

{kind=link}
[ad_1]
It is a visitor authored submit by Bart Del Piero, Knowledge Scientist, DPG Media.
Firstly of a marketing campaign, entrepreneurs and publishers will usually have a speculation of who the goal section can be, however as soon as a marketing campaign begins, it may be very tough to see who truly responds, summary a section based mostly on the totally different qualities of the totally different respondents, after which modify concentrating on based mostly off these segments in a well timed method. Machine studying, nevertheless, could make it doable to sift by means of giant volumes of respondent and non-respondent viewers knowledge in close to real-time to mechanically create lookalike audiences particular to the nice or service being marketed, growing promoting ROI (and the value publishers can cost for his or her advert stock whereas nonetheless growing the worth for his or her shoppers).
Within the focused promoting area at DPG Media, we attempt to discover new methods to greatest ship high-quality and marketable segments to our advertisers. One strategy to optimizing advertising and marketing campaigns is thru the usage of ‘low time to market’-lookalikes of high-value clickers and presenting them to the advertiser as an improved deal.
This is able to entail constructing a system that permits us to coach a classification mannequin that ‘learns’ throughout the marketing campaign lifetime based mostly on a steady feed of information (principally by means of day by day batches), which leads to day by day up to date and improved goal audiences for a number of advertising and marketing and advert campaigns. This logic may be visualized as follows:
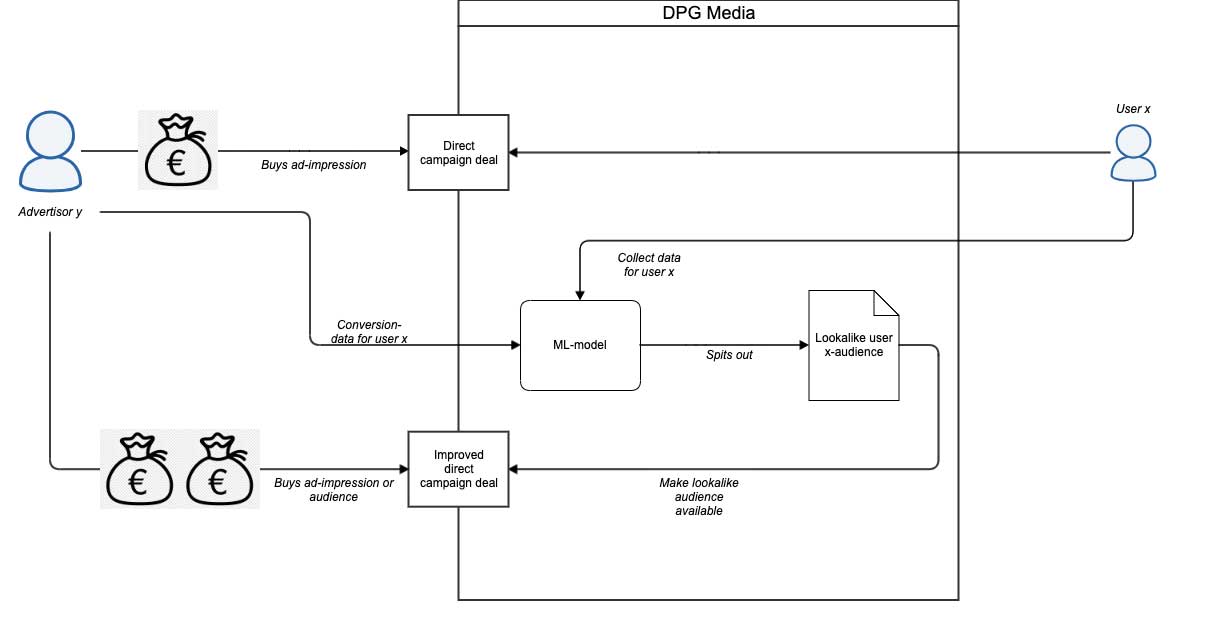
This leads to two fundamental questions:
- Can we create a lookalike mannequin that learns marketing campaign click-behaviour over time?
- Can this complete setup run easily and with a low runtime to maximise income?
To reply these questions, this weblog submit focuses on two applied sciences throughout the Databricks setting: Hyperopt and PandasUDF.
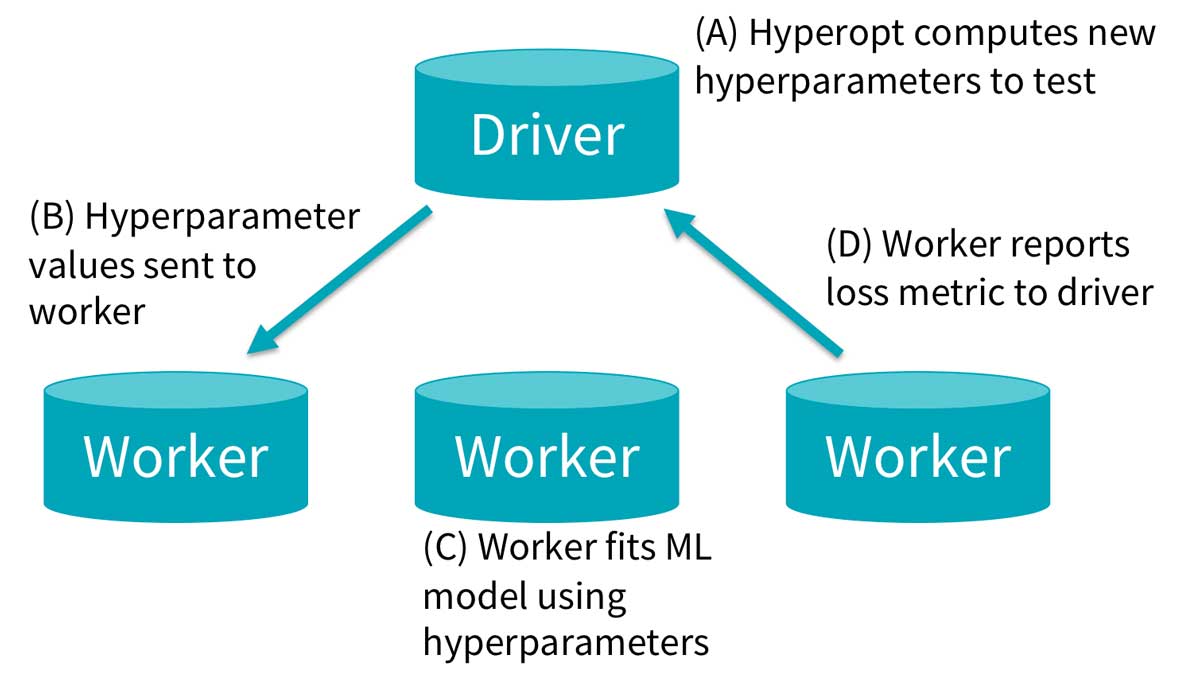
Hyperopt
In a nutshell, Hyperopt permits us to shortly prepare and match a number of sklearn-models throughout a number of executors for hyperparameter tuning and may seek for the optimum configuration based mostly on earlier evaluations. As we try to match a number of fashions per marketing campaign, for a number of campaigns, this permits us to shortly get the perfect hyperparameter configuration, leading to the perfect loss, in a really quick time interval (eg: round 14 minutes for preprocessing and optimizing a random forest with 24 evaluations and a parallelism-parameter of 16). Necessary right here is that our label is the propensity to click on (i.e., a likelihood), moderately than being a clicker (a category). Afterward, the mannequin with the bottom loss (outlined as – AUC of the Precision-Recall), is written to MLflow. This course of is completed as soon as per week or if the marketing campaign has simply began and we get extra knowledge for that particular marketing campaign in comparison with the day past.
PandasUDF
After we now have our mannequin, we need to draw inferences on all guests of our websites for the final 30 days. To do that, we question the most recent, greatest mannequin from MLflow and broadcast this over all executors. As a result of the information set we need to rating is kind of giant, we distribute it in n-partitions and let every executor rating a distinct partition; all of that is performed by leveraging the PandasUDF-logic. The chances then get collected again to the motive force, and customers get ranked from lowest propensity to click on, to highest propensity to click on:
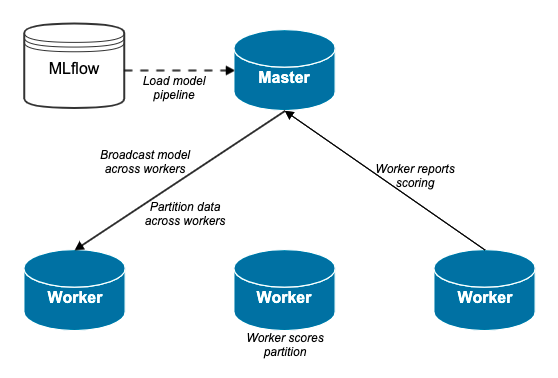
Leveraging PandasUDF-logic with MLflow to attain customers based mostly on their propensity to click on.
After this, we choose a threshold based mostly on quantity vs high quality (this can be a business-driven alternative relying on how a lot ad-space we now have for a given marketing campaign) and create a section for it in our knowledge administration platform (DMP).
Conclusion
In brief, we will summarize the complete course of as follows
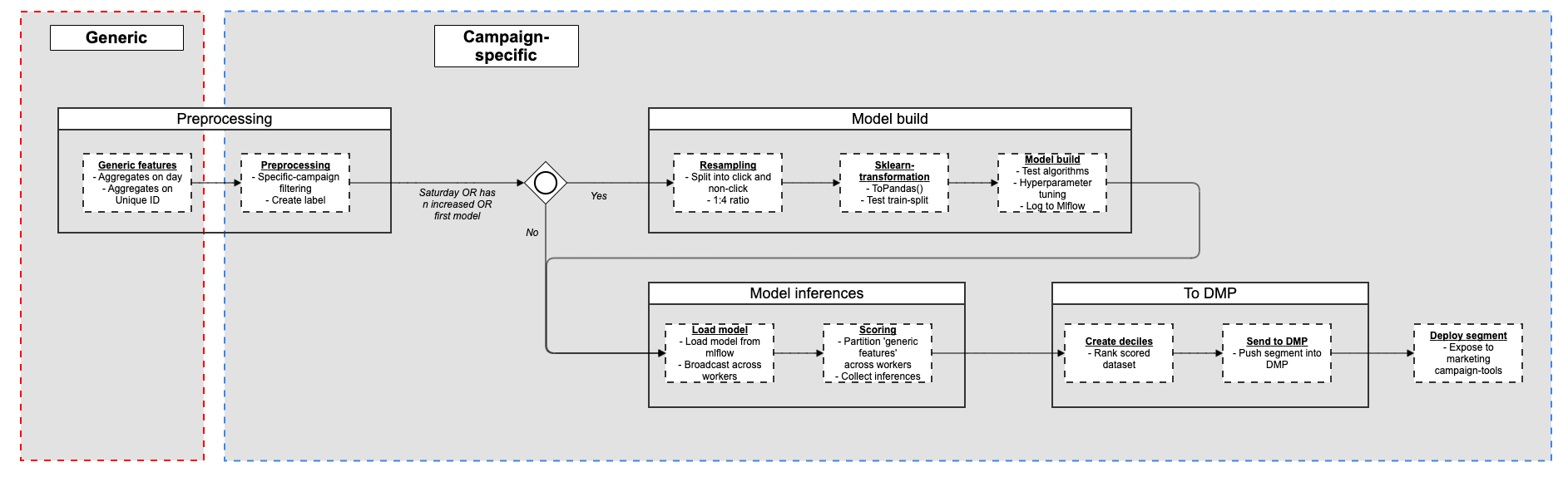
This complete course of runs round one hour per marketing campaign if we retrain the fashions. If not, it takes about half-hour per day to load and rating new audiences. We purpose to maintain the runtime as little as doable so we will account for extra campaigns. By way of the standard of those audiences, they will differ considerably, in any case, there isn’t any such factor as a free lunch in machine studying.
For brand spanking new campaigns with out many conversions, we see the mannequin bettering when extra knowledge is gathered in day by day batches and our estimates are getting higher. For instance, for a random marketing campaign the place:
- Imply: Common Precision-Recall AUC of all evaluations throughout the day by day hyperopt-run
- Max: Highest Precision-Recall AUC of an analysis throughout the day by day hyperopt-run
- Min: Lowest Precision-Recall AUC of an analysis throughout the day by day hyperopt-run
- St Dev: Commonplace deviation Precision-Recall AUC of all evaluations throughout the day by day hyperopt-run
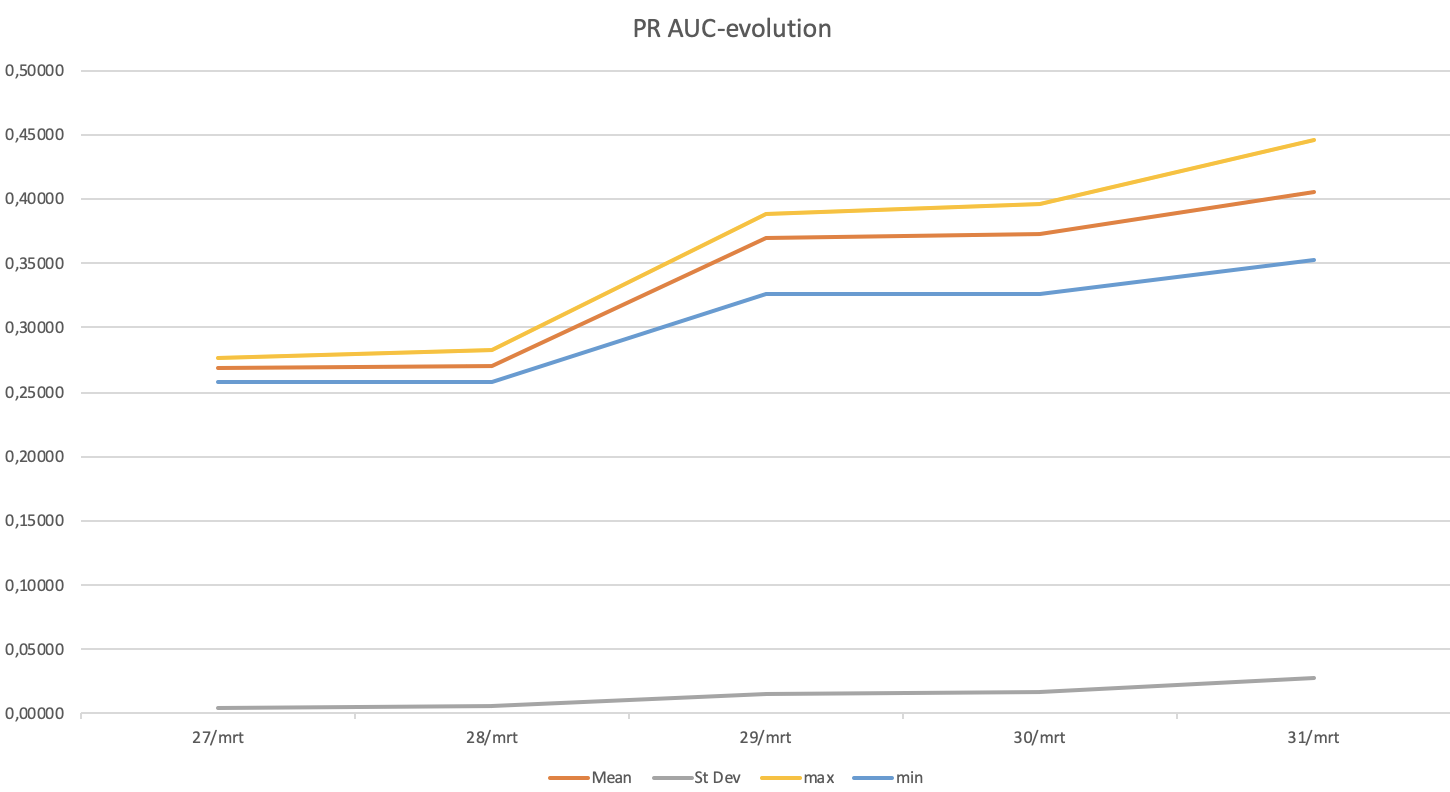
AUC of precision-recall apart, for advertisers, crucial metric is the click-through charge. We examined this mannequin for 2 advert campaigns and in contrast it to a standard run-off community marketing campaign. This produced the next outcomes:
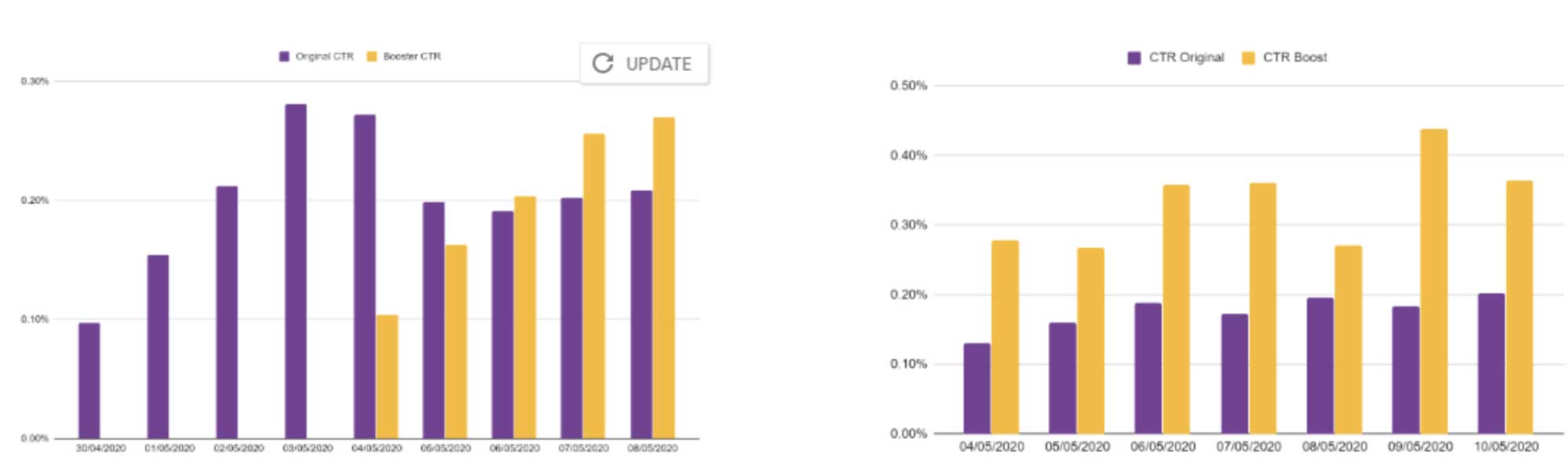
In fact, as there isn’t any free lunch, you will need to notice that there isn’t any single high quality metric throughout campaigns and analysis should be performed on a campaign-per-campaign foundation.
[ad_2]