
{kind=link}
[ad_1]
[*]
AWS Glue is a totally managed serverless service that permits you to course of knowledge coming via totally different knowledge sources at scale. You should use AWS Glue jobs for numerous use instances corresponding to knowledge ingestion, preprocessing, enrichment, and knowledge integration from totally different knowledge sources. AWS Glue model 3.0, the newest model of AWS Glue Spark jobs, supplies a performance-optimized Apache Spark 3.1 runtime expertise for batch and stream processing.
You’ll be able to writer AWS Glue jobs in numerous methods. In the event you choose coding, AWS Glue permits you to write Python/Scala supply code with the AWS Glue ETL library. In the event you choose interactive scripting, AWS Glue interactive classes and AWS Glue Studio notebooks lets you write scripts in notebooks by inspecting and visualizing the info. In the event you choose a graphical interface fairly than coding, AWS Glue Studio helps you writer knowledge integration jobs visually with out writing code.
For a production-ready knowledge platform, a growth course of and CI/CD pipeline for AWS Glue jobs is essential. We perceive the large demand for growing and testing AWS Glue jobs the place you like to have flexibility, an area laptop computer, a Docker container on Amazon Elastic Compute Cloud (Amazon EC2), and so forth. You’ll be able to obtain that by utilizing AWS Glue Docker pictures hosted on Docker Hub or the Amazon Elastic Container Registry (Amazon ECR) Public Gallery. The Docker pictures enable you to arrange your growth surroundings with extra utilities. You should use your most popular IDE, pocket book, or REPL utilizing the AWS Glue ETL library.
This submit is a continuation of weblog submit “Creating AWS Glue ETL jobs domestically utilizing a container“. Whereas the sooner submit launched the sample of growth for AWS Glue ETL Jobs on a Docker container utilizing a Docker picture, this submit focuses on the way to develop and check AWS Glue model 3.0 jobs utilizing the identical method.
Resolution overview
The next Docker pictures can be found for AWS Glue on Docker Hub:
- AWS Glue model 3.0 –
amazon/aws-glue-libs:glue_libs_3.0.0_image_01 - AWS Glue model 2.0 –
amazon/aws-glue-libs:glue_libs_2.0.0_image_01
You can too acquire the photographs from the Amazon ECR Public Gallery:
- AWS Glue model 3.0 –
public.ecr.aws/glue/aws-glue-libs:glue_libs_3.0.0_image_01 - AWS Glue model 2.0 –
public.ecr.aws/glue/aws-glue-libs:glue_libs_2.0.0_image_01
Notice: AWS Glue Docker pictures are x86_64 suitable and arm64 hosts are at present not supported.
On this submit, we use amazon/aws-glue-libs:glue_libs_3.0.0_image_01 and run the container on an area machine (Mac, Home windows, or Linux). This container picture has been examined for AWS Glue model 3.0 Spark jobs. The picture incorporates the next:
- Amazon Linux
- AWS Glue ETL Library (aws-glue-libs)
- Apache Spark 3.1.1
- Spark historical past server
- JupyterLab
- Livy
- Different library dependencies (the identical as those of the AWS Glue job system)
To arrange your container, you pull the picture from Docker Hub after which run the container. We display the way to run your container with the next strategies, relying in your necessities:
spark-submit- REPL shell (
pyspark) pytest- JupyterLab
- Visible Studio Code
Conditions
Earlier than you begin, ensure that Docker is put in and the Docker daemon is working. For set up directions, see the Docker documentation for Mac, Home windows, or Linux. Additionally just be sure you have a minimum of 7 GB of disk house for the picture on the host working Docker.
For extra details about restrictions when growing AWS Glue code domestically, see Native Growth Restrictions.
Configure AWS credentials
To allow AWS API calls from the container, arrange your AWS credentials with the next steps:
- Create an AWS named profile.
- Open
cmdon Home windows or a terminal on Mac/Linux, and run the next command:
Within the following sections, we use this AWS named profile.
Pull the picture from Docker Hub
In the event you’re working Docker on Home windows, select the Docker icon (right-click) and select Change to Linux containers… earlier than pulling the picture.
Run the next command to tug the picture from Docker Hub:
Run the container
Now you possibly can run a container utilizing this picture. You’ll be able to select any of following strategies based mostly in your necessities.
spark-submit
You’ll be able to run an AWS Glue job script by working the spark-submit command on the container.
Write your ETL script (pattern.py within the instance under) and put it aside beneath the /local_path_to_workspace/src/ listing utilizing the next instructions:
These variables are used within the docker run command under. The pattern code (pattern.py) used within the spark-submit command under is included within the appendix on the finish of this submit.
Run the next command to run the spark-submit command on the container to submit a brand new Spark utility:
REPL shell (pyspark)
You’ll be able to run a REPL (read-eval-print loop) shell for interactive growth. Run the next command to run the pyspark command on the container to begin the REPL shell:
pytest
For unit testing, you should use pytest for AWS Glue Spark job scripts.
Run the next instructions for preparation:
Run the next command to run pytest on the check suite:
JupyterLab
You can begin Jupyter for interactive growth and advert hoc queries on notebooks. Full the next steps:
- Run the next command to begin JupyterLab:
- Open http://127.0.0.1:8888/lab in your internet browser in your native machine to entry the JupyterLab UI.

- Select Glue Spark Native (PySpark) beneath Pocket book.
Now you can begin growing code within the interactive Jupyter pocket book UI.

Visible Studio Code
To arrange the container with Visible Studio Code, full the next steps:
- Set up Visible Studio Code.
- Set up Python.
- Set up Visible Studio Code Distant – Containers.
- Open the workspace folder in Visible Studio Code.
- Select Settings.
- Select Workspace.
- Select Open Settings (JSON).
- Enter the next JSON and put it aside:
Now you’re able to arrange the container.
- Run the Docker container:
- Begin Visible Studio Code.
- Select Distant Explorer within the navigation pane, and select the container
amazon/aws-glue-libs:glue_libs_3.0.0_image_01.
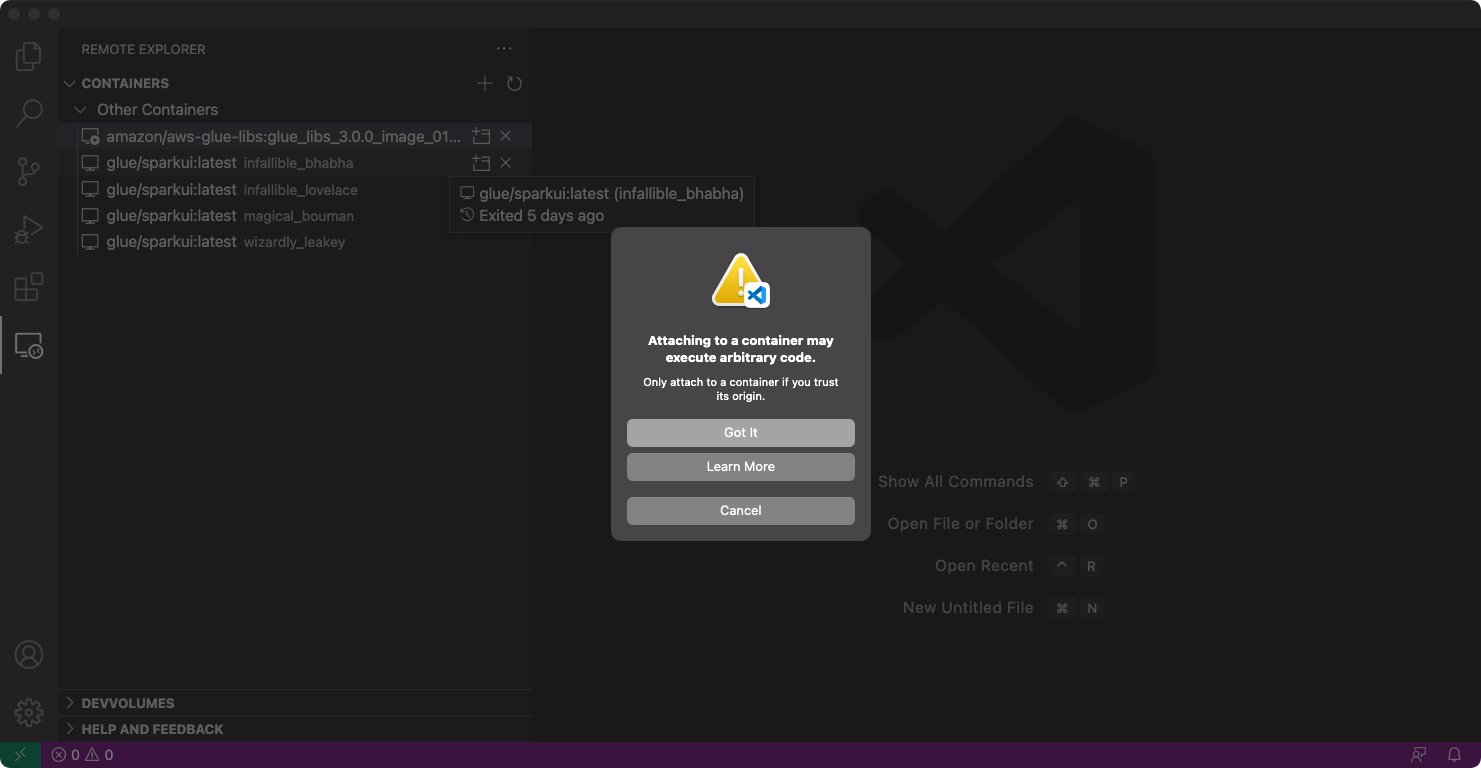
- Proper-click and select Connect to Container.

- If the next dialog seems, select Obtained it.
- Open
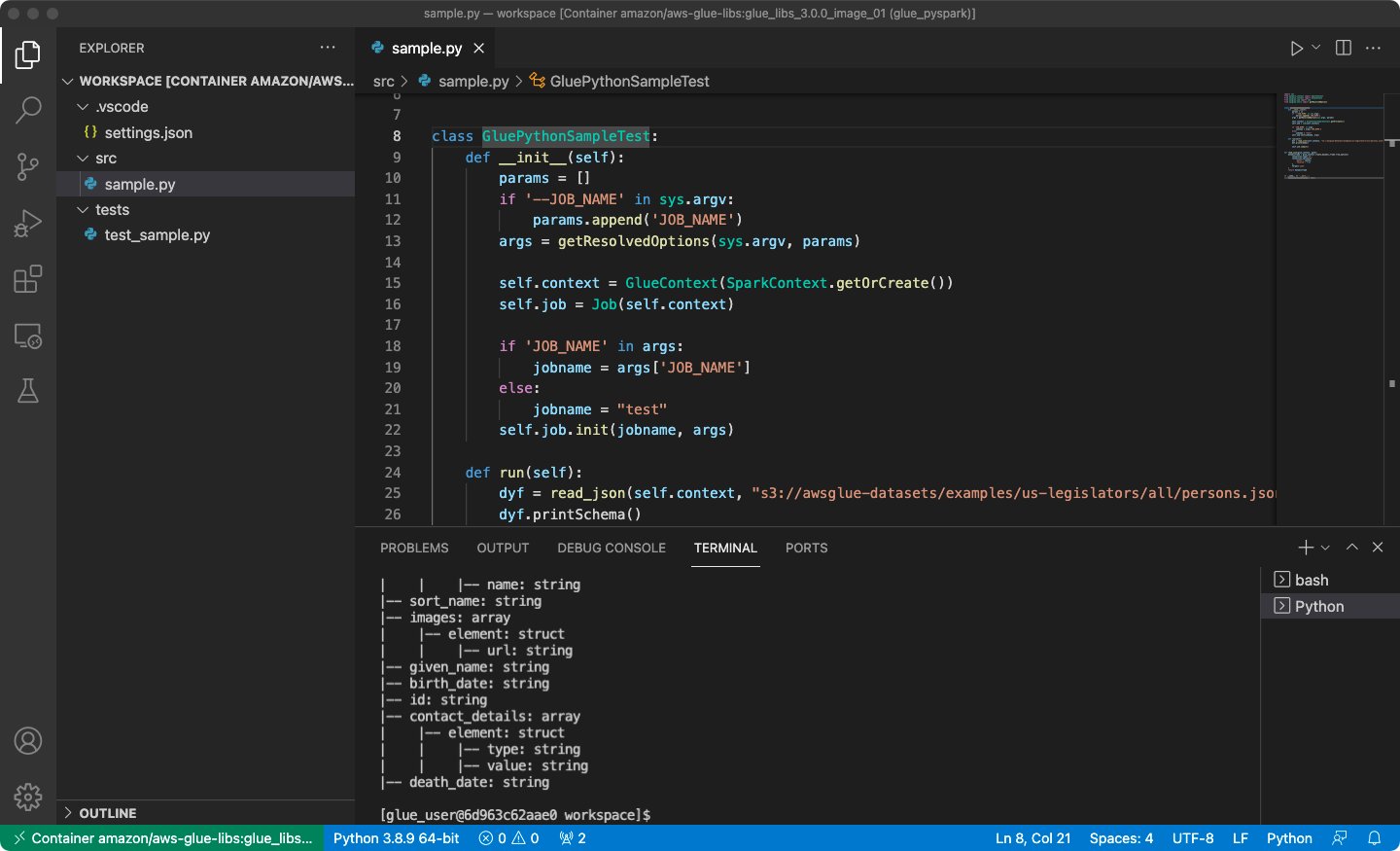
/dwelling/glue_user/workspace/. - Create an AWS Glue PySpark script and select Run.
You must see the profitable run on the AWS Glue PySpark script.
Conclusion
On this submit, we discovered the way to get began on AWS Glue Docker pictures. AWS Glue Docker pictures enable you to develop and check your AWS Glue job scripts anyplace you like. It’s accessible on Docker Hub and Amazon ECR Public Gallery. Test it out, we sit up for getting your suggestions.
Appendix: AWS Glue job pattern codes for testing
This appendix introduces three totally different scripts as AWS Glue job pattern codes for testing functions. You should use any of them within the tutorial.
The next pattern.py code makes use of the AWS Glue ETL library with an Amazon Easy Storage Service (Amazon S3) API name. The code requires Amazon S3 permissions in AWS Id and Entry Administration (IAM). You’ll want to grant the IAM-managed coverage arn:aws:iam::aws:coverage/AmazonS3ReadOnlyAccess or IAM customized coverage that permits you to make ListBucket and GetObject API requires the S3 path.
The next test_sample.py code is a pattern for a unit check of pattern.py:
Concerning the Authors
 Subramanya Vajiraya is a Cloud Engineer (ETL) at AWS Sydney specialised in AWS Glue. He’s keen about serving to prospects remedy points associated to their ETL workload and implement scalable knowledge processing and analytics pipelines on AWS. Outdoors of labor, he enjoys occurring bike rides and taking lengthy walks together with his canine Ollie, a 1-year-old Corgi.
Subramanya Vajiraya is a Cloud Engineer (ETL) at AWS Sydney specialised in AWS Glue. He’s keen about serving to prospects remedy points associated to their ETL workload and implement scalable knowledge processing and analytics pipelines on AWS. Outdoors of labor, he enjoys occurring bike rides and taking lengthy walks together with his canine Ollie, a 1-year-old Corgi.
 Vishal Pathak is a Knowledge Lab Options Architect at AWS. Vishal works with prospects on their use instances, architects options to resolve their enterprise issues, and helps them construct scalable prototypes. Previous to his journey in AWS, Vishal helped prospects implement enterprise intelligence, knowledge warehouse, and knowledge lake tasks within the US and Australia.
Vishal Pathak is a Knowledge Lab Options Architect at AWS. Vishal works with prospects on their use instances, architects options to resolve their enterprise issues, and helps them construct scalable prototypes. Previous to his journey in AWS, Vishal helped prospects implement enterprise intelligence, knowledge warehouse, and knowledge lake tasks within the US and Australia.
 Noritaka Sekiyama is a Principal Massive Knowledge Architect on the AWS Glue group. He enjoys studying totally different use instances from prospects and sharing information about massive knowledge applied sciences with the broader neighborhood.
Noritaka Sekiyama is a Principal Massive Knowledge Architect on the AWS Glue group. He enjoys studying totally different use instances from prospects and sharing information about massive knowledge applied sciences with the broader neighborhood.
[*][ad_2]