
{kind=link}
[ad_1]
AWS Glue is a serverless knowledge integration service that makes it straightforward to find, put together, and mix knowledge for analytics, machine studying (ML), and software improvement. In AWS Glue, you need to use Apache Spark, which is an open-source, distributed processing system on your knowledge integration duties and massive knowledge workloads. Apache Spark makes use of in-memory caching and optimized question execution for quick analytic queries towards your datasets, that are break up into a number of partitions so that you could execute totally different transformations in parallel.
Shuffling is a crucial step in a Spark job each time knowledge is rearranged between partitions. The groupByKey(), reduceByKey(), be part of(), and distinct() are some examples of vast transformations that may trigger a shuffle. Throughout a shuffle, knowledge is written to disk and transferred throughout the community. In consequence, the shuffle operation is usually constrained by the obtainable native disk capability, or knowledge skew, which may trigger straggling executors. Spark typically throws a No area left on system or MetadataFetchFailedException error when there may be not sufficient disk area left on the executor and there’s no restoration.
This publish introduces a new Spark shuffle supervisor obtainable in AWS Glue that disaggregates Spark compute and shuffle storage by using Amazon Easy Storage Service (Amazon S3) to retailer Spark shuffle and spill information. Utilizing Amazon S3 for Spark shuffle storage helps you to run data-intensive workloads rather more reliably.
Understanding the shuffle operation in AWS Glue
Spark creates bodily plans for working your workflow, referred to as Directed Acyclic Graphs (DAGs). The DAG represents a collection of transformations in your dataset, every leading to a brand new immutable RDD. The entire transformations in Spark are lazy, in that they aren’t computed till an motion is named to generate outcomes. There are two kinds of transformations:
- Slender transformation – Comparable to
map,filter,union, andmapPartition, the place every enter partition contributes to just one output partition. - Broad transformation – Comparable to
be part of,groupBykey,reduceByKey, andrepartition, the place every enter partition contributes to many output partitions.
In Spark, a shuffle happens each time knowledge is rearranged between partitions. That is required as a result of the vast transformation wants data from different partitions with a view to full its processing. Spark gathers the required knowledge from every partition and combines it into a brand new partition. Throughout a shuffle part, all Spark map duties write shuffle knowledge to a neighborhood disk that’s then transferred throughout the community and fetched by Spark scale back duties. With AWS Glue, employees write shuffle knowledge on native disk volumes connected to the AWS Glue employees.
Along with shuffle writes, Spark makes use of native disk to spill knowledge from reminiscence that exceeds the heap area outlined by the spark.reminiscence.fraction configuration parameter. Shuffle spill (reminiscence) is the scale of the de-serialized type of the info within the reminiscence on the time when the employee spills it. Whereas shuffle spill (disk) is the scale of the serialized type of the info on disk after the employee has spilled.

Challenges
Spark makes use of native disk for storing intermediate shuffle and shuffle spills. This introduces the next key challenges:
- Hitting native storage limits – In case you have a Spark job that computes transformations over a considerable amount of knowledge, and ends in both an excessive amount of spill or shuffle or each, you then may get a failed job with
java.io.IOException: No area left on systemexception if the underlying storage has crammed up. - Co-location of storage with executors – If an executor is misplaced, then shuffle information are misplaced as nicely. This results in a number of activity and stage retries, as Spark tries to recompute phases with a view to get better misplaced shuffle knowledge. Spark natively offers an exterior shuffle service that lets it retailer shuffle knowledge impartial to the lifetime of executors. However the shuffle service itself turns into some extent of failure and should all the time be up with a view to serve shuffle knowledge. Moreover, shuffles are nonetheless saved on native disk, which could run out of area for a big job.
For example one of many previous situations, let’s use the question q80.sql from the usual TPC-DS 3 TB dataset for instance. This question makes an attempt to calculate the whole gross sales, returns, and eventual revenue realized throughout a selected time-frame. It includes a number of vast transformations (shuffles) attributable to left outer be part of, group by, and union all. Let’s run the next question with 10 G1.x AWS Glue DPU (knowledge processing unit). For the G.1X employee kind, every employee maps to 1 DPU and 1 executor. 10 G1.x employees account for a complete of 640GB of disk area. See the next sql question:
The next screenshot exhibits the AWS Glue job run particulars from the Apache Spark internet UI:
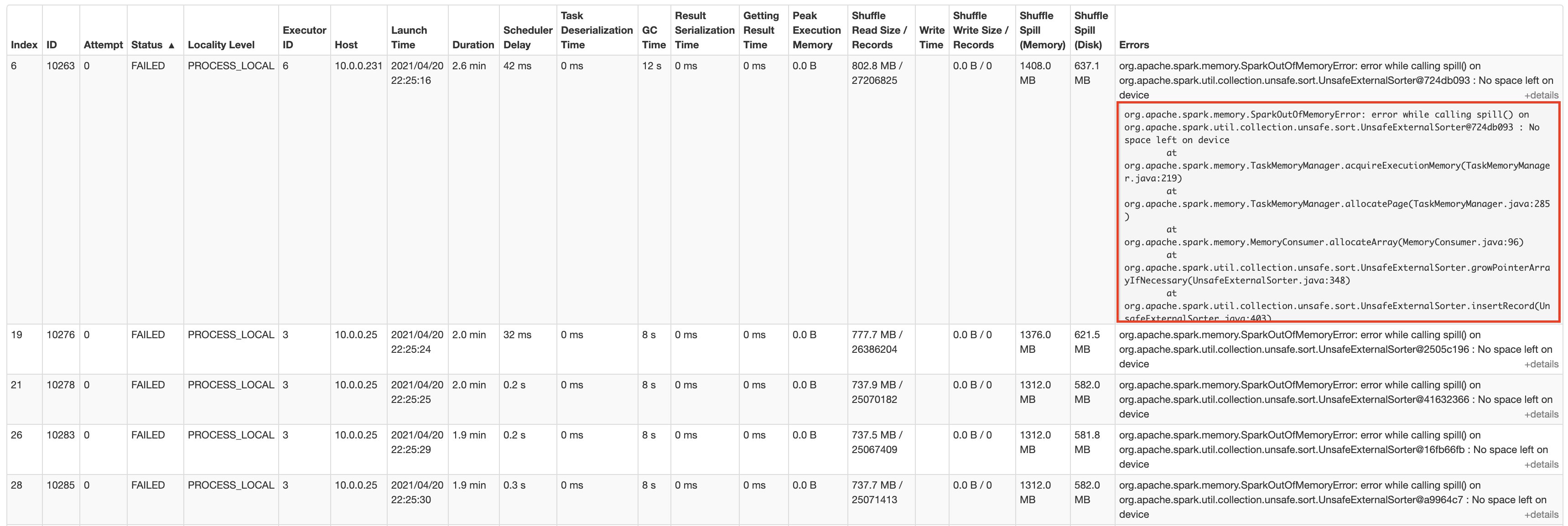
The job runs for about 1 hour and 25 minutes, then we begin observing activity failures. Spark finally ends up stopping the stage and canceling the job when the duty retries additionally fail.
The next screenshots present the aggregated metrics for the failed stage, in addition to how a lot knowledge is spilled to disk by particular person executors:
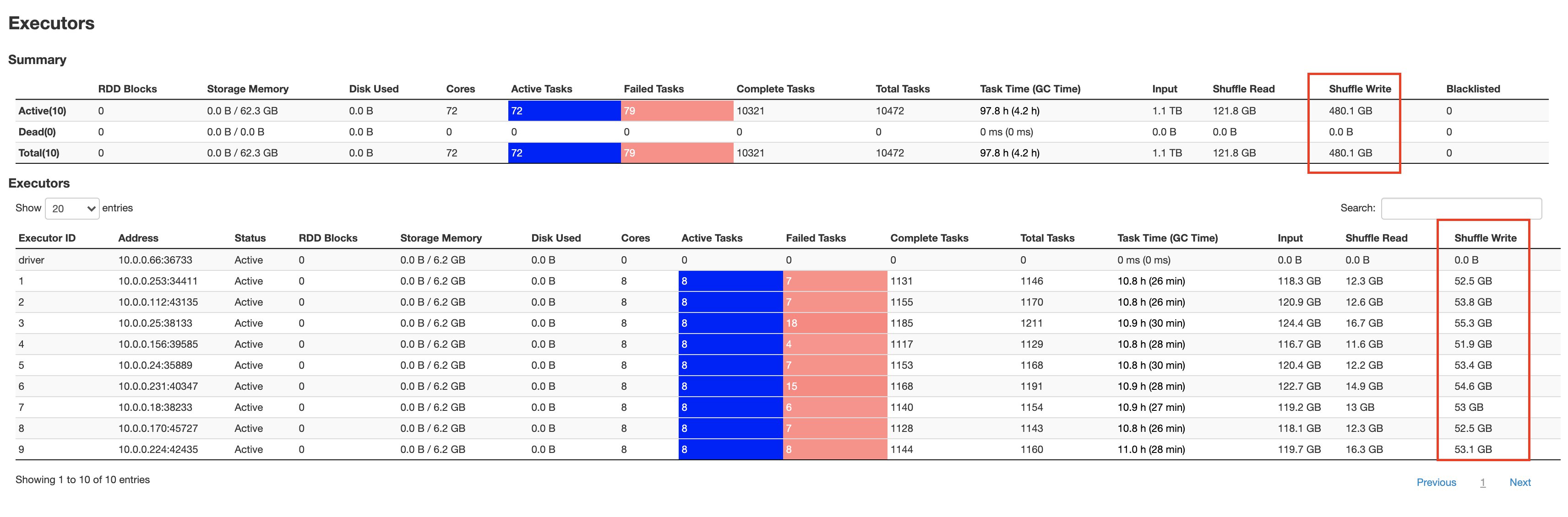
As seen within the Shuffle Write metric from the above Spark UI screenshot, all 10 employees shuffle over 50 GB of knowledge. Additional writes aren’t allowed, and duties begin failing with a “No area left on system” error.

The remaining storage is occupied by knowledge that’s spilled to disk, as seen within the Shuffle Spill (Disk) metric from the above Spark UI screenshot. This failed job is a traditional instance of a data-intensive transformation the place Spark is each shuffling and spilling to disk when executor reminiscence is crammed.
Resolution overview
We’ve got varied strategies for overcoming the disk area error:
- Scale out – Improve the variety of employees. This incurs a rise in value. Nevertheless, scaling out won’t all the time work, particularly in case your knowledge is closely skewed on a number of keys. Fixing skewness would require appreciable modifications to your Spark software logic.
- Improve shuffle partitions – Growing the shuffle partitions can typically assist overcome area errors. Nevertheless, this won’t all the time work, and subsequently is unreliable.
- Disaggregate compute and storage – This strategy presents a number of of the benefits of not solely scaling storage for big shuffles, but in addition including reliability within the occasion of node failures as a result of shuffle knowledge is independently saved. Following are few implementations of this disaggregated strategy:
- Devoted intermediate storage cluster – On this strategy, you utilize an extra fleet of shuffle providers to serve intermediate shuffle. It has a number of benefits, comparable to merging shuffle information and sequential I/O, however it introduces an overhead of fleet upkeep from each operations, in addition to a value standpoint. For examples of this strategy, see Cosco: An Environment friendly Fb-Scale Shuffle Service and Zeus: Uber’s Extremely Scalable and Distributed Shuffle as a Service.
- Serverless storage – AWS Glue implements a unique strategy during which you make the most of Amazon S3, an economical managed and serverless storage, to retailer intermediate shuffle knowledge. This design doesn’t rely upon a devoted daemon, comparable to shuffle service, to protect shuffle information. This allows you to elastically scale your Spark job with out the overhead of working, working, and sustaining extra storage or compute nodes.
With AWS Glue 2.0, now you can use Amazon S3 to retailer Spark shuffle and spill knowledge. Amazon S3 is an object storage service that provides industry-leading scalability, knowledge availability, safety, and efficiency. This offers full elasticity to Spark jobs, thereby permitting you to run your most knowledge intensive workloads reliably.
The next diagram illustrates how Spark map duties write the shuffle and spill information to the given Amazon S3 shuffle bucket. Reducer duties contemplate the shuffle blocks as distant blocks and skim them from the identical shuffle bucket.
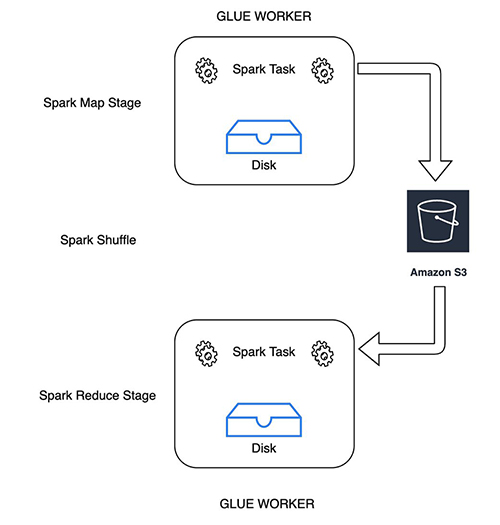
Use Amazon S3 to retailer shuffle and spill knowledge
The next job parameters allow and tune Spark to make use of S3 buckets for storing shuffle and spill knowledge. You too can allow at-rest encryption when writing shuffle knowledge to Amazon S3 by utilizing safety configuration settings.
| Key | Worth | Rationalization |
| –write-shuffle-files-to-s3 | TRUE | That is the principle flag, which tells Spark to make use of S3 buckets for writing and studying shuffle knowledge. |
| –write-shuffle-spills-to-s3 | TRUE | That is an non-compulsory flag that allows you to offload spill information to S3 buckets, which offers extra resiliency to your Spark job. That is solely required for big workloads that spill loads of knowledge to disk. This flag is disabled by default. |
| –conf | spark.shuffle.glue.s3ShuffleBucket=S3://<shuffle-bucket> | That is additionally non-compulsory, and it specifies the S3 bucket the place we write the shuffle information. By default, we use —TempDir/shuffle-data. |
You too can use the AWS Glue Studio console to allow Amazon S3 based mostly shuffle or spill. You possibly can select the previous properties from pre-populated choices within the Job parameters part.

Outcomes
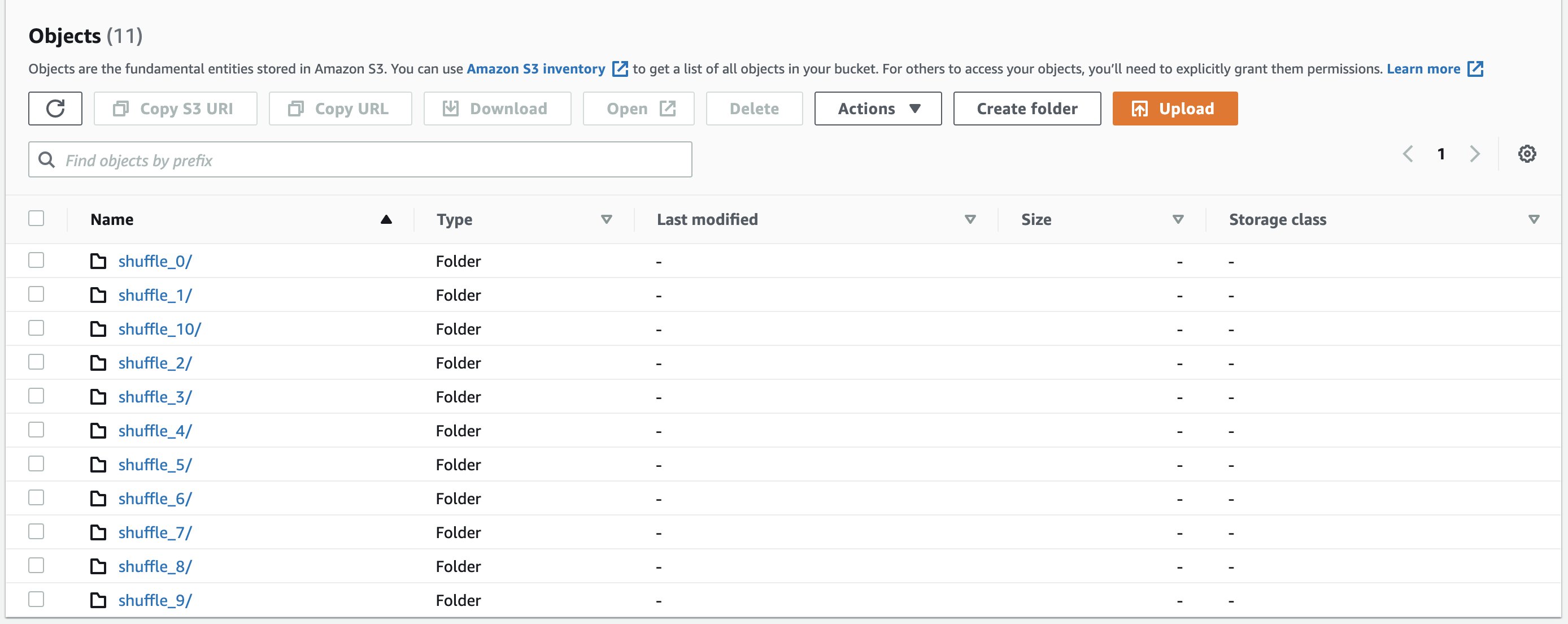
Let’s run the identical q80.sql question with Amazon S3 shuffle enabled. We are able to view the shuffle information saved within the S3 bucket within the following format:
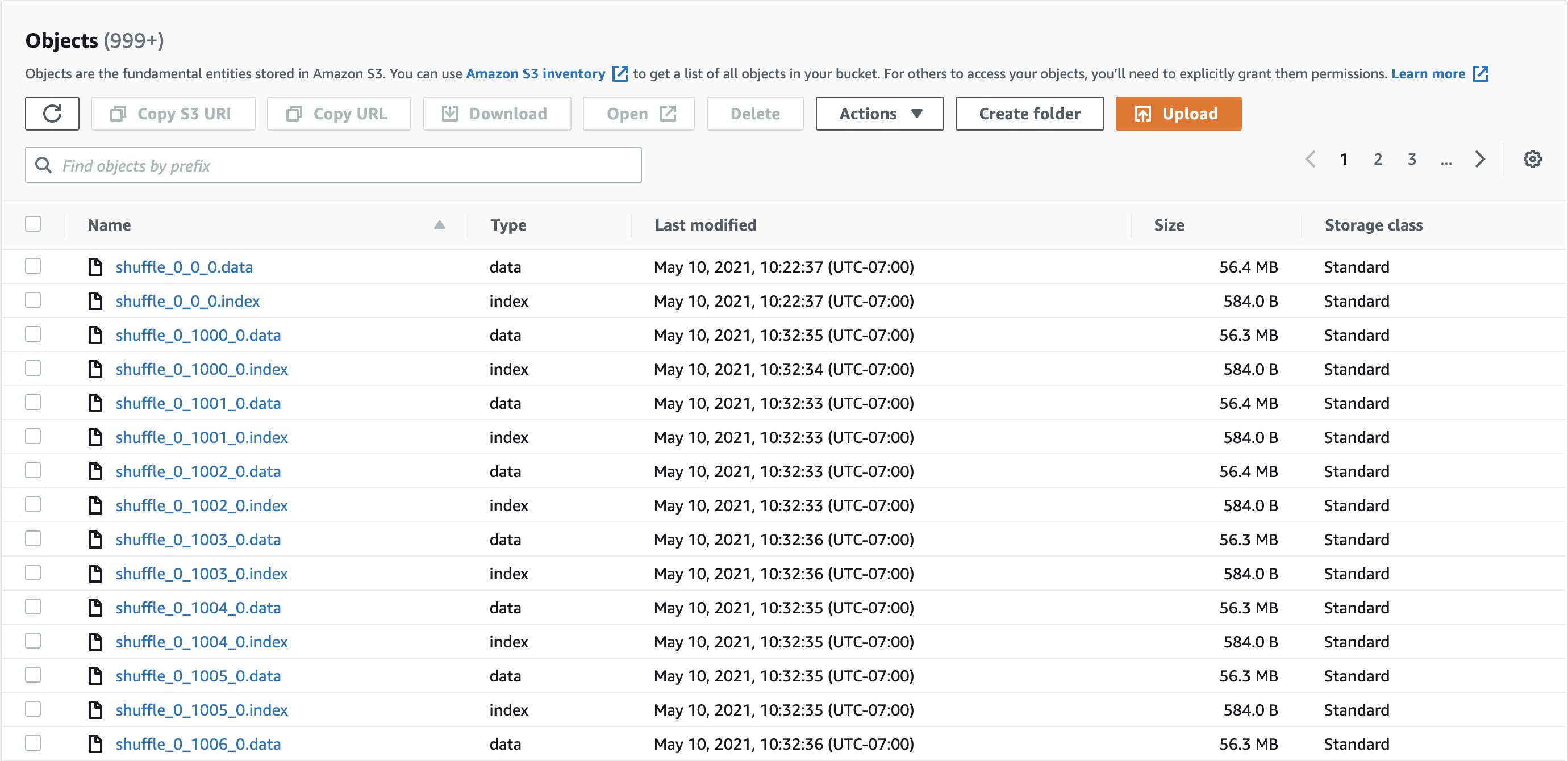
Two sorts of information are created:
- Knowledge – Shops the shuffle output of the present activity
- Index – Shops the classification data of the info within the knowledge file by storing partition offsets
The next screenshots exhibits instance shuffle directories and shuffle information:
The next screenshot exhibits the aggregated metrics from the Spark UI:
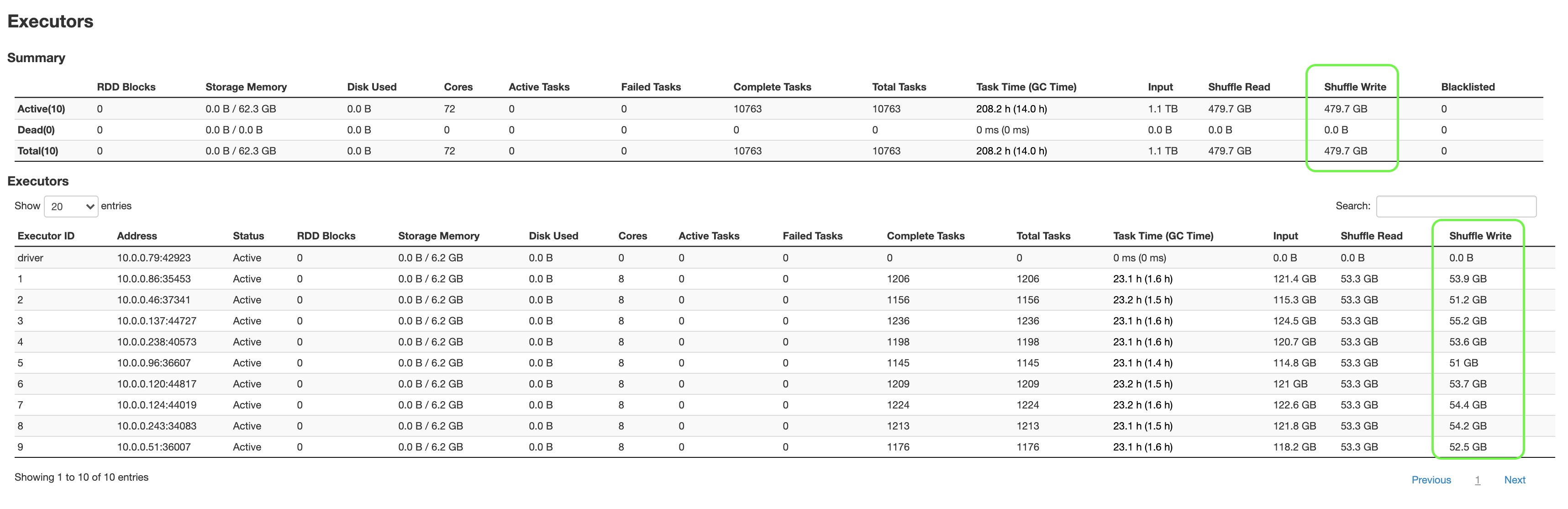
The next are a number of key highlights:
q80.sql, which had failed earlier after 1 hour and 25 minutes, and was in a position to full solely 13 out of 18 phases, completed efficiently in about 2 hours and 53 minutes, finishing all 18 phases.- We had been in a position to shuffle 479.7 GB of knowledge with out worrying about storage limits.
- Extra employees aren’t required to scale storage, which offers substantial value financial savings.
Issues and finest practices
Bear in mind the next finest practices when contemplating this answer:
- This characteristic is really useful whenever you need to make sure the dependable execution of your knowledge intensive workloads that create a considerable amount of shuffle or spill knowledge. Writing and studying shuffle information from Amazon S3 is marginally slower when in comparison with native disk for our experiments with TPC-DS queries. S3 shuffle efficiency could be impacted by the quantity and dimension of shuffle information. For instance, S3 might be slower for reads as in comparison with native storage in case you have a lot of small shuffle information or partitions in your Spark software.
- You should utilize this characteristic in case your job incessantly suffers from
No area left on systempoints. - You should utilize this characteristic in case your job incessantly suffers fetch failure points (
org.apache.spark.shuffle.MetadataFetchFailedException). - You should utilize this characteristic in case your knowledge is skewed.
- We advocate setting the S3 bucket lifecycle insurance policies on the shuffle bucket (spark.shuffle.glue.s3ShuffleBucket) with a view to clear up outdated shuffle knowledge.
- On the time of penning this weblog, this characteristic is at present obtainable on AWS Glue 2.0 and Spark 2.4.3.
Conclusion
This publish mentioned how we will independently scale storage in AWS Glue with out including extra employees. With this characteristic, you possibly can count on jobs which are processing terabytes of knowledge to run rather more reliably. Comfortable shuffling!
Concerning the Authors
 Anubhav Awasthi is a Huge Knowledge Specialist Options Architect at AWS. He works with prospects to supply architectural steering for working analytics options on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Huge Knowledge Specialist Options Architect at AWS. He works with prospects to supply architectural steering for working analytics options on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
 Rajendra Gujja is a Software program Growth Engineer on the AWS Glue workforce. He’s enthusiastic about distributed computing and all the pieces and something to do with the info.
Rajendra Gujja is a Software program Growth Engineer on the AWS Glue workforce. He’s enthusiastic about distributed computing and all the pieces and something to do with the info.
 Mohit Saxena is a Software program Engineering Supervisor on the AWS Glue workforce. His workforce works on distributed methods for effectively managing knowledge lakes on AWS and optimizes Apache Spark for efficiency and reliability.
Mohit Saxena is a Software program Engineering Supervisor on the AWS Glue workforce. His workforce works on distributed methods for effectively managing knowledge lakes on AWS and optimizes Apache Spark for efficiency and reliability.
[ad_2]