
{kind=link}
[ad_1]
Guaranteeing knowledge reliability is among the key goals of sustaining knowledge integrity and is essential for constructing knowledge belief throughout a corporation. Information reliability implies that the info is full and correct. It’s the catalyst for delivering trusted knowledge analytics and insights. Incomplete or inaccurate knowledge leads enterprise leaders and knowledge analysts to make poor selections, which may result in detrimental downstream impacts and subsequently could lead to groups spending precious money and time correcting the info afterward. Subsequently, it’s all the time a greatest apply to run knowledge reliability checks earlier than loading the info into any targets like Amazon Redshift, Amazon DynamoDB, or Amazon Timestream databases.
This publish discusses an answer for working knowledge reliability checks earlier than loading the info right into a goal desk in Amazon Redshift utilizing the open-source library Nice Expectations. You’ll be able to automate the method for knowledge checks through the in depth built-in Nice Expectations glossary of guidelines utilizing PySpark, and it’s versatile for including or creating new custom-made guidelines in your use case.
Amazon Redshift is a cloud knowledge warehouse answer and delivers as much as 3 times higher price-performance than different cloud knowledge warehouses. With Amazon Redshift, you possibly can question and mix exabytes of structured and semi-structured knowledge throughout your knowledge warehouse, operational database, and knowledge lake utilizing commonplace SQL. Amazon Redshift permits you to save the outcomes of your queries again to your Amazon Easy Storage Service (Amazon S3) knowledge lake utilizing open codecs like Apache Parquet, to be able to carry out further analytics from different analytics providers like Amazon EMR, Amazon Athena, and Amazon SageMaker.
Nice Expectations (GE) is an open-source library and is obtainable in GitHub for public use. It helps knowledge groups eradicate pipeline debt by knowledge testing, documentation, and profiling. Nice Expectations helps construct belief, confidence, and integrity of knowledge throughout knowledge engineering and knowledge science groups in your group. GE presents a wide range of expectations builders can configure. The software defines expectations as statements describing verifiable properties of a dataset. Not solely does it provide a glossary of greater than 50 built-in expectations, it additionally permits knowledge engineers and scientists to write down customized expectation features.
Use case overview
Earlier than performing analytics or constructing machine studying (ML) fashions, cleansing knowledge can take up quite a lot of time within the mission cycle. With out automated and systematic knowledge high quality checks, we could spend most of our time cleansing knowledge and hand-coding one-off high quality checks. As most knowledge engineers and scientists know, this course of will be each tedious and error-prone.
Having an automatic high quality test system is essential to mission effectivity and knowledge integrity. Such techniques assist us perceive knowledge high quality expectations and the enterprise guidelines behind them, know what to anticipate in our knowledge evaluation, and make speaking the info’s intricacies a lot simpler. For instance, in a uncooked dataset of buyer profiles of a enterprise, if there’s a column for date of beginning in format YYYY-mm-dd, values like 1000-09-01 could be appropriately parsed as a date kind. Nevertheless, logically this worth could be incorrect in 2021, as a result of the age of the individual could be 1021 years, which is inconceivable.
One other use case may very well be to make use of GE for streaming analytics, the place you need to use AWS Database Migration Service (AWS DMS) emigrate a relational database administration system. AWS DMS can export change knowledge seize (CDC) recordsdata in Parquet format to Amazon S3, the place these recordsdata can then be cleansed by an AWS Glue job utilizing GE and written to both a vacation spot bucket for Athena consumption or the rows will be streamed in AVRO format to Amazon Kinesis or Kafka.
Moreover, automated knowledge high quality checks will be versioned and likewise deliver profit within the type of optimum knowledge monitoring and decreased human intervention. Information lineage in an automatic knowledge high quality system can even point out at which stage within the knowledge pipeline the errors had been launched, which might help inform enhancements in upstream techniques.
Resolution structure
This publish comes with a ready-to-use blueprint that robotically provisions the mandatory infrastructure and spins up a SageMaker pocket book that walks you step-by-step by the answer. Moreover, it enforces the perfect practices in knowledge DevOps and infrastructure as code. The next diagram illustrates the answer structure.

The structure accommodates the next elements:
- Information lake – After we run the AWS CloudFormation stack, an open-source pattern dataset in CSV format is copied to an S3 bucket in your account. As an output of the answer, the info vacation spot is an S3 bucket. This vacation spot consists of two separate prefixes, every of which accommodates recordsdata in Parquet format, to differentiate between accepted and rejected knowledge.
- DynamoDB – The CloudFormation stack persists knowledge high quality expectations in a DynamoDB desk. 4 predefined column expectations are populated by the stack in a desk referred to as
redshift-ge-dq-dynamo-blog-rules. Aside from the pre-populated guidelines, you possibly can add any rule from the Nice Expectations glossary in keeping with the info mannequin showcased later within the publish. - Information high quality processing – The answer makes use of a SageMaker pocket book occasion powered by Amazon EMR to course of the pattern dataset utilizing PySpark (v3.1.1) and Nice Expectations (v0.13.4). The pocket book is robotically populated with the S3 bucket location and Amazon Redshift cluster identifier through the SageMaker lifecycle config provisioned by AWS CloudFormation.
- Amazon Redshift – We create inner and exterior tables in Amazon Redshift for the accepted and rejected datasets produced from processing the pattern dataset. The exterior
dq_rejected.monster_com_rejecteddesk, for rejected knowledge, makes use of Amazon Redshift Spectrum and creates an exterior database within the AWS Glue Information Catalog to reference the desk. Thedq_accepted.monster_comdesk is created as an everyday Amazon Redshift desk by utilizing the COPY command.
Pattern dataset
As a part of this publish, we’ve carried out checks on the Monster.com job candidates pattern dataset to reveal the info reliability checks utilizing the Nice Expectations library and loading knowledge into an Amazon Redshift desk.
The dataset accommodates almost 22,000 totally different pattern data with the next columns:
nationcountry_codedate_addedhas_expiredjob_boardjob_descriptionjob_titlejob_typelocationgrouppage_urlwagesectoruniq_id
For this publish, we’ve chosen 4 columns with inconsistent or soiled knowledge, particularly group, job_type, uniq_id, and location, whose inconsistencies are flagged in keeping with the foundations we outline from the GE glossary as described later within the publish.
Conditions
For this answer, you need to have the next conditions:
- An AWS account should you don’t have one already. For directions, see Signal Up for AWS.
- For this publish, you possibly can launch the CloudFormation stack within the following Areas:
us-east-1us-east-2us-west-1us-west-2
- An AWS Identification and Entry Administration (IAM) person. For directions, see Create an IAM Person.
- The person ought to have create, write, and skim entry for the next AWS providers:
- Familiarity with Nice Expectations and PySpark.
Arrange the setting
Select Launch Stack to start out creating the required AWS sources for the pocket book walkthrough:
![]()
For extra details about Amazon Redshift cluster node sorts, see Overview of Amazon Redshift clusters. For the kind of workflow described on this publish, we advocate utilizing the RA3 Occasion Kind household.
Run the notebooks
When the CloudFormation stack is full, full the next steps to run the notebooks:
- On the SageMaker console, select Pocket book situations within the navigation pane.

This opens the pocket book situations in your Area. You must see a pocket book titled redshift-ge-dq-EMR-blog-notebook.
- Select Open Jupyter subsequent to this pocket book to open the Jupyter pocket book interface.
You must see the Jupyter pocket book file titled ge-redshift.ipynb.
- Select the file to open the pocket book and observe the steps to run the answer.
Run configurations to create a PySpark context
When the pocket book is open, be sure that the kernel is about to Sparkmagic (PySpark). Run the next block to arrange Spark configs for a Spark context.

Create a Nice Expectations context
In Nice Expectations, your knowledge context manages your mission configuration. We create an information context for our answer by passing our S3 bucket location. The S3 bucket’s title, created by the stack, ought to already be populated throughout the cell block. Run the next block to create a context:
For extra particulars on making a GE context, see Getting began with Nice Expectations.
Get GE validation guidelines from DynamoDB
Our CloudFormation stack created a DynamoDB desk with prepopulated rows of expectations. The information mannequin in DynamoDB describes the properties associated to every dataset and its columns and the variety of expectations you wish to configure for every column. The next code describes an instance of the info mannequin for the column group:
The code accommodates the next parameters:
- id – Distinctive ID of the doc
- dataset_name – Identify of the dataset, for instance
monster_com - guidelines – Record of GE expectations to use:
- kwargs – Parameters to move to a person expectation
- title – Identify of the expectation from the GE glossary
- reject_msg – String to flag for any row that doesn’t move this expectation
- column_name – Identify of dataset column to run the expectations on
Every column can have a number of expectations related that it must move. You may as well add expectations for extra columns or to present columns by following the info mannequin proven earlier. With this system, you possibly can automate verification of any variety of knowledge high quality guidelines in your datasets with out performing any code change. Aside from its flexibility, what makes GE highly effective is the flexibility to create customized expectations if the GE glossary doesn’t cowl your use case. For extra particulars on creating customized expectations, see How you can create customized Expectations.
Now run the cell block to fetch the GE guidelines from the DynamoDB shopper:
- Learn the
monster.compattern dataset and move by validation guidelines.
After we’ve the expectations fetched from DynamoDB, we are able to learn the uncooked CSV dataset. This dataset ought to already be copied to your S3 bucket location by the CloudFormation stack. You must see the next output after studying the CSV as a Spark DataFrame.
To judge whether or not a row passes every column’s expectations, we have to move the mandatory columns to a Spark user-defined operate. This UDF evaluates every row within the DataFrame and appends the outcomes of every expectation to a feedback column.

Rows that move all column expectations have a null worth within the feedback column.
A row that fails not less than one column expectation is flagged with the string format REJECT:reject_msg_from_dynamo. For instance, if a row has a null worth within the group column, then in keeping with the foundations outlined in DynamoDB, the feedback column is populated by the UDF as REJECT:null_values_found_in_organization.
The method with which the UDF operate acknowledges a probably faulty column is finished by evaluating the end result dictionary generated by the Nice Expectations library. The era and construction of this dictionary depends upon the key phrase argument of result_format. Briefly, if the rely of surprising column values of any column is bigger than zero, we flag that as a rejected row.
- Break up the ensuing dataset into accepted and rejected DataFrames.
Now that we’ve all of the rejected rows flagged within the supply DataFrame throughout the feedback column, we are able to use this property to separate the unique dataset into accepted and rejected DataFrames. Within the earlier step, we talked about that we append an motion message within the feedback column for every failed expectation in a row. With this truth, we are able to choose rejected rows that begin with the string REJECT (alternatively, you can too filter by non-null values within the feedback column to get the accepted rows). When we’ve the set of rejected rows, we are able to get the accepted rows as a separate DataFrame by utilizing the next PySpark besides operate.

Write the DataFrames to Amazon S3.
Now that we’ve the unique DataFrame divided, we are able to write them each to Amazon S3 in Parquet format. We have to write the accepted DataFrame with out the feedback column as a result of it’s solely added to flag rejected rows. Run the cell blocks to write down the Parquet recordsdata underneath acceptable prefixes as proven within the following screenshot.

Copy the accepted dataset to an Amazon Redshift desk
Now that we’ve written the accepted dataset, we are able to use the Amazon Redshift COPY command to load this dataset into an Amazon Redshift desk. The pocket book outlines the steps required to create a desk for the accepted dataset in Amazon Redshift utilizing the Amazon Redshift Information API. After the desk is created efficiently, we are able to run the COPY command.
One other noteworthy level to say is that one of many benefits that we witness as a result of knowledge high quality method described on this publish is that the Amazon Redshift COPY command doesn’t fail as a result of schema or datatype errors for the columns, which have clear expectations outlined that match the schema. Equally, you possibly can outline expectations for each column within the desk that satisfies the schema constraints and will be thought-about a dq_accepted.monster_com row.
Create an exterior desk in Amazon Redshift for rejected knowledge
We have to have the rejected rows obtainable to us in Amazon Redshift for comparative evaluation. These comparative analyses might help inform upstream techniques relating to the standard of knowledge being collected and the way they are often corrected to enhance the general high quality of knowledge. Nevertheless, it isn’t sensible to retailer the rejected knowledge on the Amazon Redshift cluster, significantly for giant tables, as a result of it occupies further disk area and improve value. As an alternative, we use Redshift Spectrum to register an exterior desk in an exterior schema in Amazon Redshift. The exterior schema lives in an exterior database within the AWS Glue Information Catalog and is referenced by Amazon Redshift. The next screenshot outlines the steps to create an exterior desk.
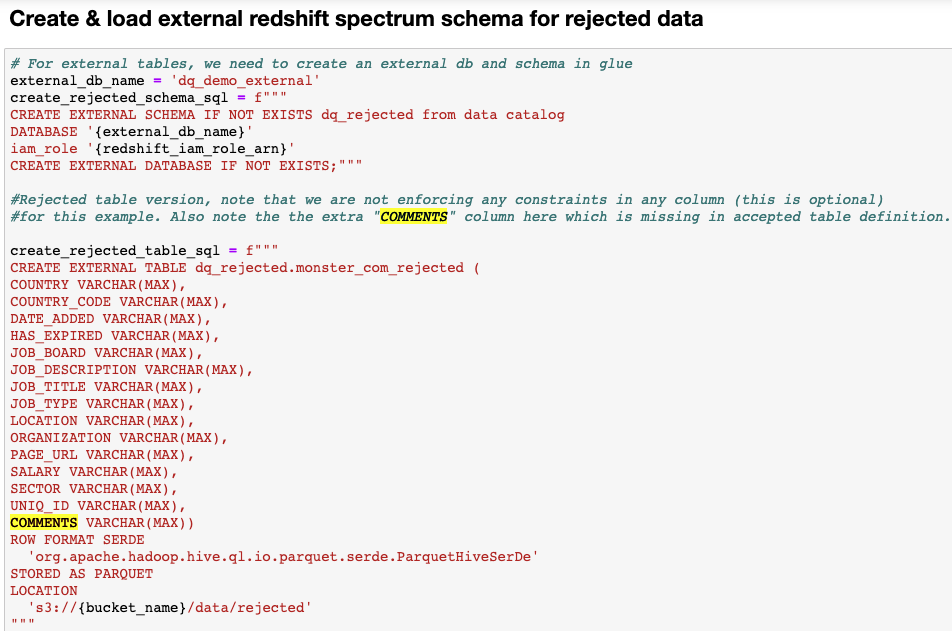
Confirm and examine the datasets in Amazon Redshift.
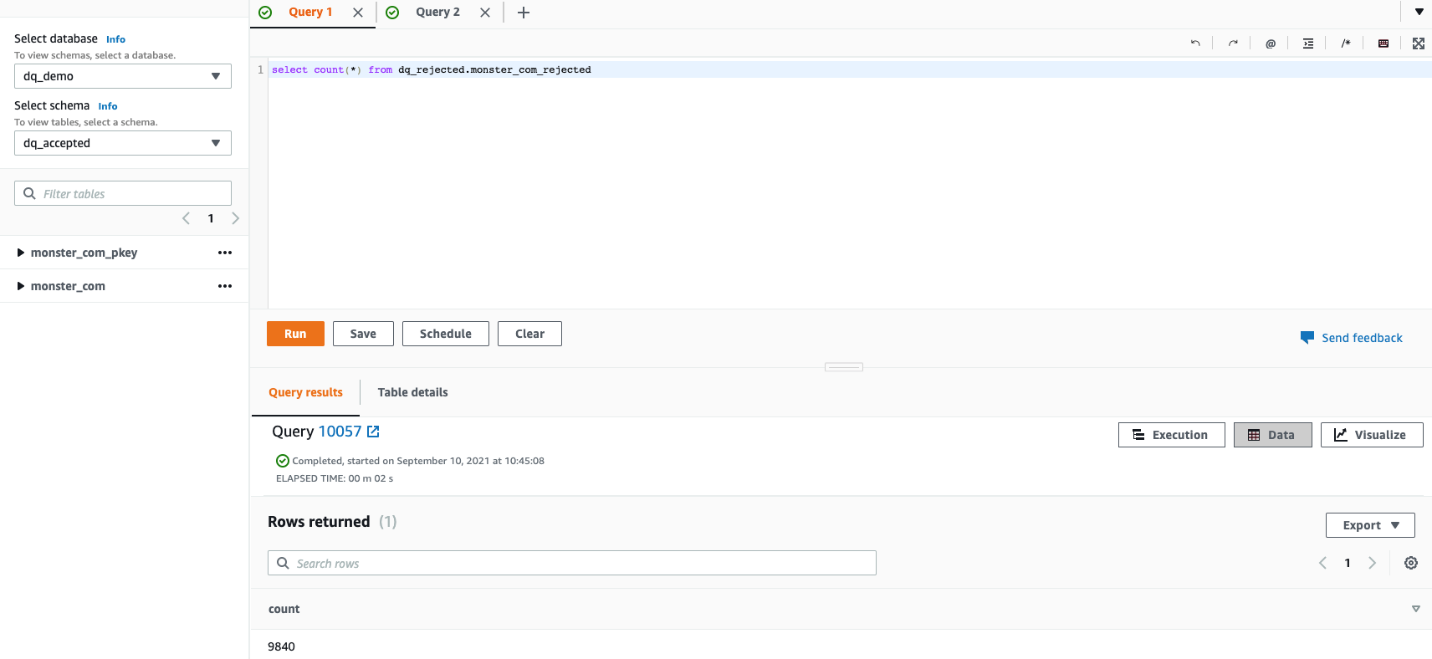
12,160 data obtained processed efficiently out of a complete of twenty-two,000 from the enter dataset, and had been loaded to the monster_com desk underneath the dq_accepted schema. These data efficiently handed all of the validation guidelines configured in DynamoDB.

A complete 9,840 data obtained rejected as a result of breaking of a number of guidelines configured in DynamoDB and loaded to the monster_com_rejected desk within the dq_rejected schema. On this part, we describe the conduct of every expectation on the dataset.
- Anticipate column values to not be null in
group– This rule is configured to reject a row if the group is null. The next question returns the pattern of rows, from thedq_rejected.monster_com_rejecteddesk, which arenullwithin thegroupcolumn, with their reject message.
- Anticipate column values to match the regex record in
job_type– This rule expects the column entries to be strings that may be matched to both any of or all of a listing of normal expressions. In our use case, we’ve solely allowed values that match a sample inside[".*Full.*Time", ".*Part.*Time", ".*Contract.*"]. - The next question reveals rows which are rejected as a result of an invalid job kind.

A lot of the data had been rejected with a number of causes, and all these mismatches are captured underneath the feedback column.
- Anticipate column values to not match regex for
uniq_id– Much like the earlier rule, this rule goals to reject any row whose worth matches a sure sample. In our case, that sample is having an empty area (s++) within the major columnuniq_id. This implies we contemplate a price to be invalid if it has empty areas within the string. The next question returned an invalid format foruniq_id.
- Anticipate column entries to be strings with a size between a minimal worth and a most worth (inclusive) – A size test rule is outlined within the DynamoDB desk for the
locationcolumn. This rule rejects values or rows if the size of the worth violates the required constraints. The next - question returns the data which are rejected as a result of a rule violation within the
locationcolumn.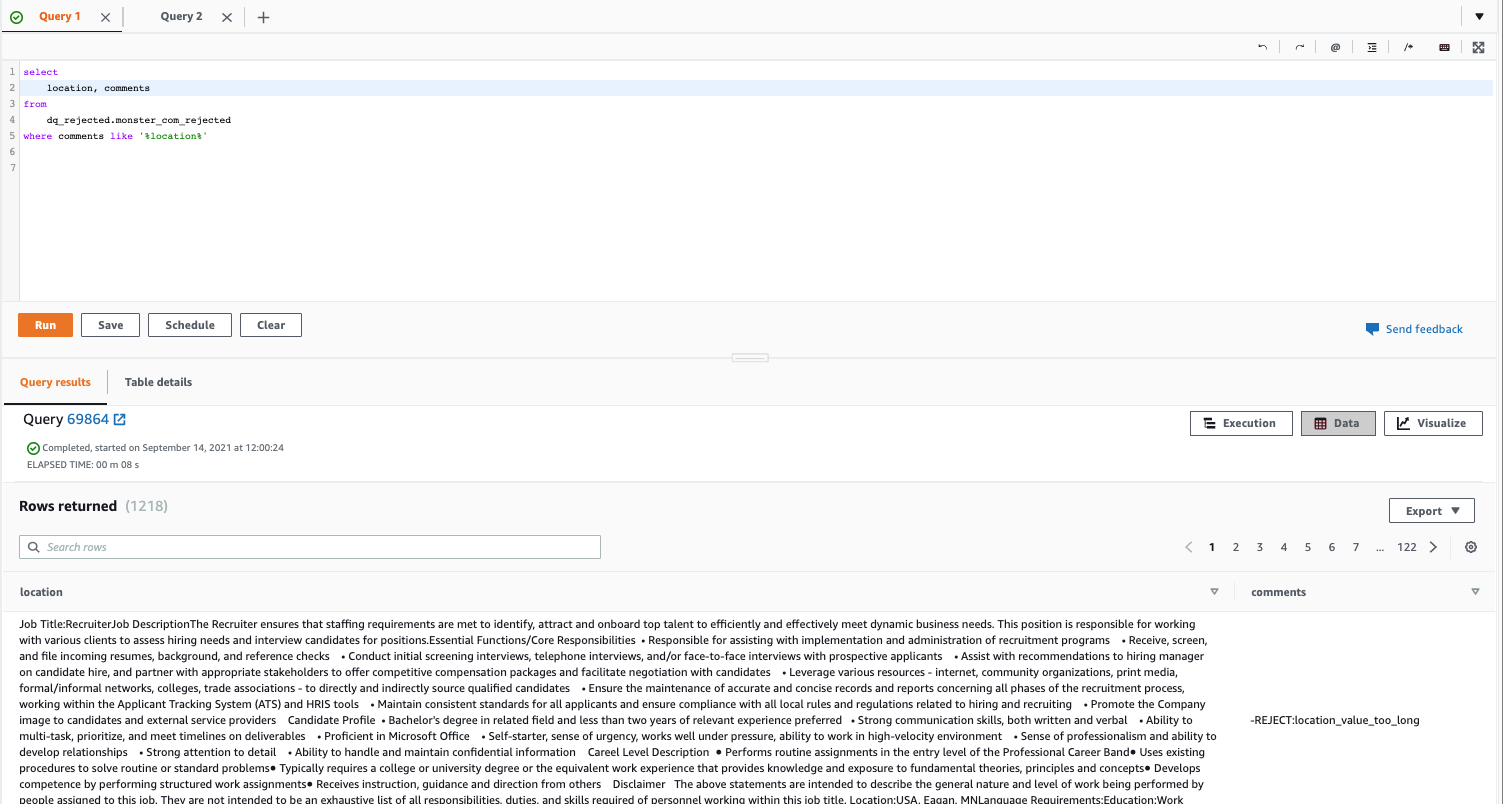
You’ll be able to proceed to research the opposite columns’ predefined guidelines from DynamoDB or decide any rule from the GE glossary and add it to an present column. Rerun the pocket book to see the results of your knowledge high quality guidelines in Amazon Redshift. As talked about earlier, you can too strive creating customized expectations for different columns.
Advantages and limitations
The effectivity and efficacy of this method is delineated from the truth that GE allows automation and configurability to an intensive diploma when put next with different approaches. A really brute pressure various to this may very well be writing saved procedures in Amazon Redshift that may carry out knowledge high quality checks on staging tables earlier than knowledge is loaded into most important tables. Nevertheless, this method won’t be scalable as a result of you possibly can’t persist repeatable guidelines for various columns, as endured right here in DynamoDB, in saved procedures (or name DynamoDB APIs), and must write and retailer a rule for every column of each desk. Moreover, to just accept or reject a row primarily based on a single rule requires complicated SQL statements which will lead to longer durations for knowledge high quality checks or much more compute energy, which may additionally incur further prices. With GE, an information high quality rule is generic, repeatable, and scalable throughout totally different datasets.
One other advantage of this method, associated to utilizing GE, is that it helps a number of Python-based backends, together with Spark, Pandas, and Dask. This offers flexibility throughout a corporation the place groups may need abilities in several frameworks. If an information scientist prefers utilizing Pandas to write down their ML pipeline function high quality take a look at, then an information engineer utilizing PySpark can use the identical code base to increase these checks as a result of consistency of GE throughout backends.
Moreover, GE is written natively in Python, which suggests it’s a very good possibility for engineers and scientists who’re extra used to working their extract, remodel, and cargo (ETL) workloads in PySpark compared to frameworks like Deequ, which is natively written in Scala over Apache Spark and matches higher for Scala use circumstances (the Python interface, PyDeequ, can be obtainable). One other advantage of utilizing GE is the flexibility to run multi-column unit checks on knowledge, whereas Deequ doesn’t help that (as of this writing).
Nevertheless, the method described on this publish won’t be essentially the most performant in some circumstances for full desk load batch reads for very giant tables. That is as a result of serde (serialization/deserialization) value of utilizing UDFs. As a result of the GE features are embedded in PySpark UDFs, the efficiency of those features is slower than native Spark features. Subsequently, this method provides the perfect efficiency when built-in with incremental knowledge processing workflows, for instance utilizing AWS DMS to write down CDC recordsdata from a supply database to Amazon S3.
Clear up
A number of the sources deployed on this publish, together with these deployed utilizing the offered CloudFormation template, incur prices so long as they’re in use. Make sure you take away the sources and clear up your work if you’re completed as a way to keep away from pointless value.
Go to the CloudFormation console and click on the ‘delete stack’ to take away all sources.
The sources within the CloudFormation template aren’t manufacturing prepared. If you want to make use of this answer in manufacturing, allow logging for all S3 buckets and make sure the answer adheres to your group’s encryption insurance policies by EMR Safety Greatest Practices.
Conclusion
On this publish, we demonstrated how one can automate knowledge reliability checks utilizing the Nice Expectations library earlier than loading knowledge into an Amazon Redshift desk. We additionally confirmed how you need to use Redshift Spectrum to create exterior tables. If soiled knowledge had been to make its manner into the accepted desk, all downstream shoppers corresponding to enterprise intelligence reporting, superior analytics, and ML pipelines can get affected and produce inaccurate experiences and outcomes. The traits of such knowledge can generate fallacious leads for enterprise leaders whereas making enterprise selections. Moreover, flagging soiled knowledge as rejected earlier than loading into Amazon Redshift additionally helps cut back the effort and time an information engineer may need to spend as a way to examine and proper the info.
We have an interest to listen to the way you want to apply this answer in your use case. Please share your ideas and questions within the feedback part.
Concerning the Authors
 Faizan Ahmed is a Information Architect at AWS Skilled Companies. He likes to construct knowledge lakes and self-service analytics platforms for his clients. He additionally enjoys studying new applied sciences and fixing, automating, and simplifying buyer issues with easy-to-use cloud knowledge options on AWS. In his free time, Faizan enjoys touring, sports activities, and studying.
Faizan Ahmed is a Information Architect at AWS Skilled Companies. He likes to construct knowledge lakes and self-service analytics platforms for his clients. He additionally enjoys studying new applied sciences and fixing, automating, and simplifying buyer issues with easy-to-use cloud knowledge options on AWS. In his free time, Faizan enjoys touring, sports activities, and studying.
 Bharath Kumar Boggarapu is a Information Architect at AWS Skilled Companies with experience in huge knowledge applied sciences. He’s obsessed with serving to clients construct performant and sturdy data-driven options and understand their knowledge and analytics potential. His areas of pursuits are open-source frameworks, automation, and knowledge architecting. In his free time, he likes to spend time with household, play tennis, and journey.
Bharath Kumar Boggarapu is a Information Architect at AWS Skilled Companies with experience in huge knowledge applied sciences. He’s obsessed with serving to clients construct performant and sturdy data-driven options and understand their knowledge and analytics potential. His areas of pursuits are open-source frameworks, automation, and knowledge architecting. In his free time, he likes to spend time with household, play tennis, and journey.
[ad_2]