
[ad_1]
GIGO (rubbish in, rubbish out) is an idea widespread to laptop science and arithmetic: the standard of the output is set by the standard of the enter. In trendy knowledge structure, you deliver knowledge from totally different knowledge sources, which creates challenges round quantity, velocity, and veracity. You may write unit exams for purposes, nevertheless it’s equally vital to make sure the info veracity of those purposes, as a result of incoming knowledge high quality could make or break your utility. Incorrect, lacking, or malformed knowledge can have a big impression on manufacturing methods. Examples of information high quality points embrace however are usually not restricted to the next:
- Lacking or incorrect values can result in failures within the manufacturing system that require non-null values
- Adjustments within the distribution of information can result in sudden outputs of machine studying (ML) fashions
- Aggregations of incorrect knowledge can result in incorrect enterprise selections
- Incorrect knowledge sorts have a big effect on monetary or scientific institutes
On this put up, we introduce knowledge high quality guidelines in AWS Glue DataBrew. DataBrew is a visible knowledge preparation software that makes it simple to profile and put together knowledge for analytics and ML. We exhibit find out how to use DataBrew to outline a listing of guidelines in a brand new entity referred to as a ruleset. A ruleset is a algorithm that evaluate totally different knowledge metrics in opposition to anticipated values.
The put up describes the implementation course of and supplies a step-by-step information to construct knowledge high quality checks in DataBrew.
Resolution overview
As an example our knowledge high quality use case, we use a human sources dataset. This dataset incorporates the next attributes:
For this put up, we downloaded knowledge with 5 million data, however be at liberty to make use of a smaller dataset to observe together with this put up.
The next diagram illustrates the structure for our resolution.
The steps on this resolution are as follows:
- Create a pattern dataset.
- Create a ruleset.
- Create knowledge high quality guidelines.
- Create a profile job.
- Examine the info high quality guidelines validation outcomes.
- Clear the dataset.
- Create a DataBrew job.
- Validate the info high quality verify with the up to date dataset.
Conditions
Earlier than you get began, full the next stipulations:
- Have an AWS account.
- Obtain the pattern dataset.
- Extract the CSV file.
- Create an Amazon Easy Storage Service (Amazon S3) bucket with three folders:
enter,output, andprofile. - Add the pattern knowledge in enter folder to your S3 bucket (for instance, s3://<s3 bucket title>/enter/).
Create a pattern dataset
To create your dataset, full the next steps:
- On the DataBrew console, within the navigation pane, select Datasets.
- Select Join new dataset.
- For Dataset title, enter a reputation (for instance,
human-resource-dataset). - Beneath Information lake/knowledge retailer, select Amazon S3 as your supply.
- For Enter your supply from Amazon S3, enter the S3 bucket location the place you uploaded your pattern recordsdata (for instance, s3://<s3 bucket title>/enter/).

- Beneath Further configurations, preserve the chosen file kind CSV and CSV delimiter comma (,).
- Scroll to the underside of the web page and select Create dataset.
The dataset is now out there on the Datasets web page.

Create a ruleset
We now outline knowledge high quality rulesets in opposition to the dataset created within the earlier step.
- On the DataBrew console, within the navigation pane, select DQ Guidelines.
- Select Create knowledge high quality ruleset.
- For Ruleset title, enter a reputation (for instance,
human-resource-dataquality-ruleset). - Beneath Related dataset, select the dataset you created earlier.

Create knowledge high quality guidelines
So as to add knowledge high quality guidelines, you need to use guidelines and add a number of guidelines, and inside every rule, you’ll be able to outline a number of checks.
For this put up, we create the next knowledge high quality guidelines and knowledge high quality checks throughout the guidelines:
- Row rely is appropriate
- No duplicate rows
- Worker ID, electronic mail tackle, and SSN are distinctive
- Worker ID and cellphone quantity are usually not be null
- Worker ID and worker age in years has no detrimental values
- SSN knowledge format is appropriate (123-45-6789)
- Cellphone quantity for string size is appropriate
Areacolumn solely has the required area- Worker ID is an integer
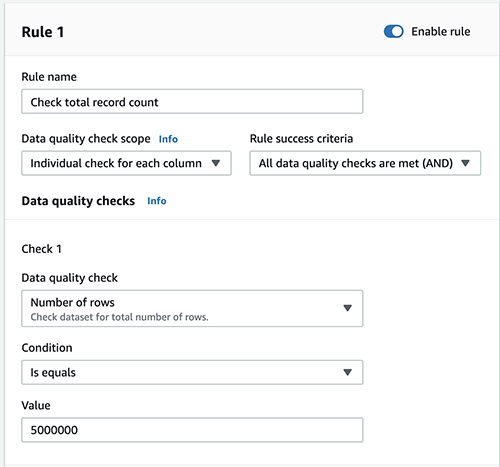
Row rely is appropriate
To verify the entire row rely, full the next steps:
- Add a brand new rule.
- For Rule title, enter a reputation (for instance,
Test complete file rely). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- For Information high quality checks¸ select Variety of rows.
- For Situation, select Is equals.
- For Worth, enter
5000000.
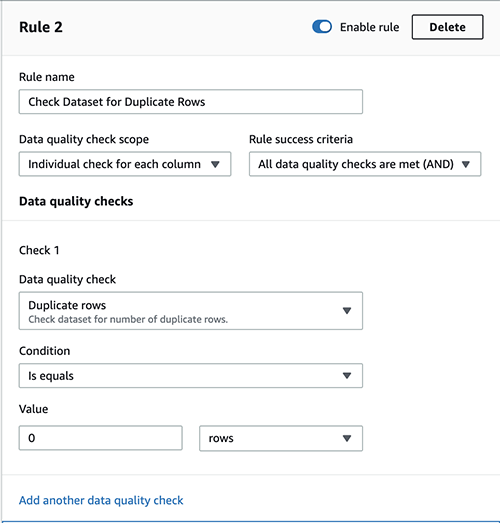
No duplicate rows
To verify the dataset for duplicate rows, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance,
Test dataset for duplicate rows). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- Beneath Test 1, for Information high quality verify¸ select Duplicate rows.
- For Situation, select Is equals.
- For Worth, enter
0and select rows on the drop-down menu.
Worker ID, electronic mail tackle, and SSN are distinctive
To verify that the worker ID, electronic mail, and SSN are distinctive, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance,
Test dataset for Distinctive Values). - For Information high quality verify scope, select Widespread checks for chosen columns.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- For Chosen columns, choose Chosen columns.
- Select the columns
Emp ID,e mail, andSSN. - Beneath Test 1, for Information high quality verify, select Distinctive values.
- For Situation, select Is equals.
- For Worth, enter
100and select %(%) rows on the drop-down menu.

Worker ID and cellphone quantity are usually not be null
To verify that worker IDs and cellphone numbers aren’t null, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance,
Test Dataset for NOT NULL). - For Information high quality verify scope, select Widespread checks for chosen columns.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- For Chosen columns, choose Chosen columns.
- Select the columns
Emp IDandCellphone No. - Beneath Test 1, for Information high quality verify, select Worth is just not lacking.
- For Situation, select Larger than equals.
- For Threshold, enter
100and select %(%) rows on the drop-down menu.

Worker ID and age in years has no detrimental values
To verify the worker ID and age for constructive values, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance,
Test emp ID and age for constructive values). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- Beneath Test 1, for Information high quality verify, select Numeric values.
- Select Emp ID on the drop-down menu.
- For Situation, select Larger than equals.
- For Worth, choose Customized worth and enter
0.
- Select Add one other high quality verify and repeat the identical steps for age in years.
SSN knowledge format is appropriate
To verify the SSN knowledge format, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance,
Test dataset format). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- Beneath Test 1, for Information high quality verify, select String values.
- Select SSN on the drop-down menu.
- For Situation, select Matches (RegEx sample).
- For RegEx worth, enter
^[0-9]{3}-[0-9]{2}-[0-9]{4}$.

Cellphone quantity string size is appropriate
To verify the size of the cellphone quantity, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance, Test
Dataset Cellphone no. for string size). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- Beneath Test 1, for Information high quality verify, select Worth string size.
- Select Cellphone No on the drop-down menu.
- For Situation, select Larger than equals.
- For Worth, choose Customized worth and enter
9. - Beneath Test 2, for Information high quality verify, select Worth string size.
- Select Cellphone No on the drop-down menu.
- For Situation, select Lower than equals.
- For Worth¸ choose Customized worth and enter
12.

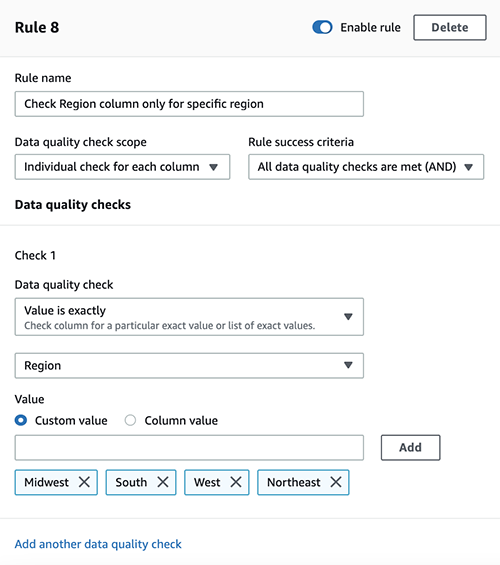
Area column solely has the required area
To verify the Area column, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance, Test
Area column just for particular area). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- Beneath Test 1, for Information high quality verify, select Worth is strictly.
- Select Area on the drop-down menu.
- For Worth, choose Customized worth.
- Select the values
Midwest,South,West, andNortheast.
Worker ID is an integer
To verify that the worker ID is an integer, full the next steps:
- Select Add one other rule.
- For Rule title, enter a reputation (for instance,
Validate Emp ID is an Integer). - For Information high quality verify scope, select Particular person verify for every column.
- For Rule success standards, select All knowledge high quality checks are met (AND).
- Beneath Test 1, for Information high quality verify, select String values.
- Select Emp ID on the drop-down menu.
- For Situation, select Matches (RegEx sample).
- For RegEx worth, enter
^[0-9]+$.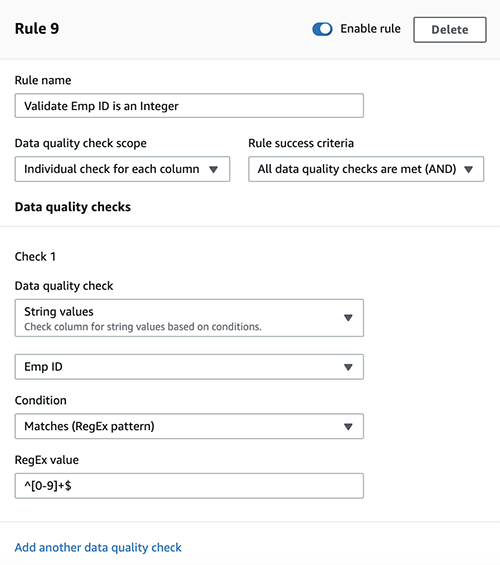
- After you create all the foundations, select Create ruleset.

Your ruleset is now listed on the Information high quality rulesets web page.

Create a profile job
To create a profile job together with your new ruleset, full the next steps:
- On the Information high quality rulesets web page, choose the ruleset you simply created.
- Select Create profile job with ruleset.

- For Job title, preserve the prepopulated title or enter a brand new one.
- For Information pattern, choose Full dataset.
The default pattern measurement is vital for knowledge high quality guidelines validation, as a result of it issues when you validate all of the roles or a restricted pattern.
- Beneath Job output settings, for S3 location, enter the trail to the
profilebucket.
For those who enter a brand new bucket title, the folder is created robotically.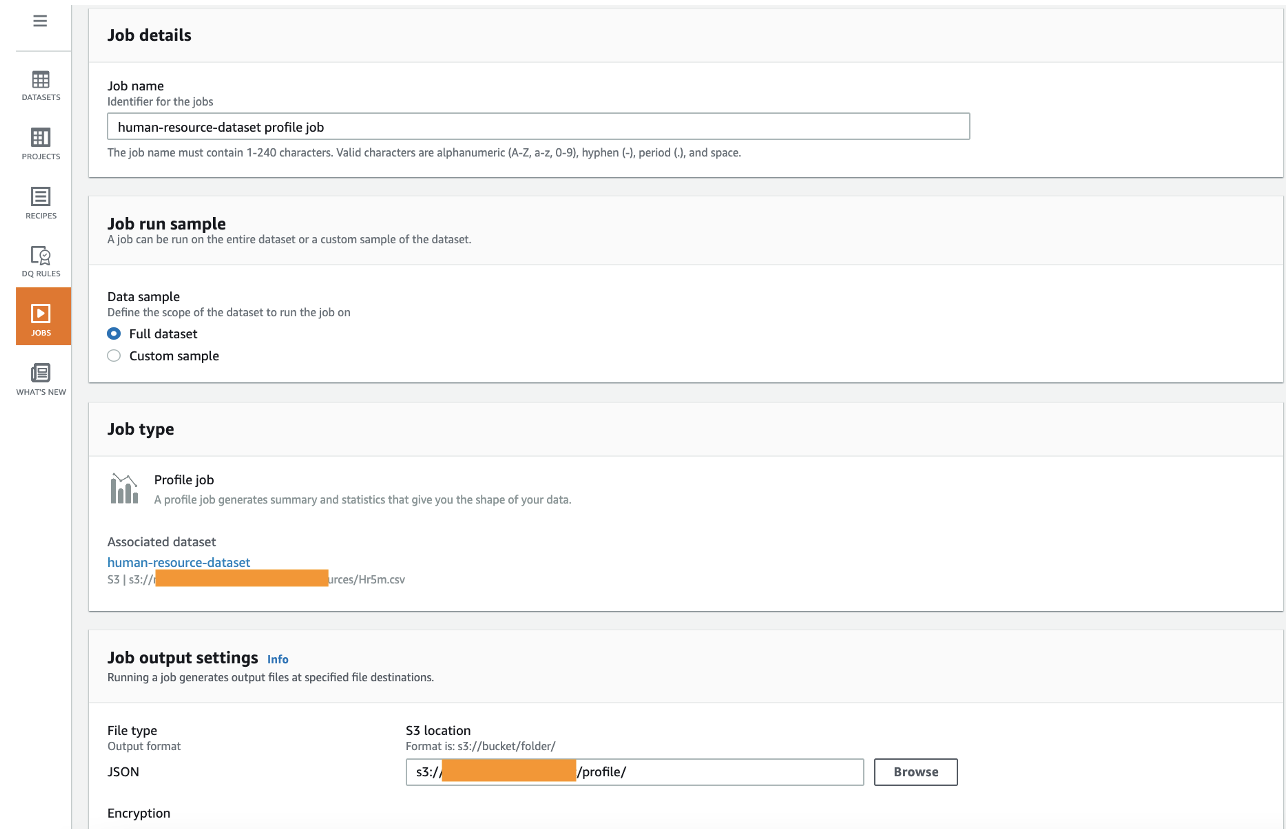
- Maintain the default settings for the remaining optionally available sections: Information profile configurations, Information high quality guidelines, Superior job settings, Related schedules, and Tags.

The following step is to decide on or create the AWS Id and Entry Administration (IAM) function that grants DataBrew entry to learn from the enter S3 bucket and write to the job output bucket.
- For Position title, select an present function or select Create a brand new IAM function and enter an IAM function suffix.
- Select Create and run job.

For extra details about configuring and operating DataBrew jobs, see Creating, operating, and scheduling AWS Glue DataBrew jobs.
Examine knowledge high quality guidelines validation outcomes
To examine the info high quality guidelines, we have to let the profile job full.
- On the Jobs web page of the DataBrew console, select the Profile jobs tab.
- Wait till the profile job standing modifications to
Succeeded. - When the job is full, select View knowledge profile.
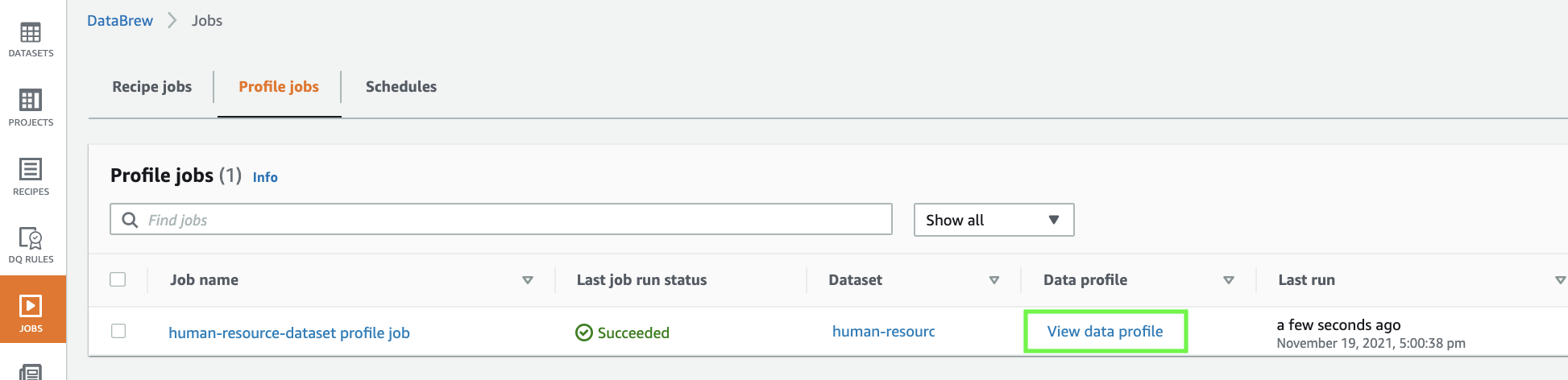
You’re redirected to the Information profile overview tab on the Datasets web page.
- Select the Information high quality guidelines tab.
Right here you’ll be able to evaluate the standing to your knowledge high quality guidelines. As proven within the following screenshot, eight of the 9 knowledge high quality guidelines outlined have been profitable, and one rule failed.
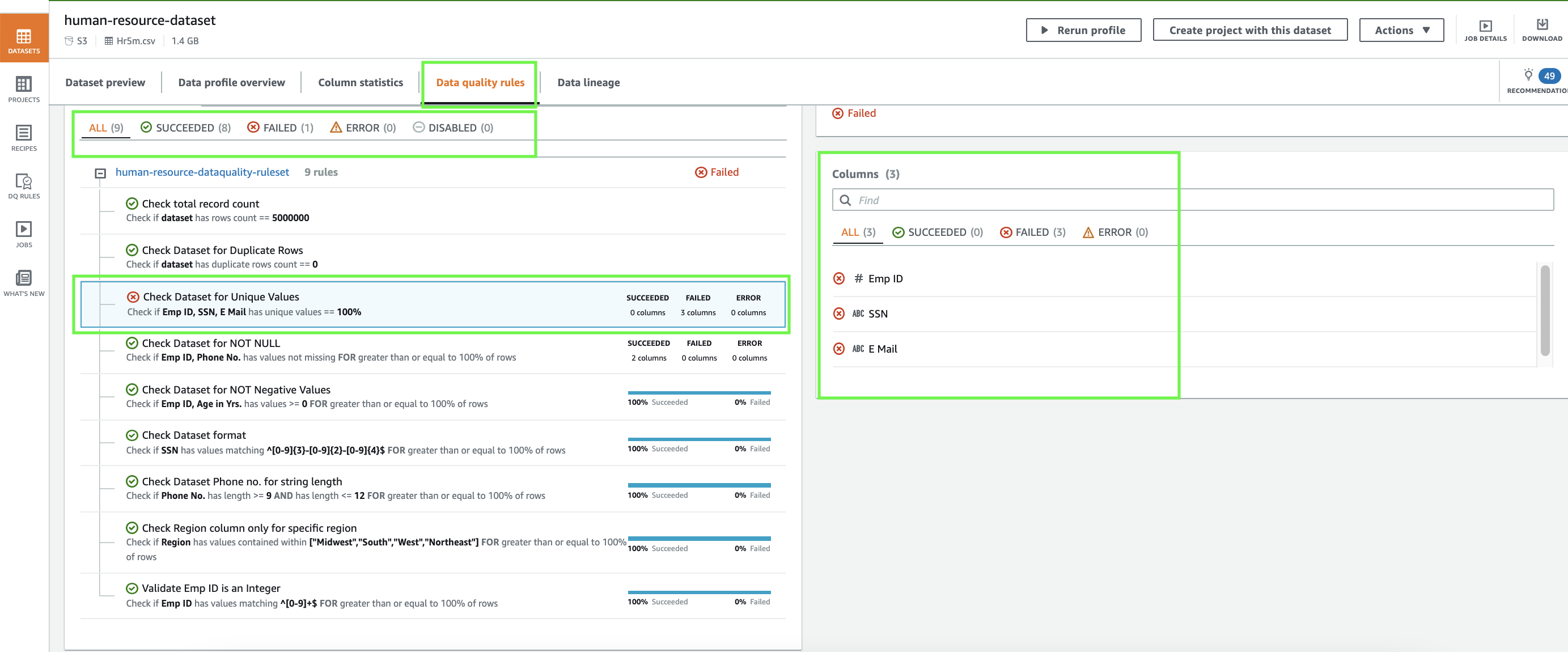
Our failed knowledge high quality rule signifies that we discovered duplicate values for worker ID, SSN, and electronic mail.
- To verify that the info has duplicate values, on the Column statistics tab, select the
Emp IDcolumn.
- Scroll right down to the part Prime distinct values.


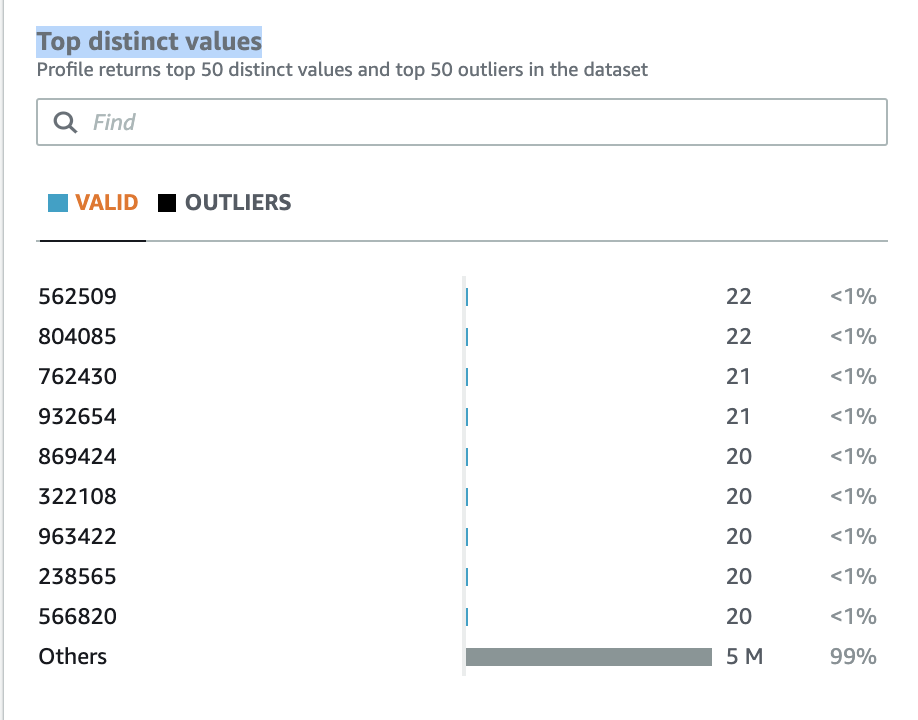
{kind=link}
Equally, you’ll be able to verify the E Mail and SSN columns to seek out that these columns even have duplicate values.
Now we have now confirmed that our knowledge has duplicate values. The following step is to wash up the dataset and rerun the standard guidelines validation.
Clear the dataset
To scrub the dataset, we first must create a venture.
- On the DataBrew console, select Tasks.
- Select Create venture.
- For Mission title, enter a reputation (for this put up,
human-resource-project-demo). - For Choose a dataset, choose My datasets.
- Choose the
human-resource-dataset dataset. - Maintain the sampling measurement at its default.
- Beneath Permissions, for Position title, select the IAM function that we created beforehand for our DataBrew profile job.
- Select Create venture.

The venture takes a couple of minutes to open. When it’s full, you’ll be able to see your knowledge.
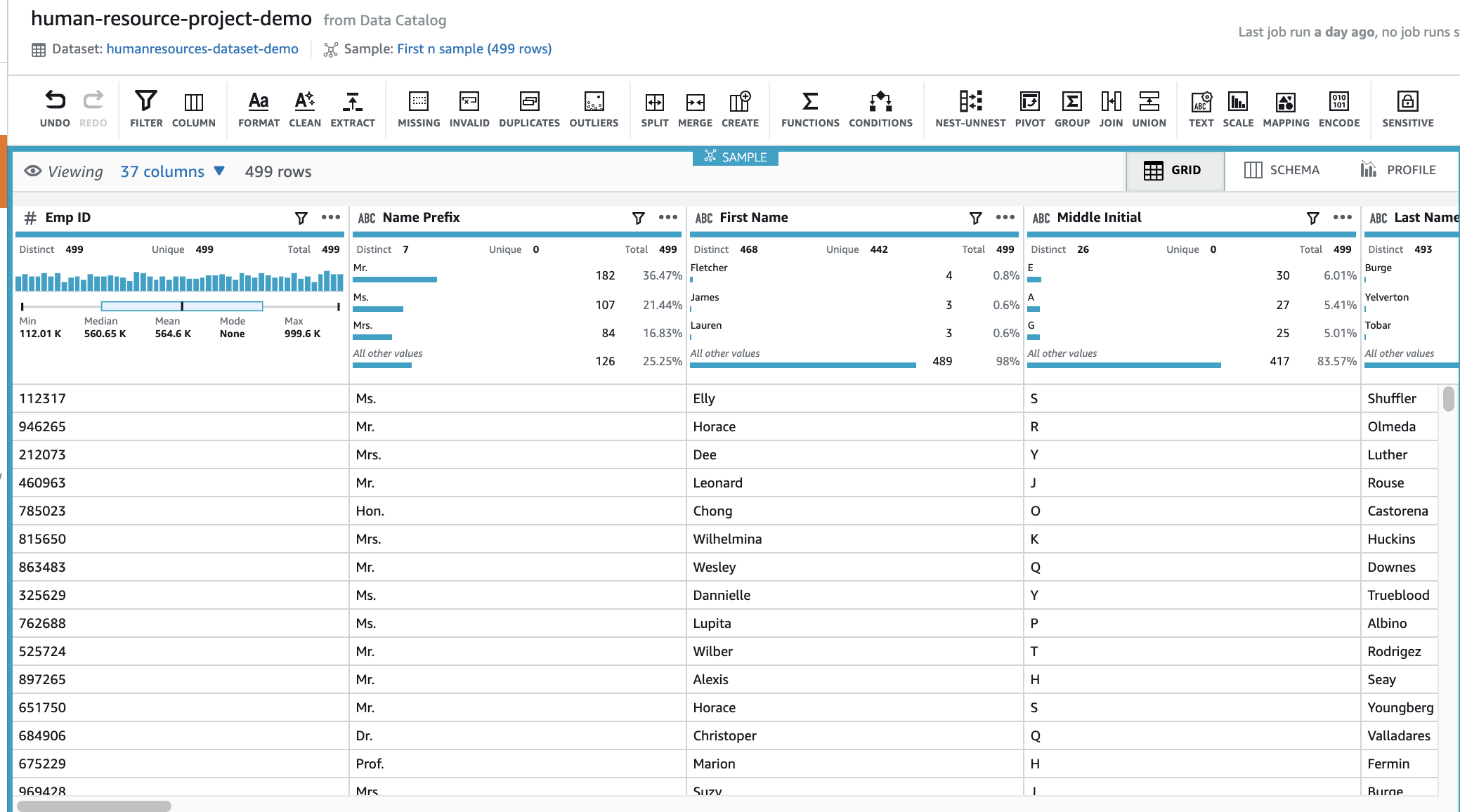
Subsequent, we delete the duplicate worth from the Emp ID column.
- Select the
Emp IDcolumn. - Select the extra choices icon (three dots) to view all of the transforms out there for this column.
- Select Take away duplicate values.

- Repeat these steps for the
SSNandE Mailcolumns.
Now you can see the three utilized steps within the Recipe pane.

Create a DataBrew job
The following step is to create a DataBrew job to run these transforms in opposition to the complete dataset.
- On the venture particulars web page, select Create job.

- For Job title, enter a reputation (for instance,
human-resource-after-dq-check). - Beneath Job output settings¸ for File kind, select your closing storage format to be CSV.
- For S3 location, enter your output S3 bucket location (for instance,
s3://<s3 bucket title>/output/). - For Compression, select None.

- Beneath Permissions, for Position title¸ select the identical IAM function we used beforehand.
- Select Create and run job.

- Look ahead to job to finish; you’ll be able to monitor the job on the Jobs web page.

Validate the info high quality verify with the corrected dataset
To carry out the info high quality checks with the corrected dataset, full the next steps:
- Observe the steps outlined earlier to create a brand new dataset, utilizing the corrected knowledge from the earlier part.
- Select the Amazon S3 location of the job output.

- Select Create dataset.

- Select DQ Guidelines and choose the ruleset you created earlier.
- On the Actions menu, select Duplicate.
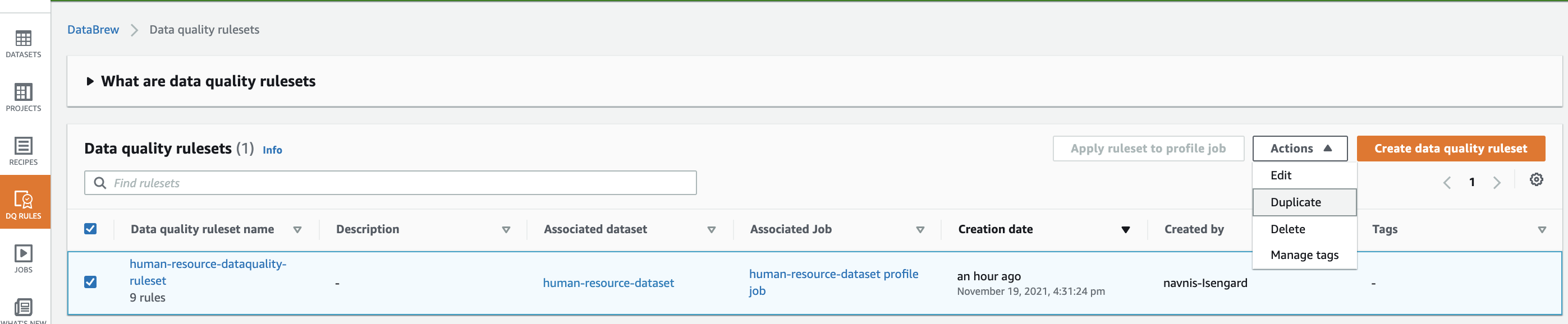
- For Ruleset title, enter a reputation (for instance,
human-resource-dataquality-ruleset-on-corrected-dataset). - Choose the newly created dataset.

- Select Create knowledge high quality ruleset.

- After the ruleset is created, choose it and select Create profile job with ruleset.
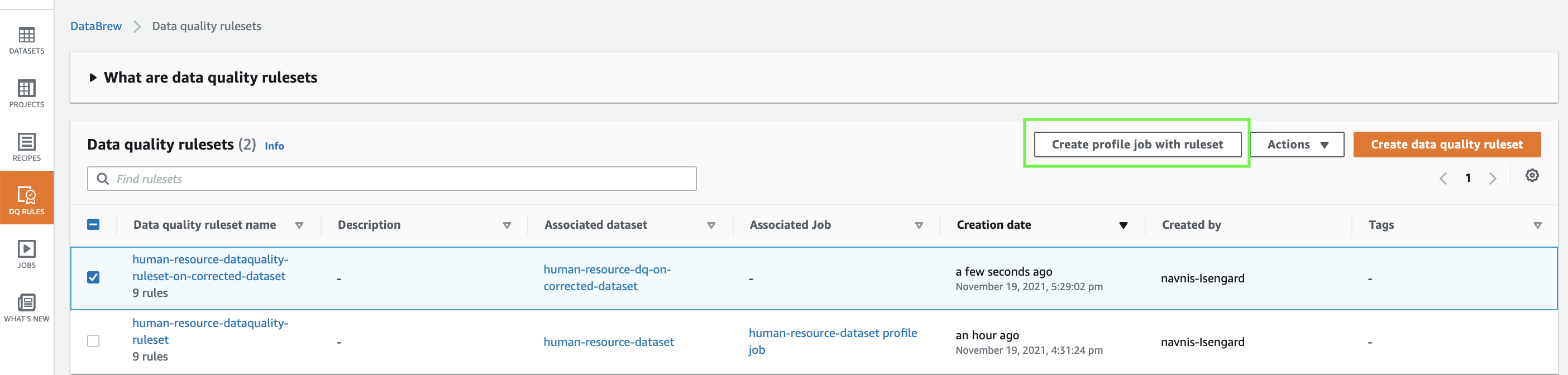
- Create a brand new profile job.

- Select Create and run job.

- When the job is full, repeat the steps from earlier to examine the info high quality guidelines validation outcomes.
This time, beneath Information high quality guidelines, all the foundations are handed besides Test complete file rely since you eliminated duplicate values.

On the Column statistics web page, beneath Prime distinct values for the Emp ID column, you’ll be able to see the distinct values.

You could find related outcomes for the SSN and E Mail columns.
Clear up
To keep away from incurring future prices, we advocate you delete the sources you created throughout this walkthrough.
Conclusion
As demonstrated on this put up, you need to use DataBrew to assist create knowledge high quality guidelines, which will help you determine any discrepancies in your knowledge. You may as well use DataBrew to wash the info and validate it going forwards. You possibly can be taught extra about AWS Glue DataBrew from right here and be taught round AWS Glue DataBrew pricing right here.
In regards to the Authors
 Navnit Shukla is an AWS Specialist Resolution Architect, Analytics, and is keen about serving to prospects uncover insights from their knowledge. He has been constructing options to assist organizations make data-driven selections.
Navnit Shukla is an AWS Specialist Resolution Architect, Analytics, and is keen about serving to prospects uncover insights from their knowledge. He has been constructing options to assist organizations make data-driven selections.
 Harsh Vardhan Singh Gaur is an AWS Options Architect, specializing in Analytics. He has over 5 years of expertise working within the area of massive knowledge and knowledge science. He’s keen about serving to prospects undertake greatest practices and uncover insights from their knowledge.
Harsh Vardhan Singh Gaur is an AWS Options Architect, specializing in Analytics. He has over 5 years of expertise working within the area of massive knowledge and knowledge science. He’s keen about serving to prospects undertake greatest practices and uncover insights from their knowledge.
[ad_2]