to a vector in actual time as an audio chunk will get processed. On one hand, we get a outcome instantly and this may be helpful for stay captioning use instances for instance. Then again, we will’t return in time and proper labeling errors. If the generated voice fingerprints are of top of the range, the outcomes are normally good. We worker a simple grasping algorithm: as a brand new vector will get processed, we assign it to a brand new or an current bucket (assortment of vectors). That is performed by measuring how related the brand new vector is to the typical vector in every bucket. Whether it is related sufficient (based mostly on a specific similarity threshold), the vector can be added to essentially the most related bucket. In any other case, it will likely be assigned a brand new bucket.
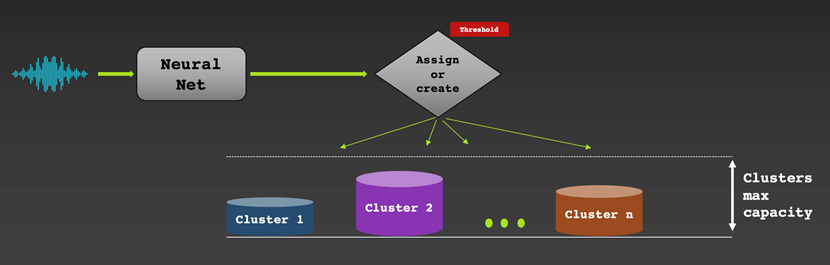
Offline clustering signifies that we assign a speaker label to every vector after we’ve entry to the whole audio. This permits the algorithm to shuttle in time to seek out the most effective speaker label project, sometimes outperforming on-line clustering strategies. The draw back is that we have to look ahead to the complete audio recording to be obtainable which makes this method not appropriate for real-time transcriptions. We base our strategy on Spectral Clustering. With out going into an excessive amount of element, since it is a widespread approach, we selected this explicit methodology as a result of it’s strong for the actual information we’ve. Extra importantly, it is ready to estimate the variety of audio system mechanically. This is a vital function since we aren’t given the variety of speaker/clusters beforehand.
Information Pipeline
The spine of the neural audio embedder and the clustering algorithm described above is the info used to coach it and fortunately we’re in an incredible state of affairs in that regard. We work intently on diarization with the Voicea workforce inside Cisco, who’re answerable for dealing with assembly transcription in Webex. Throughout that course of, they save audio segments from conferences that they detect speech in and make them obtainable for obtain. Every saved phase is mechanically labeled in response to the machine it comes. This permits us to make use of these audio segments to coach our speaker embedder on a speaker recognition job. As a result of excessive quantity of conferences which might be hosted on WebEx we’re capable of acquire a substantial amount of information and the quantity continues to extend over time.
One bundle that helps us collaborate effectively whereas working with this amount of information is DVC, quick for Information Model Management. DVC is an open-source software for model management on datasets and fashions which might be too massive to trace utilizing git. Once you add a file or folder to DVC, it creates a small .dvc file that tracks the unique via future modifications and uploads the unique content material to cloud storage. Altering the unique file produces a brand new model of the .dvc file and going to older variations of the .dvc file will can help you revert to older variations of the tracked file. We add this .dvc file to git as a result of we will then simply change to older variations of it and pull previous variations of the tracked file from the cloud. This may be very helpful in ML initiatives if you wish to change to older variations of datasets or determine which dataset the mannequin was skilled on.
One other good thing about DVC is performance for sharing fashions and datasets. Every time one particular person collects information from the Voicea endpoint so as to add to the speaker recognition dataset, so long as that particular person updates the .dvc file and pushes it, the opposite particular person can seamlessly obtain the brand new information from the cloud and begin coaching on it. The identical course of applies for sharing new fashions as nicely.
Integration with Webex
Assembly Recordings Web page
The primary WebEx integration for our diarization mannequin was on the assembly recordings web page. This web page is the place individuals can see a replay of a recorded assembly together with transcriptions supplied by Voicea. Our diarization is built-in inside Voicea’s assembly transcription pipeline and runs alongside it after the assembly is completed and the recording is saved. What we add to their system is a speaker label to every audio shard that Voicea identifies and segments. The aim for our system is that if we give one audio shard a label of X, the identical speaker producing an audio shard later within the assembly will even obtain a label of X.
There have been vital efforts devoted to enhancing runtime of the diarization in order that it match inside a suitable vary. The largest affect was altering the clustering to work when splitting up a gathering into smaller chunks. As a result of we run eigendecomposition throughout the spectral clustering, the runtime is O(n^3) in follow, which leads to prolonged runtimes and reminiscence points for lengthy conferences. By splitting the assembly into 20-minute chunks, operating diarization on every half individually, and recombining the outcomes, we’ve a slight accuracy commerce off for big reductions in runtime.
Publish Assembly Web page
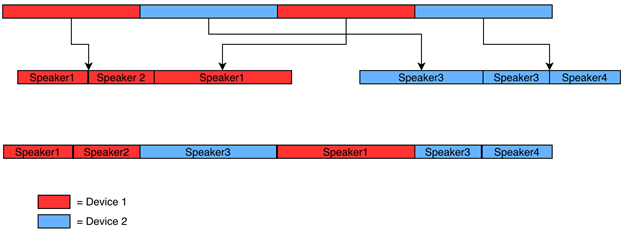
The opposite integration with WebEx is diarization for the post-meeting web page. This web page is proven immediately after a gathering and comprises transcription info as nicely. The primary distinction from the earlier integration is that we’ve info on which machine every audio phase comes from. What this implies is that we will do diarization individually for every audio endpoint and keep away from errors the place our mannequin predicts the identical speaker for audio that got here from totally different units.
This diagram exhibits how this works in follow. The pink segments are from machine 1, the blue segments are from machine 2, and there are 2 audio system in every machine. We first group up all of the audio from every machine and run the diarization individually for every group. This provides us timestamps and speaker labels inside every single machine grouping. We hold monitor of the time offset of every phase as it’s grouped by machine and use that to remodel the speaker label instances from the machine grouping to what they’re within the unique, full assembly.
The post-meeting integration can also be deployed throughout the Voicea infrastructure on Kubernetes. Our service is deployed as a Flask app inside a docker picture that interfaces with a number of different micro companies.
Venture vo-id
We will do extra
What you’ll be able to construct with Neural Voice Embedder doesn’t cease with Speaker Diarization.
You probably have some name-labelled audio samples from audio system which might be current within the conferences you wish to diarize, you can go one step additional and supply the proper title for every phase.
Equally, you can construct a voice authentication/verification app by evaluating an audio enter with a database of labelled audio segments.
Venture vo-id
We needed to make it simple for builders to get their fingers soiled and shortly construct options across the speaker diarization and recognition area. Venture vo-id (Voice Identification) is an open-source undertaking structured to let builders with totally different experience in AI to take action. The README cointains all the knowledge wanted. To present you an instance, it takes solely 4 traces of code to carry out speaker diarization on an audio file:
audio_path = "assessments/audio_samples/short_podcast.wav" from void.voicetools import ToolBox # Depart `use_cpu` clean to let the machine use the GPU if obtainable tb = ToolBox(use_cpu=True) rttm = tb.diarize(audio_path)
Coaching your individual Voice Embedder
We supplied a skilled neural community (the vectorizer), however you probably have the sources, we made it attainable to replace and practice the neural community your self: all the knowledge wanted is obtainable within the README.
Associated sources
We’d love to listen to what you assume. Ask a query or depart a remark beneath.
And keep linked with Cisco DevNet on social!
Twitter @CiscoDevNet | Fb | LinkedIn
Go to the brand new Developer Video Channel
Share:
[ad_2]