

{kind=link}
[ad_1]
Information Mesh
Credit score: Thoughtworks
To centralize or distribute information administration? That query has been on the entrance burner ever since departmental minicomputers invaded the enterprise, adopted much more subversively by PCs and LANs strolling by the again door. And standard knowledge has swung backwards and forwards ever since. Workgroup or departmental techniques to make information accessible, then enterprise database consolidations to eliminate all of the duplication.
Bear in mind when the info lake was presupposed to be the top state? Similar to the enterprise information warehouse earlier than it, the notion that every one information may roll into one place in order that there was solely a single supply of fact that every one walks of life throughout the enterprise may entry proved unrealistic. The connectedness of the Web, the seemingly low-cost storage and infinite scalability of the cloud, the explosion of sensible gadget and IoT information threaten to overwhelm the info warehouses and information lakes so laboriously arrange. Information lakehouses have recently emerged to convey one of the best of each worlds, whereas information materials and clever information hubs optimize the tradeoffs between virtualizing and replicating information.
It might be pointless to state that any of those options provide the definitive silver bullet.
Enter the Information Mesh
Over the previous 12 months, a brand new principle has emerged that acknowledges the futility of top-down or monolithic approaches to information administration: the info mesh. Whereas a lot of the highlight of late has been on AI and machine studying, within the information world, there are fewer subjects which are drawing extra dialogue than information mesh. Simply take a look at Google Tendencies information for the previous 90 days: searches for Information Mesh far outnumber these for Information Lakehouse.
It was originated by Zhamak Dehghani, director of subsequent tech incubation at Thoughtworks North America, by an intensive set of works starting with an introduction again in 2019, a drill-down on ideas, and logical structure in late 2020, that can quickly culminate in a guide (in the event you’re , Starburst Information is providing a sneak peek). Information meshes have typically been in comparison with information materials, however a detailed learn of Dehghani’s work reveals that that is extra about course of than expertise, as James Serra, an structure lead at EY and previously with Microsoft, accurately identified in a weblog publish. Nonetheless, the subject of information meshes (that are distributed views of the info property) vs. information materials (which apply extra centralized approaches) deserves its personal publish, as curiosity in each has been fairly related.
Merely said, if that’s doable, information mesh is not a expertise stack or bodily structure. Information mesh is a course of and architectural strategy that delegates duty for particular information units to domains, or areas of the enterprise which have the requisite subject material experience to know what the info is meant to symbolize and the way it’s for use.
There’s an architectural facet to this: as a substitute of assuming that information will reside in an information lake, every “area” shall be chargeable for selecting find out how to host and serve the datasets that they personal.
Apart from exterior regulation or company governance coverage, the domains are the explanation why particular information units are collected. However the satan is within the particulars, and there are a whole lot of them.
So, the info mesh isn’t outlined by the info warehouse, information lake, or information lakehouse the place the info bodily resides. Neither is it outlined by the info federation, information integration, question engine, or cataloging instruments that populate and annotate these information shops. In fact, that hasn’t stopped expertise distributors from information mesh washing their merchandise. Over the subsequent 12 months, we’re prone to see suppliers of catalogs, question engines, information pipelines, and governance paint their instruments or platforms in an information mesh mild. However as you see the advertising messages, keep in mind that information meshes are about course of and the way you implement expertise. As an illustration, a federated question engine is solely an enabler that may assist a crew with implementation, however by itself doesn’t abruptly flip an information property into an information mesh.
The core pillars
Information Mesh is a posh idea, however the easiest way to start out is by understanding the ideas behind it.
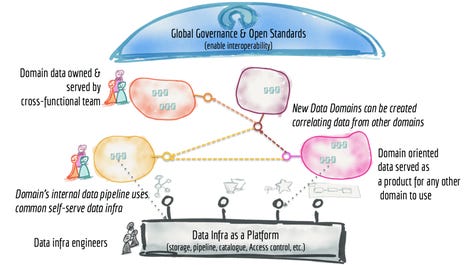
The primary precept is about information possession – it ought to be native, residing with the crew chargeable for gathering and/or consuming the info. If there’s a central precept to information meshes, that is it – it is that the management of information ought to devolve to the area that owns it. Consider a website as an extension of area information – that is the organizational entity or group of people that perceive what the info is and the way it pertains to the enterprise. That is the entity that is aware of why the dataset is being collected; how it’s consumed, and by whom; and, the way it ought to be ruled by its lifecycle.
Issues get a bit extra difficult for information that’s shared throughout domains, or the place information underneath one area relies on information or APIs from different domains. Welcome to the true world, the place information is never an island. This is without doubt one of the locations the place implementing meshes may get sticky.
The second precept is that information ought to be considered a product. That’s, in impact, a extra expansive view of what contains an information entity, in that it’s greater than the piece of information or a selected information set and takes extra of a lifecycle view of how information can and ought to be served and consumed. And a part of the definition of the product is a proper service stage goal, which may pertain to components equivalent to efficiency, trustworthiness and reliability, information high quality, security-related authorization guidelines, and so forth. It is a promise that the area that owns the info makes to the group.
Particularly, an information product goes past the info set or information entity to incorporate the code for the info pipelines essential to generate and/or rework the info; the related metadata (which in fact may embody all the things from schema definition to related enterprise glossary phrases, consumption fashions or varieties equivalent to relational tables, occasions, batch recordsdata, varieties, graphs, and many others.); and infrastructure (how and the place the info is saved and processed). This has vital organizational ramifications, on condition that the constructing of information pipelines is usually a disjoint exercise dealt with independently by specialist practitioners equivalent to information engineers and builders. At the least in a matrix context, they must be a part of, or related to, the area or enterprise crew that owns the info.
On, and by the way in which, that information product must fulfill some key necessities. The info should be readily discoverable; that is presumably what catalogs are for. It also needs to be explorable, enabling customers to drill down. And it ought to be addressable; right here, Dehghani mentions that information ought to have distinctive canonical addresses, which appears like a higher-level abstraction that semantic net remnant, the traditional Uri. Lastly, information ought to be comprehensible (Dehghani suggests “self-describing semantics and syntax”); reliable; and safe. Let’s not overlook that, since that is meant to cross a number of domains, that information harmonization efforts shall be mandatory.
Whereas information mesh isn’t outlined by expertise, in the true world, particular engineering teams will personal the underlying information platform, whether or not or not it’s a database, information lake, and/or streaming engine. That applies no matter whether or not the group is implementing these platforms on-premises or profiting from a managed database service within the cloud, and extra possible, in each locations. Any person must personal the underlying platform, and these platforms shall be thought-about merchandise, too, within the grand scheme of issues.
Self-service information platform
Credit score: Thoughtworks
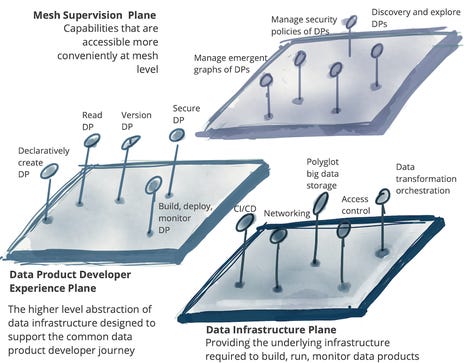
The third precept is the necessity for information to be out there by way of a self-service information platform as proven above. In fact, self-service has change into a watchword for broader information entry as it’s the solely method for information to change into consumable as the info property expands, on condition that IT sources are finite, particularly with information engineers who’re uncommon and valuable. What she is describing right here shouldn’t be confused with self-service platforms for information visualization or information scientists; this one is extra for infrastructure and product builders.
This platform can have, what Dehghani phrases, completely different planes (or skins) that service completely different swaths of practitioners. Examples may embrace an infrastructure provisioning airplane, that offers with all of the ugly bodily mechanics of marshaling information (like provisioning storage; setting entry controls; and the question engine); a product improvement expertise that gives a declarative interface to managing the info lifecycle; and a supervision airplane that manages the info merchandise. Dehghani will get much more exhaustive on what a self-serve information platform ought to help, and right here is the record.
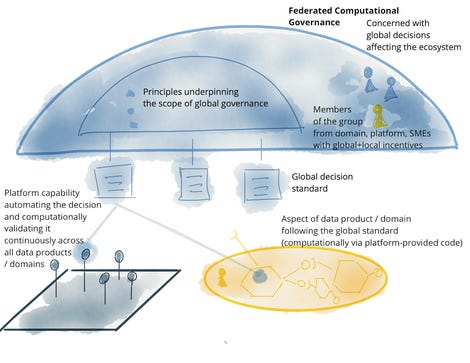
Lastly, no strategy to managing information is full with out governance. That is the fourth precept, and Dehghani phrases it federated computational governance. This acknowledges the fact that in a distributed atmosphere, there shall be a number of, interdependent information merchandise that should interoperate, and in so doing help information sovereignty mandates and the accompanying guidelines for information retention and entry. There shall be a necessity to completely perceive and observe information lineage.
A single publish wouldn’t do that matter justice. On the threat of bastardizing the concept, because of this a federation of information merchandise and information platform product homeowners create and implement a worldwide algorithm making use of to all information merchandise and interfaces. What’s lacking right here is that there must be provision for prime administration in the case of enterprisewide insurance policies and mandates; Dehghani infers it (hopefully her guide will get extra particular). In essence, Dehghani is stating what’s prone to be casual observe as we speak, the place a whole lot of advert hoc decision-making on governance is already being made at a neighborhood stage.
Federated Computational Governance
Credit score: Thoughtworks
So must you do this at dwelling?
Few subjects have drawn as a lot consideration within the information world over the previous 12 months as the info mesh. One of many triggers is that, in an more and more cloud-native world the place purposes and enterprise logic are being decomposed into microservices, why not deal with information the identical method?
The reply is less complicated mentioned than completed. As an illustration, whereas monolithic techniques will be inflexible and unwieldy, distributed techniques introduce their very own complexities, welcome or not. There’s the chance of making new silos, to not point out chaos, when native empowerment isn’t adequately thought out.
As an illustration, creating information pipelines is meant to be a part of the definition of an information product, however when these pipelines will be reused elsewhere, provision should be made for information product groups to share their IP. In any other case, there’s a lot of duplicated effort. Dehghani requires groups to function in a federated atmosphere, however right here the chance is treading on any person else’s turf.
Distributing the lifecycle administration of information could also be empowering, however in most organizations, there are prone to be loads of situations the place possession of information isn’t clear-cut for situations the place a number of stakeholder teams both share use or the place information is derived from any person else’s information. Dehghani acknowledges this, noting that domains usually get information from a number of sources, and in flip, completely different domains could duplicate information (and rework them in numerous methods) for their very own consumption.
Information meshes as ideas are works in progress. In her introductory publish, Dehghani refers to a key strategy for making information discoverable: by what she phrases “self-describing semantics.” However her description is temporary, indicating that utilizing “well-described syntax” accompanied by pattern datasets, and specs for schema are good beginning factors — for the info engineer, not the enterprise analyst. It is a level we would wish to see her flesh out in her forthcoming guide.
One other key requirement, for federated “computational” governance, generally is a mouthful to pronounce, however will probably be much more of that to implement, as a take a look at the diagram above illustrates. Localizing choices as near the supply whereas globalizing choices relating to interoperability goes to require appreciable trial and error.
All that mentioned, there are good the reason why we’re having this dialogue. There are disconnects with information, and most of the points are hardly new. Centralized structure, equivalent to an enterprise information warehouse, information lake, or information lakehouse, cannot do justice in a polyglot world. Alternatively, arguments will be made for the info material strategy that maintains {that a} extra centralized strategy to metadata administration and information discovery shall be extra environment friendly. There’s additionally a case to be made {that a} hybrid strategy that harnesses the ability of unified metadata administration of the info material might be used as a logical backplane for domains to construct and personal their information merchandise.
One other ache level is that the processes for dealing with information at every stage of its lifecycle are sometimes disjoint, the place information engineers or app builders constructing pipelines could also be divorced from the road organizations that the info serves. Self-service has change into standard with enterprise analysts for visualization, and for information scientists in creating ML fashions and shifting them into manufacturing. There’s a good case to be made to broaden this to managing the info lifecycle to groups that, by all logic ought to personal the info.
However let’s not get forward of ourselves. That is very formidable stuff. In the case of distributing the administration and possession of information belongings, as talked about earlier, the satan is within the particulars. And there are many particulars that also must be ironed out. We’re not but bought that such bottom-up approaches to proudly owning information will scale throughout the whole enterprise information property, and that perhaps we must always intention our sights extra modestly: restrict the mesh to components of the group with associated or interdependent domains.
We’re seeing a number of posts the place clients are prematurely declaring victory. However as this publish states, simply because your group has carried out a federated question layer or section its information lakes doesn’t render its deployment an information mesh. At this level, implementing an information mesh with all of its distributed governance ought to be handled as proof of idea.
[ad_2]