
{kind=link}
[ad_1]
It is a visitor submit by Diego Benavides and Luis Bendezú, Senior Knowledge Architects, Knowledge Structure Path at Belcorp.
Belcorp is likely one of the foremost shopper packaged items (CPG) firms offering cosmetics merchandise within the area for greater than 50 years, allotted to round 13 nations in North, Central, and South America (AMER). Born in Peru and with its personal product manufacturing facility in Colombia, Belcorp all the time stayed forward of the curve and tailored its enterprise mannequin in accordance with buyer wants and strengthened its technique with technological developments, offering every time a greater buyer expertise. Targeted on this, Belcorp started to implement its personal knowledge technique encouraging using knowledge for decision-making. Primarily based on this technique, the Belcorp knowledge structure workforce designed and carried out an information ecosystem permitting enterprise and analytics groups to eat useful knowledge that they use to generate hypotheses and insights which can be materialized in higher advertising methods or novel merchandise. This submit goals to element a collection of steady enhancements carried out throughout 2021 in an effort to scale back the variety of platform incidents reported on the finish of 2020, optimize SLAs required by the enterprise, and be extra cost-efficient when utilizing Amazon EMR, leading to as much as 30% financial savings for the corporate.
To remain forward of the curve, stronger firms have constructed an information technique that permits them to enhance foremost enterprise methods, and even create new ones, utilizing knowledge as a foremost driver. As one of many foremost shopper packaged items (CPG) firms within the area, Belcorp will not be an exception—in recent times we’ve been working to implement data-driven decision-making.
We all know that every one good knowledge technique is aligned to enterprise goals and based mostly on foremost enterprise use circumstances. At present, all our workforce efforts are centered on the ultimate customers, and virtually all enterprise initiatives are associated to hyper-personalization, pricing, and buyer engagement.
To help these initiatives, the info structure division offers knowledge providers like knowledge integration, just one supply of fact, knowledge governance and knowledge high quality frameworks, knowledge availability, knowledge accessibility, and optimized time to market, in accordance with enterprise necessities like different huge firms. To supply minimal capabilities to help all these providers, we wanted a scalable, versatile, and cost-efficient knowledge ecosystem. Belcorp began this journey a few years in the past utilizing AWS providers like Amazon Elastic Compute Cloud (Amazon EC2), AWS Lambda, AWS Fargate, Amazon EMR, Amazon DynamoDB, and Amazon Redshift, which at the moment feed our foremost analytical options with knowledge.
As we have been rising, we needed to regularly enhance our structure design and processing framework with regard to knowledge quantity and extra advanced knowledge answer necessities. We additionally needed to undertake high quality and monitoring frameworks in an effort to assure knowledge integrity, knowledge high quality, and repair stage agreements (SLAs). As you possibly can anticipate, it’s not a straightforward process, and requires its personal technique. Initially of 2021 and attributable to vital incidents we have been discovering, operational stability was affected, instantly impacting enterprise outcomes. Billing was additionally impacted, attributable to extra new advanced workloads being included, which precipitated an sudden enhance in platform prices. In response, we determined to concentrate on three challenges:
- Operational stability
- Value-efficiency
- Service stage agreements
This submit particulars some motion factors we carried out throughout 2021 over Belcorp’s knowledge processing framework based mostly on Amazon EMR. We additionally focus on how these actions helped us face the challenges beforehand talked about, and likewise present financial financial savings to Belcorp, which was the info structure workforce’s foremost contribution to the corporate.
Overview of answer
Belcorp’s knowledge ecosystem consists by seven key functionality pillars (as proven within the following diagram) that outline our architectural design and provides us kind of technological versatile choices. Our knowledge platform might be labeled as part of the second technology of knowledge platforms, as talked about by Zhamak Dehghani in The best way to Transfer Past a Monolithic Knowledge Lake to a Distributed Knowledge Mesh. The truth is, it has all the constraints and restrictions of a Lakehouse method as talked about within the paper Lakehouse: A New Era of Open Platforms that Unify Knowledge Warehousing and Superior Analytics .
Belcorp’s knowledge platform helps two foremost use circumstances. On one facet, it offers knowledge to be consumed utilizing visualization instruments, encouraging self-service. On the opposite facet, it offers useful knowledge to end-users, like knowledge scientists or knowledge analysts, via distributed knowledge warehouses and object storage extra suited to superior analytical practices.

The next reference design explains the primary two layers answerable for offering useful knowledge for these use circumstances. The information processing layer consists of two sub-layers. The primary is Belcorp’s Knowledge Lake Integrator, which is a built-in, in-house Python answer with a set of API REST providers answerable for organizing all the info workloads and knowledge levels contained in the analytics repositories. It additionally works as a degree of management to distribute assets to be allotted for every Amazon EMR Spark job. The processing sub-layer is principally composed of the EMR cluster, which is answerable for orchestrating, monitoring, and sustaining all of the Spark jobs developed utilizing a Scala framework.

For the persistent repository layer, we use Amazon Easy Storage Service (Amazon S3) object storage as an information repository for analytics workloads, the place we’ve designed a set of knowledge levels which have operational and useful functions based mostly on the reference structure design. Discussing the repository design in additional depth is out of scope for this submit, however we should observe that it covers all of the widespread challenges associated to knowledge availability, knowledge accessibility, knowledge consistency, and knowledge high quality. As well as, it achieves all Belcorp’s wants required by its enterprise mannequin, regardless of all limitations and restrictions we inherit by the design beforehand talked about.
We are able to now transfer our consideration to the primary function of this submit.
As we talked about, we skilled vital incidents (a few of which existed earlier than) and sudden price will increase originally of 2021, which motivated us to take motion. The next desk lists among the foremost points that attracted our consideration.
| Reported Incidents | Affect |
| Delay in Spark jobs on Amazon EMR | Core workloads take a very long time |
| Delay in Amazon EMR nodes auto scaling | Workloads take a very long time |
| Enhance in Amazon EMR computational utilization per node | Sudden price enhance |
| Misplaced useful resource containers | Workloads course of an enormous knowledge crash |
| Overestimated reminiscence and CPUs | Sudden price enhance |
To face these points, we determined to alter methods and began to investigate every difficulty in an effort to establish the trigger. We outlined two motion traces based mostly on three challenges that the leaders needed us to work on. The next determine summarizes these traces and challenges.
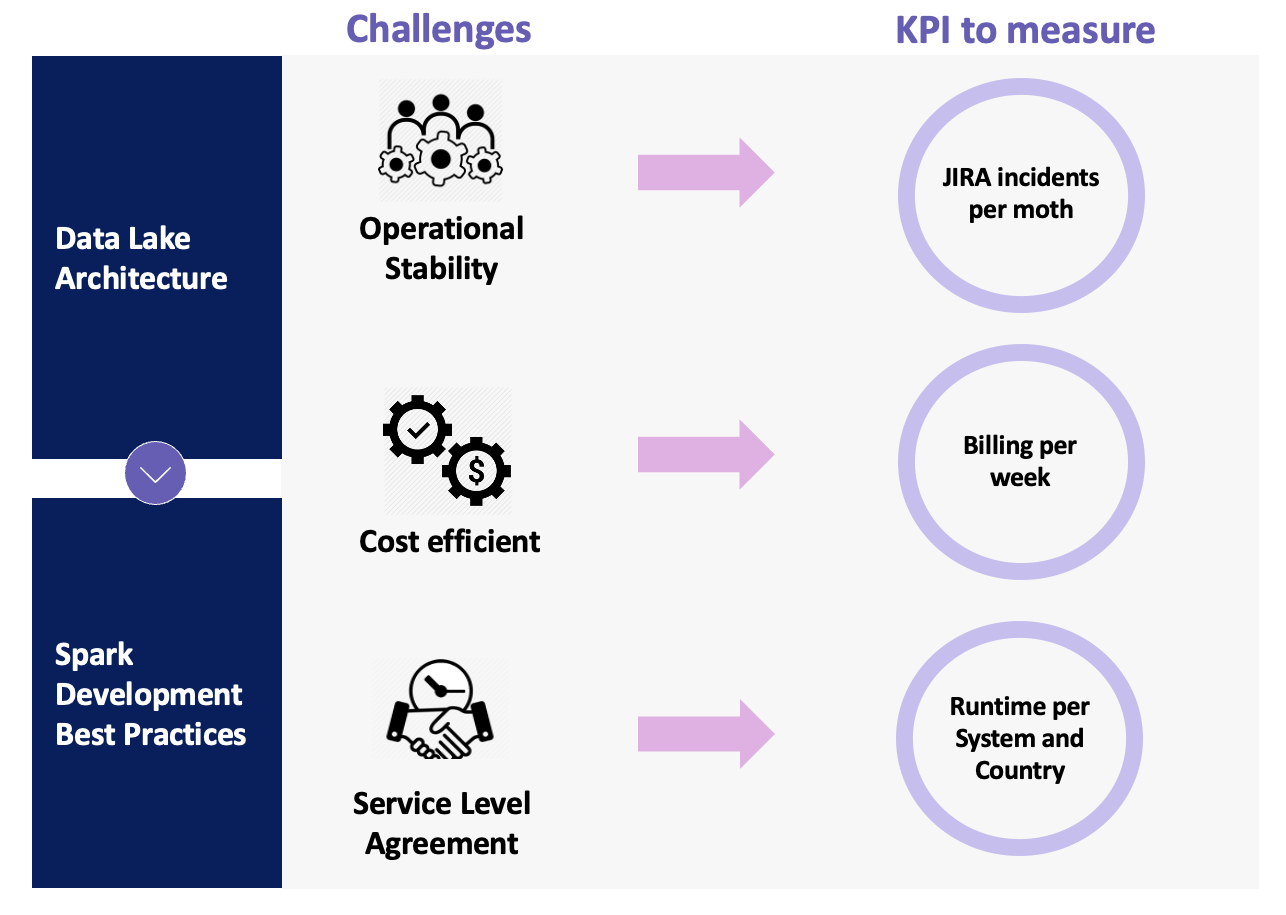
The information lake structure motion line refers to all of the architectural gaps and deprecated options that we decided as a part of the primary issues that have been producing the incidents. The Spark improvement finest practices motion line is expounded to the developed Spark knowledge answer that had been inflicting instability attributable to dangerous practices through the improvement lifecycle. Specializing in these motion traces, our leaders outlined three challenges in an effort to lower the variety of incidents and assure the standard of the service we offer: operational stability, cost-efficiency, and SLAs.
Primarily based on these challenges, we outlined three KPIs to measure the success of the challenge. Jira incidents enable us to validate that our adjustments are having a optimistic affect; billing per week reveals the leaders that a part of the adjustments we utilized will steadily optimize price; and runtime offers the enterprise customers with a greater time to market.
Subsequent, we outlined the subsequent steps and learn how to measure progress. Primarily based on our monitoring framework, we decided that the majority incidents that arose have been associated to the info processing and protracted repository layers. Then we needed to determine learn how to resolve them. We might make reactive fixes in an effort to obtain operational stability and never have an effect on enterprise, or we might change our normal manner of working, analyze every difficulty, and supply a last answer to optimize our framework. As you possibly can guess, we determined to alter our manner of working.
We carried out a preliminary evaluation to find out the primary impacts and challenges. We then proposed the next actions and enhancements based mostly on our motion traces:
- Knowledge lake structure – We redesigned the EMR cluster; we’re now utilizing core and process nodes
- Spark improvement finest practices – We optimized Spark parameters (RAM reminiscence, cores, CPUs, and executor quantity)
Within the subsequent part, we clarify intimately the actions and enhancements proposed in an effort to obtain our targets.
Actions and enhancements
As we talked about within the earlier part, the evaluation made by the structure workforce resulted in a listing of actions and enhancements that might assist us face three challenges: operational stability, a cost-efficient knowledge ecosystem, and SLAs.
Earlier than going additional, it’s a very good time to supply extra particulars in regards to the Belcorp knowledge processing framework. We constructed it based mostly on Apache Spark utilizing the Scala programming language. Our knowledge processing framework is a set of scalable, parameterizable, and reusable Scala artifacts that present improvement groups with a strong device to implement advanced knowledge pipelines, reaching essentially the most advanced enterprise necessities utilizing Apache Spark expertise. By the Belcorp DevOps framework, we deploy every artifact to a number of non-production environments. Then we promote into manufacturing, the place the EMR cluster launches all of the routines utilizing the Scala artifacts that reference every conceptual space contained in the analytical platform. This a part of the cycle offers the groups with a point of flexibility and agility. Nevertheless, we forgot, for a second, the standard of the software program we have been growing utilizing Apache Spark expertise.
On this part, we dive into the actions and enhancements we utilized in an effort to optimize the Belcorp knowledge processing framework and enhance the structure.
Redesigning the EMR cluster
The present design and implementation of the Belcorp knowledge lake will not be the primary model. We’re at the moment in model 2.0, and from the start of the primary implementation till now, we’ve tried totally different EMR cluster designs to implement the info processing layer. Initially, we used a hard and fast cluster with 4 nodes (as proven within the following determine), however when the auto scaling functionality was launched and Belcorp’s knowledge workloads elevated, we determined to maneuver it there to optimize useful resource utilization and prices. Nevertheless, an auto scaled EMR cluster has totally different choices too. You’ll be able to select between core and process nodes with a minimal and most variety of every. As well as, you possibly can choose On-Demand or Spot Cases. You may also implement an optimized allocation technique utilizing EMR occasion fleets to cut back the chance of Spot Occasion loss. For extra details about Amazon EMR assets allocation methods, see Spark enhancements for elasticity and resiliency on Amazon EMR and Optimizing Amazon EMR for resilience and price with capacity-optimized Spot Cases.

We examined all these capabilities, however we discovered some issues.
First, though AWS provides many capabilities and functionalities round Amazon EMR, in the event you don’t have a point of information in regards to the expertise that you simply need to use, you might encounter many points because the use circumstances come up. As we talked about, we determined to make use of the Apache Spark knowledge processing engine via Amazon EMR as part of Belcorp knowledge ecosystem, however we confronted many points. At any time when an incident appeared, it motivated the info architect workforce in cost to repair it, as part of the operational and help duties. Each one of these reactive fixes have been associated to altering Amazon EMR configuration to strive totally different alternate options in an effort to effectively resolve these incidents.
We discovered that the majority incidents have been associated to useful resource allocation, so we examined many configuration choices reminiscent of occasion varieties, growing the variety of nodes, custom-made guidelines for auto scaling, and fleet methods. This final possibility was used to cut back node loss. On the finish of 2020, we validated that an EMR cluster with computerized scaling enabled with a minimal capability of three On-Demand core nodes 24/7 and the power to scale as much as 25 On-Demand core nodes supplied us with a secure knowledge processing platform. Initially of 2021, extra advanced Spark jobs have been deployed as part of the info processing routines contained in the EMR cluster, inflicting operational instability once more. As well as, the billing was growing unexpectedly, which alerted leaders whose workforce wanted to revamp the EMR cluster in an effort to hold wholesome operational stability and optimize the prices.
We quickly realized that it was attainable to cut back as much as 40% of the present billing utilizing Spot Cases, as an alternative of protecting all core nodes in On-Demand consumption. One other infrastructure optimization that we needed to use was to exchange plenty of core nodes with process nodes, as a result of virtually all Belcorp knowledge workloads are memory-intensive and use Amazon S3 to learn the supply knowledge and write the outcome dataset. The query right here was how to do this with out shedding the advantages of the present design. To reply this query, we had the steerage of the AWS Account Staff and our AWS Analytics and Large Knowledge Specialist SA, in an effort to make clear questions in regards to the following:
- Apache Spark implementation in Amazon EMR
- Core and process node finest practices for manufacturing environments
- Spot Occasion conduct in Amazon EMR
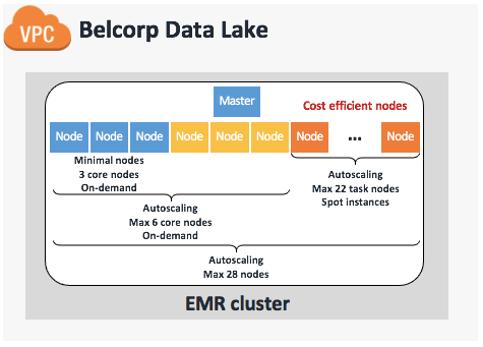
We undoubtedly suggest addressing these three details earlier than making use of any adjustments as a result of, in accordance with our earlier expertise, making modifications at midnight can result in pricey and underperforming Amazon EMR implementation. With that in thoughts, we redesigned the EMR cluster to make the most of EMR managed scaling, which mechanically resizes your cluster for finest efficiency on the lowest attainable price. We outlined a most of 28 capability items with three On-Demand core nodes all the time on (24/7) in an effort to help knowledge workloads through the day. We then set an auto scaling restrict of six On-Demand cores in an effort to present minimal HDFS capabilities to help the remaining 22 process nodes composed of Spot Cases. This last configuration is predicated on recommendation from AWS specialists that we’ve at the very least one core node to help six process nodes, protecting a 1:6 ratio. The next desk summarizes our cluster design.
| Cluster Scaling Coverage | Amazon EMR Managed Scaling Enabled |
Minimal node items (MinimumCapacityUnits) |
3 |
Most node items (a) |
28 |
On-demand restrict (MaximumOnDemandCapacityUnits) |
6 |
Most core nodes (MaximumCoreCapacityUnits) |
6 |
| Occasion sort | m4.10xlarge |
| Variety of major nodes | 1 |
| Main node occasion sort | m4.4xlarge |
The next determine illustrates our up to date and present cluster design.
Tuning Spark parameters
As any good e-book about Apache Spark can let you know, Spark parameter tuning is the primary matter it’s essential look into earlier than deploying a Spark software in manufacturing.
Adjusting Spark parameters is the duty of organising the assets (CPUs, reminiscence, and the variety of executors) to every Spark software. On this submit, we don’t concentrate on driver occasion assets; we concentrate on the executors as a result of that’s the primary difficulty we discovered inside Belcorp’s implementation.
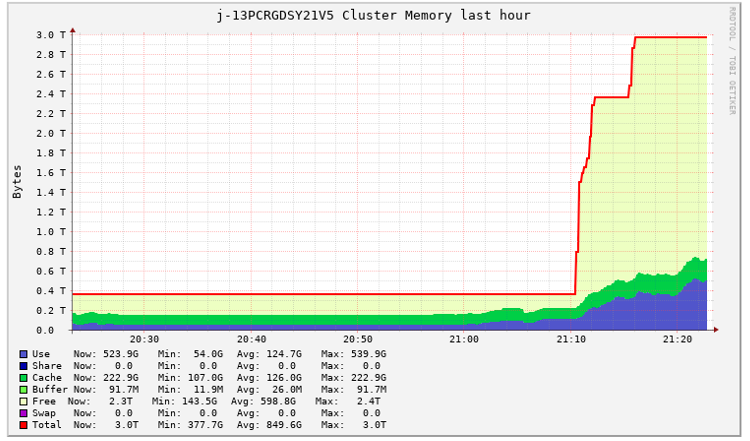
After we utilized enhancements round be a part of operation and cache methods in Spark software improvement, we realized that a few of these purposes have been assigned with overestimated assets within the EMR cluster. Meaning Spark purposes assigned assets, however solely 30% of the assets have been used. The next Ganglia report illustrates the overestimation of useful resource allocation for one Spark software job, which we captured throughout one in all our assessments.
A giant consequence of this conduct was the large deployment of EMR nodes that weren’t being correctly utilized. That implies that quite a few nodes have been provisioned due to the auto scaling characteristic required by a Spark software submit, however a lot of the assets of those nodes have been stored free. We present a primary instance of this later on this part.
With this proof, we started to suspect that we wanted to regulate the Spark parameters of a few of our Spark purposes.
As we talked about in earlier sections, as a part of the Belcorp knowledge ecosystem, we constructed a Knowledge Pipelines Integrator, which has the primary accountability of sustaining centralized management of the runs of every Spark software. To do this, it makes use of a JSON file containing the Spark parameter configuration and performs every spark-submit utilizing Livy service, as proven within the following instance code:
This JSON file comprises the Spark parameter configuration of every Spark software associated to an inner system and nation we undergo the EMR cluster. Within the following instance, CM is the title of the system and PE is the nation code that the info comes from:
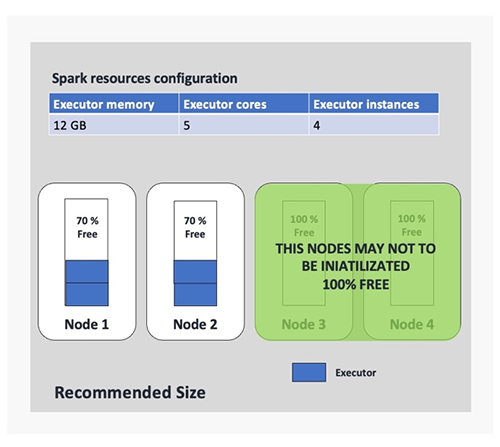
The issue with this method is that as we add extra purposes, the administration of those configuration information turns into extra advanced. As well as, we had a variety of Spark purposes arrange with a default configuration that was outlined a very long time in the past when workloads have been cheaper. So, it was anticipated that some issues would change. One instance of a Spark software with uncalibrated parameters is proven within the following determine (we use 4 executor cases just for the instance). On this instance, we realized we have been allocating executors with a variety of assets with out following any of the Spark finest practices. This was inflicting the provisioning of fats executors (utilizing Spark slang) allocating every of these in at the very least one node. That implies that if we outline a Spark software to be submitted utilizing 10 executors, we require at the very least 10 nodes of the cluster and use 10 nodes for just one run, which was very costly for us.

While you cope with Spark parameter tuning challenges, it’s all the time a good suggestion to comply with skilled recommendation. Maybe one of the crucial essential items of recommendation is expounded to the variety of executor cores you need to use in a single Spark software. Consultants counsel that an executor ought to have as much as 4 or 5 cores. We have been acquainted with this restriction as a result of we previously developed Spark purposes within the Hadoop ecosystem due to Hadoop File Programs I/O restrictions. That’s, if we’ve extra cores configured for one executor, we carry out extra I/O operations in a single HDFS knowledge node, and it’s well-known that HDFS degrades attributable to excessive concurrency. This constraint isn’t an issue if we use Amazon S3 as storage, however the suggestion stays because of the overload of the JVM. Keep in mind, whilst you have extra operational duties, like I/O operations, the JVM of every executor has extra work to do, so the JVM is degraded.
With these info and former findings, we realized that for a few of our Spark purposes, we have been utilizing solely 30% of the assigned assets. We would have liked to recalibrate the Spark job parameters in an effort to allocate solely the best-suited assets and considerably scale back the overuse of EMR nodes. The next determine offers an instance of the advantages of this enchancment, the place we are able to observe a 50% of node discount based mostly on our earlier configuration.
We used the next optimized parameters to optimize the Spark software associated to the CM system:
Outcomes
On this submit, we needed to share the success story of our challenge to enhance the Belcorp knowledge ecosystem, based mostly on two traces of actions and three challenges outlined by leaders utilizing AWS knowledge applied sciences and in-house platforms.
We have been clear about our goals from the start based mostly on the outlined KPIs, so we’ve been capable of validate that the variety of JIRA incidents reported on the finish of Could 2021 had a notable discount. The next figures reveals a discount of as much as 75% in respect to earlier months, highlighting March as a vital peak.

Primarily based on this incident discount, we discovered that the majority Spark job routines working within the EMR cluster benefitted from a runtime optimization, together with the 2 most advanced Spark jobs, with a discount as much as 60%, as proven within the following determine.
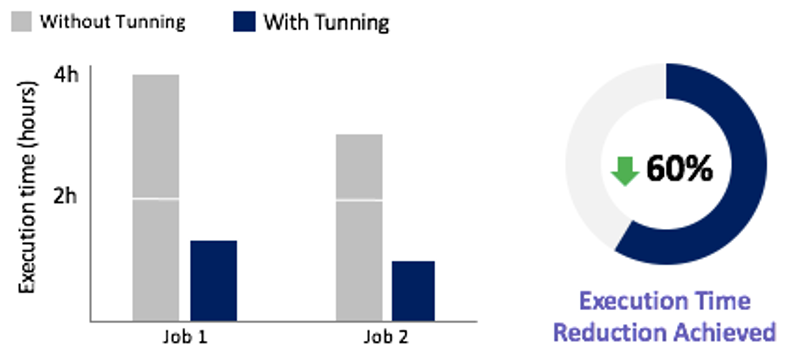
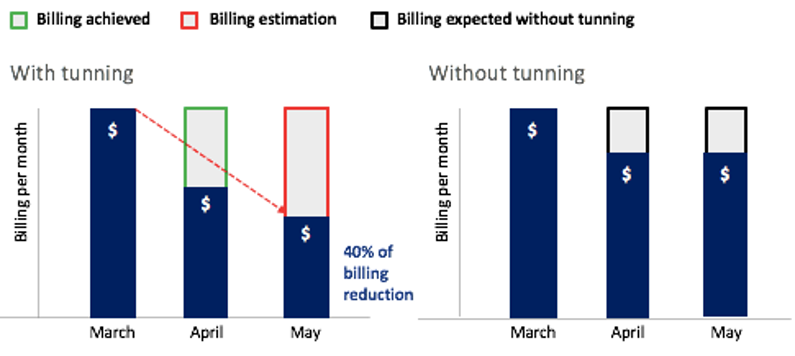
Maybe crucial contribution of the enhancements made by the workforce is instantly associated to the billing per week. For instance, Amazon EMR redesigning, the be a part of operation enhancements, cache finest practices utilized, and Spark parameter tuning—all of those produced a notable discount in using cluster assets. As we all know, Amazon EMR calculates billing based mostly on the time that the cluster nodes have been on, no matter whether or not they do any work. So, once we optimized EMR cluster utilization, we optimized the prices we have been producing as nicely. As proven within the following determine, solely in 2 months, between March and Could, we achieved a billing discount of as much as 40%. We estimate that we are going to save as much as 26% of the annual billing that might have been generated with out the enhancements.
Conclusion and subsequent steps
The information structure workforce is answerable for the Belcorp knowledge ecosystem’s steady enhancements, and we’re all the time being challenged to realize a best-in-class structure, craft higher architectural answer designs, optimize price, and create essentially the most automated, versatile, and scalable frameworks.
On the identical time, we’re excited about the way forward for this knowledge ecosystem—how we are able to adapt to new enterprise wants, generate new enterprise fashions, and deal with present architectural gaps. We’re working now on the subsequent technology of the Belcorp knowledge platform, based mostly on novel approaches like knowledge merchandise, knowledge mesh, and lake homes. We consider these new approaches and ideas are going to assist us to cowl our present architectural gaps within the second technology of our knowledge platform design. Moreover, it’s going to assist us higher arrange the enterprise and improvement groups in an effort to acquire larger agility through the improvement cycle. We’re considering of knowledge options as an information product, and offering groups with a set of technological elements and automatic frameworks they will use as constructing blocks.
Acknowledgments
We wish to thank our leaders, particularly Jose Israel Rico, Company Knowledge Structure Director, and Venkat Gopalan, Chief Expertise, Knowledge and Digital Officer, who encourage us to be buyer centric, insist on the very best requirements, and help each technical resolution based mostly on a stronger data of the cutting-edge.
Concerning the Authors
 Diego Benavides is the Senior Knowledge Architect of Belcorp answerable for the design, implementation, and the continual enchancment of the International and Company Knowledge Ecosystem Structure. He has expertise working with huge knowledge and superior analytics applied sciences throughout many business areas like telecommunication, banking, and retail.
Diego Benavides is the Senior Knowledge Architect of Belcorp answerable for the design, implementation, and the continual enchancment of the International and Company Knowledge Ecosystem Structure. He has expertise working with huge knowledge and superior analytics applied sciences throughout many business areas like telecommunication, banking, and retail.
 Luis Bendezú works as a Senior Knowledge Engineer at Belcorp. He’s answerable for steady enhancements and implementing new knowledge lake options utilizing plenty of AWS providers. He additionally has expertise as a software program engineer, designing APIs, integrating many platforms, decoupling purposes, and automating guide jobs.
Luis Bendezú works as a Senior Knowledge Engineer at Belcorp. He’s answerable for steady enhancements and implementing new knowledge lake options utilizing plenty of AWS providers. He additionally has expertise as a software program engineer, designing APIs, integrating many platforms, decoupling purposes, and automating guide jobs.
 Mar Ortiz is a bioengineer who works as a Options Architect Affiliate at AWS. She has expertise working with cloud compute and various applied sciences like media, databases, compute, and distributed structure design.
Mar Ortiz is a bioengineer who works as a Options Architect Affiliate at AWS. She has expertise working with cloud compute and various applied sciences like media, databases, compute, and distributed structure design.
 Raúl Hugo is an AWS Sr. Options Architect with greater than 12 years of expertise in LATAM monetary firms and world telco firms as a SysAdmin, DevOps engineer, and cloud specialist.
Raúl Hugo is an AWS Sr. Options Architect with greater than 12 years of expertise in LATAM monetary firms and world telco firms as a SysAdmin, DevOps engineer, and cloud specialist.
[ad_2]