

{kind=link}
[ad_1]
The AWS Glue Information Catalog gives partition indexes to speed up queries on extremely partitioned tables. Within the put up Enhance question efficiency utilizing AWS Glue partition indexes, we demonstrated how partition indexes scale back the time it takes to fetch partition info in the course of the planning section of queries run on Amazon EMR, Amazon Redshift Spectrum, and AWS Glue extract, remodel, and cargo (ETL) jobs.
We’re happy to announce Amazon Athena help for AWS Glue Information Catalog partition indexes. You should utilize the identical indexes configured for Amazon EMR, Redshift Spectrum, and AWS Glue ETL jobs with Athena to scale back question planning occasions for extremely partitioned tables, which is widespread in most knowledge lakes on Amazon Easy Storage Service (Amazon S3).
On this put up, we describe the best way to arrange partition indexes and carry out a couple of pattern queries to reveal the efficiency enchancment on Athena queries.
Arrange sources with AWS CloudFormation
That will help you get began shortly, we offer an AWS CloudFormation template, the identical template we utilized in a earlier put up. You may evaluation and customise it to fit your wants. A few of the sources this stack deploys incur prices when in use.
The CloudFormation template generates the next sources:
In the event you’re utilizing AWS Lake Formation permissions, you’ll want to be sure that the IAM consumer or function working AWS CloudFormation has the required permissions to create a database on the AWS Glue Information Catalog.
The tables created by the CloudFormation template use pattern knowledge positioned in an S3 public bucket. The information is partitioned by the columns yr, month, day, and hour. There are 367,920 partition folders in complete, and every folder has a single file in JSON format that incorporates an occasion much like the next:
To create your sources, full the next steps:
- Check in to the AWS CloudFormation console.
- Select Launch Stack:

- Select Subsequent.
- For DatabaseName, depart because the default.
- Select Subsequent.
- On the following web page, select Subsequent.
- Assessment the main points on the ultimate web page and choose I acknowledge that AWS CloudFormation may create IAM sources.
- Select Create.
Stack creation can take as much as 5 minutes. When the stack is full, you might have two Information Catalog tables: table_with_index and table_without_index. Each tables level to the identical S3 bucket, as talked about beforehand, which holds knowledge for greater than 42 years (1980–2021) in 367,920 partitions. Every partition folder features a knowledge.json file containing the occasion knowledge. Within the following sections, we reveal how the partition indexes enhance question efficiency with these tables utilizing an instance that represents giant datasets in an information lake.
Arrange partition indexes
You may create as much as three partition indexes per desk for brand spanking new and present tables. If you wish to create a brand new desk with partition indexes, you’ll be able to embrace a listing of PartitionIndex objects with the CreateTable API name. So as to add a partition index to an present desk, use the CreatePartitionIndex API name. You can even carry out these actions from the AWS Glue console.
Let’s configure a brand new partition index for the desk table_with_index we created with the CloudFormation template.
- On the AWS Glue console, select Tables.
- Select the desk
table_with_index. - Select Partitions and indices.
- Select Add new index.
- For Index identify, enter
year-month-day-hour. - For Chosen keys from schema, choose yr, month, day, and hour. Make that you just select every column on this order, and ensure that Partition key for every column is appropriately configured as follows:
yr: Partition (0)month: Partition (1)day: Partition (2)hour: Partition (3)
- Select Add index.
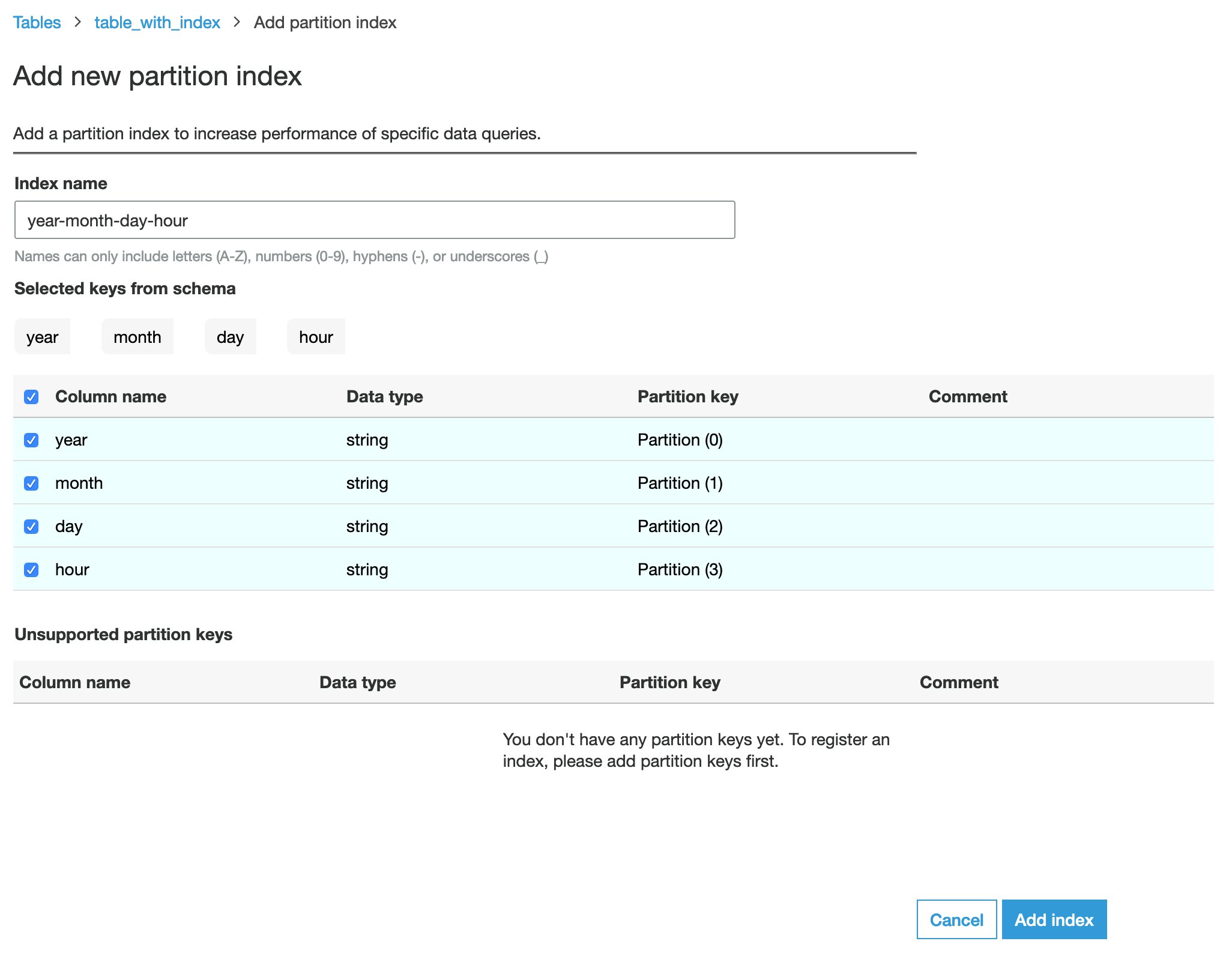
The Standing column of the newly created partition index reveals as Creating. We have to anticipate the partition index to be Lively earlier than it may be utilized by question engines. It ought to take about 1 hour to course of and construct the index for 367,920 partitions.

When the partition index is prepared for table_with_index, you need to use it when querying with Athena. For table_without_index, you must anticipate to see no change in question latency as a result of no partition indexes had been configured.
Allow partition filtering
To allow partition filtering in Athena, you’ll want to replace the desk properties as follows:
- On the AWS Glue console, select Tables.
- Select the desk
table_with_index. - Select Edit desk.
- Beneath Desk properties, add the next:
- Key –
partition_filtering.enabled - Worth –
true
- Key –
- Select Apply.

Alternatively, you’ll be able to set this parameter by working an ALTER TABLE SET PROPERTIES question in Athena:
Question tables utilizing Athena
Now that your desk has filtering enabled for Athena, let’s question each tables to see the efficiency variations.
First, question the desk with out utilizing the partition index. Within the Athena question editor, enter the next question:
The next screenshot reveals the question took 44.9 seconds.

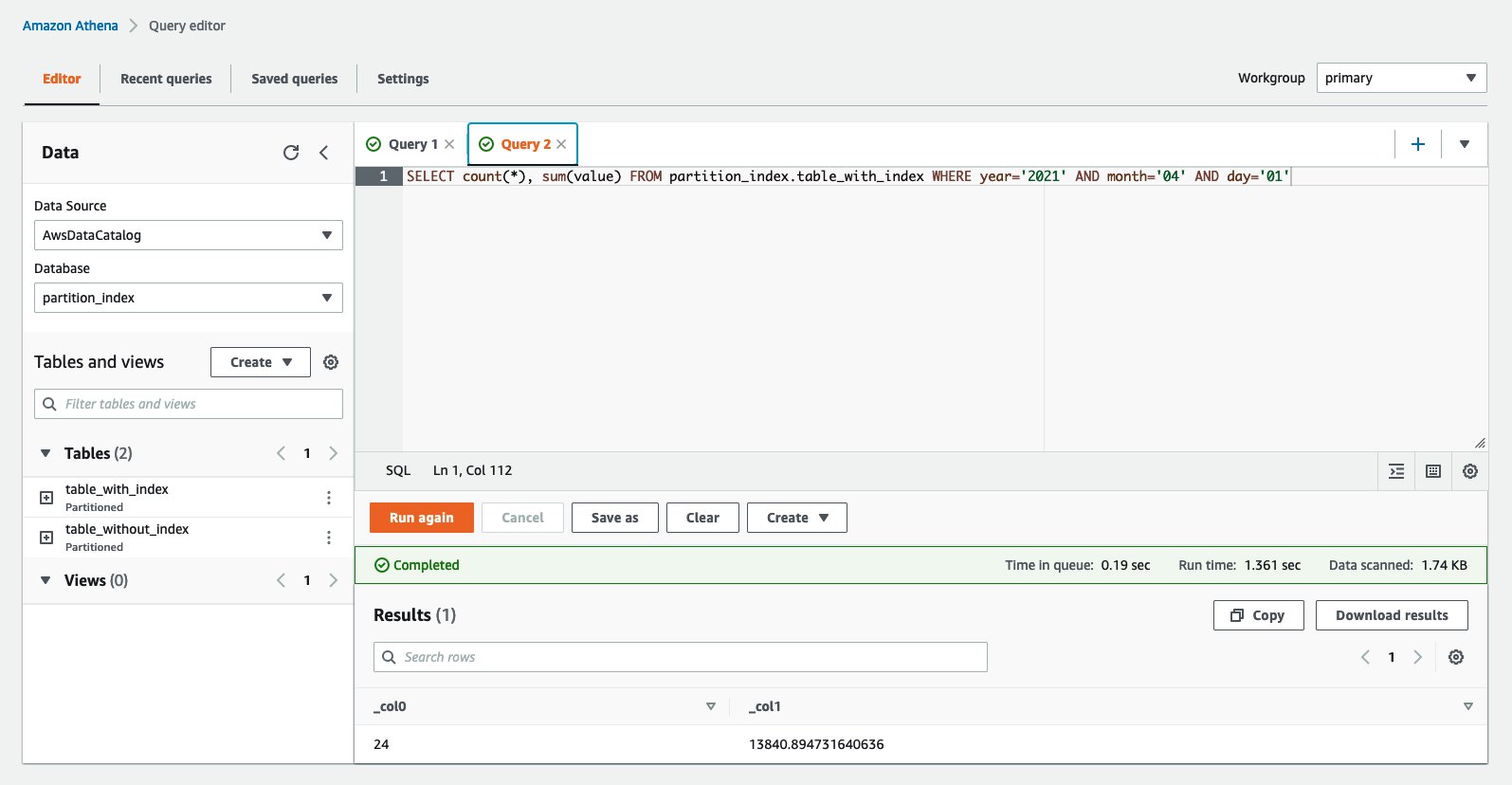
Subsequent, question the desk with utilizing the partition index. You could use the columns which might be configured for the indexes within the WHERE clause to realize these efficiency advantages. Run the next question:
The next screenshot reveals the question took simply 1.3 seconds to finish, which is considerably sooner than the desk with out indexes.
Question planning is the section the place the desk and partition metadata are fetched from the AWS Glue Information Catalog. With partition indexes enabled, retrieving solely the partitions required by the question will be performed extra effectively and due to this fact faster. Let’s retrieve the execution particulars of every question through the use of the AWS Command Line Interface (AWS CLI) to match planning statistics.
The next is the question execution particulars for the question that ran in opposition to a desk with out partition indexes:
The next is the question execution particulars for a question that ran in opposition to a desk with partition indexes:
QueryPlanningTimeInMillis represents the variety of milliseconds that Athena took to plan the question processing circulate. This contains the time spent retrieving desk partitions from the info supply. As a result of the question engine performs the question planning, the question planning time is a subset of engine processing time.
Evaluating the stats for each queries, we are able to see that QueryPlanningTimeInMillis is considerably decrease within the question utilizing partition indexes. It went from 44 seconds to 0.3 seconds when utilizing partition indexes. The development in question planning resulted in a sooner total question runtime, going from 45 seconds to 1.3 seconds—a 35 occasions better efficiency enchancment.
Clear up
Now to the ultimate step, cleansing up the sources:
- Delete the CloudFormation stack.
- Affirm each tables have been deleted from the AWS Glue Information Catalog.
Conclusion
At AWS, we try to enhance the efficiency of our companies and our clients’ expertise. The AWS Glue Information Catalog is a completely managed, Apache Hive appropriate metastore that allows a variety of massive knowledge, analytics, and machine studying companies, like Athena, Amazon EMR, Redshift Spectrum, and AWS Glue ETL, to entry knowledge within the knowledge lake. Athena clients can now additional scale back question latency by enabling partition indexes on your tables in Amazon S3. Utilizing partition indexes can enhance the effectivity of retrieving metadata for extremely partitioned tables ranging within the tens and a whole bunch of 1000’s and tens of millions of partitions.
You may be taught extra about AWS Glue Information Catalog partition indexes in Working with Partition Indexes, and extra about Athena finest practices in Greatest Practices When Utilizing Athena with AWS Glue.
In regards to the Creator
 Noritaka Sekiyama is a Principal Large Information Architect on the AWS Glue group. He’s enthusiastic about architecting fast-growing knowledge platforms, diving deep into distributed massive knowledge software program like Apache Spark, constructing reusable software program artifacts for knowledge lakes, and sharing the data in AWS Large Information weblog posts. In his spare time, he enjoys having and watching killifish, hermit crabs, and grubs along with his youngsters.
Noritaka Sekiyama is a Principal Large Information Architect on the AWS Glue group. He’s enthusiastic about architecting fast-growing knowledge platforms, diving deep into distributed massive knowledge software program like Apache Spark, constructing reusable software program artifacts for knowledge lakes, and sharing the data in AWS Large Information weblog posts. In his spare time, he enjoys having and watching killifish, hermit crabs, and grubs along with his youngsters.
[ad_2]