

{kind=link}
[ad_1]
Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) just lately introduced assist for Index Transforms. You need to use Index Transforms to extract significant info from an present index, and retailer the aggregated info in a brand new index. The important thing good thing about Index Transforms is quicker retrieval of information by performing aggregations, grouping prematurely, and storing these ends in summarized views. For instance, you may run steady aggregations on ecommerce order knowledge to summarize and be taught the spending behaviors of your prospects. With Index Transforms, you’ve gotten the pliability to pick out particular fields from the supply index. You can too run Index Remodel jobs on indices that don’t have a timestamp area.
There are two methods to configure Index Remodel jobs: by utilizing the OpenSearch Dashboards UI or index rework REST APIs. On this submit, we focus on these two strategies and share some greatest practices.
Use the OpenSearch Dashboards UI
To configure an Index Remodel job within the Dashboards UI, first establish the supply index you wish to rework. You can too use pattern ecommerce orders knowledge obtainable on the OpenSearch Dashboards house web page.
- After you log into Kibana Dashboards, select Dwelling within the navigation pane, then select Add pattern knowledge.

- Select Add Information to create a pattern index (for instance,
opensearch_dashboards_sample_data_ecommerce).
- Launch OpenSearch Dashboards and on the menu bar, select Index Administration.
- Select Remodel Jobs within the navigation pane.
- Select Create Remodel Job.
- Specify the Index Remodel job title and choose the just lately created pattern ecommerce index because the supply.
- Select an present index or create a brand new one when choosing the goal index.

- Select Edit knowledge filter, you’ve gotten an choice to run transformations solely on the filtered knowledge. For this submit, we run transformations on merchandise bought greater than 10 occasions however lower than 200.
- Select Subsequent.

The pattern ecommerce supply index has over 50 fields. We solely wish to choose the fields which can be related to monitoring the gross sales knowledge by product class.
- Choose the fields
class.key phrase,total_quantity, andmerchandise.value. Index rework wizard permits to filter particular fields of curiosity, after which choose rework operations on these chosen fields.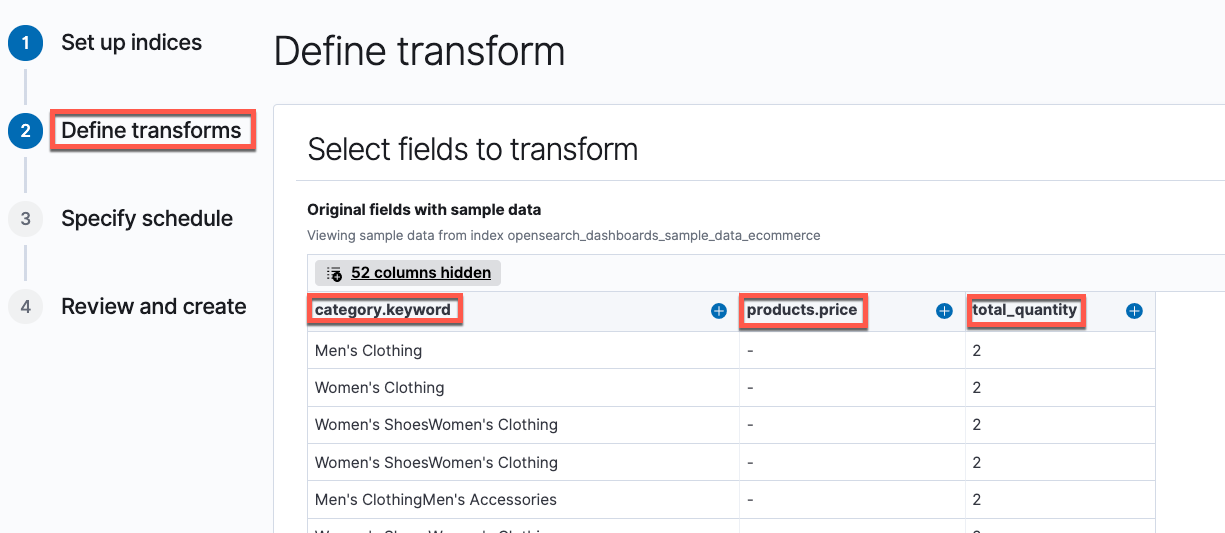
- As a result of we wish to combination by product class, select the plus signal subsequent to the sector
class.key phraseand select Group by phrases.
- Equally, select Combination by max, min, avg for the
merchandise.valuearea and Combination by sum for thetotal_quantityarea.
Index rework wizard supplies preview functionality of reworked fields on pattern knowledge for fast overview. Moreover, you too can edit the reworked area names in favor of extra descriptive names.
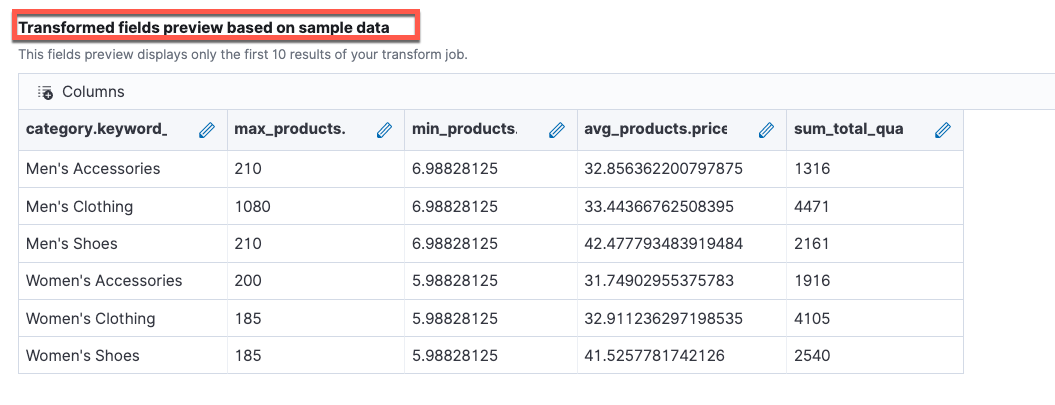
At the moment, Index Remodel jobs assist histogram, date_histogram, and phrases groupings. For extra details about groupings, see Bucket aggregations. For metrics aggregations, you may select from sum, avg, max, min, value_count, percentiles, and scripted_metric.
Scripted metrics might be helpful when you should calculate a worth based mostly on an present attribute of the doc. For instance, discovering a modern follower depend on a steady social feed or discovering the shopper who positioned the primary order over certain quantity on a selected day. Scripted metrics might be coded in painless scripts —easy, safe scripting language designed particularly to be used with search platforms.
The next is the instance script to seek out the primary buyer who positioned an order valued greater than $100.
Scripted metrics run in 4 phases:
- Initialize section (
init_script) – Optionally available initialization section the place shard stage variables might be initialized. - Map section (
map_script) – Runs the code on every collected doc. - Mix section (
combine_script) – Returns the outcomes from all shards ornodes to the coordinator node. - Cut back section (
reduce_script) – Produces the ultimate end result by processing the outcomes from all shards.
In case your use case includes a number of advanced scripted metrics calculations, plan to carry out calculations previous to ingesting knowledge into the OpenSearch Service area.
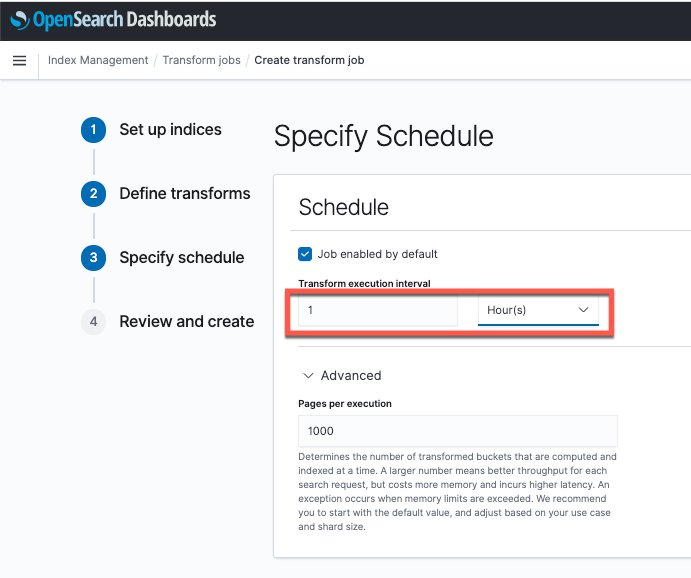
- Within the final step, specify the schedule for the Index Remodel job, for instance each 12 hours.
- On the Superior tab, you may modify the pages per run.
This setting signifies the info that may be processed in every search request. Elevating this quantity can improve the reminiscence utilization and result in increased latency. We advocate utilizing the default setting (1000 pages per run).
- Evaluate all the choice and select Create to schedule the Index Remodel job.

Index Remodel jobs are enabled by default and run based mostly on a specific schedule. Select Refresh to view the standing of the Index Remodel job.

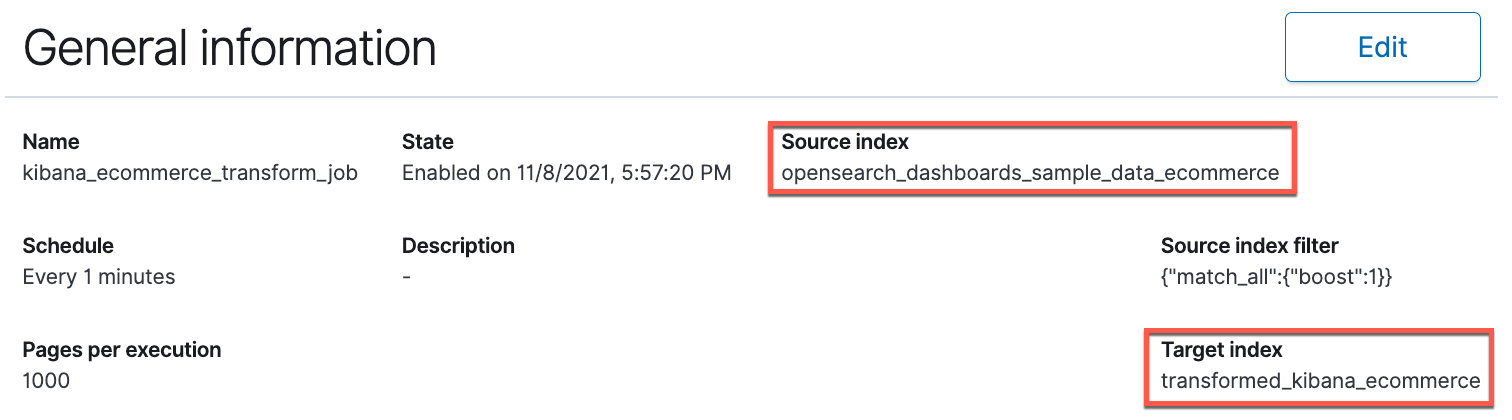
After the job runs efficiently, you may view the small print across the variety of paperwork processed, and the time taken to index and search the info.
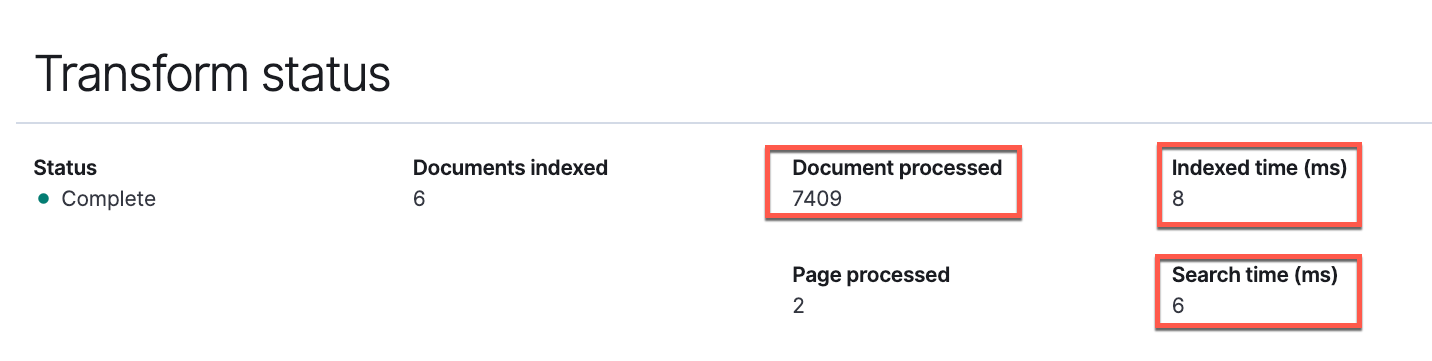
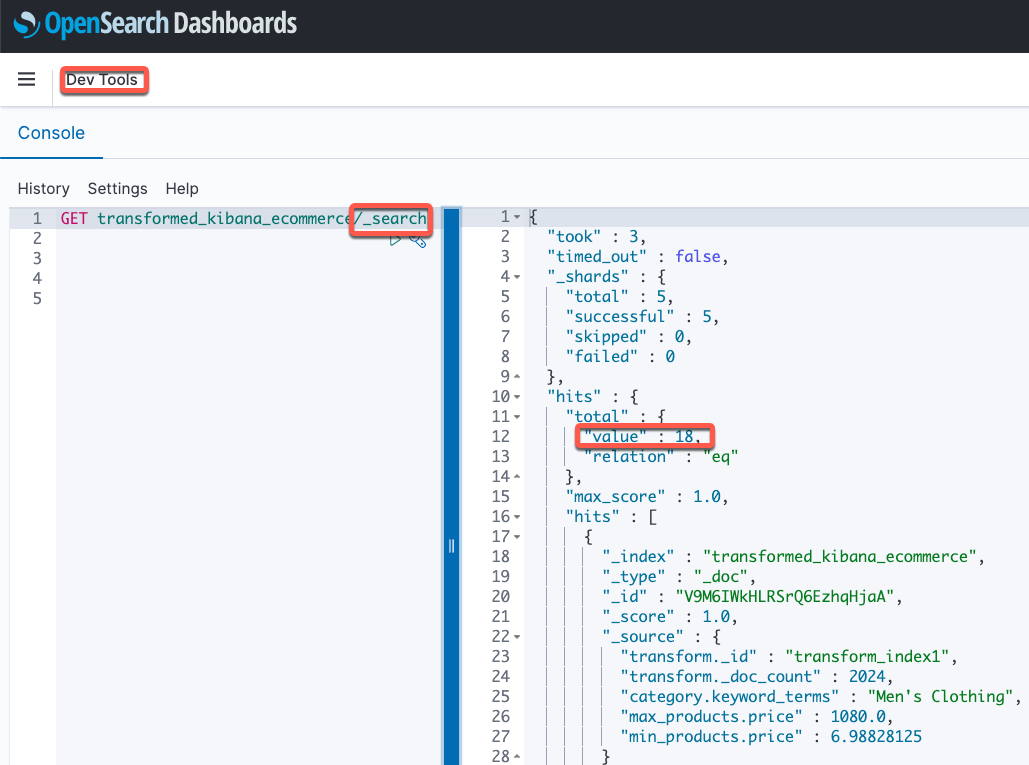
You can too view the goal index contents utilizing the _search API utilizing the OpenSearch Dev Instruments console.
Use REST APIs
Index Remodel APIs may also be used to create, replace, begin, and cease Index Remodel job operations. For instance, refer Create Remodel API to create Index Remodel job to execute each minute. Index Remodel API supplies flexibility to customise the job interval to satisfy your particular necessities.
Use the next API to get particulars of your scheduled Index Remodel job:
To preview outcomes of a beforehand run Index Remodel job:
We get the next response from our API name:
To delete an present Index Remodel job, disable the job after which difficulty the Delete API:
Greatest practices:
Index Remodel jobs are perfect for steady aggregation of information and sustaining summarized knowledge as a substitute of performing advanced aggregations at question time again and again. It’s designed to run on an index or indices, and never on adjustments between job runs.
Take into account the next greatest practices when utilizing Index Transforms:
- Keep away from operating Index Remodel jobs on rotating indexes with index patterns because the job scans all paperwork in these indices at every run. Use APIs to create a brand new Index Remodel job for every rotating index.
- Think about extra compute capability in case your Index Remodel job includes a number of aggregations as a result of this course of might be CPU intensive. For instance, In case your job scans 5 indices with 3 shards every and takes 5 minutes to finish, then minimal of 17 (5*3=15 for studying supply indices and a pair of for writing to focus on index contemplating 1 reproduction) vCPUs are required for 5minutes to finish.
- Attempt to schedule Index Remodel jobs at non-peak occasions to reduce the influence on real-time search queries.
- Be sure that there may be enough storage for the goal indexes. The scale of the goal index will depend on the cardinality of the chosen group by time period(s) and quite a lot of attributes are computed as a part of the rework. Ensure you have sufficient storage overhead mentioned in our sizing information.
- Monitor and regulate the OpenSearch Service cluster configurations.
Conclusion
This submit describes how you need to use OpenSearch Index Transforms to combination particular fields from an present index and retailer the summarized knowledge into a brand new index utilizing the OpenSearch Dashboards UI or Index Remodel REST APIs. The Index Remodel characteristic is powered by OpenSearch, an open-source search and analytics engine that makes it simple so that you can carry out interactive log analytics, real-time utility monitoring, web site search, and extra. Index Transforms can be found on all domains operating Amazon OpenSearch Service 1.0 or larger, throughout 25 AWS Areas globally.
Concerning the Authors
 Viral Shah is a Principal Options Architect with the AWS Information Lab staff based mostly out of New York, NY. He has over 20 years of expertise working with enterprise prospects and startups, primarily within the knowledge and database area. He likes to journey and spend high quality time together with his household.-
Viral Shah is a Principal Options Architect with the AWS Information Lab staff based mostly out of New York, NY. He has over 20 years of expertise working with enterprise prospects and startups, primarily within the knowledge and database area. He likes to journey and spend high quality time together with his household.-
 Arun Lakshmanan is a Search Specialist Answer Architect at AWS based mostly out of Chicago, IL.
Arun Lakshmanan is a Search Specialist Answer Architect at AWS based mostly out of Chicago, IL.
[ad_2]