
{kind=link}
[ad_1]
Historically, learn replicas of relational databases are sometimes used as a knowledge supply for non-online transactions of net functions reminiscent of reporting, enterprise evaluation, advert hoc queries, operational excellence, and buyer companies. As a result of exponential progress of knowledge quantity, it grew to become frequent apply to switch such learn replicas with information warehouses or information lakes to have higher scalability and efficiency. In most real-world use circumstances, it’s vital to copy the information from a supply relational database to the goal in actual time. Change information seize (CDC) is likely one of the most typical design patterns to seize the modifications made within the supply database and relay them to different information shops.
AWS provides a broad collection of purpose-built databases to your wants. For analytic workloads reminiscent of reporting, enterprise evaluation, and advert hoc queries, Amazon Redshift is highly effective choice. With Amazon Redshift, you possibly can question and mix exabytes of structured and semi-structured information throughout your information warehouse, operational database, and information lake utilizing commonplace SQL.
To realize CDC from Amazon Relational Database Service (Amazon RDS) or different relational databases to Amazon Redshift, the only resolution is to create an AWS Database Migration Service (AWS DMS) process from the database to Amazon Redshift. This strategy works effectively for easy information replication. To have extra flexibility to denormalize, rework, and enrich the information, we advocate utilizing Amazon Kinesis Information Streams and AWS Glue streaming jobs between AWS DMS duties and Amazon Redshift. This publish demonstrates how this second strategy works in a buyer state of affairs.
Instance use case
For our instance use case, we’ve a database that shops information of a fictional group that holds sports activities occasions. We now have three dimension tables: sport_event, ticket, and buyer, and one truth desk: ticket_activity. The desk sport_event shops sport kind (reminiscent of baseball or soccer), date, and site. The desk ticket shops seat degree, location, and ticket coverage for the goal sport occasion. The desk buyer shops particular person buyer names, e-mail addresses, and cellphone numbers, that are delicate info. When a buyer buys a ticket, the exercise (e.g. who bought the ticket) is recorded within the desk ticket_activity. One document is inserted into the desk ticket_activity each time a buyer buys a ticket, so new information are being ingested into this truth desk constantly. The information ingested into the desk ticket_activity are solely up to date when wanted, when an administrator maintains the information.
We assume a persona, a knowledge analyst, who’s answerable for analyzing developments of the sports activities exercise from this steady information in actual time. To make use of Amazon Redshift as a major information mart, the information analyst wants to complement and clear the information in order that customers like enterprise analysts can perceive and make the most of the information simply.
The next are examples of the information in every desk.
The next is the dimension desk sport_event.
| event_id | sport_type | start_date | location | |
| 1 | 35 | Baseball | 9/1/2021 | Seattle, US |
| 2 | 36 | Baseball | 9/18/2021 | New York, US |
| 3 | 37 | Soccer | 10/5/2021 | San Francisco, US |
The next is the dimension desk ticket (the sphere event_id is the overseas key for the sphere event_id within the desk sport_event).
| ticket_id | event_id | seat_level | seat_location | ticket_price | |
| 1 | 1315 | 35 | Commonplace | S-1 | 100 |
| 2 | 1316 | 36 | Commonplace | S-2 | 100 |
| 3 | 1317 | 37 | Premium | P-1 | 300 |
The next is the dimension desk buyer.
| customer_id | title | cellphone | ||
| 1 | 222 | Teresa Stein | teresa@instance.com | +1-296-605-8486 |
| 2 | 223 | Caleb Houston | celab@instance.com | 087-237-9316×2670 |
| 3 | 224 | Raymond Turner | raymond@instance.web | +1-786-503-2802×2357 |
The next is the actual fact desk ticket_activity (the sphere purchased_by is the overseas key for the sphere customer_id within the desk buyer).
| ticket_id | purchased_by | created_by | updated_by | |
| 1 | 1315 | 222 | 8/15/2021 | 8/15/2021 |
| 2 | 1316 | 223 | 8/30/2021 | 8/30/2021 |
| 3 | 1317 | 224 | 8/31/2021 | 8/31/2021 |
To make the information straightforward to research, the information analyst needs to have just one desk that features all the data as an alternative of becoming a member of all 4 tables each time they wish to analyze. Additionally they wish to masks the sphere phone_number and tokenize the sphere email_address as delicate info. To satisfy this requirement, we merge these 4 tables into one desk and denormalize, tokenize, and masks the information.
The next is the vacation spot desk for evaluation, sport_event_activity.
| ticket_id | event_id | sport_type | start_date | location | seat_level | seat_location | ticket_price | purchased_by | title | email_address | phone_number | created_at | updated_at | |
| 1 | 1315 | 35 | Baseball | 9/1/2021 | Seattle, USA | Commonplace | S-1 | 100 | 222 | Teresa Stein | 990d081b6a420d04fbe07dc822918c7ec3506b12cd7318df7eb3af6a8e8e0fd6 | +*-***-***-**** | 8/15/2021 | 8/15/2021 |
| 2 | 1316 | 36 | Baseball | 9/18/2021 | New York, USA | Commonplace | S-2 | 100 | 223 | Caleb Houston | c196e9e58d1b9978e76953ffe0ee3ce206bf4b88e26a71d810735f0a2eb6186e | ***-***-****x**** | 8/30/2021 | 8/30/2021 |
| 3 | 1317 | 37 | Soccer | 10/5/2021 | San Francisco, US | Premium | P-1 | 300 | 224 | Raymond Turner | 885ff2b56effa0efa10afec064e1c27d1cce297d9199a9d5da48e39df9816668 | +*-***-***-****x**** | 8/31/2021 | 8/31/2021 |
Answer overview
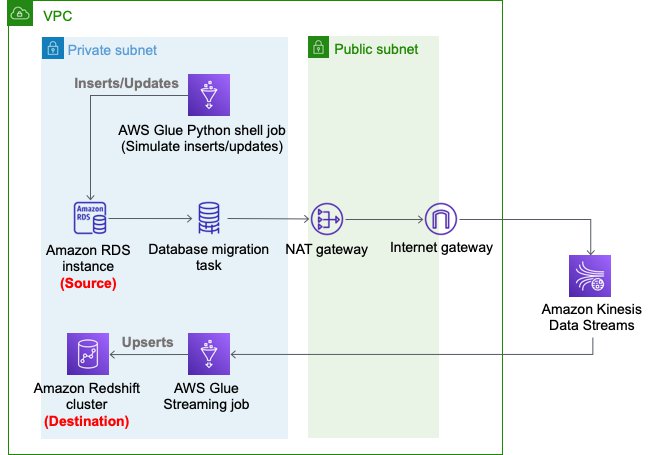
The next diagram depicts the structure of the answer that we deploy utilizing AWS CloudFormation.

We use an AWS DMS process to seize the modifications within the supply RDS occasion, Kinesis Information Streams as a vacation spot of the AWS DMS process CDC replication, and an AWS Glue streaming job to learn modified information from Kinesis Information Streams and carry out an upsert into the Amazon Redshift cluster. Within the AWS Glue streaming job, we enrich the sports-event information.
Arrange assets with AWS CloudFormation
This publish contains a CloudFormation template for a fast setup. You may overview and customise it to fit your wants.
The CloudFormation template generates the next assets:
- An Amazon RDS database occasion (supply).
- An AWS DMS replication occasion, used to copy the desk
ticket_activityto Kinesis Information Streams. - A Kinesis information stream.
- An Amazon Redshift cluster (vacation spot).
- An AWS Glue streaming job, which reads from Kinesis Information Streams and the RDS database occasion, denormalizes, masks, and tokenizes the information, and upserts the information into the Amazon Redshift cluster.
- Three AWS Glue Python shell jobs:
rds-ingest-data-initial-<CloudFormation Stack title>creates 4 supply tables on Amazon RDS and ingests the preliminary information into the tablessport_event,ticket, andbuyer. Pattern information is routinely generated at random by Faker library.rds-ingest-data-incremental-<CloudFormation Stack title>ingests new ticket exercise information into the supply deskticket_activityon Amazon RDS constantly. This job simulates buyer exercise.rds-upsert-data-<CloudFormation Stack title>upserts particular information within the supply deskticket_activityon Amazon RDS. This job simulates administrator exercise.
- AWS Identification and Entry Administration (IAM) customers and insurance policies.
- An Amazon VPC, a public subnet, two non-public subnets, an web gateway, a NAT gateway, and route tables.
- We use non-public subnets for the RDS database occasion, AWS DMS replication occasion, and Amazon Redshift cluster.
- We use the NAT gateway to have reachability to pypi.org to make use of MySQL Connector for Python from the AWS Glue Python shell jobs. It additionally gives reachability to Kinesis Information Streams and an Amazon Easy Storage Service (Amazon S3) API endpoint.
The next diagram illustrates this structure.
To arrange these assets, you need to have the next conditions:
To launch the CloudFormation stack, full the next steps:
- Register to the AWS CloudFormation console.
- Select Launch Stack:

- Select Subsequent.
- For S3BucketName, enter the title of your new S3 bucket.
- For VPCCIDR, enter the CIDR IP handle vary that doesn’t battle together with your present networks.
- For PublicSubnetCIDR, enter the CIDR IP handle vary throughout the CIDR you gave in VPCCIDR.
- For PrivateSubnetACIDR and PrivateSubnetBCIDR, enter the CIDR IP handle vary throughout the CIDR you gave for VPCCIDR.
- For SubnetAzA and SubnetAzB, select the subnets you wish to use.
- For DatabaseUserName, enter your database consumer title.
- For DatabaseUserPassword, enter your database consumer password.
- Select Subsequent.
- On the following web page, select Subsequent.
- Overview the small print on the ultimate web page and choose I acknowledge that AWS CloudFormation would possibly create IAM assets with customized names.
- Select Create stack.
Stack creation can take about 20 minutes.
Ingest new information
On this part, we stroll you thru the steps to ingest new information.
Arrange an preliminary supply desk
To arrange an preliminary supply desk in Amazon RDS, full the next steps:
- On the AWS Glue console, select Jobs.
- Choose the
job rds-ingest-data-initial-<CloudFormation stack title>. - On the Actions menu, select Run job.
- Await the Run standing to indicate as
SUCCEEDED.
This AWS Glue job creates a supply desk occasion on the RDS database occasion.
Begin information ingestion to the supply desk on Amazon RDS
To begin information ingestion to the supply desk on Amazon RDS, full the next steps:
- On the AWS Glue console, select Triggers.
- Choose the set off
periodical-trigger-<CloudFormation stack title>. - On the Actions menu, select Activate set off.
- Select Allow.
This set off runs the job rds-ingest-data-incremental-<CloudFormation stack title> to ingest one document each minute.
Begin information ingestion to Kinesis Information Streams
To begin information ingestion from Amazon RDS to Kinesis Information Streams, full the next steps:
- On the AWS DMS console, select Database migration duties.
- Choose the duty
rds-to-kinesis-<CloudFormation stack title>. - On the Actions menu, select Restart/Resume.
- Await the Standing to indicate as Load full, replication ongoing.
The AWS DMS replication process ingests information from Amazon RDS to Kinesis Information Streams constantly.
Begin information ingestion to Amazon Redshift
Subsequent, to start out information ingestion from Kinesis Information Streams to Amazon Redshift, full the next steps:
- On the AWS Glue console, select Jobs.
- Choose the job
streaming-cdc-kinesis2redshift-<CloudFormation stack title>. - On the Actions menu, select Run job.
- Select Run job once more.
This AWS Glue streaming job is carried out primarily based on the rules in Updating and inserting new information. It performs the next actions:
- Creates a staging desk on the Amazon Redshift cluster utilizing the Amazon Redshift Information API
- Reads from Kinesis Information Streams, and creates a DataFrame with filtering solely INSERT and UPDATE information
- Reads from three dimension tables on the RDS database occasion
- Denormalizes, masks, and tokenizes the information
- Writes right into a staging desk on the Amazon Redshift cluster
- Merges the staging desk into the vacation spot desk
- Drops the staging desk
After about 2 minutes from beginning the job, the information ought to be ingested into the Amazon Redshift cluster.
Validate the ingested information
To validate the ingested information within the Amazon Redshift cluster, full the next steps:
- On the Amazon Redshift console, select EDITOR within the navigation pane.
- Select Connect with database.
- For Connection, select Create a brand new connection.
- For Authentication, select Momentary credentials.
- For Cluster, select the Amazon Redshift cluster
cdc-sample-<CloudFormation stack title>. - For Database title, enter
dev. - For Database consumer, enter the consumer that was specified within the CloudFormation template (for instance,
dbmaster). - Select Join.
- Enter the question
SELECT * FROM sport_event_activityand select Run.
Now you possibly can see the ingested information within the desk sport_event_activity on the Amazon Redshift cluster. Let’s word the worth of ticket_id from one of many information. For this publish, we select 1317 for example.

Replace present information
Your Amazon Redshift cluster now has the newest information ingested from the tables on the supply RDS database occasion. Let’s replace the information within the supply desk ticket_activity on the RDS database occasion to see that the up to date information are replicated to the Amazon Redshift cluster aspect.
The CloudFormation template creates one other AWS Glue job. This job upserts the information with particular IDs on the supply desk occasion. To upsert the information within the supply desk, full the next steps:
- On the AWS Glue console, select Jobs.
- Select the job
rds-upsert-data-<CloudFormation stack title>. - On the Actions menu, select Edit job.
- Below Safety configuration, script libraries, and job parameters (elective), for Job parameters, replace the next parameters:
- For Key, enter
--ticket_id_to_be_updated. - For Worth, exchange 1 with one of many ticket IDs you noticed on the Amazon Redshift console.
- For Key, enter
- Select Save.
- Select the job
rds-upsert-data-<CloudFormation stack title>. - On the Actions menu, select Run job.
- Select Run job.
This AWS Glue Python shell job simulates a buyer exercise to purchase a ticket. It updates a document within the supply desk ticket_activity on the RDS database occasion utilizing the ticket ID handed within the job argument --ticket_id_to_be_updated. It routinely selects one buyer, updates the sphere purchased_by with the shopper ID, and updates the sphere updated_at with the present timestamp.
To validate the ingested information within the Amazon Redshift cluster, run the identical question SELECT * FROM sport_event_activity. You may filter the document with the ticket_id worth you famous earlier.

Based on the rows returned to the question, the document ticket_id=1317 has been up to date. The sector updated_at has been up to date from 2021-08-16 06:05:01 to 2021-08-16 06:53:52, and the sphere purchased_by has been up to date from 449 to 14. From this consequence, you possibly can see that this document has been efficiently up to date on the Amazon Redshift cluster aspect as effectively. It’s also possible to select Queries within the left pane to see previous question runs.
Clear up
Now to the ultimate step, cleansing up the assets.
- Cease the AWS DMS replication process
rds-to-kinesis-<CloudFormation stack title>. - Cease the AWS Glue streaming job
streaming-cdc-kinesis2redshift-<CloudFormation stack title>. - Delete the CloudFormation stack.
Conclusion
On this publish, we demonstrated how one can stream information—not solely new information, but additionally up to date information from relational databases—to Amazon Redshift. With this strategy, you possibly can simply obtain upsert use circumstances on Amazon Redshift clusters. Within the AWS Glue streaming job, we demonstrated the frequent method to denormalize, masks, and tokenize information for real-world use circumstances.
In regards to the Authors
 Noritaka Sekiyama is a Principal Huge Information Architect on the AWS Glue group. He enjoys collaborating with totally different groups to ship outcomes like this publish. In his spare time, he enjoys taking part in video video games together with his household.
Noritaka Sekiyama is a Principal Huge Information Architect on the AWS Glue group. He enjoys collaborating with totally different groups to ship outcomes like this publish. In his spare time, he enjoys taking part in video video games together with his household.
 Roman Gavrilov is an Engineering Supervisor at AWS Glue. He has over a decade of expertise constructing scalable Huge Information and Occasion-Pushed options. His group works on Glue Streaming ETL to permit close to actual time information preparation and enrichment for machine studying and analytics.
Roman Gavrilov is an Engineering Supervisor at AWS Glue. He has over a decade of expertise constructing scalable Huge Information and Occasion-Pushed options. His group works on Glue Streaming ETL to permit close to actual time information preparation and enrichment for machine studying and analytics.
[ad_2]