

{kind=link}
[ad_1]
Getting into knowledge and shifting it from one place to a different is a time-consuming, repetitive job. One worker can simply spend as much as three hours a day simply shifting knowledge round. Along with consuming up employees’ time, handbook knowledge dealing with is liable to errors, which result in income losses.Â
A report by Dun & Bradstreet, investigating the previous and way forward for knowledge, revealed that one in 5 companies lose cash resulting from incomplete knowledge. Optical character recognition (OCR) know-how will help companies resolve these points. OCR algorithms can rework paper-based paperwork to editable searchable textual content.Â
They’ll additionally extract info from information and enter it into the corresponding fields in an organization’s IT methods. So, how does OCR work? How can this know-how assist you obtain enterprise objectives? And do you have to contact an synthetic intelligence options supplier that can assist you construct and arrange OCR software program?
What’s optical character recognition, and the way it works
OCR definition
Optical character recognition is a know-how that converts typed or handwritten textual content and printed pictures containing textual content into machine-readable digital knowledge format. OCR algorithms assist flip giant quantities of paper paperwork into digital information, facilitating textual content storage, processing, and looking out.
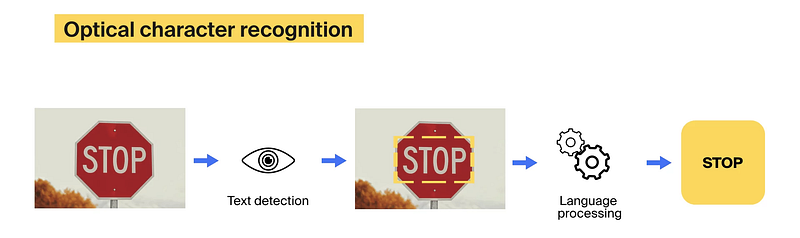
OCR methods include {hardware} and software program. The {hardware} half may be an optical scanner or the same machine that may convert paper paperwork to the digital format. The software program half is the OCR algorithm itself.
How does OCRÂ work?
It’s exhausting for computer systems to acknowledge characters due to the totally different fonts and variations on how one letter may be written. Handwritten letters complicate issues even additional. However, optical character recognition algorithms tackle this problem. Each OCR resolution operates in 4 fundamental steps:
Picture acquisition
The method entails utilizing an optical scanner to seize a digital copy of the paper doc. The doc needs to be correctly aligned and sized.
Pre-processing
The purpose of this section is to make the enter file usable by the OCR algorithm. The noise and background are eradicated. Pre-processing consists of the next steps:
- Format evaluation: figuring out captions, columns, and graphs as blocks
- De-skew: tilting the digital doc to make traces horizontal in case if it wasn’t correctly aligned throughout scanning

- Picture refinement: smoothing the perimeters, eradicating mud particles, growing distinction between textual content and background
- Textual content detection: some algorithms detect separate phrases and divide them into letters whereas others work with textual content straight with out splitting it into characters.

- Binarization: changing the scanned doc into black and white format, the place darkish areas characterize characters (alphabetic or numeric) and white areas are recognized as background. This step helps to acknowledge totally different fonts.
Character detection
Throughout this section, optical character recognition algorithms carry out totally different manipulations to acknowledge letters and numbers. There are two fundamental approaches:
- Sample recognition: OCR algorithms are educated on all kinds of fonts, textual content codecs, and handwriting types to match distinct characters from the enter file to what they’ve discovered.

- Characteristic recognition: some algorithms profit from identified character properties, similar to crossed and curved traces, to establish characters in enter information. For instance, a letter “H†is recognized as two vertical traces and one crossing horizontal line. OCR algorithms powered by neural networks (NN) use a special logic the place the primary NN layers mixture pixels from the enter file to create a low-level characteristic map of the picture.
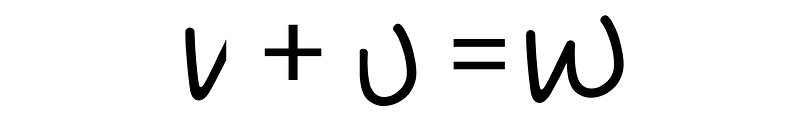
After detecting characters, this system converts them to American Commonplace Code for Info Change (ASCII) to facilitate additional manipulations.
Submit-processing
The output may be primary like a personality string or a file. Extra superior OCR options can retain the unique web page construction and create a PDF file with searchable textual content. Although there are not any instruments to date that may assure 100% accuracy on totally different enter information, some optical character recognition algorithms can obtain a powerful accuracy of 99.8% on acquainted texts. Utilizing handwriting will considerably compromise the outcomes. Additionally, it’s necessary to know that with poor coaching or unfamiliar texts the error charge may be as excessive as 20%. Therefore, it’s obligatory for customers to continually monitor, proofread, and proper OCR algorithms’ output, particularly when a brand new sort of paperwork enters the pipeline.Â
Submit-processing section also can contain pure language processing (NLP) and different AI strategies for knowledge verification. AI can’t solely appropriate the textual content but in addition catch errors in calculations. Let’s assume that whereas processing an bill, an OCR algorithm recognized the overall sum to be $500. AI can confirm this by including all of the bills and determining that they don’t quantity to $500. AI can notify a human worker to assessment this specific case.Â
If you wish to enhance the algorithm’s high quality, you may experiment with open-source OCR libraries, similar to Tesseract, that use their very own dictionary for character segmentation. One other method is to create a specialised glossary of phrases reoccurring in your area. Additionally, reviewers can use their suggestions as an enter to a different optical character recognition algorithm coaching session.
How can OCR algorithms profit your corporation?
Here’s what optical character recognition options can do for you:
- Reduce down prices: changing information to the digital format and automating knowledge entry reduces prices by way of worker hours
- Enhance buyer satisfaction: this know-how will allow folks to replace their private info remotely by scanning identification paperwork as a substitute of bodily visiting a financial institution or another institution
- Provide cheaper backup choices: there is no such thing as a must retailer paper-based paperwork along with their duplicates and triplicates, which consumes costly bodily storage items
- Facilitate translation amongst totally different languages: some OCR instruments have the power to translate paperwork from one language into one other
- Automate workflows: looking out by means of digital information with a very good administration system in place is quicker than coping with paper paperwork. Much less processes will likely be placed on maintain whereas searching for a misplaced bodily file. If you’re interested by a extra complete automation resolution, you may make the most of clever course of automation providers that embrace OCR and different superior capabilities.
OCR options out there on the market
If you’re occupied with incorporating OCR options into your IT methods, you’ve received a number of choices to select from.
Open-source optical character recognition algorithms
There are a number of open-source OCR algorithms that companies can adapt to their wants. These options are simpler to customise as their supply code is universally accessible. Nonetheless, there is no such thing as a central authority. Builders of open-source options don’t assume accountability and don’t supply additional assist. Therefore, the code’s high quality may be questionable. This selection is extra appropriate for firms with sturdy IT departments able to fixing any malfunctioning. Alternatively, you may attain out to machine studying consultants who can customise and retrain this software program for you.Â
Listed here are some generally used open-source OCR options:
Tesseract
Tesseract open-source engine is likely one of the hottest OCR instruments, and it’s believed to be among the many most correct free instruments. It was developed by Hewlett-Packard between 1985 and 1994. Ranging from 2006, this platform was managed and additional developed by Google. Tesseract is written in C++ nevertheless it gives wrappers in Java, Python, Swift, Ruby, and R, and some extra widespread programming languages.Â
The software operates utilizing a command line and doesn’t have a graphical consumer interface. Nonetheless, there are a number of GUI choices which you can deploy to make this resolution consumer pleasant. One instance is glmageReader. This interface is developed utilizing Python and helps totally different picture codecs, together with PNG, GIF, and PNM.
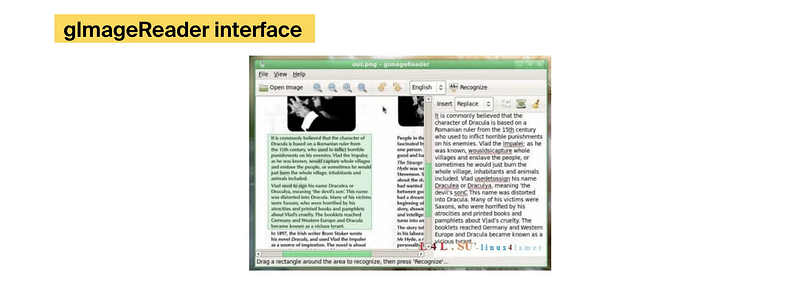
Tesseract doesn’t supply web page structure evaluation, doesn’t format the output, and its command line interface requires all pictures to be submitted in TIFF format. Moreover, this OCR resolution will not be optimized for GPU and doesn’t enable batch processing.
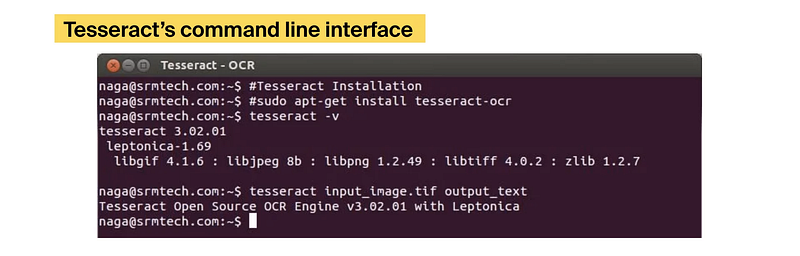
Tesseract’s command line interface
OCRopus
OCRopus was initially written in Python and now has a separate C++ model. It’s supported by Google and was used as an OCR engine for Google ReCaptcha algorithm.
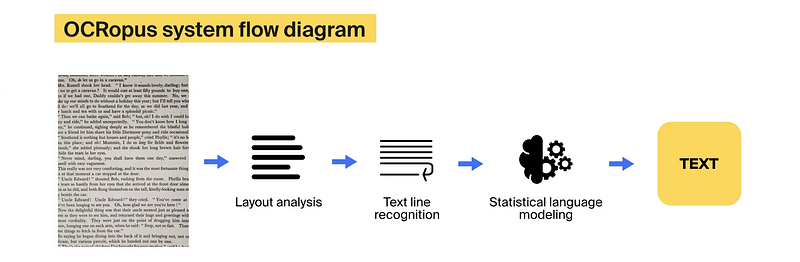
OCRopus has three fundamental options:
- Bodily structure evaluation: identifies textual content blocks, columns, and features and determines the studying order. For instance, to detect columns, it makes use of a maximal whitespace rectangle algorithm to detect white areas between columns.
- Line recognition: acknowledges traces inside every block or column, whether or not they’re vertical or left-to-right traces.
- Statistical language modeling: makes use of dictionaries and stochastic grammar to resolve the issue of lacking and unidentified letters.
EasyOCR
Jaided AI, an optical character recognition firm, constructed EasyOCR package deal utilizing Python and PyTorch library with its deep studying fashions. It helps over 80 languages together with Cyrillic scripts, Chinese language, and Arabic, and this base retains increasing. As part of the implementation roadmap, there are plans so as to add configurable choices for recognizing handwritten textual content.

Business OCR options
Software program as a service (SaaS) options will let you profit from high-quality algorithms and obtain full vendor assist. Relying on the chosen platform, you would possibly have the ability to retrain the OCR algorithm in your dataset and even additional adapt it to your distinctive wants.
Amazon Textract
Amazon Textract is a machine learning-based service that extracts printed and handwritten textual content from scanned paperwork. It may well work with unstructured knowledge and with formatted textual content, similar to kinds and tables. The answer makes use of AI and doesn’t want any additional configuration steps or templates. This service is safe and compliant with knowledge safety laws, such HIPAA and GDPR. Amazon Textract gives 4 APIs that clients can use and pay for accordingly:
- Detect doc textual content API: extracts unstructured printed textual content and handwriting from scans. Prices $0.0015 per web page for the primary a million pages; afterwards, the worth decreases.
- Analyze doc API: works with structured knowledge. Extracts textual content from kinds and tables. Purchasers can pay $0.015 per web page when processing tables, and $0.05 per web page within the case of kinds. The value decreases after the primary million pages.
- Analyze expense API: works with invoices. This service has a standard taxonomy of receipt-related fields. For instance, it could acknowledge bill quantity. Customers can pay $0.01 per web page for the primary million pages.
- Analyze ID API: understands the context of id paperwork, similar to driver’s licenses and passports, and might extract textual content from particular fields. You possibly can profit from this service for $0.025 for the primary 100,000 pages.
Google Cloud Imaginative and prescient
Google gives Imaginative and prescient API, which may extract printed and handwritten textual content from paperwork and pictures. It incorporates two options for optical character recognition:
- Text_detection: extracts textual content from pictures, like pictures of visitors indicators
- Document_text_detection: captures texts in paperwork and pictures. It differs from the earlier characteristic as its response is optimized for dense texts.
Each options enable customers to course of the primary 1,000 items per 30 days free of charge. After that, you’ll pay $1.5 per every 1,000 items. This value will lower as you submit extra items per 30 days.
Microsoft Azure Laptop Imaginative and prescient
Microsoft gives OCR providers as part of its generic laptop imaginative and prescient API, not as a stand-alone characteristic. So, you pay for the entire package deal, which, along with optical character recognition, consists of identification of celebrities, landmarks, manufacturers, and common object detection. This API will value you $1 per 1,000 transactions for the primary million items. Afterwards, the worth decreases to $0.65 per 1,000 transactions, and can maintain declining as you submit extra content material.
Prime OCR use circumstances in numerous industries
Optical character recognition algorithms are gaining traction in numerous industries. Beneath are a number of the most distinguished OCR functions.
OCR in banking
Banking establishments use a great deal of paper-based paperwork of their workflows. These embrace cheques, buyer information, mortgage functions, financial institution statements, and so on. Adopting OCR recognition algorithms permits workers to retailer and entry all these paperwork digitally and prevents paperwork loss and harm.Â
Examine dealing withÂ
One instance of OCR on this sector is utilizing banking apps to deposit paper-based checks digitally. These options deploy optical character recognition algorithms to establish related fields in checks and carry out operations accordingly with out the necessity for an worker to switch all this knowledge manually. Moreover, such apps can carry out signature validation towards the present database and clear the test instantly.Â
Buyer onboardingÂ
As a substitute of getting an worker confirm shoppers’ id manually, OCR-powered options can extract and validate all related info from the particular person’s passport and different ID paperwork. This enables for fast verification and improves buyer expertise.Â
Consumer info updatingÂ
As a substitute of getting to go to or name a financial institution, with the assistance of OCR, shoppers can scan their paperwork to replace info routinely. For instance, Alfa-Financial institution collaborated with Good Engines to reinforce their banking app with optical character recognition capabilities. With this new characteristic, clients can place ID paperwork in entrance of their smartphone’s cameras, affirm the extracted knowledge, and replace their info within the banking system.
OCR in healthcare
Much like the banking sector, healthcare organizations accumulate many paper paperwork, similar to X-ray scans, take a look at outcomes, therapy plans, and so forth. OCR algorithms assist digitize these information to stop lack of bodily paperwork and cut back efforts wasted on dealing with paper information manually. Moreover, some OCR options that acknowledge handwritten textual content can course of affected person enrollment papers and prescriptions.Â
Medical claims systemÂ
There are software program distributors who specialise in OCR-enabled medical declare processing. One such firm is OCR Options. It developed a product that may scan, confirm, and accurately route medical claims for additional dealing with. This program is educated and configured to work with widespread codecs, similar to Dental Declare Types and CMS-1500, amongst others.Â
FaxÂ
Many medical amenities nonetheless depend on fax. Optical character recognition options can convert incoming materials into accessible digitally saved format.Â
InvoicingÂ
OCR-powered options assist healthcare organizations digitize invoices and file them accurately. One OCR instance comes from San Francisco-based Nanonets, which gives an OCR-powered resolution that focuses on bill processing. The corporate claims its software program will cut back bill knowledge entry time from three minutes per bill to simply 30 seconds.
OCR in retail
Optical character recognition algorithms allow retail workers to save lots of time on processing buy orders, invoices, packing lists, and different paperwork. These options also can extract serial numbers from merchandise’ barcodes and allow clients to scan their vouchers and extract serial codes.Â
ID scanningÂ
Retailer workers might must scan private info for a lot of causes, similar to age verification, filling info for buyer loyalty, and extra. OCR distributors capitalize on this chance.Â
As an example, OCR Options, primarily based in Florida, developed idMax, an OCR-powered software program that may scan ID paperwork, extract related fields, and populate the retailer’s database with corresponding info. idMax may be put in regionally or accessed by means of the cloud.
Challenges of adopting an OCR resolution in your enterprise
In the event you determined to deploy OCR recognition algorithms to enhance your operations, there are a number of points that you must contemplate:
- Enter materials: be sure all enter information are appropriate for the OCR algorithm. For instance, the information should be free of harm that may intervene with the algorithm’s capability to acknowledge its content material. The distinction is excessive sufficient, the pages are correctly aligned, and so on. Some algorithms have highly effective pre-processing capabilities and might resolve a few of these points for you. But when this isn’t the case, perhaps it’s a good suggestion to put money into a high-quality scanner and guarantee correct web page alignment.
- Coaching dataset: if you happen to resolve to coach or retrain optical character recognition algorithms, you must be sure the knowledge you intend to make use of faithfully represents your enter materials and incorporates sufficient appropriate annotations. In case your coaching dataset is just too small, or doesn’t include sufficient annotations, the algorithm won’t produce desired outcomes. Additionally, throughout coaching, you must pay particular consideration to comparable characters/symbols. For instance, numbers 2 and seven might look somewhat comparable, particularly if the algorithm is predicted to work with handwritten textual content. Knowledge scientists must cowl such distinctions within the coaching knowledge. One other instance may be utilizing OCR algorithms to detect and seize license plates on automobiles. You have to be sure your algorithm doesn’t go for a customized sticker with textual content on the again of a automobile mistaking it for a license plate.
- Handwritten textual content: with handwriting come quite a few further OCR challenges. There’s a giant number of writing types between totally different folks, even particular person consumer’s writing may be inconsistent. Gathering a dependable consultant coaching dataset is a problem as you must account for all of the totally different types. Cursive handwriting is especially difficult to course of. Additionally, whereas printed textual content is available in a straight line, handwriting tends to have variable rotations, which complicates issues much more.
- Scaling: if you happen to improve the variety of customers or the variety of requests per time slot, the system can collapse, particularly in case you are utilizing an open-source resolution and relying by yourself computing energy. In case of business OCR merchandise that run within the cloud, you may prepare and pay for extra capability.
- OCR algorithm’s efficiency monitoring: after deployment, the algorithm’s efficiency would possibly begin degrading resulting from various factors. One instance is the change in distribution between the coaching knowledge and the precise manufacturing knowledge. This happens when the mannequin begins engaged on datasets it wasn’t ready for, similar to totally different fonts or characters with uncommon inclines. These adjustments will have an effect on the mannequin’s output over time, and you must detect these points and retrain the mannequin accordingly to take care of its preliminary accuracy stage.
To sum up
Optical character recognition algorithms have the potential to hurry up your corporation processes. Nonetheless, there are related challenges to contemplate. The chosen algorithm is prone to want retraining, and it’s a tedious job to correctly annotate a big dataset. You additionally want to consider potential scaling as your corporation expands.Â
Adopting an open-source resolution appears tempting value smart nevertheless it comes with its disadvantages, similar to lack of assist and updates, which may open safety loopholes. Business options are extra dependable on this regard however may be pricey and exhausting to customise.Â
If you’re not sure of proceed and which OCR resolution is the very best match for your corporation, don’t hesitate to achieve out. At ITRex, we will likely be completely satisfied to conduct a radical analysis of your corporation wants to find out the very best OCR possibility. We are able to additionally assist you retrain the chosen resolution and combine it into your system. We are able to additionally construct a customized OCR algorithm, if wanted.Â
Do you wish to pace up your operations with optical character recognition? Drop ITRex a line! Their AI consultants will help you with OCR resolution integration and coaching. They’ll additionally develop customized algorithms for you, if wanted.Â
The publish How Optical Character Recognition Algorithms Redefine Enterprise Processes appeared first on Datafloq.
[ad_2]