
[ad_1]
DAN THAT IS A MOUTHFUL!
In one other life I used to be an educational random web particular person, cope with it and transfer on.
So a few members of the group have been pushing me to doc the Native web optimization Information method to web optimization and a subject got here up internally over the previous few weeks that I believe is a superb instance. I believe the psychological mannequin we have now for approaching SERPs and rankings is damaged. Particularly, it’s inflicting folks to misconceive method web optimization as a self-discipline and it’s all our personal fault for the push to make every thing shortly comprehensible and non-complex. Advanced issues are complicated, it’s okay. Simply to be upfront, I’m not going to supply you a brand new heuristic within the context of this piece, I’m simply right here posing issues.
Background
We have to get some conceptual foundations constructed up earlier than we are able to knock them down.
First, it’s vital to know two vital ideas for this submit:
False Precision: Utilizing implausibly exact statistics to provide the looks of fact and certainty, or utilizing a negligible distinction in information to attract incorrect inferences.
Cognitive Bias: A scientific error in pondering that happens when individuals are processing and decoding info on the planet round them and impacts the selections and judgments that they make.
On our psychological mannequin of SERPs; I believe it’s fairly non-controversial to say that most individuals within the web optimization house have a heuristic of SERPs primarily based on these 3 issues:
- Outcomes are ordered by positions (1-10)
- Outcome are incremented by items of 1
- Outcomes scale equally (1 and a pair of are the identical distance from one another as 3 and 4, 4 is 3 items away from place 1 and so forth)
That is so completely and utterly incorrect throughout all factors:
- Outcomes are ordered by match to an info retrieval system (e.g. greatest match, and various matches and so forth). There are theoretically a number of totally different “greatest solutions” within the 10 blue hyperlinks. Greatest information website, greatest business website, greatest recipe and so forth.
- Outcomes are ordered by nevertheless “apt” the net doc is at answering the question. Not even near some linear 1-10 rating system. Under is a screenshot of the Data Base Search API returns matches for “tacos” with the scores of the 2nd and third outcomes highlighted:
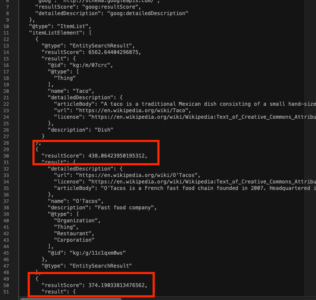
If you wish to do a deep dive into this, Dr. Ricardo Baeza-Yates has you lined right here in his 2020 RecSys Keynote on “Bias on Search and Recommender Techniques”. - This logically follows from the earlier level. Per the screenshot of Data Base Search outcomes for “tacos” we are able to see the space between search outcomes will not be really 1. The space between place “2” and place “3”, highlighted within the screenshot above, is 64. That is going to be REALLY vital later.
Further Essential Data
The web and key phrases are an extended tail distribution mannequin. Here’s a background piece on how info retrieval specialists take into consideration tackle that in recommender techniques.

Graph of Lengthy Tail Distribution
~18% of key phrase searches every single day are by no means earlier than seen key phrases searches.
Many SERPs are unimaginable to disambiguate. For instance, “cake” has native, informational, baking and eCommerce websites that present “apt” outcomes for variations of “cake” in the identical SERP.
Implications
So I first began diving into all this when working with statisticians on our quantitative analysis round native search rating elements round 5 years in the past, and it has a number of implications with reference to decoding SERP outcomes. One of the best instance is relating to rank monitoring.
There’s an assumption made about how a lot nearer place 5 is to place 1 than place 11 however that is completely and utterly obfuscated by the visible layer of a SERP. As I illustrate with Google Data Base API search, machines match phrases/paperwork primarily based on their very own standards which is explicitly not a 1-10 scale. With this in thoughts and understanding that enormous techniques like search are lengthy tail, that signifies that plenty of “unhealthy”, low scoring outcomes, are nonetheless the “greatest” match for a question.
In these situations of the 18% of every day queries which can be new situations each search end result might be very shut in rankability in place 1, separated by small variations. This implies it might be simply as simple to maneuver from place 7 to place 1 for plenty of queries as it’s simple for them to maneuver from place 12 to 1.

Utilizing the instance above, saying that positions 7-10 are meaningfully totally different from one another is like saying positions 1 & 2 on this instance are meaningfully totally different from one another. It’s utilizing a negligible distinction in information to attract incorrect inferences, which is the textbook definition of false precision.
To take it even additional, nearly all of web page 1 outcomes might be middling outcomes to the question as a result of it’s new and search engines like google and yahoo don’t know rank it primarily based on their techniques that use consumer conduct and so forth to rank issues. Because it’s a brand new question to them, plenty of elements of their system received’t have the ability to work to the identical diploma of specificity as it might for a time period like “tacos”. This implies the distribution might be much more negligible between positions on a SERP.
Dan, how are you aware that is how the distribution is?!?!?!?!
Random web stranger, please do sustain. None of us understand how the distribution of the rankability of things is finished in any SERP, not even Googlers. All hypotheses about how Google’s orders search outcomes are unable to be confirmed unfaithful (falsified) e.g. you’ll be able to’t science any of this. That’s actually my level.
Again to “tacos“; in excessive quantity, deep data queries like that, one of the best outcomes that Google might return are possible extremely good solutions (per their techniques) and barely differentiated by way of the totally different SERP positions.
This implies the highest restaurant on web page 2 for tacos is unlikely to be meaningfully worse than those on web page 1 given a excessive stock of paperwork to investigate and return. Fortunately I dwell in SoCal…. However that doesn’t imply that Google does.
Bear in mind earlier after I did a Data Graph API search to indicate how these items are scored? Nicely let’s take a look at two of my favourite phrases: “Taco Rating”. If you wish to play alongside at dwelling go to this hyperlink and hit execute within the backside proper nook.
This beneath chart reveals the “outcomes rating” for the highest 15 outcomes that the API returned for “tacos”: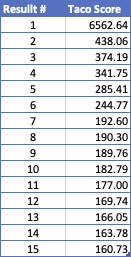
In addition to the truth that every thing after the primary result’s enjoying catch up, the distinction between positions 6 & 7 is similar because the distinction between 7 & 15. Discuss insignificant variations that you shouldn’t use to attract any conclusions…
For those who want a graph to higher perceive, take a look at this lengthy tail distribution curve

{kind=link}
Options
Alright Dan, you satisfied me that our psychological mannequin of SERPs is hijacking our brains in unfavourable methods and our false precision is main us astray, BUT WHAT DO I DO ABOUT IT?
Nicely, I’m glad you requested, random web stranger as I’ve a number of ideas and instruments that may hopefully enable you to transfer past this cognitive blocker.
Techniques Principle

The Algorithm
With a purpose to overcome false precision, I personally advocate adopting a “Techniques Principle” method, and testing Considering in Techniques by Donella Meadows (previous model accessible without cost right here).
That is vital as a result of techniques principle mainly says that complicated techniques like Google search are true blackboxes that not even the folks engaged on the techniques themselves understand how they work. That is actually simply observable on face when Google’s techniques stopped utilizing rel=prev and rel=subsequent and it took them a pair years to note.
The individuals who work on Google Search have no idea the way it works with the intention to predict search outcomes, it’s too complicated a system. So we should always cease utilizing all this false precision. It seems silly IMHO, not intelligent.

A Google Search Engineer Onerous at Work
Embracing Uncertainty
Y’all, I hate to interrupt this to you however search outcomes aren’t predictable in any manner primarily based on performing some web optimization analysis and proposing a technique and techniques consequently.

web optimization Math
We ascribe exact which means to unknowable issues with the intention to higher assist our fragile human brains address the nervousness/worry of the unknown. The unknown/uncertainty of those complicated techniques is baked into the cake. Simply bear in mind the fixed, crushing tempo of Google algo updates. They’re continuously working to alter their techniques in important methods mainly each month.
By the point you might be carried out having the ability to do any actual analysis to know how a lot an replace has modified how the system operates they’ve already modified it a pair extra occasions. That is why replace/algo chasing is mindless to me. We work in an unsure, unknowable, complicated system and embracing meaning abandoning false precision.
Considering Quick/Considering Gradual
It is a idea of the thoughts/behavioral economics put ahead by nobel prize successful economist Daniel Kahnamen.
The Human Mind is Loopy
How this pertains to problems with cognitive bias is that this bias usually arises from “quick pondering” or System 1 pondering. I’m not going to dive too deep into the distinction between these two or clarify them. As a substitute right here is Daniel Kahnamen explaining it himself in addition to an explainer submit right here.
Simply for instance how vital I believe this idea is to web optimization in addition to management and choice making; I ask folks in interviews “What’s your Superpower?” and one of the crucial unimaginable SEOs I’ve ever had the pleasure of working with (shout out Aimee Sanford!) answered “sluggish pondering” and that was that.
Takeaways
I actually suppose web optimization is fairly easy, and will get overly difficult by the truth that our self-discipline is simply manner over crowded with entrepreneurs advertising and marketing advertising and marketing. If individuals are speaking about analyzing a core algorithm replace exterior a selected context and/or making sweeping statements about what and the way Google is behaving, then it’s best to know that that is stuffed with false precision.
We will’t even meaningfully talk about the space between particular person search positions, not to mention how web scale techniques work. For those who internalize all of this false precision, it should result in cognitive biases in your pondering that may impair your efficiency. You’ll do worse at web optimization.
Now we simply all must faucet into our sluggish pondering, overcome our cognitive bias, cease utilizing false precision and develop a brand new psychological mannequin. Easy proper?
[ad_2]