

{kind=link}
[ad_1]
Amazon Athena is an interactive serverless question service to question knowledge from Amazon Easy Storage Service (Amazon S3) in customary SQL. Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) is a completely managed, open-source, distributed search and analytics suite derived from Elasticsearch, permitting you to run OpenSearch Service or Elasticsearch clusters at scale with out having to handle {hardware} provisioning, software program set up, patching, backups, and so forth.
Though each companies have their very own use circumstances, there could be conditions once you need to run queries that mix knowledge in Amazon S3 with knowledge in an Amazon OpenSearch Service Cluster. In such circumstances, federated queries in Athena are possibility—they supply the potential to mix knowledge from a number of knowledge sources and analyze them in a single question. The federated question function works through the use of knowledge supply connectors which can be constructed for various knowledge sources. To permit Amazon OpenSearch Service to be one of many sources that Athena can question in opposition to, AWS has made obtainable an information supply connector for OpenSearch Service clusters to be queried from Athena.
This publish demonstrates the right way to question knowledge in Amazon OpenSearch Service and Amazon S3 in a single question. We use the information made obtainable within the public COVID-19 knowledge lake, documented as a part of the publish A public knowledge lake for evaluation of COVID-19 knowledge.
Particularly, we use the next two datasets:
alleninstitute_metadata: Metadata on papers pulled from the COVID-19 Open Analysis Dataset (CORD-19). Theshacolumn signifies the paper ID, which is the file title of the paper within the knowledge lake. This dataset is saved in Amazon OpenSearch Service as a result of it comprises the column summary, which you’ll search on.alleninstitute_comprehend_medical: Outcomes containing annotations obtained by operating the papers within the previous dataset by means of Amazon Comprehend Medical. That is accessed from its public storage ats3://covid19-lake/alleninstitute/CORD19/comprehendmedical/comprehend_medical.json.
Knowledge stream when combining knowledge from Amazon OpenSearch Service and Amazon S3
The information supply connectors are applied as AWS Lambda features. When a consumer points a question that mixes knowledge from Amazon OpenSearch Service and Amazon S3, Athena refers back to the AWS Glue Knowledge Catalog metadata to search for the desk definitions. For the desk whose knowledge is in Amazon S3, Athena fetches the information from Amazon S3. For the tables which can be in Amazon OpenSearch Service, Athena invokes the Lambda operate (a part of the information supply connector software) to learn the information from Amazon OpenSearch Service. Relying on the quantity of information, you possibly can invoke this operate a number of occasions in parallel for a similar question to allow quicker reads.
The next diagram illustrates this knowledge stream.

Arrange the 2 knowledge sources utilizing AWS CloudFormation
To organize for querying each knowledge sources, launch the AWS CloudFormation template utilizing the “Launch Stack” button beneath. All you should do is select Create stack.
![]()
To run the CloudFormation stack, you should be logged in to an AWS account with permissions to do the next:
- Create a CloudFormation stack
- Create an Id and Entry Administration (IAM) function
- Create a Lambda operate, assign an IAM function to it, and invoke it
- Launch an OpenSearch Service cluster
- Create AWS Glue databases and desk
- Create an S3 bucket
For directions on making a CloudFormation stack, see Get began.
For extra details about controlling permissions and entry for these companies, see the next assets:
The CloudFormation template creates the next:
- A desk within the AWS Glue Knowledge Catalog named
alleninstitute_comprehend_medicalthat factors to the S3 locations3://covid19-lake/alleninstitute/CORD19/comprehendmedical/comprehend_medical.json. This comprises the outcomes extracted from the CORD-19 knowledge utilizing the pure language processing service Amazon Comprehend Medical. - An S3 bucket with the title
athena-es-connector-spill-bucket-adopted by the primary few characters from the stack ID to maintain the bucket title distinctive. - An OpenSearch Service cluster with the title
es-alleninstitute-data, which has two cases configured to permit a job to entry the cluster. - An IAM function to entry the OpenSearch Service cluster.
- A Lambda operate that comprises a bit of Python code that reads all of the metadata of the papers together with the summary. This knowledge is obtainable as JSON at
s3://covid19-lake/alleninstitute/CORD19/json/metadata/. For this publish, we load simply one of many 4 JSON recordsdata obtainable. - A customized useful resource that invokes the Lambda operate to load the information into the OpenSearch Service cluster.
The stack can take 15–half-hour to finish.
When the stack is absolutely deployed, navigate to the Outputs tab of the stack and notice the title of the S3 bucket created (the worth for SpillBucket).

For the remainder of the steps, you want permissions to do the next:
Deploy the Amazon Athena OpenSearch connector
When the OpenSearch Service area with an index containing the metadata associated to the COVID-19 analysis papers and the AWS Glue desk pointing to the Amazon Comprehend Medical output knowledge is prepared, you possibly can deploy the Amazon Athena OpenSearch connector utilizing the AWS Serverless Utility Repository.
- On the AWS Serverless Utility Repository console, select Accessible functions.
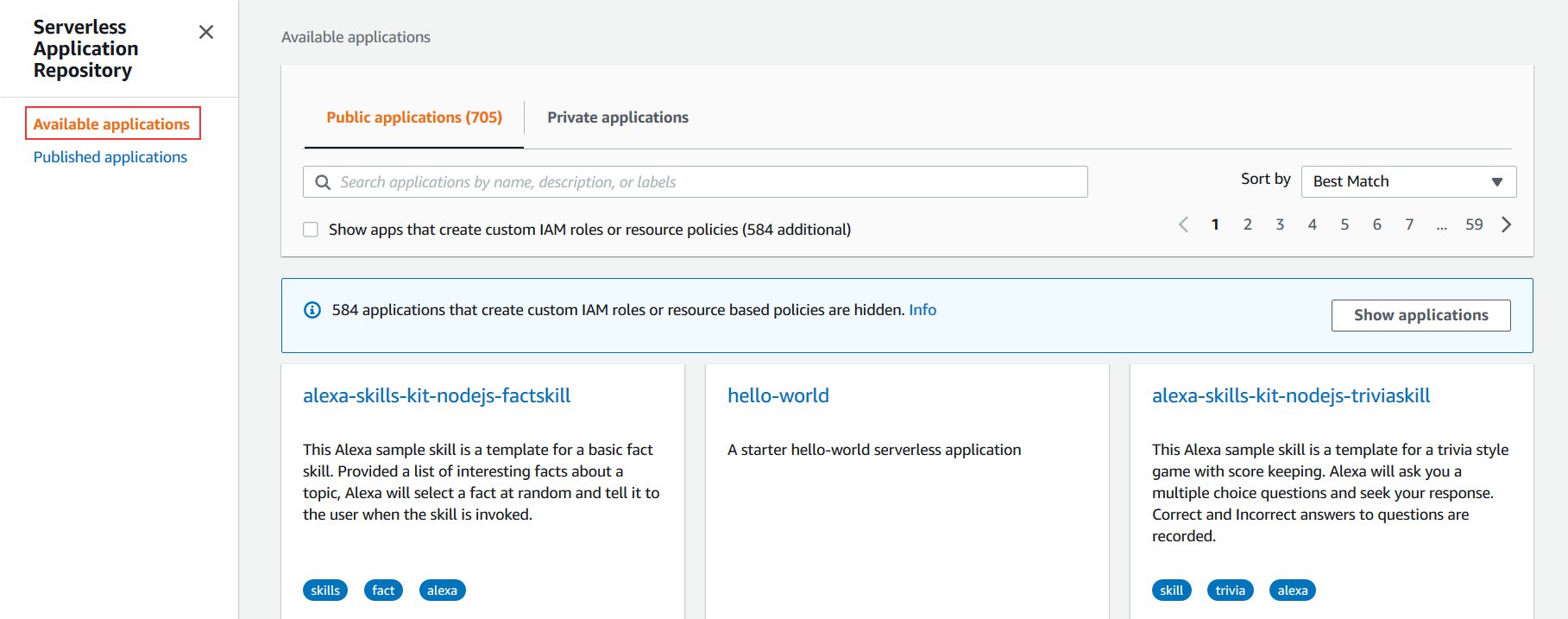
- Seek for
Athena Elasticsearchand choose Present apps that create customized IAM roles or useful resource insurance policies. - Select AthenaElasticsearchConnector.
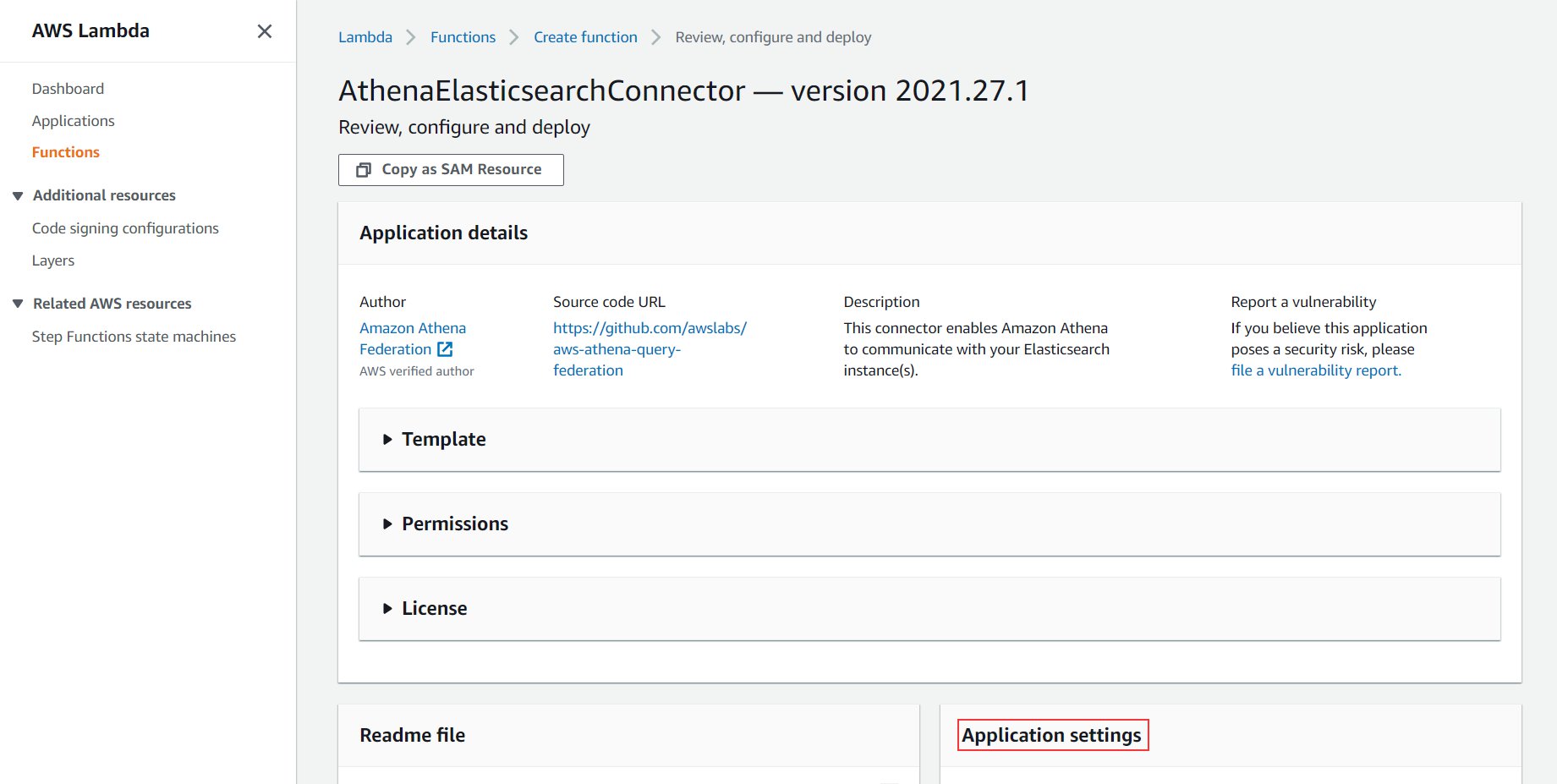
You’re redirected to the appliance display screen.
- Scroll right down to the Utility settings part.
- For AthenaCatalogName, enter a reputation (for this publish, we use
es-connector).
This title is the title of the appliance and the Lambda operate that connects to Amazon OpenSearch Service each time you run a question from Athena. For extra particulars about all of the parameters, check with the connector’s GitHub web page.
- For SpillBucket, enter the title you famous within the earlier part once we deployed the CloudFormation stack (it begins with
athena-es-connector-spill-bucket).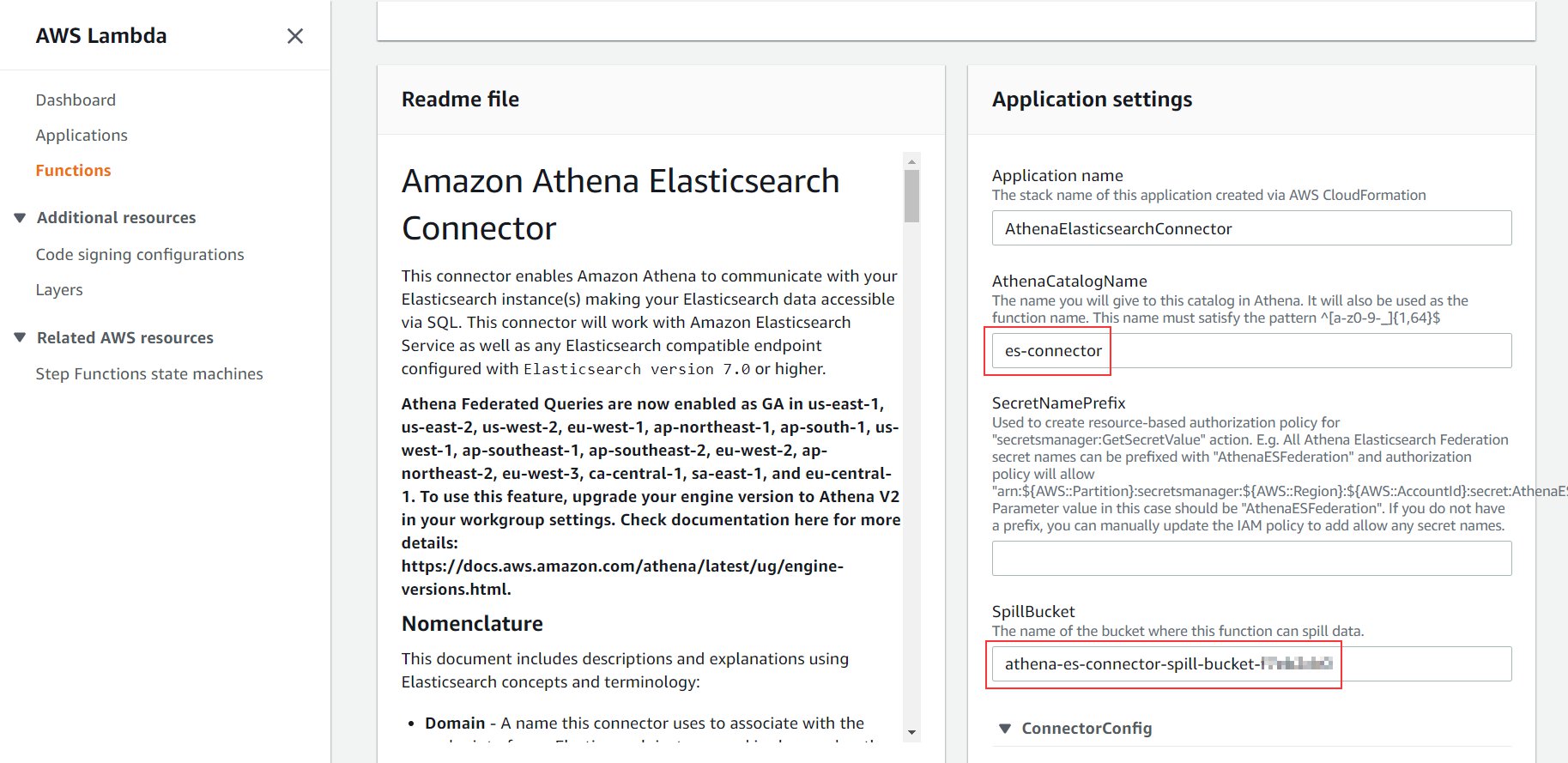
- Depart all different settings as default.

- Choose I acknowledge that this app creates customized IAM roles.
- Select Deploy.
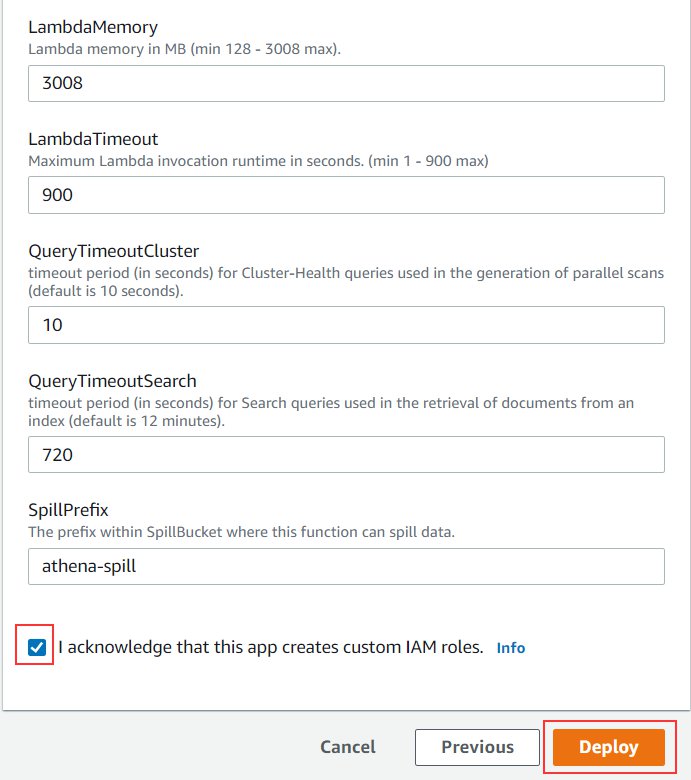
In just a few seconds, you’re redirected to the Purposes web page. You’ll be able to see the standing of your deployment on the Deployments tab. The deployment takes 1–2 minutes to finish.

Create a brand new knowledge supply in Athena
Now that the connector software has been deployed, it’s time to arrange the OpenSearch Service area to point out as a catalog on Athena.
- On the Athena console, navigate to the
cord19database.
The database comprises the desk alleninstitute_comprehend_medical, which was created as a part of the CloudFormation template. This refers back to the knowledge sitting in Amazon S3 at s3://covid19-lake/alleninstitute/CORD19/comprehendmedical/.
- Select Knowledge sources within the navigation pane.
- Select Join knowledge supply.

- Choose Customized knowledge supply.

- For Knowledge supply title, enter a reputation (for instance,
es-cord19-catalog). - Choose Use an current Lambda operate and select es-connector on the drop-down menu.

- Select Join knowledge supply.

- Select Subsequent.
- For Lambda operate, select es-connector.
- Select Join.
A brand new catalog es-cord19-catalog ought to now be obtainable, as within the following screenshot.

- On the Question editor tab, for Knowledge supply, select es-cord19-catalog.

Now you can question this knowledge supply from Athena.
Question OpenSearch Service domains from Athena
If you select the es-cord19-catalog knowledge supply, the Lambda operate (which was a part of the connector software that we deployed) will get invoked and fetches the main points concerning the area and the index. The OpenSearch Service area exhibits up as a database, and the index is proven as a desk. You too can question the desk with the next question:

Now you possibly can be part of knowledge from each Amazon OpenSearch Service and Amazon S3 with queries, resembling the next:
The previous question will get the title and the URL of all of the analysis papers the place the prognosis was associated to infectious ailments.
The next screenshot exhibits the question outcomes.

Clear up
To scrub up the assets created as a part of this publish, full the next steps:
- On the Amazon S3 console, find and choose your S3 bucket (the identical bucket you famous from the CloudFormation stack).
- Select Empty.

You too can obtain this by operating the next command from a command line:
- On the AWS CloudFormation console, delete the stack you created.

- Delete the stack created for the Amazon Athena OpenSearch connector software. The default title is
serverlessrepo-AthenaElasticsearchConnector.
- On the Athena console, delete the
es-cord19-catalogknowledge supply.
You too can delete the information supply with the next command:
Conclusion
On this publish, we noticed the right way to mix knowledge from OpenSearch Service clusters with different knowledge sources like Amazon S3 to run federated queries. You’ll be able to apply this answer to different use circumstances, resembling combining AWS CloudTrail logs loaded into OpenSearch Service clusters with VPC stream logs knowledge in Amazon S3 to research uncommon community visitors, or combining product evaluations knowledge in Amazon OpenSearch Service with product knowledge in Amazon S3 or different knowledge sources. You too can pull knowledge from Amazon OpenSearch Service and create an AWS Glue desk out of it utilizing a CTAS question in Athena.
To study extra concerning the Amazon Athena OpenSearch connector and its different configuration choices, see the GitHub repo.
To study extra about question federation in Athena, check with Utilizing Amazon Athena Federated Question or Question any knowledge supply with Amazon Athena’s new federated question.
Concerning the Authors
 Behram Irani, Sr Analytics Options Architect
Behram Irani, Sr Analytics Options Architect
 Madhav Vishnubhatta, Sr Technical Account Supervisor
Madhav Vishnubhatta, Sr Technical Account Supervisor
[ad_2]