

{kind=link}
[ad_1]
Amazon Athena is an interactive question service that makes it straightforward to investigate information in Amazon Easy Storage Service (Amazon S3) utilizing commonplace SQL. Athena is serverless, so there is no such thing as a infrastructure to handle, and also you pay just for the queries that you just run.
In November 2020, Athena introduced the Normal Availability of the V2 model of its core engine along with efficiency enhancements and new characteristic capabilities. Right now, V2 is the default engine model for each Athena workgroup and it contains extra enhancements made since its first launch. Engine enhancements are launched ceaselessly and are robotically accessible to you with out the necessity for guide intervention.
On this publish, we focus on the efficiency benchmarks and efficiency enhancements of Athena’s newest engine.
We carried out benchmark testing on our newest engine utilizing TPC-DS benchmark queries at 3 TB scale and noticed that question efficiency improved by 3x and price decreased by 70% on account of diminished scanned information dimension when in comparison with our earlier engine.
Efficiency and price comparability on TPC-DS benchmarks
We used the industry-standard TPC-DS 3 TB to symbolize completely different buyer use instances. These benchmark checks have a spread of accuracy inside +/- 10% and are consultant of workloads with 10 instances the acknowledged benchmark dimension. This implies a 3 TB benchmark dataset precisely represents buyer workloads on 30–50 TB datasets.
In our testing, the dataset was saved in Amazon S3 in non-compressed Parquet format with no extra optimizations and the AWS Glue Knowledge Catalog was used to retailer metadata for databases and tables. Truth tables have been partitioned on the date column used for be a part of operations and every reality desk consisted of two,000 partitions. We chosen 71 of the 99 queries from the TPC-DS benchmark that finest illustrated the variations between engines V1 and V2. We ran the queries with a concurrency of three. This implies as much as 3 queries have been in a operating state at any given time and the following question was submitted as quickly as one of many 3 operating queries accomplished.
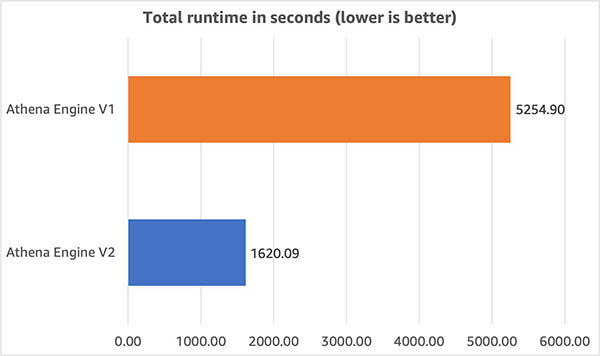
The next graph illustrates the whole runtime of queries on engines V1 and V2 and exhibits runtime was 3x quicker on engine V2.
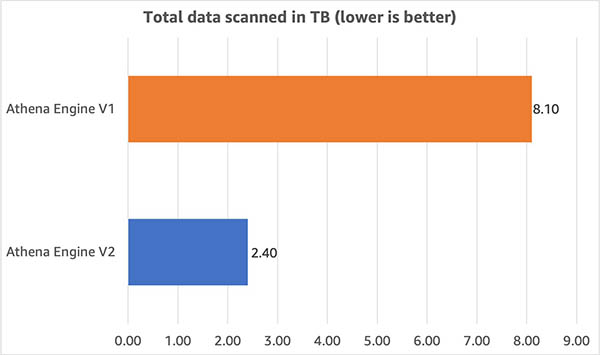
We additionally in contrast the quantity of knowledge scanned by queries on this benchmark. As proven within the following graph, we discovered that the information scanned – and the ensuing per-query prices – have been 70% decrease with engine V2.
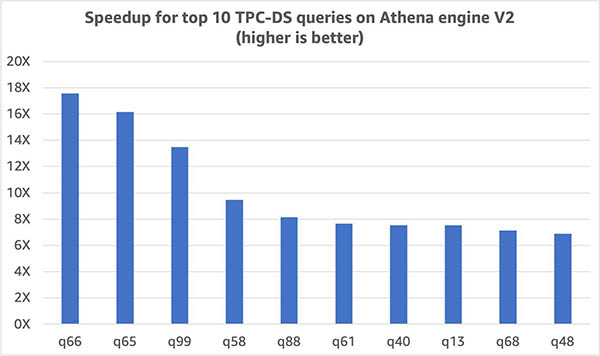
Queries in our benchmark have been persistently extra performant with engine V2. The next graph exhibits the ten TPC-DS queries with the most important enchancment in runtime. For this set of queries, runtime improved by 6.9 instances.
Now, let’s have a look at a number of the enhancements in engine V2 that contributed in the direction of these astounding outcomes.
Efficiency enhancements in engine V2
The Athena engine is constructed upon Presto, an open-source distributed SQL question engine optimized for low latency. We’re constantly bettering Athena’s engine with enhancements developed by Athena and AWS engineering groups in addition to incorporating contributions from the PrestoDB and Trino group. The result’s an engine with constantly rising efficiency and cost-effectiveness advantages which are robotically accessible to you. Just a few such enhancements are highlighted within the following sections.
Extra environment friendly joins through dynamic filtering and dynamic partition pruning
Dynamic filtering and dynamic partition pruning improves the question runtime and reduces information scanned for queries with joins and a really selective filter clause for the desk on the best aspect of be a part of, as proven within the following instance.
Within the following question, Table_B is a small desk with a really selective filter. (column_A = “worth”). After the selective filter is utilized to Table_B, a price checklist for a joined column Table_B.date is extracted first, and it’s pushed all the way down to a joined desk Table_A as a filter. It’s used to filter out pointless rows and partitions of Table_A. This ends in studying fewer rows and partitions from the supply for Table_A and serving to cut back question runtime and information scan dimension, which in flip helps cut back the prices of operating the question in Athena.
Extra clever be a part of ordering and distribution picks
Selecting a greater be a part of order and be a part of algorithm is crucial to raised question efficiency. They will simply have an effect on how a lot information is learn from a specific desk, how a lot information is transferred to the intermediate phases by way of networks, and the way a lot reminiscence is required to construct up a hash desk to facilitate a be a part of. Be a part of order and be a part of algorithm choices are a part of the cost-based optimizer that makes use of statistics to enhance question plans by deciding how tables and subqueries are joined.
For instances the place statistics aren’t accessible, we launched an analogous idea however by way of enumerating and analyzing the metadata of the S3 information to optimize question plans. The logic for these guidelines takes into consideration each small tables and small subqueries whereas making these choices. For instance, take into account the next question:
The syntactical be a part of order is A be a part of B be a part of C. With these optimization guidelines, if A is taken into account a small desk after retrieving the approximate dimension by way of quick file enumeration on Amazon S3, the principles place desk A on the construct aspect (the aspect that’s constructed right into a hash desk for a be a part of) and makes the be a part of as a broadcast be a part of to hurry up the question and cut back reminiscence consumption. Moreover, the principles reorder the joins to reduce the intermediate consequence dimension, which helps additional pace up the general question runtime.
Nested discipline pruning for advanced information sorts
On this enchancment for Parquet and ORC datasets, when a nested discipline is queried in a fancy information kind like struct, array of structs, or map, solely the particular subfield or nested discipline is learn from the supply as a substitute of studying your complete row. If there’s a filter on the nested discipline, Athena can now push down the predicate to the Parquet or ORC file to prune the content material at supply degree. This has led to vital financial savings in information scanned and a discount in question runtime. With this characteristic, you don’t have to flatten your nested information to enhance question efficiency.
Optimized prime N rank() features
Beforehand, all enter information for rank() window features was despatched to the window operator for processing and the LIMIT and filter clauses have been utilized at a later stage.
With this optimization, the engine can substitute the window operator with a prime N rank operator, push down the filters, and solely hold prime N (the place N is the LIMIT quantity) entries for every window group to save lots of reminiscence and I/O throughput.
A great instance of a question that benefited from this optimization is question 67 (proven within the following code) of the TPC-DS benchmark. It incorporates a subquery with a memory- and CPU-heavy window perform rank() that’s utilized to the output of one other subquery, which generates an enormous quantity of intermediate information after scanning the massive reality desk store_sales. The output of this subquery is additional filtered with LIMIT and comparability operators earlier than returning the ultimate outcomes. Due to the LIMIT and comparability operator, solely information with the bottom 100 complete gross sales are significant in every merchandise class window group; the remainder are discarded. Processing these information (that are discarded later by way of window features) is reminiscence and community intensive.
With this enhancement, solely a small quantity of knowledge is saved in reminiscence and despatched throughout the community as a result of the filters and limits are pushed down. This makes your complete workflow extra environment friendly and permits the engine to course of a bigger quantity of knowledge with the identical sources.
Question 67 was unsuccessful on engine V1 regardless of the appreciable time and effort wanted to scan (roughly 75 GB of knowledge) and course of information that was ultimately thrown away as a consequence of useful resource exhaustion. On engine V2, this question completes in roughly 165 seconds and scans solely 17 GB of knowledge.
Within the following question, filter clause rk <=100 and restrict 100 are pushed to the rank() perform as described earlier:
Different optimizations
Along with these optimizations, the next contributed in the direction of quicker queries and diminished information scan for the queries in our benchmark:
- Additional pushdown of LIMIT and filter operators to scale back the intermediate outcomes dimension and information scanned from the sources
- Enhancement of aggregation and window features to eat a lot much less reminiscence and supply higher efficiency
- Addition of a distributed kind for the ORDER BY operator to make the most of sources successfully which helps kind extra information reliably
- Enchancment in task-scheduling mechanisms for extra environment friendly processing throughout sources
Conclusion
With the efficiency optimizations within the newest engine V2 of Athena, you possibly can run queries quicker and at decrease price than earlier than. The TPC-DS benchmark queries on engine V2 confirmed a 3x enchancment in question runtime and price discount of 70%.
In our mission to innovate on behalf of consumers, Athena routinely releases efficiency and reliability enhancements on its newest engine model. To remain updated with the newest engine launch, guarantee your Athena workgroups have chosen Automated question engine improve in your workgroup settings.
For extra info, see the efficiency enhancements for engine V2 and test our launch notes to find out about new options and enhancements.
Concerning the Authors
 Pathik Shah is a Sr. Large Knowledge Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the massive information analytics house since then, serving to clients construct scalable and sturdy options utilizing AWS analytics companies.
Pathik Shah is a Sr. Large Knowledge Architect on Amazon Athena. He joined AWS in 2015 and has been focusing within the massive information analytics house since then, serving to clients construct scalable and sturdy options utilizing AWS analytics companies.
 Xuanyu Zhan is a Software program Improvement Engineer on Amazon Athena. He joined Athena in 2019 and has been engaged on completely different areas of Athena engine V2, together with engine improve, engine reliability, and engine efficiency.
Xuanyu Zhan is a Software program Improvement Engineer on Amazon Athena. He joined Athena in 2019 and has been engaged on completely different areas of Athena engine V2, together with engine improve, engine reliability, and engine efficiency.
 Sungheun Wi is a Sr. Software program Improvement Engineer on Amazon Athena. He joined AWS in 2019 and has been engaged on a number of database engines corresponding to Athena and Aurora, specializing in analytic question processing enhancements.
Sungheun Wi is a Sr. Software program Improvement Engineer on Amazon Athena. He joined AWS in 2019 and has been engaged on a number of database engines corresponding to Athena and Aurora, specializing in analytic question processing enhancements.
[ad_2]