

{kind=link}
[ad_1]
Cross-posted from Bounded Remorse.
To know neural networks, researchers usually use similarity metrics to measure how related or completely different two neural networks are to one another. As an illustration, they’re used to check imaginative and prescient transformers to convnets [1], to grasp switch studying [2], and to clarify the success of ordinary coaching practices for deep fashions [3]. Beneath is an instance visualization utilizing similarity metrics; particularly we use the favored CKA similarity metric (launched in [4]) to check two transformer fashions throughout completely different layers:
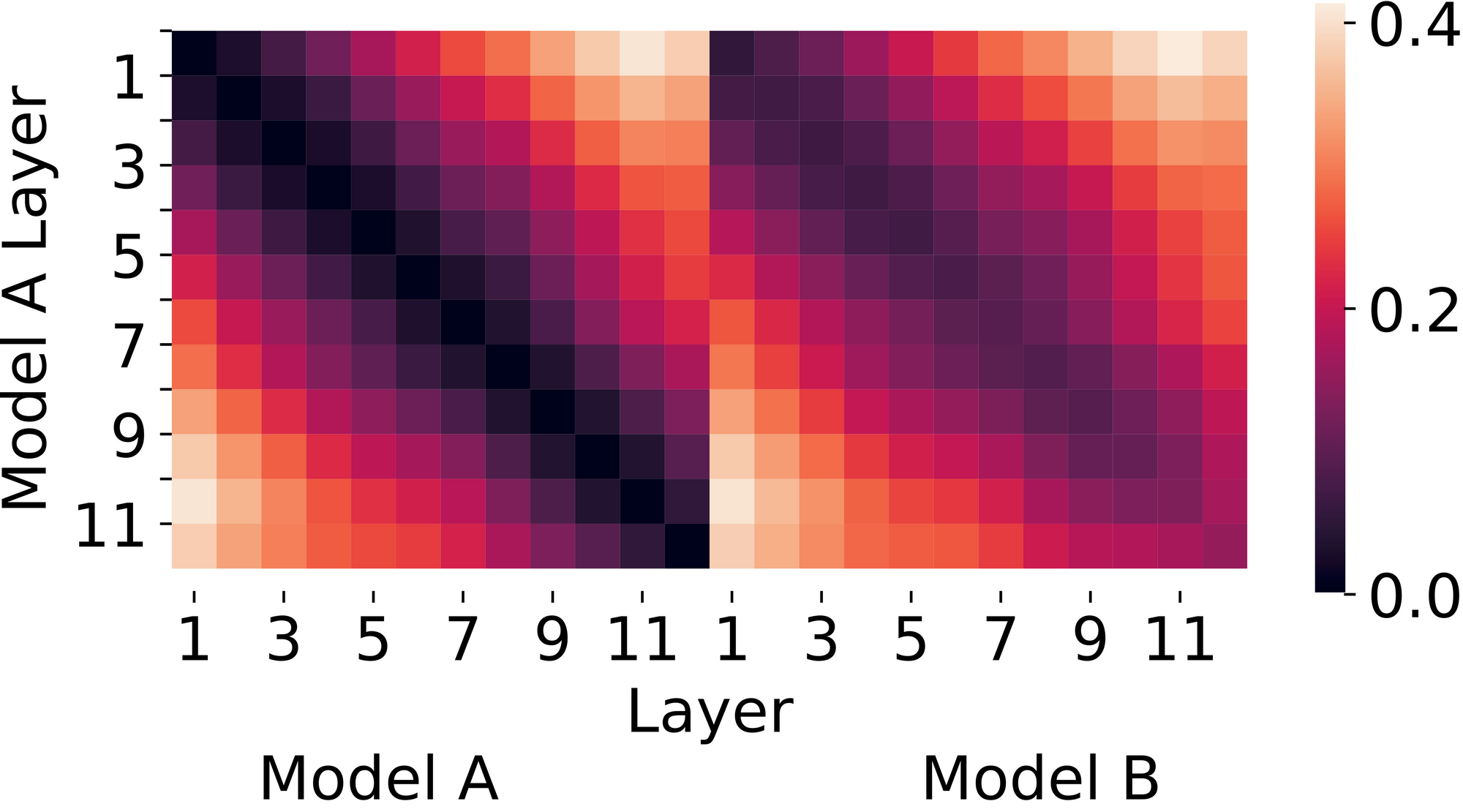
Determine 1. CKA (Centered Kernel Alignment) similarity between two networks skilled identically aside from random initialization. Decrease values (darker colours) are extra related. CKA means that the 2 networks have related representations.
Sadly, there isn’t a lot settlement on which specific similarity metric to make use of. Right here’s the very same determine, however produced utilizing the Canonical Correlation Evaluation (CCA) metric as an alternative of CKA:
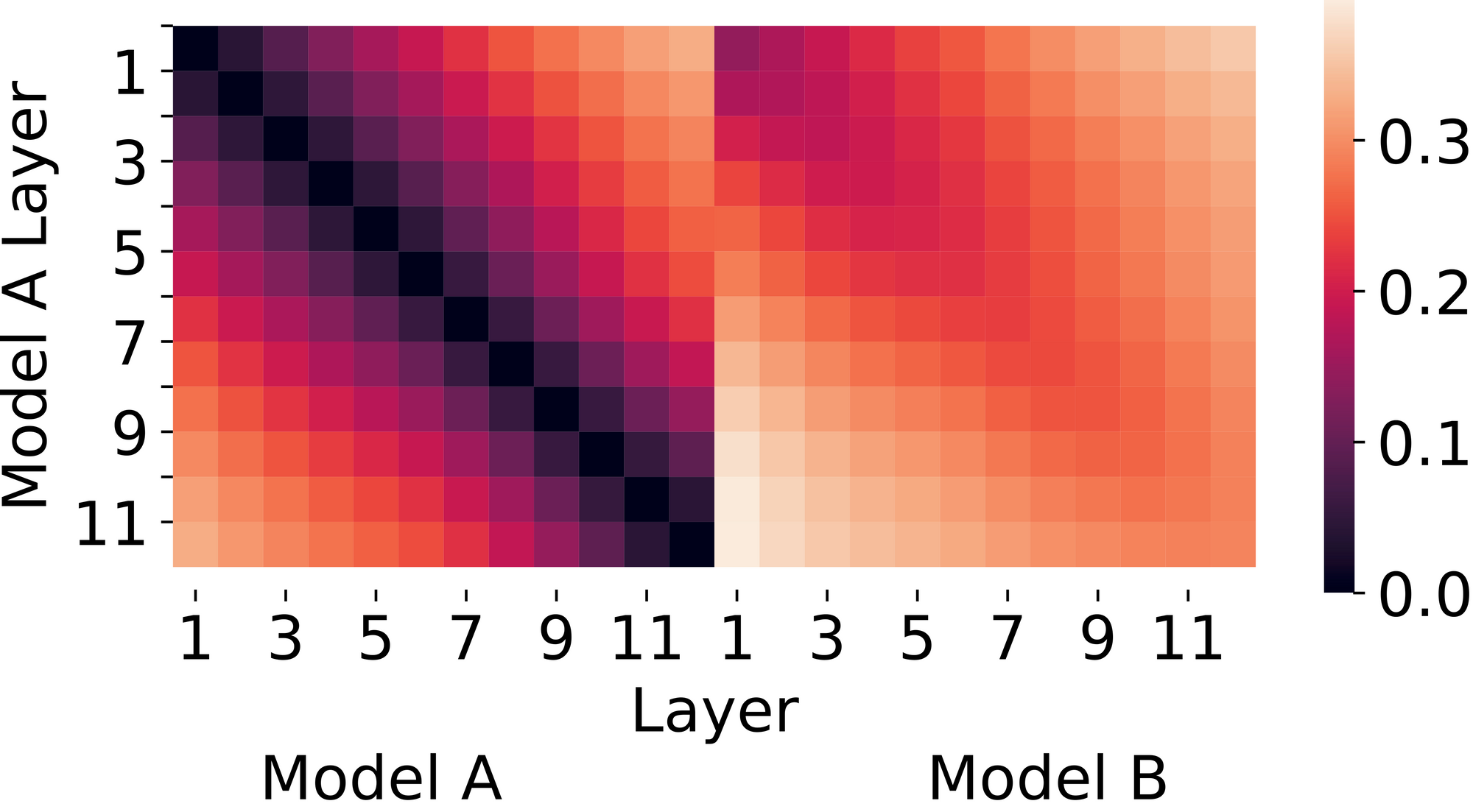
Determine 2. CCA (Canonical Correlation Evaluation) similarity between the identical two networks. CCA distances recommend that the 2 networks study considerably completely different representations, particularly at later layers.
Within the literature, researchers usually suggest new metrics and justify them based mostly on intuitive desiderata that have been lacking from earlier metrics. For instance, Morcos et al. inspire CCA by arguing that similarity metrics ought to be invariant to invertible linear transformations [5]. Kornblith et al. disagree about which invariances a similarity metric ought to have, and as an alternative argue that metrics ought to move an intuitive check – given two skilled networks with the identical structure however completely different initialization, layers on the similar depth ought to be most related to one another – and their proposed metric, CKA, performs one of the best on their check [4].
Our paper, Grounding Illustration Similarity with Statistical Testing, argues towards this follow. To begin, we present that by selecting completely different intuitive exams, we are able to make any technique look good. CKA does nicely on a “specificity check” just like the one proposed by Kornblith et al., however it does poorly on a “sensitivity check” that CCA shines on.
To maneuver past intuitive exams, our paper offers a carefully-designed quantitative benchmark for evaluating similarity metrics. The essential thought is {that a} good similarity metric ought to correlate with the precise performance of a neural community, which we operationalize as accuracy on a activity. Why? Accuracy variations between fashions are a sign that the fashions are processing knowledge in a different way, so intermediate representations have to be completely different, and similarity metrics ought to discover this.
Thus, for a given pair of neural community representations, we measure each their (dis)similarity and the distinction between their accuracies on some activity. If these are well-correlated throughout many pairs of representations, now we have a great similarity metric. In fact, an ideal correlation with accuracy on a specific activity additionally isn’t what we’re hoping for, since metrics ought to seize many vital variations between fashions, not only one. A great similarity metric is one which will get typically excessive correlations throughout a few functionalities.
We assess performance with a variety of duties. For a concrete instance, one subtask in our benchmark builds off the statement that BERT language fashions finetuned with completely different random seeds could have practically equivalent in-distribution accuracy, however broadly various out-of-distribution accuracy (for instance, starting from 0 to 60% on the HANS dataset [6]). Given two sturdy fashions, a similarity metric ought to fee them as related, and given one sturdy and one non-robust mannequin, a metric ought to fee them as dissimilar. Thus we take 100 such BERT fashions and consider whether or not (dis)similarity between every pair of mannequin representations correlates with their distinction in OOD accuracy.
Our benchmark consists of many of those subtasks, the place we gather mannequin representations that change alongside axes comparable to coaching seeds or layer depth, and consider the fashions’ functionalities. We embrace the next subtasks:
- Various seeds and layer depths, and assessing performance via linear probes (linear classifiers skilled on high of a frozen mannequin’s intermediate layer)
- Various seeds, layer depths, and principal part deletion, and assessing performance via linear probes
- Various finetuning seeds and assessing performance via OOD check units (described above)
- Various pretraining and finetuning seeds and assessing performance via OOD check units
Yow will discover the code for our benchmarks right here.
The desk beneath exhibits our outcomes with BERT language fashions (imaginative and prescient mannequin outcomes may be discovered within the paper). Along with the favored CKA and (PW)CCA metrics, we thought-about a classical baseline referred to as the Procrustes distance. Each CKA and PWCCA dominate sure benchmarks and fall behind on others, whereas Procrustes is extra constant and sometimes near the chief. As well as, our final subtask is difficult, with no similarity measure attaining excessive correlation. We current it as a problem activity to inspire additional progress for similarity metrics.
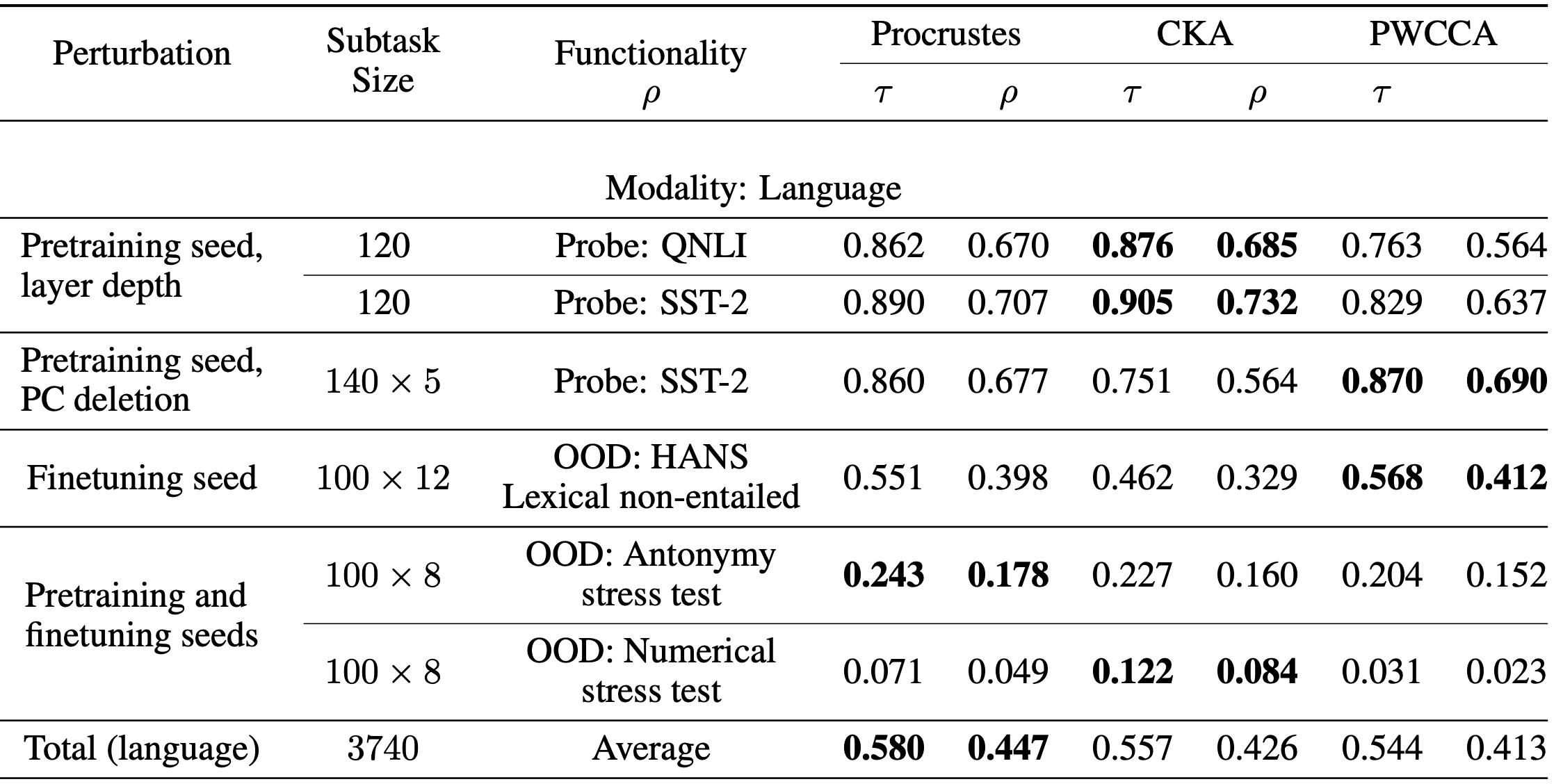
Ultimately, we have been shocked to see Procrustes achieve this nicely for the reason that current CKA and CCA strategies have gotten extra consideration, and we initially included Procrustes as a baseline for the sake of thoroughness. Constructing these benchmarks throughout many various duties was important for highlighting Procrustes as a great all-around technique, and it might be nice to see the creation of extra benchmarks that consider the capabilities and limitations of different instruments for understanding and deciphering neural networks.
For extra particulars, please see our full paper!
References
[1] Raghu, Maithra, et al. “Do Imaginative and prescient Transformers See Like Convolutional Neural Networks?.” arXiv preprint arXiv:2108.08810 (2021).
[2]Neyshabur, Behnam, Hanie Sedghi, and Chiyuan Zhang. “What’s being transferred in switch studying?.” NeurIPS. 2020.
[3] Gotmare, Akhilesh, et al. “A Nearer Have a look at Deep Studying Heuristics: Studying fee restarts, Warmup and Distillation.” Worldwide Convention on Studying Representations. 2018.
[4] Kornblith, Simon, et al. “Similarity of neural community representations revisited.” Worldwide Convention on Machine Studying. PMLR, 2019.
[5] Morcos, Ari S., Maithra Raghu, and Samy Bengio. “Insights on representational similarity in neural networks with canonical correlation.” Proceedings of the thirty second Worldwide Convention on Neural Info Processing Methods. 2018.
[6] R. T. McCoy, J. Min, and T. Linzen. Berts of a feather don’t generalize collectively: Giant variability in generalization throughout fashions with related check set efficiency. Proceedings of the Third BlackboxNLP Workshop on Analyzing and Decoding Neural Networks for NLP, 2020.
This publish is predicated on the paper “Grounding Illustration Similarity with Statistical Testing”, to be offered at NeurIPS 2021. You
can see full outcomes in our paper, and we present code to to breed
our experiments. We thank Juanky Perdomo and John Miller for his or her beneficial suggestions on this weblog
publish.
[ad_2]