
{kind=link}
[ad_1]
Hello!
I’m Dan! I feel the web optimization self-discipline is a analysis primarily based self-discipline. One among my favourite ideas is Rubbish In, Rubbish Out (GIGO), which I’m going to hyperlink to slightly then clarify however I nonetheless count on you to learn it! Since unhealthy information begets unhealthy analysis begets unhealthy ways begets unhealthy outcomes, I feel it’s necessary to have intellectually sincere and legitimate analysis.
If solely our trade was open to look overview. For these all in favour of peer reviewing different analysis, this took me ~60 min all in.
At present I’m going to look overview this research put out by Ryan Jones and Sapient Nitro on Twitter and supply up some counter, contradictory and higher analysis.
Background
Right here is the research I’m going to overview. I’m simply going to be upfront, it’s problematic analysis. Right here’s why:
- It didn’t interact in fundamental information processing (e.g. eradicating cease phrases and different widespread phrases). Which means the most typical items of speech are going to floor within the analysis, however not insights from key phrase decisions. Whereas there have been later claims that the cease phrases have been the purpose, I actually don’t perceive why that will ever be the case. With out extra effort by the authors right here I don’t suppose it is a good justification. For theme classification, cease phrases are ineffective (this contains issues like intent, which is itself a theme classification). Anyway, right here at LSG we use the NLTK library to pre-process our information. Eradicating cease and different widespread phrases is a fundamental use-case of that library. With out correctly processing and cleansing the information not one of the insights are useful. Keep in mind, GIGO.
- The info set. BrightEdge doesn’t have an excellent information set they usually aren’t very clear about how they get it. If you’re going to analyze a key phrase set that’s going to be at greatest consultant (150k key phrases is nothing within the key phrase corpus of all Search) then it’s essential be sure it’s as correct a illustration of the true information as doable. If BrightEdge has a much less consultant key phrase corpus than say AHREFs then that will imply once more the insights can’t be trusted. Once more, GIGO.
Fortunately right here at LSG, we all know the way to take away issues like cease phrases, and different widespread elements of writing, when processing giant quantities of information. I used to be in a position to get what I feel is a greater key phrase set to make use of within the analysis. And as you will note once I stroll you thru this and also you see the output, it’s simply way more useable.
The Analysis
I obtained the highest 100k key phrases by quantity from AHREFs because of the superb Patrick Stox after seeing this tweet from AHREFs CMO and being intrigued:
Fast web optimization Tip:
An empty search in @ahrefs Key phrases Explorer offers you entry to our ENTIRE ~4 billion US key phrase database (trade’s largest btw 💪)!
Then use S. quantity, KD & Phrase rely filters to search out “hi-vol, low-comp” queries.
Good for locating new alternatives! 🔥 pic.twitter.com/BGfrlxQ45s
— Tim Soulo (@timsoulo) August 4, 2021
The Course of:
I took the checklist of high 100,000 key phrases by quantity and processed the ngrams like so:
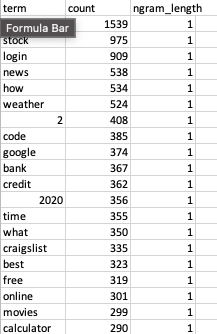
Then I took the outcomes (which appear to be this)
and ran them by means of the phrase cloud creator on wordart.com. That is my favourite phrase cloud creator as a result of it simply does an important fast information course of. You possibly can take away widespread phrases, interact in stemming to roll up shut variations, and play with the visible design. 10/10, extremely suggest.
And for people who wish to argue 100,000 key phrases vs. 150,000 key phrases; this desk will hopefully present you that it’s not tremendous related when it comes to whose drop of water is greater:

The Outcomes
There’s actual information to be gathered when you take away widespread phrases like “for” from the evaluation. Test it out!

Spoiler – while you carry out correct information evaluation on information, you’ll be able to floor some actual insights! The obvious one is that #1 gram, “close to”.
I’ve been saying all search is native seek for some time. AJ Kohn has been saying it for some time. It’s because it’s the truth of the scenario. Localization of search outcomes is the #1 pattern that SEOs are lacking. Primarily as a result of native search has at all times been regarded down as this bizarre factor that SMBs do. Their loss is our acquire I suppose 🙂
One other actually attention-grabbing factor is “vs”. Comparability queries are extremely popular, and you ought to be leveraging them in your content material in the event that they make sense. The folks successful in search already are!
Moreover there are another insights from this that I might name fundamental, however good validation. Navigational queries are very excessive, folks like free stuff and stonks, and so forth.
Anyway, right here is the ngram information from the analysis for individuals who are all in favour of analyzing it themselves. Please be happy to publish observe up analysis, simply be sure to offer us that hyperlink. I’m not going to share the highest 100k AHREFs information as you all know the place to go if you wish to purchase it 🙂
[ad_2]