
 Instrument")
{kind=link}
[ad_1]
Understanding and evaluating your synthetic intelligence (AI) system’s predictions will be difficult. AI and machine studying (ML) classifiers are topic to limitations brought on by a wide range of components, together with idea or knowledge drift, edge circumstances, the pure uncertainty of ML coaching outcomes, and rising phenomena unaccounted for in coaching knowledge. A majority of these components can result in bias in a classifier’s predictions, compromising choices made primarily based on these predictions.
The SEI has developed a new AI robustness (AIR) software to assist applications higher perceive and enhance their AI classifier efficiency. On this weblog put up, we clarify how the AIR software works, present an instance of its use, and invite you to work with us if you wish to use the AIR software in your group.
Challenges in Measuring Classifier Accuracy
There may be little doubt that AI and ML instruments are a number of the strongest instruments developed within the final a number of a long time. They’re revolutionizing fashionable science and expertise within the fields of prediction, automation, cybersecurity, intelligence gathering, coaching and simulation, and object detection, to call only a few. There may be accountability that comes with this nice energy, nonetheless. As a neighborhood, we should be conscious of the idiosyncrasies and weaknesses related to these instruments and guarantee we’re taking these under consideration.
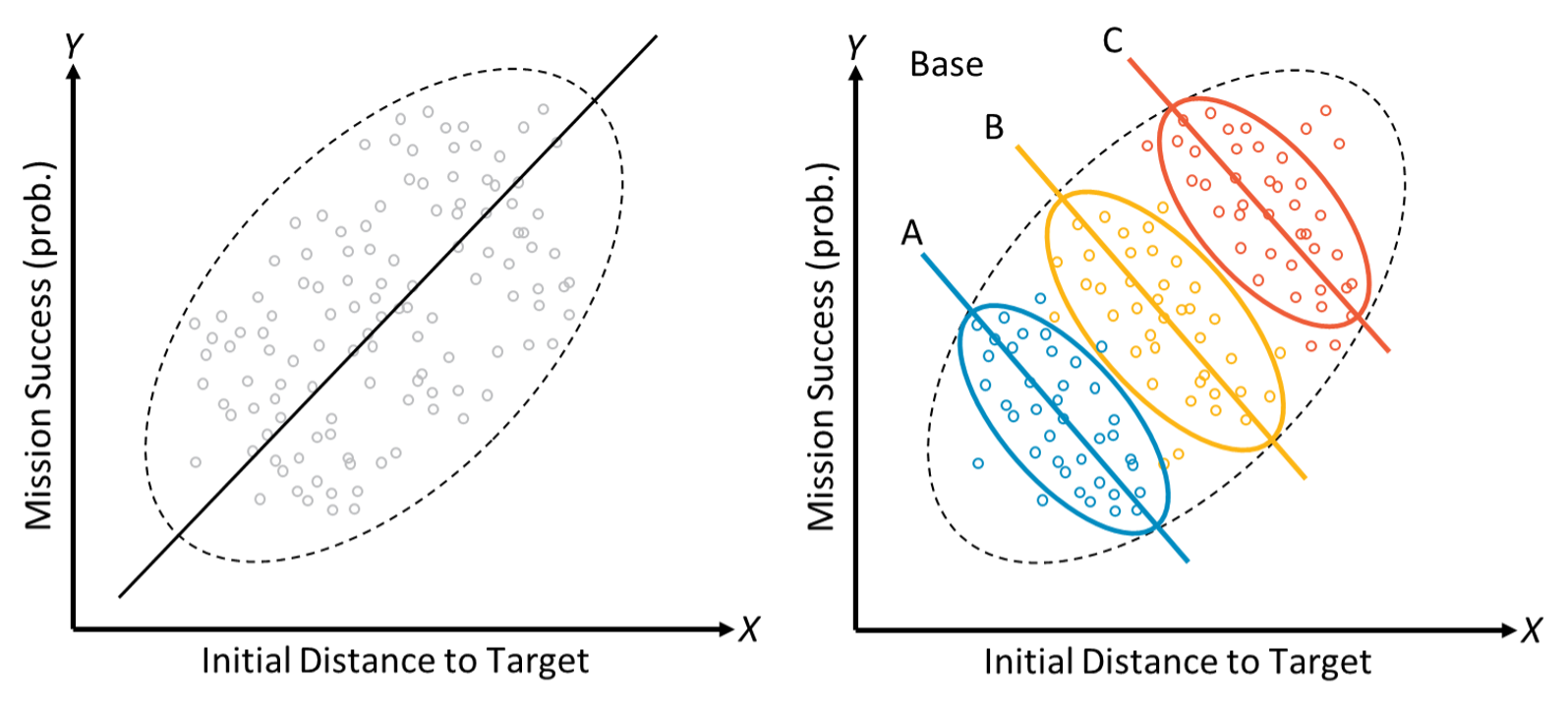
One of many best strengths of AI and ML is the power to successfully acknowledge and mannequin correlations (actual or imagined) throughout the knowledge, resulting in modeling capabilities that in lots of areas excel at prediction past the strategies of classical statistics. Such heavy reliance on correlations throughout the knowledge, nonetheless, can simply be undermined by knowledge or idea drift, evolving edge circumstances, and rising phenomena. This could result in fashions that will go away different explanations unexplored, fail to account for key drivers, and even probably attribute causes to the improper components. Determine 1 illustrates this: at first look (left) one would possibly moderately conclude that the likelihood of mission success seems to extend as preliminary distance to the goal grows. Nonetheless, if one provides in a 3rd variable for base location (the coloured ovals on the suitable of Determine 1), the connection reverses as a result of base location is a standard reason behind each success and distance. That is an instance of a statistical phenomenon often called Simpson’s Paradox, the place a pattern in teams of information reverses or disappears after the teams are mixed. This instance is only one illustration of why it’s essential to know sources of bias in a single’s knowledge.
{kind=link}
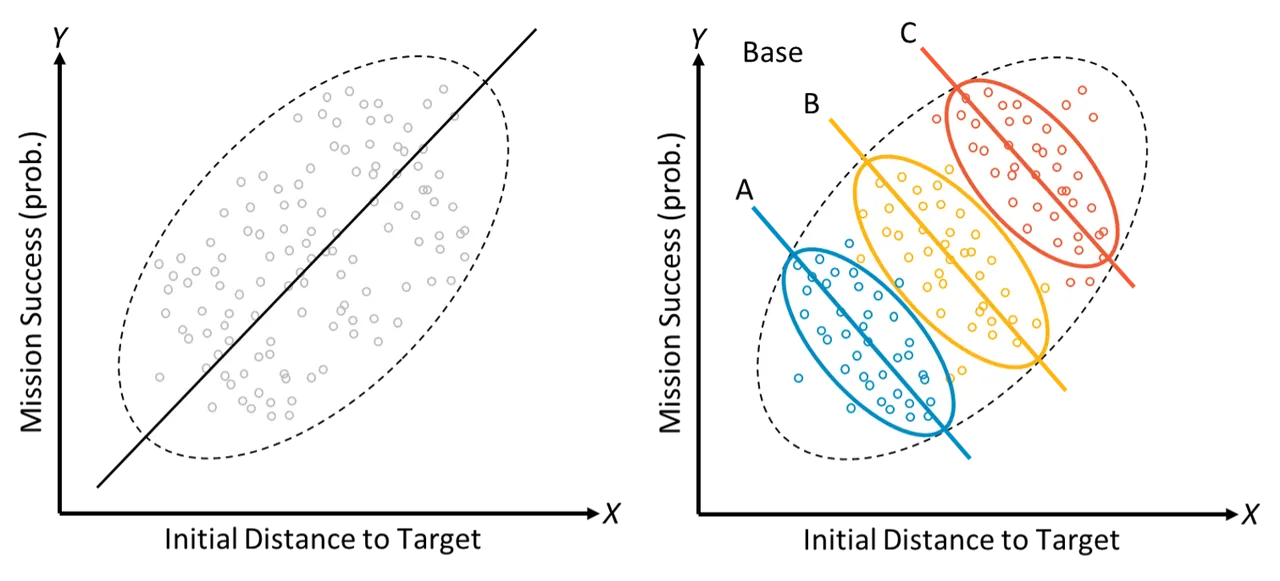
Determine 1: An illustration of Simpson’s Paradox
To be efficient in important downside areas, classifiers additionally should be strong: they want to have the ability to produce correct outcomes over time throughout a variety of eventualities. When classifiers grow to be untrustworthy on account of rising knowledge (new patterns or distributions within the knowledge that weren’t current within the unique coaching set) or idea drift (when the statistical properties of the end result variable change over time in unexpected methods), they could grow to be much less doubtless for use, or worse, might misguide a important operational determination. Usually, to guage a classifier, one compares its predictions on a set of information to its anticipated conduct (floor fact). For AI and ML classifiers, the info initially used to coach a classifier could also be insufficient to yield dependable future predictions on account of modifications in context, threats, the deployed system itself, and the eventualities into consideration. Thus, there is no such thing as a supply for dependable floor fact over time.
Additional, classifiers are sometimes unable to extrapolate reliably to knowledge they haven’t but seen as they encounter sudden or unfamiliar contexts that weren’t aligned with the coaching knowledge. As a easy instance, for those who’re planning a flight mission from a base in a heat atmosphere however your coaching knowledge solely contains cold-weather flights, predictions about gasoline necessities and system well being may not be correct. For these causes, it’s important to take causation under consideration. Understanding the causal construction of the info may help establish the varied complexities related to conventional AI and ML classifiers.
Causal Studying on the SEI
Causal studying is a subject of statistics and ML that focuses on defining and estimating trigger and impact in a scientific, data-driven means, aiming to uncover the underlying mechanisms that generate the noticed outcomes. Whereas ML produces a mannequin that can be utilized for prediction from new knowledge, causal studying differs in its deal with modeling, or discovering, the cause-effect relationships inferable from a dataset. It solutions questions corresponding to:
- How did the info come to be the best way it’s?
- What system or context attributes are driving which outcomes?
Causal studying helps us formally reply the query of “does X trigger Y, or is there another motive why they at all times appear to happen collectively?” For instance, let’s say we’ve these two variables, X and Y, which are clearly correlated. People traditionally have a tendency to take a look at time-correlated occasions and assign causation. We would motive: first X occurs, then Y occurs, so clearly X causes Y. However how can we take a look at this formally? Till just lately, there was no formal methodology for testing causal questions like this. Causal studying permits us to construct causal diagrams, account for bias and confounders, and estimate the magnitude of impact even in unexplored eventualities.
Latest SEI analysis has utilized causal studying to figuring out how strong AI and ML system predictions are within the face of circumstances and different edge circumstances which are excessive relative to the coaching knowledge. The AIR software, constructed on the SEI’s physique of labor in informal studying, supplies a brand new functionality to guage and enhance classifier efficiency that, with the assistance of our companions, might be able to be transitioned to the DoD neighborhood.
How the AIR Instrument Works
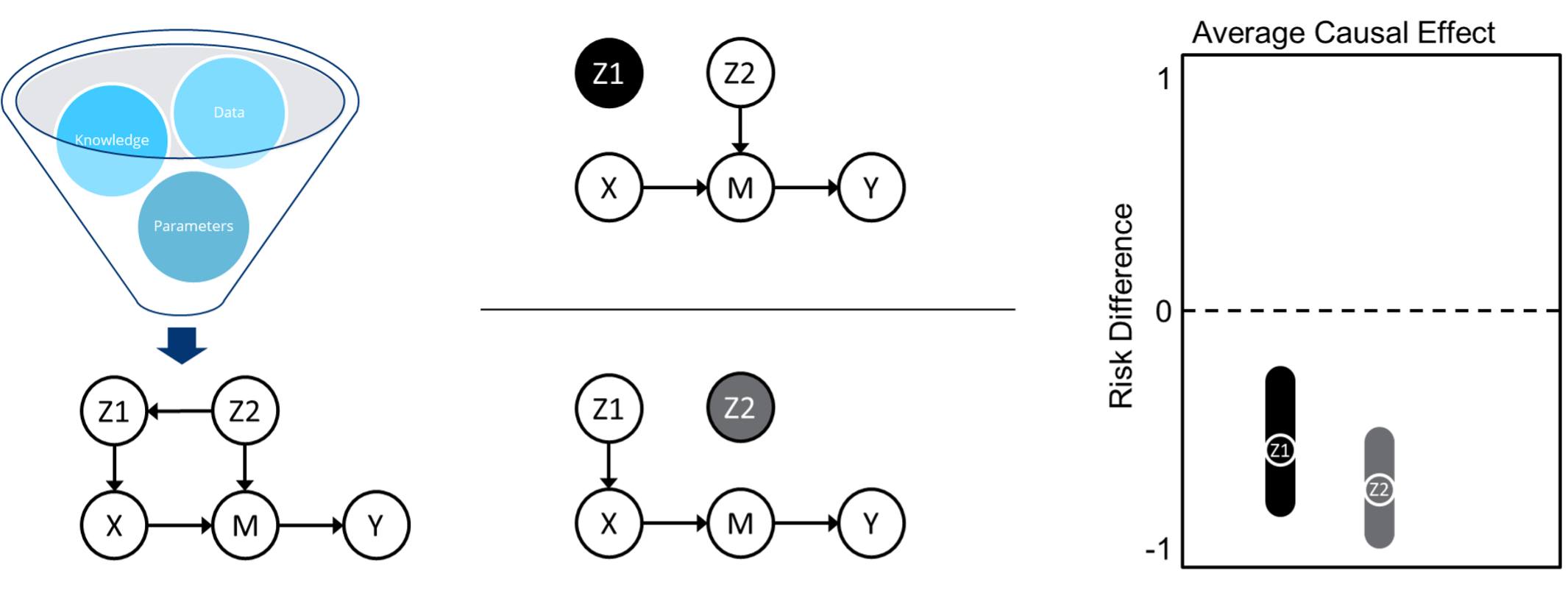
AIR is an end-to-end causal inference software that builds a causal graph of the info, performs graph manipulations to establish key sources of potential bias, and makes use of state-of-the-art ML algorithms to estimate the typical causal impact of a situation on an final result, as illustrated in Determine 2. It does this by combining three disparate, and infrequently siloed, fields from throughout the causal studying panorama: causal discovery for constructing causal graphs from knowledge, causal identification for figuring out potential sources of bias in a graph, and causal estimation for calculating causal results given a graph. Operating the AIR software requires minimal handbook effort—a person uploads their knowledge, defines some tough causal data and assumptions (with some steering), and selects acceptable variable definitions from a dropdown checklist.
{kind=link}
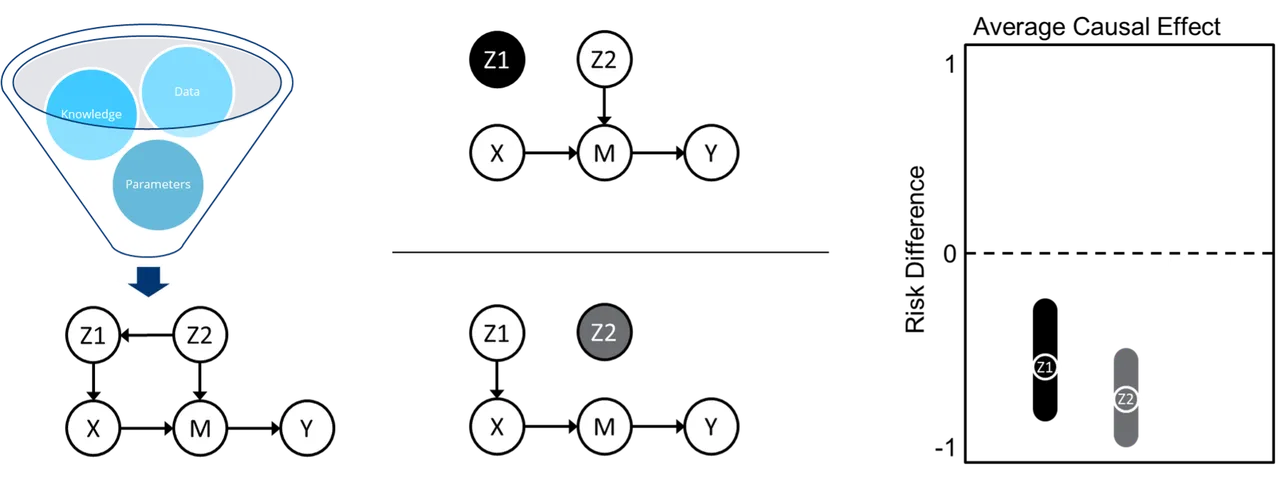
Determine 2: Steps within the AIR software
Causal discovery, on the left of Determine 2, takes inputs of information, tough causal data and assumptions, and mannequin parameters and outputs a causal graph. For this, we make the most of a state-of-the-art causal discovery algorithm known as Finest Order Rating Search (BOSS). The ensuing graph consists of a situation variable (X), an final result variable (Y), any intermediate variables (M), dad and mom of both X (Z1) or M (Z2), and the path of their causal relationship within the type of arrows.
Causal identification, in the course of Determine 2, splits the graph into two separate adjustment units geared toward blocking backdoor paths via which bias will be launched. This goals to keep away from any spurious correlation between X and Y that is because of frequent causes of both X or M that may have an effect on Y. For instance, Z2 is proven right here to have an effect on each X (via Z1) and Y (via M). To account for bias, we have to break any correlations between these variables.
Lastly, causal estimation, illustrated on the suitable of Determine 2, makes use of an ML ensemble of doubly-robust estimators to calculate the impact of the situation variable on the end result and produce 95% confidence intervals related to every adjustment set from the causal identification step. Doubly-robust estimators enable us to supply constant outcomes even when the end result mannequin (what’s likelihood of an final result?) or the therapy mannequin (what’s the likelihood of getting this distribution of situation variables given the end result?) is specified incorrectly.
{kind=link}
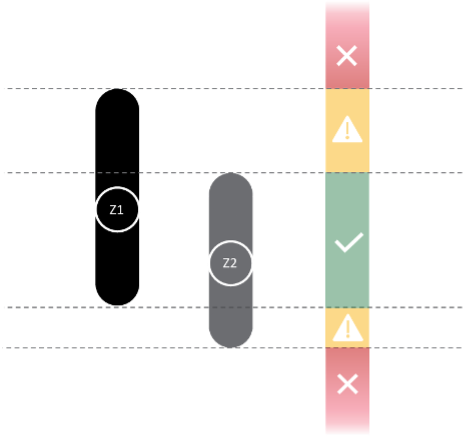
Determine 3: Deciphering the AIR software’s outcomes
The 95% confidence intervals calculated by AIR present two impartial checks on the conduct, or predicted final result, of the classifier on a situation of curiosity. Whereas it could be an aberration if just one set of the 2 bands is violated, it might even be a warning to watch classifier efficiency for that situation frequently sooner or later. If each bands are violated, a person ought to be cautious of classifier predictions for that situation. Determine 3 illustrates an instance of two confidence interval bands.
The 2 adjustment units output from AIR present suggestions of what variables or options to deal with for subsequent classifier retraining. Sooner or later, we’d prefer to make use of the causal graph along with the discovered relationships to generate artificial coaching knowledge for enhancing classifier predictions.
The AIR Instrument in Motion
To show how the AIR software could be utilized in a real-world situation, think about the next instance. A notional DoD program is utilizing unmanned aerial autos (UAVs) to gather imagery, and the UAVs can begin the mission from two completely different base areas. Every location has completely different environmental circumstances related to it, corresponding to wind velocity and humidity. This system seeks to foretell mission success, outlined because the UAV efficiently buying pictures, primarily based on the beginning location, and so they have constructed a classifier to assist of their predictions. Right here, the situation variable, or X, is the bottom location.
This system might wish to perceive not simply what mission success seems like primarily based on which base is used, however why. Unrelated occasions might find yourself altering the worth or influence of environmental variables sufficient that the classifier efficiency begins to degrade.
{kind=link}
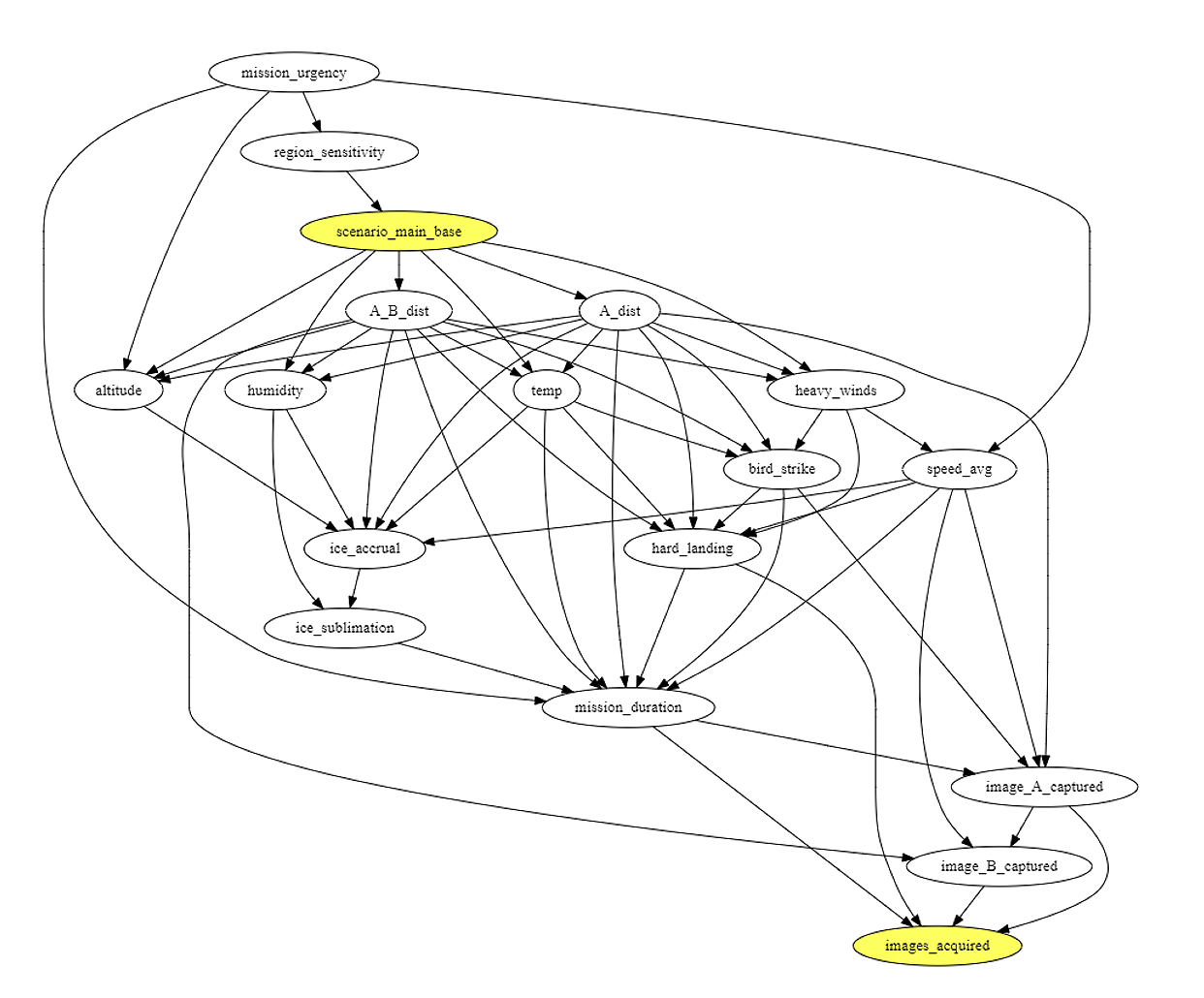
Determine 4: Causal graph of direct cause-effect relationships within the UAV instance situation.
Step one of the AIR software applies causal discovery instruments to generate a causal graph (Determine 4) of the probably cause-and-effect relationships amongst variables. For instance, ambient temperature impacts the quantity of ice accumulation a UAV would possibly expertise, which may have an effect on whether or not the UAV is ready to efficiently fulfill its mission of acquiring pictures.
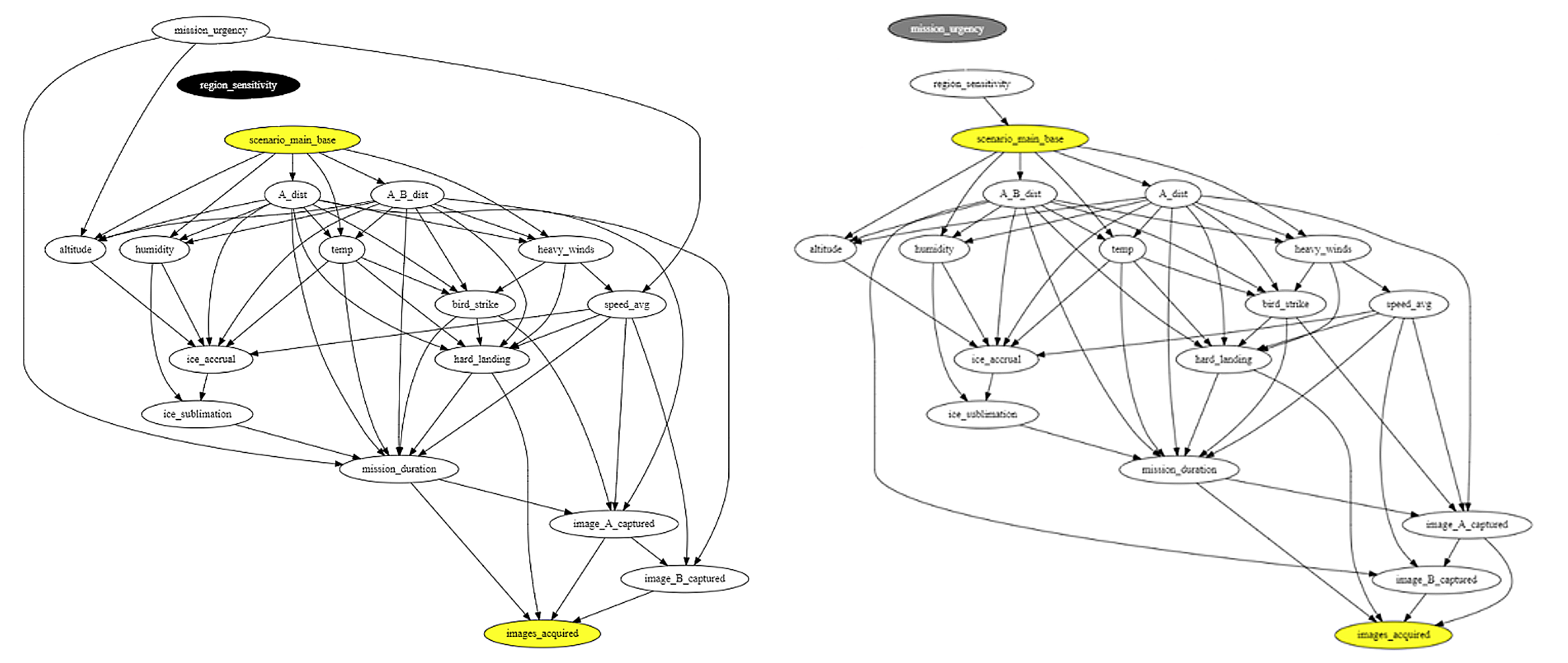
In step 2, AIR infers two adjustment units to assist detect bias in a classifier’s predictions (Determine 5). The graph on the left is the results of controlling for the dad and mom of the primary base therapy variable. The graph to the suitable is the results of controlling for the dad and mom of the intermediate variables (aside from different intermediate variables) corresponding to environmental circumstances. Eradicating edges from these adjustment units removes potential confounding results, permitting AIR to characterize the influence that selecting the primary base has on mission success.
{kind=link}
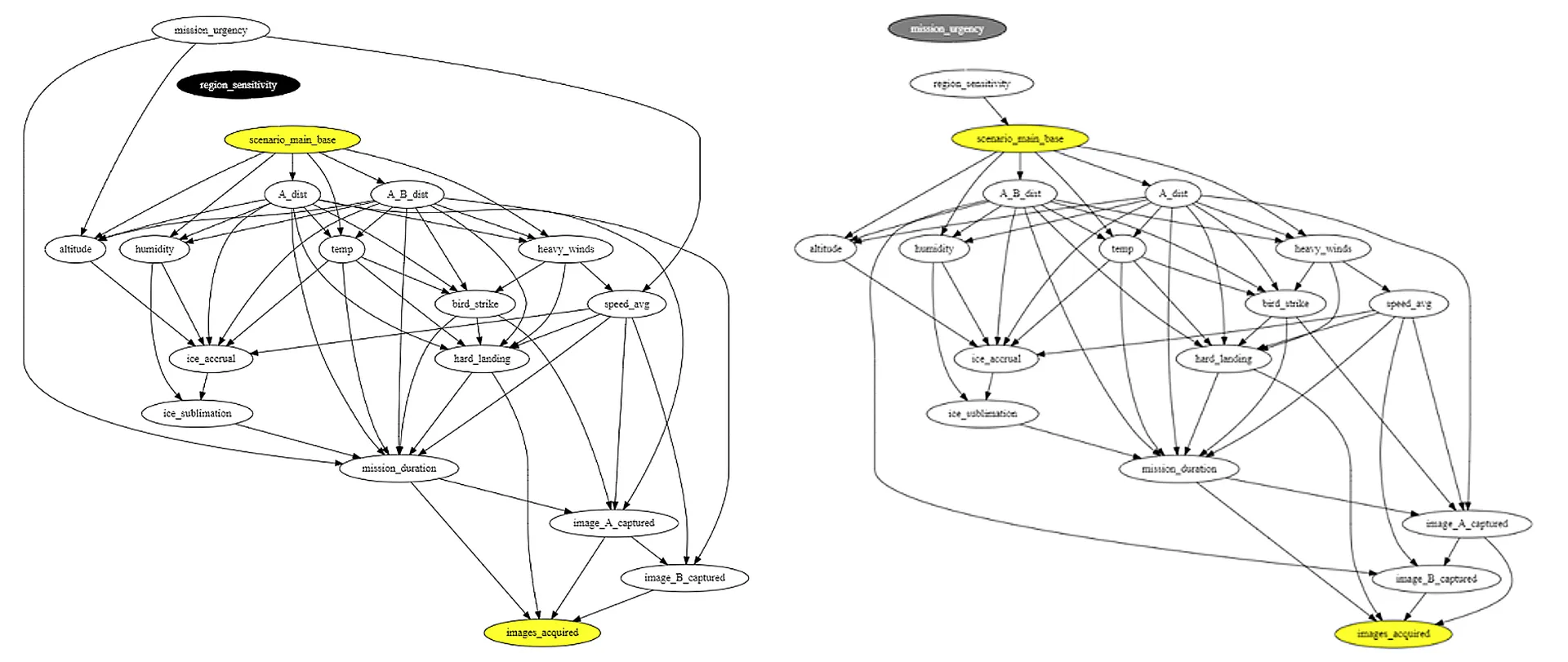
Determine 5: Causal graphs akin to the 2 adjustment units.
Lastly, in step 3, AIR calculates the chance distinction that the primary base selection has on mission success. This danger distinction is calculated by making use of non-parametric, doubly-robust estimators to the duty of estimating the influence that X has on Y, adjusting for every set individually. The result’s some extent estimate and a confidence vary, proven right here in Determine 6. Because the plot reveals, the ranges for every set are comparable, and analysts can now examine these ranges to the classifier prediction.
{kind=link}

Determine 6: Danger distinction plot displaying the typical causal impact (ACE) of every adjustment set (i.e., Z1 and Z2) alongside AI/ML classifiers. The continuum ranges from -1 to 1 (left to proper) and is coloured primarily based on degree of settlement with ACE intervals.
Determine 6 represents the chance distinction related to a change within the variable, i.e., scenario_main_base. The x-axis ranges from optimistic to unfavorable impact, the place the situation both will increase the chance of the end result or decreases it, respectively; the midpoint right here corresponds to no vital impact. Alongside the causally-derived confidence intervals, we additionally incorporate a five-point estimate of the chance distinction as realized by 5 widespread ML algorithms—determination tree, logistic regression, random forest, stacked tremendous learner, and assist vector machine. These inclusions illustrate that these issues should not explicit to any particular ML algorithm. ML algorithms are designed to be taught from correlation, not the deeper causal relationships implied by the identical knowledge. The classifiers’ prediction danger variations, represented by varied mild blue shapes, fall outdoors the AIR-calculated causal bands. This outcome signifies that these classifiers are doubtless not accounting for confounding on account of some variables, and the AI classifier(s) ought to be re-trained with extra knowledge—on this case, representing launch from primary base versus launch from one other base with a wide range of values for the variables showing within the two adjustment units. Sooner or later, the SEI plans so as to add a well being report to assist the AI classifier maintainer establish further methods to enhance AI classifier efficiency.
Utilizing the AIR software, this system staff on this situation now has a greater understanding of the info and extra explainable AI.
How Generalizable is the AIR Instrument?
The AIR software can be utilized throughout a broad vary of contexts and eventualities. For instance, organizations with classifiers employed to assist make enterprise choices about prognostic well being upkeep, automation, object detection, cybersecurity, intelligence gathering, simulation, and plenty of different purposes might discover worth in implementing AIR.
Whereas the AIR software is generalizable to eventualities of curiosity from many fields, it does require a consultant knowledge set that meets present software necessities. If the underlying knowledge set is of cheap high quality and completeness (i.e., the info contains vital causes of each therapy and final result) the software will be utilized extensively.
Alternatives to Companion
The AIR staff is presently searching for collaborators to contribute to and affect the continued maturation of the AIR software. In case your group has AI or ML classifiers and subject-matter specialists to assist us perceive your knowledge, our staff may help you construct a tailor-made implementation of the AIR software. You’ll work carefully with the SEI AIR staff, experimenting with the software to find out about your classifiers’ efficiency and to assist our ongoing analysis into evolution and adoption. A number of the roles that might profit from—and assist us enhance—the AIR software embody:
- ML engineers—serving to establish take a look at circumstances and validate the info
- knowledge engineers—creating knowledge fashions to drive causal discovery and inference phases
- high quality engineers—making certain the AIR software is utilizing acceptable verification and validation strategies
- program leaders—deciphering the data from the AIR software
With SEI adoption assist, partnering organizations acquire in-house experience, revolutionary perception into causal studying, and data to enhance AI and ML classifiers.
[ad_2]