
{kind=link}
[ad_1]
Constructing a extremely performant knowledge mannequin for an enterprise knowledge warehouse (EDW) has traditionally concerned vital design, improvement, administration, and operational effort. Moreover, the information mannequin have to be agile and adaptable to alter whereas dealing with the biggest volumes of information effectively.
Information Vault is a technique for delivering undertaking design and implementation to speed up the construct of information warehouse tasks. Throughout the general methodology, the Information Vault 2.0 knowledge modeling requirements are fashionable and broadly used inside the business as a result of they emphasize the enterprise keys and their associations inside the supply of enterprise processes. Information Vault facilitates the speedy construct of information fashions by way of the next:
- Sample-based entities every with a well-defined objective
- Information silos are eliminated as a result of knowledge is represented in supply system unbiased buildings
- Information might be loaded in parallel with minimal dependencies
- Historized knowledge is saved at its lowest degree of granularity
- Versatile enterprise guidelines might be utilized independently of the loading of the information
- New knowledge sources might be added with no impression on the prevailing mannequin.
We all the time suggest working backwards from the enterprise necessities to decide on essentially the most appropriate knowledge modelling sample to make use of; there are occasions the place Information Vault won’t be the only option to your enterprise knowledge warehouse and one other modelling sample shall be extra appropriate.
On this submit, we reveal tips on how to implement a Information Vault mannequin in Amazon Redshift and question it effectively by utilizing the newest Amazon Redshift options, reminiscent of separation of compute from storage, seamless knowledge sharing, computerized desk optimizations, and materialized views.
Information Vault knowledge modeling overview
An information warehouse platform constructed utilizing Information Vault usually has the next structure:

The structure consists of 4 layers:
- Staging – Comprises a duplicate of the newest adjustments to knowledge from the supply programs. This layer doesn’t maintain historical past and, throughout its inhabitants, you possibly can apply a number of transformations to the staged knowledge, together with knowledge sort adjustments or resizing, character set conversion, and the addition of meta-data columns to help later processing.
- Uncooked Information Vault – Holds the historized copy of the entire knowledge from a number of supply programs. No filters or enterprise transformations have occurred at this level aside from storing the information in source-system unbiased targets.
- Enterprise Information Vault – An non-obligatory supply, however could be very usually constructed. It accommodates enterprise calculations and de-normalizations with the only real objective of bettering the velocity and ease of entry inside the consumption layer, which known as the Data Mart layer.
- Data Mart Layer – The place knowledge is mostly accessed by customers, for instance reporting dashboards or extracts. You possibly can construct a number of marts from the one Information Vault Integration Layer, and the commonest knowledge modeling alternative for these marts is Star/Kimball schemas.
Convert a Third Regular Type transactional schema to a Information Vault schema
The next entity relationship diagram is a normal implementation of a transactional mannequin {that a} sports activities ticket promoting service may use:
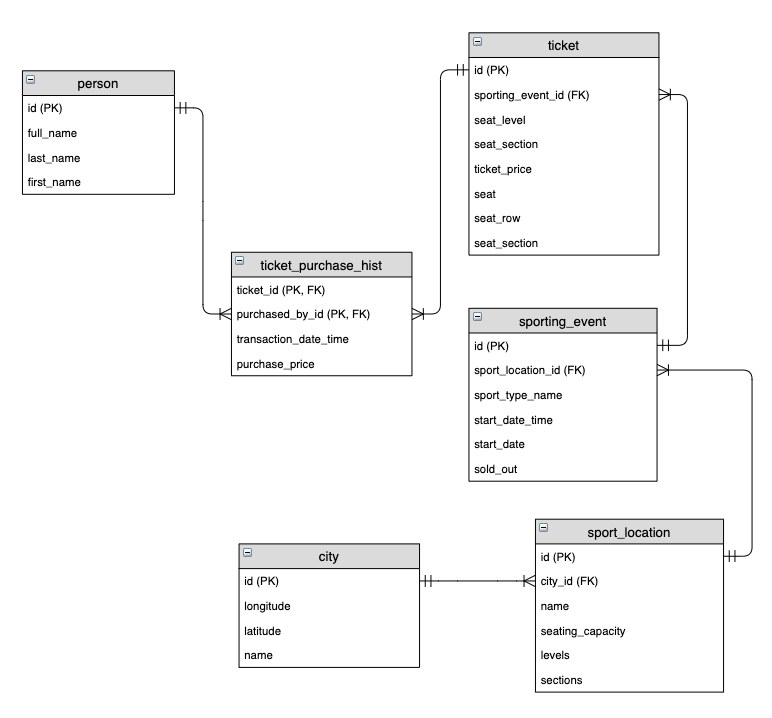
The primary entities inside the schema are sporting occasions, clients, and tickets. A buyer is an individual, and an individual should buy one or a number of tickets for a sporting occasion. This enterprise occasion is captured by the Ticket Buy Historical past intersection entity above. Lastly, a sporting occasion has many tickets out there to buy and is staged inside a single metropolis.
To transform this supply mannequin to a Information Vault mannequin, we begin to establish the enterprise keys, their descriptive attributes, and the enterprise transactions. The three foremost entity sorts within the Uncooked Information Vault mannequin are as follows:
- Hubs – A group of Enterprise Keys found for every enterprise entity.
- Hyperlinks – Enterprise transactions inside the course of being modelled. That is all the time between two or extra enterprise keys (hubs) and recorded at a time limit.
- Satellites – Historized reference knowledge about both the enterprise key (Hub) or enterprise transaction (hyperlink).
The next instance answer represents a few of the sporting occasion entities when transformed into the preceeding Uncooked Information Vault objects.
Hub entities
The hub is the definitive record of enterprise keys loaded into the Uncooked Information Vault layer from the entire supply programs. A enterprise secret’s used to uniquely establish a enterprise entity and is rarely duplicated. In our instance, the supply system has assigned a surrogate key subject referred to as Id to characterize the Enterprise Key, so that is saved in a column on the Hub referred to as sport_event_id. Some widespread extra columns on hubs embody the Load DateTimeStamp which data the date and time the enterprise key was first found, and the Report Supply which data the identify of the supply system the place this enterprise key was first loaded. Though, you don’t need to create a surrogate sort (hash or sequence) for the first key column, it is extremely widespread in Information Vault to hash the enterprise key, so our instance does this. Amazon Redshift helps a number of cryptographic hash capabilities like MD5, FNV, SHA1, and SHA2, which you’ll select to generate your main key column. See the next code :
Observe the next:
- The preceeding code assumes the MD5 hashing algorithm is used. If utilizing FNV_HASH, the datatype shall be Bigint.
- The Id column is the enterprise key from the supply feed. It’s handed into the hashing operate for the
_PKcolumn. - In our instance, there may be solely a single worth for the enterprise key. If a compound secret’s required, then multiple column might be added.
- Load_DTS is populated by way of the staging schema or extract, remodel, and cargo (ETL) code.
- Record_Source is populated by way of the staging schema or ETL code.
Hyperlink entities
The hyperlink object is the incidence of two or extra enterprise keys enterprise a enterprise transaction, for instance buying a ticket for a sporting occasion. Every of the enterprise keys is mastered of their respective hubs, and a main secret’s generated for the hyperlink comprising the entire enterprise keys (usually separated by a delimiter subject like ‘^’). As with hubs, some widespread extra columns are added to hyperlinks, together with the Load DateTimeStamp which data the date and time the transaction was first found, and the Report Supply which data the identify of the supply system the place this transaction was first loaded. See the next code:
Observe the next:
- The code assumes that the MD5 hashing algorithm is used. The
_PKcolumn is hashed values of concatenated ticket and sporting occasion enterprise keys from the supply knowledge feed, for instanceMD5(ticket_id||'^'||sporting_event_id) - The 2
_FKcolumns are overseas keys linked to the first key of the respective hubs. - Load_DTS is populated by way of the staging schema or ETL code.
- Record_Source is populated by way of the staging schema or ETL code.
Satellite tv for pc entities
The historical past of information concerning the hub or hyperlink is saved within the satellite tv for pc object. The Load DateTimeStamp is a part of the compound key of the satellite tv for pc together with the first key of both the hub or hyperlink as a result of knowledge can change over time. There are decisions inside the Information Vault requirements for tips on how to retailer satellite tv for pc knowledge from a number of sources. A typical strategy is to append the identify of the feed to the satellite tv for pc identify. This lets a single hub comprise reference knowledge from multiple supply system, and for brand new sources to be added with out impression to the prevailing design. See the next code:
Observe the next:
- The
sport_event_pkworth is inherited from the hub. - The compound secret’s the
sport_event_pkandload_dtscolumns. This permits historical past to be maintained. - The enterprise attributes are usually non-obligatory.
Load_DTSis populated by way of the staging schema or ETL code.- Record_Source is populated by way of the staging schema or ETL code.
- Hash_Diff is a Information Vault approach to simplify the identification of information adjustments inside satellites. The enterprise attribute values are concatenated and hashed along with your algorithm of alternative. Then, in the course of the ETL processing, solely the 2 hash values (one on the supply file and one on the newest dated satellite tv for pc file) must be in contrast.
Transformed Information Vault Mannequin
If we take the previous three Information Vault entity sorts above, we are able to convert the supply knowledge mannequin right into a Information Vault knowledge mannequin as follows:

The Enterprise Information Vault accommodates business-centric calculations and efficiency de-normalizations which might be learn by the Data Marts. A few of the object sorts which might be created within the Enterprise Vault layer embody the next:
- PIT (time limit) tables – You possibly can retailer knowledge in multiple satellite tv for pc for a single hub, every with a unique
Load DateTimeStamprelying on when the information was loaded. A PIT desk simplifies entry to all of this knowledge by making a desk or materialized view to current a single row with the entire related knowledge handy. The compound key of a PIT desk is the first key from the hub, plus a snapshot date or snapshot date and time for the frequency of the inhabitants. As soon as a day is the most well-liked, however equally the frequency might be each quarter-hour or as soon as a month. - Bridge tables – Much like PIT tables, bridge tables take the information from multiple hyperlink or hyperlink satellite tv for pc and once more de-normalize right into a single row. This single row view makes accessing complicated datasets over a number of tables from the Uncooked Information Vault rather more simple and performant. Like a PIT desk, the bridge desk might be both a desk or materialized view.
- KPI tables – The pre-computed enterprise guidelines calculate KPIs and retailer them in devoted tables.
- Kind 2 tables –You possibly can apply extra processing within the Enterprise Information Vault to calculate Kind 2 like time intervals as a result of the information within the Uncooked Information Vault follows an insert solely sample.
The structure of Amazon Redshift permits flexibility within the design of the Information Vault platform by utilizing the capabilities of the Amazon Redshift RA3 occasion sort to separate the compute sources from the information storage layer and the seamless potential to share knowledge between totally different Amazon Redshift clusters. This flexibility permits extremely performant and cost-effective Information Vault platforms to be constructed. For instance, the Staging and Uncooked Information Vault Layers are populated 24-hours-a-day in micro batches by one Amazon Redshift cluster, the Enterprise Information Vault layer might be constructed one-time-a-day and paused to save lots of prices when accomplished, and any variety of shopper Amazon Redshift clusters can entry the outcomes. Relying on the processing complexity of every layer, Amazon Redshift helps independently scaling the compute capability required at every stage.

The entire underlying tables in Uncooked Information Vault might be loaded concurrently. This makes nice use of the massively parallel processing structure in Amazon Redshift. For our enterprise mannequin, it is sensible to create a Enterprise Information Vault layer, which might be learn by an Data Mart to carry out dimensional evaluation on ticket gross sales. It may give us insights on the highest house groups in fan attendance and the way that correlates with particular sport places or cities. Operating these queries includes becoming a member of a number of tables. It’s necessary to design an optimum Enterprise Information Vault layer to keep away from extreme joins for deriving these insights.
For instance, to get the variety of tickets per metropolis for June 2021, the SQL appears to be like like the next code:
We are able to use the EXPLAIN command for the previous question to get the Amazon Redshift question plan. The next plan reveals that the desired joins require broadcasting knowledge throughout nodes, because the be a part of circumstances are on totally different keys. This makes the question computationally costly:
Let’s talk about the newest Amazon Redshift options that assist optimize the efficiency of those queries on high of a Enterprise Information Vault mannequin.
Use Amazon Redshift options to question the Information Vault
Computerized desk optimization
Historically, to optimize joins in Amazon Redshift, it’s really useful to make use of distribution keys and types to co-locate knowledge in the identical nodes, as primarily based on widespread be a part of predicates. The Uncooked Information Vault layer has a really well-defined sample, which is good for figuring out the distribution keys. Nevertheless, the broad vary of SQL queries relevant to the Enterprise Information Vault makes it exhausting to foretell your consumption sample that will drive your distribution technique.
Computerized desk optimization permits you to get the quickest efficiency shortly while not having to take a position time to manually tune and implement desk optimizations. Computerized desk optimization constantly observes how queries work together with tables, and it makes use of machine studying (ML) to pick out the most effective kind and distribution keys to optimize efficiency for the cluster’s workload. If Amazon Redshift determines that making use of a key will enhance cluster efficiency, then tables are routinely altered inside hours with out requiring administrator intervention.
Computerized Desk Optimization offered following suggestions for the above question to get the variety of tickets per metropolis for June 2021. The suggestions recommend modifying the distribution fashion and type keys for tables concerned in these queries.
After the really useful distribution keys and type keys had been utilized by Computerized Desk Optimization, the clarify plan reveals “DS_DIST_NONE” and no knowledge redistribution was required anymore for this question. The information required for the joins was co-located throughout Amazon Redshift nodes.
Materialized views in Amazon Redshift
The information analyst accountable for operating this evaluation advantages considerably by making a materialized view within the Enterprise Information Vault schema that pre-computes the outcomes of the queries by operating the next SQL:
To get the newest satellite tv for pc values, we should embody load_dts in our be a part of. For simplicity, we don’t do this for this submit.
You possibly can optimize this question each when it comes to code size and complexity to one thing so simple as the next:
The run plan on this case is as follows:
Extra importantly, Amazon Redshift can routinely use the materialized view even when that’s not explicitly said.
The previous situation addresses the wants of a particular evaluation as a result of the ensuing materialized view is an combination. In a extra generic situation, after reviewing our Information Vault ER diagram, you possibly can observe that any question that includes ticket gross sales evaluation per location requires a considerable variety of joins, all of which use totally different be a part of keys. Due to this fact, any such evaluation comes at a major price relating to efficiency. For instance, to get the rely of tickets bought per metropolis and stadium identify, it’s essential to run a question like the next:
You should use the EXPLAIN command for the previous question to get the clarify plan and know the way costly such an operation is:
We are able to establish generally joined tables, like hub_sport_event, hub_ticket and hub_location, after which increase the efficiency of queries by creating materialized views that implement these joins forward of time. For instance, we are able to create a materialized view to affix tickets to sport places:
If we don’t make any edits to the costly question that we ran earlier than, then the run plan is as follows:
Amazon Redshift now makes use of the materialized view for any future queries that contain becoming a member of tickets with sports activities places. For instance, a separate enterprise intelligence (BI) staff wanting into the dates with the very best ticket gross sales can run a question like the next:
Amazon Redshift can implicitly perceive that the question might be optimized by utilizing the materialized view we already created, thereby avoiding joins that contain broadcasting knowledge throughout nodes. This may be seen from the run plan:
If we drop the materialized view, then the previous question ends in the next plan:
Finish-users of the information warehouse don’t want to fret about refreshing the information within the materialized views. It’s because we enabled computerized materialized view refresh. Future use circumstances involving new dimensions additionally profit from the existence of materialized views.
Ready statements within the knowledge vault with materialized views in Amazon Redshift
One other sort of question that we are able to run on high of the Enterprise Information Vault schema is ready statements with bind variables. It’s fairly widespread to see person interfaces built-in with knowledge warehouses, which lets customers dynamically change the worth of the variable via choice in a alternative record or hyperlink in a cross-tab. When the variable adjustments, so do the question situation and the report or dashboard contents. The next question is a ready assertion to get the rely of tickets bought per metropolis and stadium identify. It takes the stadium identify as a variable and gives the variety of tickets bought in that stadium.
Let’s run the question to see the town and tickets bought for various stadiums handed as a variable on this ready assertion:
Let’s dive into the clarify plan of this ready assertion to grasp if Amazon Redshift can implicitly perceive that the question might be optimized by utilizing the materialized view bridge_tickets_per_stadium_mv that was created earlier:
As famous within the clarify plan, Amazon Redshift may optimize the clarify plan of the question to implicitly use the materialized view created earlier, even for ready statements.
Conclusion
On this submit, we’ve demonstrated tips on how to implement Information Vault mannequin in Amazon Redshift, thereby levering the out-of-the-box options. We additionally mentioned how Amazon Redshift’s options, reminiscent of seamless knowledge share, computerized desk optimization, materialized views, and computerized materialized view refresh might help you construct knowledge fashions that meet excessive efficiency necessities.
Concerning the Authors
 George Komninos is a options architect for the AWS Information Lab. He helps clients convert their concepts to a production-ready knowledge merchandise. Earlier than AWS, he spent three years at Alexa Data as a knowledge engineer. Exterior of labor, George is a soccer fan and helps the best staff on this planet, Olympiacos Piraeus.
George Komninos is a options architect for the AWS Information Lab. He helps clients convert their concepts to a production-ready knowledge merchandise. Earlier than AWS, he spent three years at Alexa Data as a knowledge engineer. Exterior of labor, George is a soccer fan and helps the best staff on this planet, Olympiacos Piraeus.
 Devika Singh is a Senior Options Architect at Amazon Internet Companies. Devika helps clients architect and construct database and knowledge analytics options to speed up their path to manufacturing as a part of the AWS Information Lab. She has experience in database and knowledge warehouse migrations to AWS, serving to clients enhance the worth of their options with AWS.
Devika Singh is a Senior Options Architect at Amazon Internet Companies. Devika helps clients architect and construct database and knowledge analytics options to speed up their path to manufacturing as a part of the AWS Information Lab. She has experience in database and knowledge warehouse migrations to AWS, serving to clients enhance the worth of their options with AWS.
 Simon Dimaline has specialised in knowledge warehousing and knowledge modeling for greater than 20 years. He at present works for the Information & Analytics observe inside AWS Skilled Companies accelerating clients’ adoption of AWS analytics providers.
Simon Dimaline has specialised in knowledge warehousing and knowledge modeling for greater than 20 years. He at present works for the Information & Analytics observe inside AWS Skilled Companies accelerating clients’ adoption of AWS analytics providers.
[ad_2]