

[ad_1]
As with all elements of our platform, we’re consistently elevating the bar and including new options to reinforce builders’ skills to construct the purposes that can make their Lakehouse a actuality. Constructing real-time purposes on Databricks isn’t any exception. Options like asynchronous checkpointing, session home windows, and Delta Stay Tables enable organizations to construct much more highly effective, real-time pipelines on Databricks utilizing Delta Lake as the inspiration for all the information that flows by the Lakehouse.
Nevertheless, for organizations that leverage Flink for real-time transformations, it’d seem that they’re unable to benefit from among the nice Delta Lake and Databricks options, however that isn’t the case. On this weblog we’ll discover how Flink builders can construct pipelines to combine their Flink purposes into the broader Lakehouse structure.
A stateful Flink utility
Let’s use a bank card firm to discover how we are able to do that.
For bank card corporations, stopping fraudulent transactions is table-stakes for a profitable enterprise. Bank card fraud poses each reputational and income threat to a monetary establishment and, subsequently, bank card corporations will need to have techniques in place to stay consistently vigilant in stopping fraudulent transactions. These organizations could implement monitoring techniques utilizing Apache Flink, a distributed event-at-a-time processing engine with fine-grained management over streaming utility state and time.
Under is an easy instance of a fraud detection utility in Flink. It screens transaction quantities over time and sends an alert if a small transaction is instantly adopted by a big transaction inside one minute for any given bank card account. By leveraging Flink’s ValueState information kind and KeyedProcessFunction collectively, builders can implement their enterprise logic to set off downstream alerts based mostly on occasion and time states.
import org.apache.flink.api.frequent.state.{ValueState, ValueStateDescriptor} import org.apache.flink.api.scala.typeutils.Sorts import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.capabilities.KeyedProcessFunction import org.apache.flink.util.Collector import org.apache.flink.walkthrough.frequent.entity.Alert import org.apache.flink.walkthrough.frequent.entity.Transaction object FraudDetector { val SMALL_AMOUNT: Double = 1.00 val LARGE_AMOUNT: Double = 500.00 val ONE_MINUTE: Lengthy = 60 * 1000L } @SerialVersionUID(1L) class FraudDetector extends KeyedProcessFunction[Long, Transaction, Alert] { @transient personal var flagState: ValueState[java.lang.Boolean] = _ @transient personal var timerState: ValueState[java.lang.Long] = _ @throws[Exception] override def open(parameters: Configuration): Unit = { val flagDescriptor = new ValueStateDescriptor("flag", Sorts.BOOLEAN) flagState = getRuntimeContext.getState(flagDescriptor) val timerDescriptor = new ValueStateDescriptor("timer-state", Sorts.LONG) timerState = getRuntimeContext.getState(timerDescriptor) } override def processElement( transaction: Transaction, context: KeyedProcessFunction[Long, Transaction, Alert]#Context, collector: Collector[Alert]): Unit = { // Get the present state for the present key val lastTransactionWasSmall = flagState.worth // Examine if the flag is about if (lastTransactionWasSmall != null) { if (transaction.getAmount > FraudDetector.LARGE_AMOUNT) { // Output an alert downstream val alert = new Alert alert.setId(transaction.getAccountId) collector.gather(alert) } // Clear up our state cleanUp(context) } if (transaction.getAmountAlong with sending alerts, most organizations will need the power to carry out analytics on all of the transactions they course of. Fraudsters are consistently evolving the strategies they use within the hopes of remaining undetected, so it's fairly probably {that a} easy heuristic-based fraud detection utility, such because the above, is not going to be adequate for stopping all fraudulent exercise. Organizations leveraging Flink for alerting will even want to mix disparate information units to create superior fraud detection fashions that analyze extra than simply transactional information, however embrace information factors corresponding to demographic data of the account holder, earlier buying historical past, time and placement of transactions, and extra.
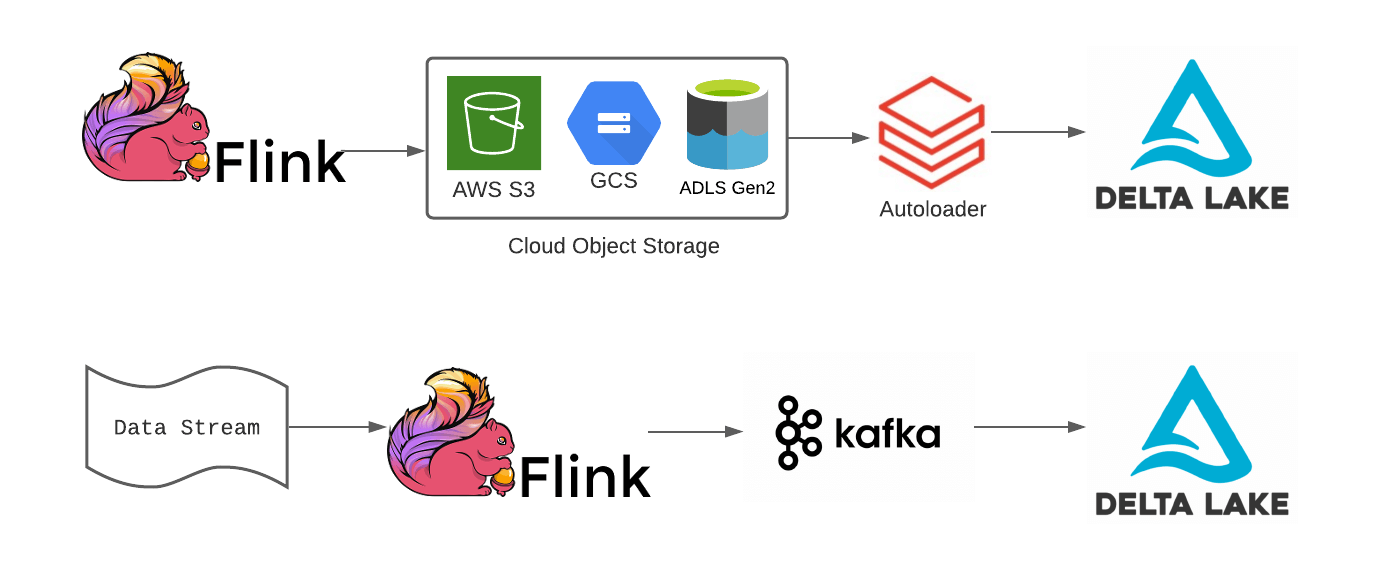
Integrating Flink purposes utilizing cloud object retailer sinks with Delta Lake
There's a tradeoff between very low-latency operational use-cases and working performant OLAP on large datasets. To fulfill operational SLAs and forestall fraudulent transactions, data have to be produced by Flink almost as rapidly as occasions are acquired, leading to small recordsdata (on the order of some KBs) within the Flink utility’s sink. This “small file downside” can result in very poor efficiency in downstream queries, as execution engines spend extra time itemizing directories and pulling recordsdata from cloud storage than they do really processing the information inside these recordsdata. Think about the identical fraud detection utility that writes transactions as parquet recordsdata with the next schema:
root |-- dt: timestamp (nullable = true) |-- accountId: string (nullable = true) |-- quantity: double (nullable = true) |-- alert: boolean (nullable = true)Luckily, Databricks Auto Loader makes it simple to stream information landed into object storage from Flink purposes into Delta Lake tables for downstream ML and BI on that information.
from pyspark.sql.capabilities import col, date_format data_path = "/demo/flink_delta_blog/transactions" delta_silver_table_path = "/demo/flink_delta_blog/silver_transactions" checkpoint_path = "/demo/flink_delta_blog/checkpoints/delta_silver" flink_parquet_schema = spark.learn.parquet(data_path).schema # Allow Auto Optimize to deal with the small file downside spark.conf.set("spark.databricks.delta.optimizeWrite.enabled", "true") spark.conf.set("spark.databricks.delta.autoCompact.enabled", "true") flink_parquet_to_delta_silver = (spark.readStream.format("cloudFiles") .choice("cloudFiles.format", "parquet") .schema(flink_parquet_schema) .load(data_path) .withColumn("date", date_format(col("dt"), "yyyy-MM-dd")) # use for partitioning the downstream Delta desk .withColumnRenamed("dt", "timestamp") .writeStream .format("delta") .choice("checkpointLocation", checkpoint_path) .partitionBy("date") .begin(delta_silver_table_path) )Delta Lake tables mechanically optimize the bodily format of information in cloud storage by compaction and indexing to mitigate the small file downside and allow performant downstream analytics.
-- Additional optimize the bodily format of the desk utilizing ZORDER. OPTIMIZE delta.`/demo/flink_delta_blog/silver_transactions` ZORDER BY (accountId)Very similar to Auto-Loader can remodel a static supply like cloud storage right into a streaming datasource, Delta Lake tables additionally perform as streaming sources regardless of being saved in object storage. Because of this organizations utilizing Flink for operational use circumstances can leverage this architectural sample for streaming analytics with out sacrificing their real-time necessities.
streaming_delta_silver_table = (spark.readStream.format("delta") .load(delta_silver_table_path) # ... further streaming ETL and/or analytics right here... )Integrating Flink purposes utilizing Apache Kafka and Delta Lake
Let’s say the bank card firm needed to make use of their fraud detection mannequin that they inbuilt Databricks, and the mannequin to attain the information in real-time. Pushing recordsdata to cloud storage may not be quick sufficient for some SLAs round fraud detection, to allow them to write information from their Flink utility to message bus techniques like Kafka, AWS Kinesis, or Azure Occasion Hub. As soon as the information is written to Kafka, a Databricks job can learn from Kafka and write to Delta Lake.
For Flink builders, there's a Kafka Connector that may be built-in along with your Flink initiatives to permit for DataStream API and Desk API-based streaming jobs to jot down out the outcomes to a company’s Kafka cluster. Be aware that as of the writing of this weblog, Flink doesn't come packaged with this connector, so you'll need to incorporate the Kafka Connector JAR in your venture’s construct file (i.e. pom.xml, construct.sbt, and many others).
Right here is an instance of how you'll write the outcomes of your DataStream in Flink to a subject on the Kafka Cluster:
package deal spendreport; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.atmosphere.StreamExecutionEnvironment; import org.apache.flink.walkthrough.frequent.entity.Transaction; import org.apache.flink.walkthrough.frequent.supply.TransactionSource; public class FraudDetectionJob { public static void predominant(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamtransactions = env .addSource(new TransactionSource()) .identify("transactions"); String brokers = “enter-broker-information-here” KafkaSink sink = KafkaSink. builder() .setBootstrapServers(brokers) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("transactions") .setValueSerializationSchema(new TransactionSchema()) .construct() ) .construct(); transactions.sinkTo(sink) env.execute("Fraud Detection"); } } Now you may simply leverage Databricks to jot down a Structured Streaming utility to learn from the Kafka matter that the outcomes of the Flink DataStream wrote out to. To determine the learn from Kafka...
kafka = (spark.readStream .format("kafka") .choice("kafka.bootstrap.servers", kafka_bootstrap_servers_plaintext ) .choice("subscribe", “fraud-events” ) .choice("startingOffsets", "newest" ) .load()) kafkaTransformed = kafka.choose(from_json(col(“worth”).solid(“string), schema) ...further transformationsAs soon as the information has been schematized, we are able to load our mannequin and rating the microbatch of information that Spark processes after every set off. For a extra detailed instance of Machine Studying fashions and Structured streaming, examine this text out in our documentation.
import pyspark.ml.Pipeline pipelineModel = Pipeline.load(“/path/to/educated/mannequin) streamingPredictions = (pipelineModel.remodel(kafkaTransformed) .groupBy(“id”) .agg( (sum(when('prediction === 'label, 1)) / rely('label)).alias("true prediction fee"), rely('label).alias("rely") ))Now we are able to write to Delta by configuring the writeStream and pointing it to our fraud_predictions Delta Lake desk. This may enable us to construct necessary reviews on how we monitor and deal with fraudulent transactions for our clients; we are able to even use the outputs to grasp how our mannequin is doing over time when it comes to what number of false positives it outputs or correct assessments.
streamingPredictions.writeStream .format(“delta”) .outputMode(“append”) .choice(“checkpointLocation”, “/location/in/cloud/storage”) .desk(“fraud_predictions”)Conclusion
With each of those choices, Flink and Autoloader or Flink and Kafka, organizations can nonetheless leverage the options of Delta Lake and guarantee they're integrating their Flink purposes into their broader Lakehouse structure. Databricks has additionally been working with the Flink group to construct a direct Flink to Delta Lake connector, which you'll be able to learn extra about right here.


{kind=link}
[ad_2]