

{kind=link}
[ad_1]
Microsoft SharePoint is a doc administration system for storing information, organizing paperwork, and sharing and enhancing paperwork in collaboration with others. Your group could need to ingest SharePoint knowledge into your knowledge lake, mix the SharePoint knowledge with different knowledge that’s out there within the knowledge lake, and use it for reporting and analytics functions. AWS Glue is a serverless knowledge integration service that makes it straightforward to find, put together, and mix knowledge for analytics, machine studying, and utility growth. AWS Glue offers all of the capabilities wanted for knowledge integration in an effort to begin analyzing your knowledge and placing it to make use of in minutes as an alternative of months.
Organizations typically handle their knowledge on SharePoint within the type of information and lists, and you need to use this knowledge for simpler discovery, higher auditing, and compliance. SharePoint as a knowledge supply will not be a typical relational database and the information is usually semi structured, which is why it’s typically tough to hitch the SharePoint knowledge with different relational knowledge sources. This put up exhibits how one can ingest and course of SharePoint lists and information with AWS Glue and Amazon EventBridge, which lets you be part of different knowledge that’s out there in your knowledge lake. We use SharePoint REST APIs with a normal open knowledge protocol (OData) syntax. OData advocates a normal approach of implementing REST APIs that enables for SQL-like querying capabilities. OData helps you concentrate on your small business logic whereas constructing RESTful APIs with out having to fret concerning the numerous approaches to outline request and response headers, question choices, and so forth.
AWS Glue event-driven workflows
In contrast to a conventional relational database, SharePoint knowledge could or could not change continuously, and it’s tough to foretell the frequency at which your SharePoint server generates new knowledge, which makes it tough to plan and schedule knowledge processing pipelines effectively. Working knowledge processing continuously will be costly, whereas scheduling pipelines to run occasionally can ship chilly knowledge. Equally, triggering pipelines from an exterior course of can enhance complexity, value, and job startup time.
AWS Glue helps event-driven workflows, a functionality that lets builders begin AWS Glue workflows based mostly on occasions delivered by EventBridge. The primary cause to decide on EventBridge on this structure is as a result of it permits you to course of occasions, replace the goal tables, and make info out there to eat in near-real time. As a result of frequency of information change in SharePoint is unpredictable, utilizing EventBridge to seize occasions as they arrive lets you run the information processing pipeline solely when new knowledge is offered.
To get began, you merely create a brand new AWS Glue set off of kind EVENT and place it as the primary set off in your workflow. You possibly can optionally specify a batching situation. With out occasion batching, the AWS Glue workflow is triggered each time an EventBridge rule matches, which can lead to a number of concurrent workflows working. AWS Glue protects you by setting default limits that limit the variety of concurrent runs of a workflow. You possibly can enhance the required limits by opening a assist case. Occasion batching permits you to configure the variety of occasions to buffer or the utmost elapsed time earlier than firing the actual set off. When the batching situation is met, a workflow run is began. For instance, you’ll be able to set off your workflow when 100 information are uploaded in Amazon Easy Storage Service (Amazon S3) or 5 minutes after the primary add. We advocate configuring occasion batching to keep away from too many concurrent workflows, and optimize useful resource utilization and price.
For instance this resolution higher, think about the next use case for a wine manufacturing and distribution firm that operates throughout a number of international locations. They at present host all their transactional system’s knowledge on a knowledge lake in Amazon S3. Additionally they use SharePoint lists to seize suggestions and feedback on wine high quality and composition from their suppliers and different stakeholders. The availability chain group needs to hitch their transactional knowledge with the wine high quality feedback in SharePoint knowledge to enhance their wine high quality and handle their manufacturing points higher. They need to seize these feedback from the SharePoint server inside an hour and publish that knowledge to a wine high quality dashboard in Amazon QuickSight. With an event-driven method to ingest and course of their SharePoint knowledge, the provision chain group can eat the information in lower than an hour.
Overview of resolution
On this put up, we stroll by an answer to arrange an AWS Glue job to ingest SharePoint lists and information into an S3 bucket and an AWS Glue workflow that listens to S3 PutObject knowledge occasions captured by AWS CloudTrail. This workflow is configured with an event-based set off to run when an AWS Glue ingest job provides new information into the S3 bucket. The next diagram illustrates the structure.
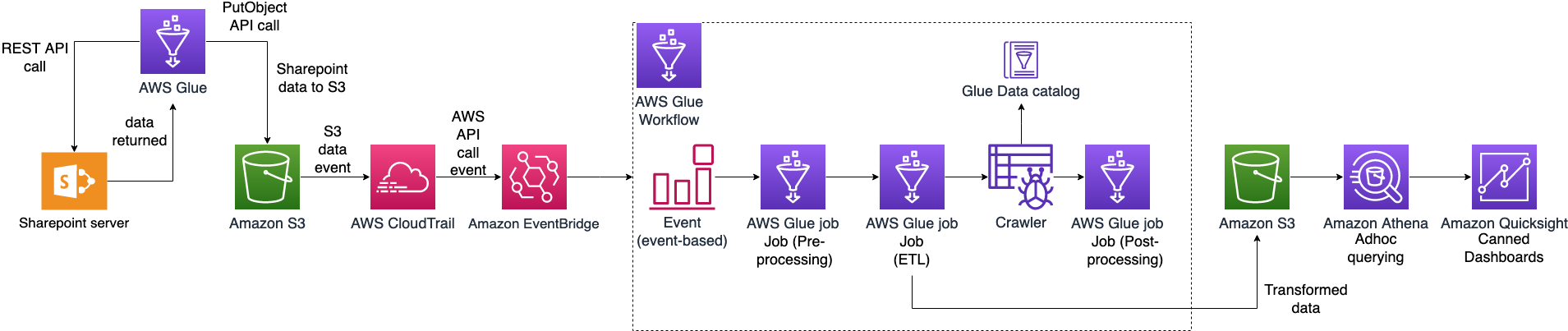
To make it easy to deploy, we captured your complete resolution in an AWS CloudFormation template that lets you robotically ingest SharePoint knowledge into Amazon S3. SharePoint makes use of ClientID and TenantID credentials for authentication and makes use of Oauth2 for authorization.
The template helps you carry out the next steps:
- Create an AWS Glue Python shell job to make the REST API name to the SharePoint server and ingest information or lists into Amazon S3.
- Create an AWS Glue workflow with a beginning set off of EVENT kind.
- Configure CloudTrail to log knowledge occasions, akin to PutObject API calls to CloudTrail.
- Create a rule in EventBridge to ahead the PutObject API occasions to AWS Glue once they’re emitted by CloudTrail.
- Add an AWS Glue event-driven workflow as a goal to the EventBridge rule. The workflow will get triggered when the SharePoint ingest AWS Glue job provides new information to the S3 bucket.
Stipulations
For this walkthrough, it is best to have the next conditions:
Configure SharePoint server authentication particulars
Earlier than launching the CloudFormation stack, you must arrange your SharePoint server authentication particulars, particularly, TenantID, Tenant, ClientID, ClientSecret, and the SharePoint URL in AWS Programs Supervisor Parameter Retailer of the account you’re deploying in. This makes positive that no authentication particulars are saved within the code they usually’re fetched in actual time from Parameter Retailer when the answer is working.
To create your AWS Programs Supervisor parameters, full the next steps:
- On the Programs Supervisor console, underneath Software Administration within the navigation pane, select Parameter Retailer.

- Select Create Parameter.
- For Title, enter the parameter title
/DATALAKE/GlueIngest/SharePoint/tenant. - Go away the sort as string.
- Enter your SharePoint tenant element into the worth subject.
- Select Create parameter.
- Repeat these steps to create the next parameters:
/DataLake/GlueIngest/SharePoint/tenant/DataLake/GlueIngest/SharePoint/tenant_id/DataLake/GlueIngest/SharePoint/client_id/checklist/DataLake/GlueIngest/SharePoint/client_secret/checklist/DataLake/GlueIngest/SharePoint/client_id/file/DataLake/GlueIngest/SharePoint/client_secret/file/DataLake/GlueIngest/SharePoint/url/checklist/DataLake/GlueIngest/SharePoint/url/file
Deploy the answer with AWS CloudFormation
For a fast begin of this resolution, you’ll be able to deploy the supplied CloudFormation stack. This creates all of the required sources in your account.
The CloudFormation template generates the next sources:
- S3 bucket – Shops knowledge, CloudTrail logs, job scripts, and any short-term information generated throughout the AWS Glue extract, remodel, and cargo (ETL) job run.
- CloudTrail path with S3 knowledge occasions enabled – Allows EventBridge to obtain
PutObjectAPI name knowledge in a selected bucket. - AWS Glue Job – A Python shell job that fetches the information from the SharePoint server.
- AWS Glue workflow – A knowledge processing pipeline that’s comprised of a crawler, jobs, and triggers. This workflow converts uploaded knowledge information into Apache Parquet format.
- AWS Glue database – The AWS Glue Information Catalog database that holds the tables created on this walkthrough.
- AWS Glue desk – The Information Catalog desk representing the Parquet information being transformed by the workflow.
- AWS Lambda perform – The AWS Lambda perform is used as an AWS CloudFormation customized useful resource to repeat job scripts from an AWS Glue-managed GitHub repository and an AWS Large Information weblog S3 bucket to your S3 bucket.
- IAM roles and insurance policies – We use the next AWS Id and Entry Administration (IAM) roles:
- LambdaExecutionRole – Runs the Lambda perform that has permission to add the job scripts to the S3 bucket.
- GlueServiceRole – Runs the AWS Glue job that has permission to obtain the script, learn knowledge from the supply, and write knowledge to the vacation spot after conversion.
- EventBridgeGlueExecutionRole – Has permissions to invoke the
NotifyEventAPI for an AWS Glue workflow. - IngestGlueRole – Runs the AWS Glue job that has permission to ingest knowledge into the S3 bucket.
To launch the CloudFormation stack, full the next steps:
- Sign up to the AWS CloudFormation console.
- Select Launch Stack:

- Select Subsequent.
- For pS3BucketName, enter the distinctive title of your new S3 bucket.
- Go away pWorkflowName and pDatabaseName because the default.
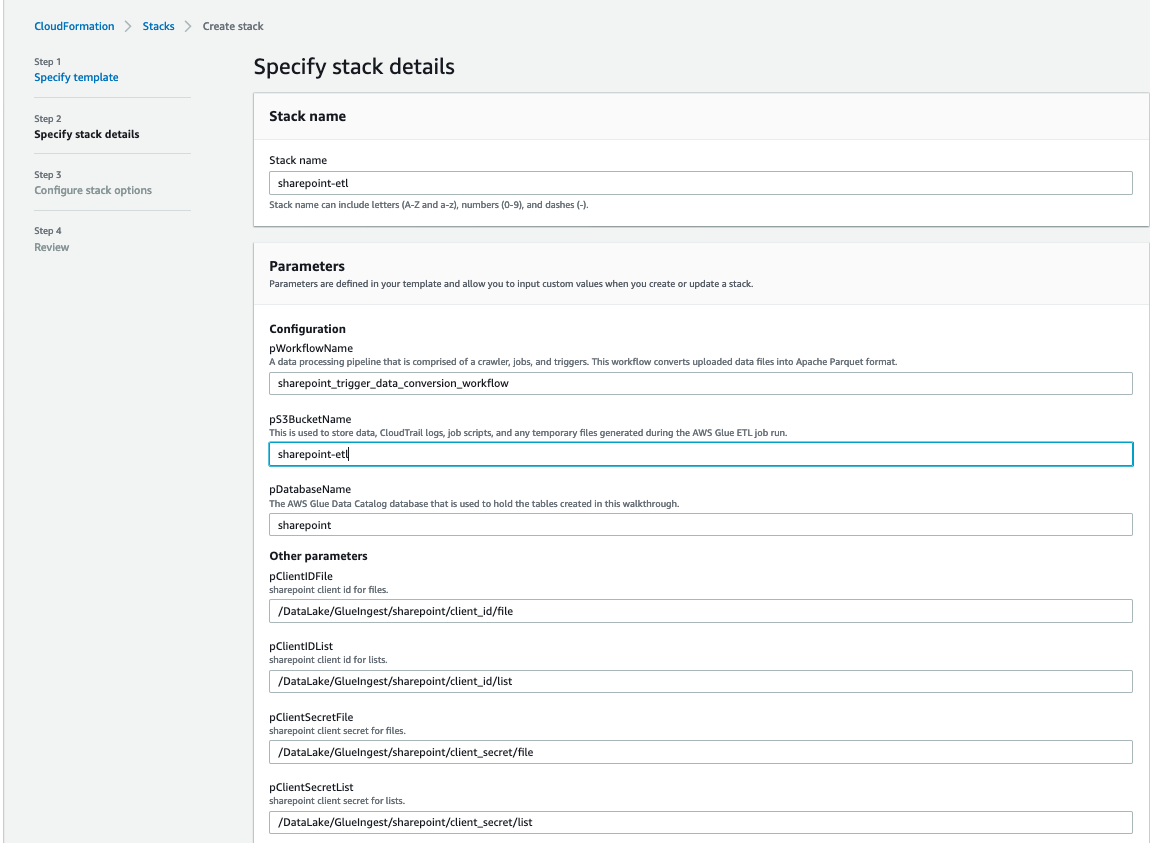
- For pDatasetName, enter the SharePoint checklist title or file title you need to ingest.
- Select Subsequent.
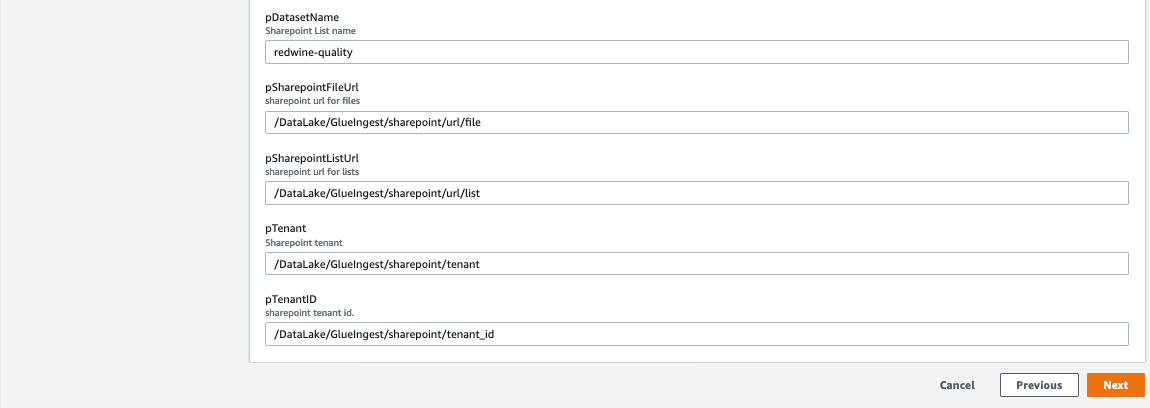
- On the following web page, select Subsequent.
- Evaluation the main points on the ultimate web page and choose I acknowledge that AWS CloudFormation would possibly create IAM sources.
- Select Create.
It takes a couple of minutes for the stack creation to finish; you’ll be able to comply with the progress on the Occasions tab.
You possibly can run the ingest AWS Glue job both on a schedule or on demand. Because the job efficiently finishes and ingests knowledge into the uncooked prefix of the S3 bucket, the AWS Glue workflow runs and transforms the ingested uncooked CSV information into Parquet information and hundreds them into the remodeled prefix.
Evaluation the EventBridge rule
The CloudFormation template created an EventBridge rule to ahead S3 PutObject API occasions to AWS Glue. Let’s evaluation the configuration of the EventBridge rule:
- On the EventBridge console, underneath Occasions, select Guidelines.
- Select the rule
s3_file_upload_trigger_rule-<CloudFormation-stack-name>. - Evaluation the data within the Occasion sample part.
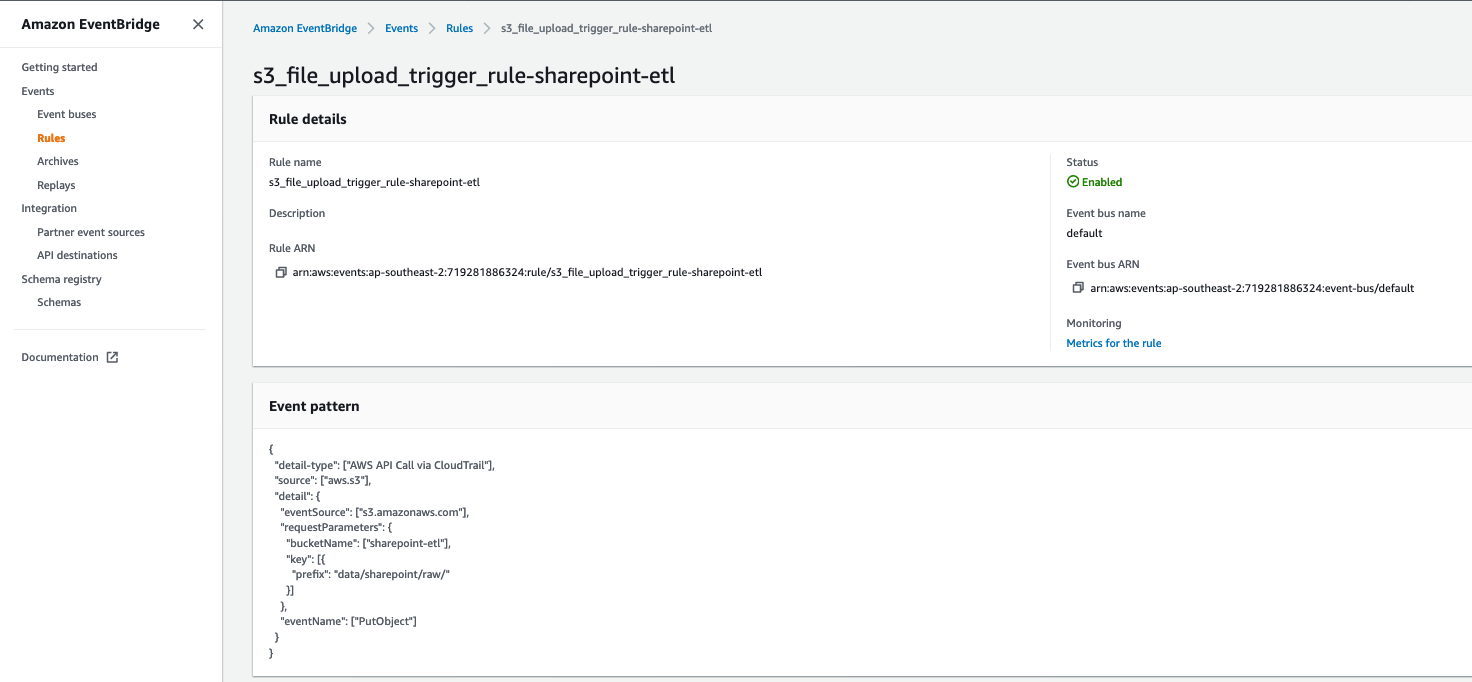
The occasion sample exhibits that this rule is triggered when an S3 object is uploaded to s3://<bucket_name>/knowledge/SharePoint/tablename_raw/. CloudTrail captures the PutObject API calls made and relays them as occasions to EventBridge.
- Within the Targets part, you’ll be able to confirm that this EventBridge rule is configured with an AWS Glue workflow as a goal.

Run the ingest AWS Glue job and confirm the AWS Glue workflow is triggered efficiently
To check the workflow, we run the ingest-glue-job-SharePoint-file job utilizing the next steps:
- On the AWS Glue console, choose the
ingest-glue-job-SharePoint-filejob.

- On the Motion menu, select Run job.
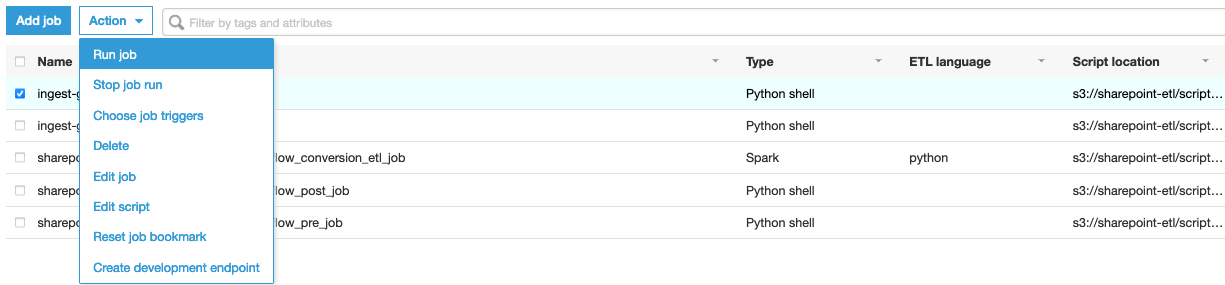
- Select the Historical past tab and wait till the job succeeds.
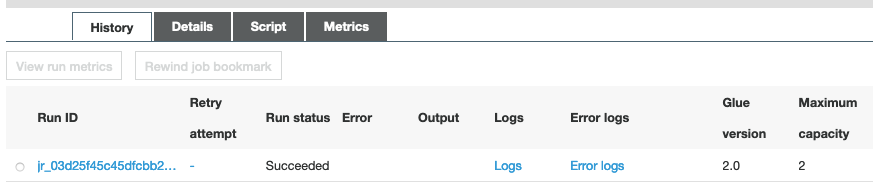
Now you can see the CSV information within the uncooked prefix of your S3 bucket.
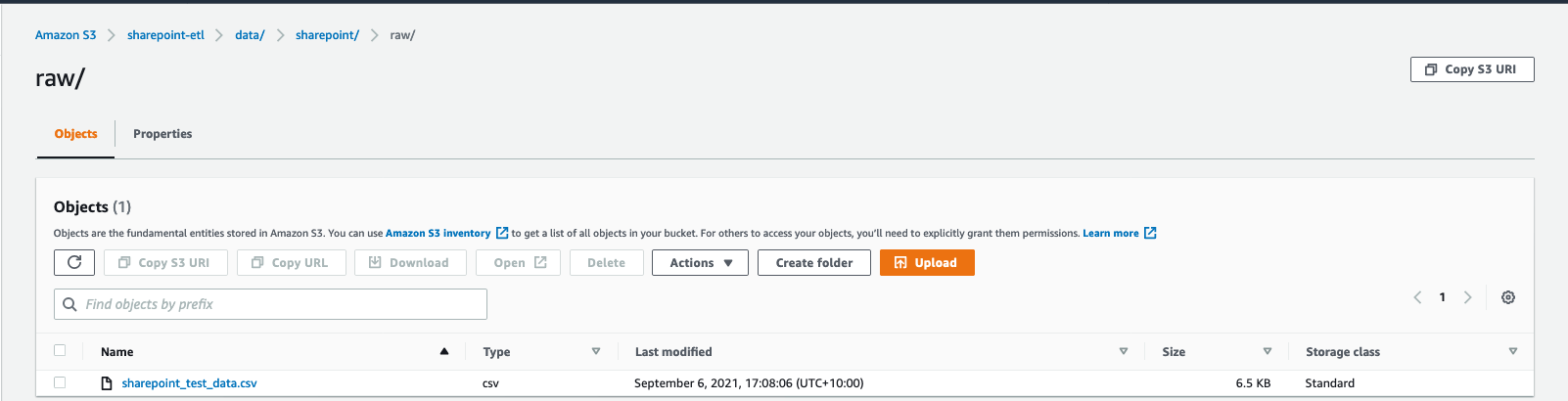
Now the workflow needs to be triggered.
- On the AWS Glue console, validate that your workflow is within the
RUNNINGstate.

- Select the workflow to view the run particulars.
- On the Historical past tab of the workflow, select the present or most up-to-date workflow run.
- Select View run particulars.

When the workflow run standing adjustments to Accomplished, let’s examine the transformed information in your S3 bucket.
- Swap to the Amazon S3 console, and navigate to your bucket.
You possibly can see the Parquet information underneath s3://<bucket_name>/knowledge/SharePoint/tablename_transformed/.
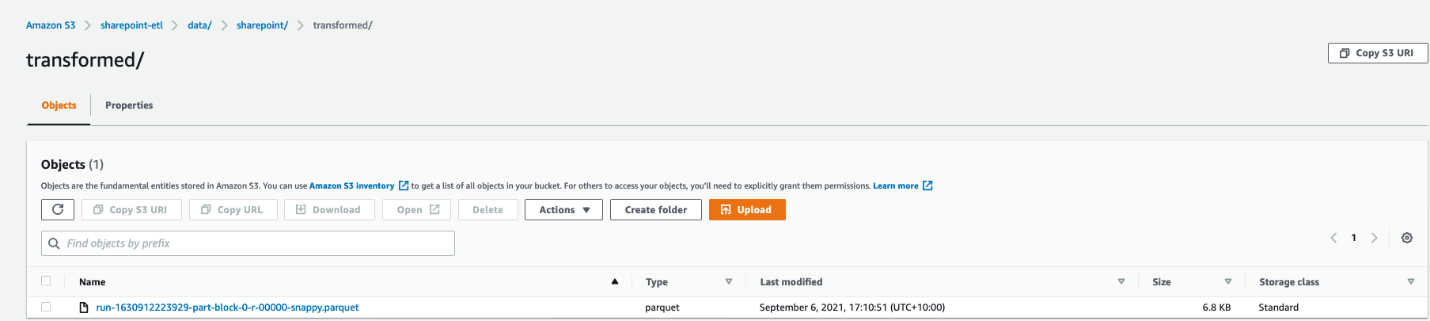
Congratulations! Your workflow ran efficiently based mostly on S3 occasions triggered by importing information to your bucket. You possibly can confirm every part works as anticipated by working a question in opposition to the generated desk utilizing Amazon Athena.
Pattern wine dataset
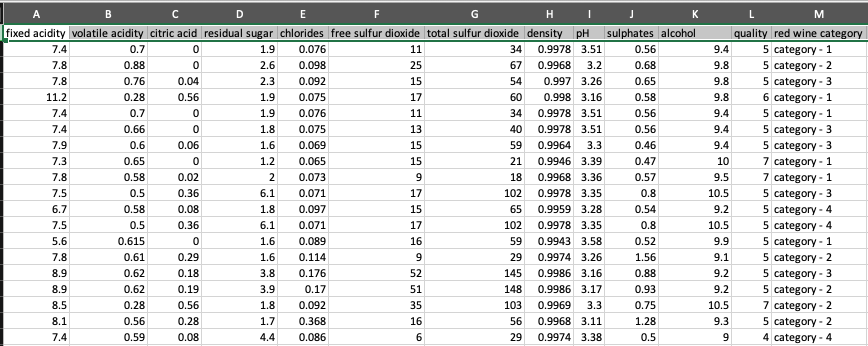
Let’s analyze a pattern purple wine dataset. The next screenshot exhibits a SharePoint checklist that accommodates numerous readings that relate to the traits of the wine and an related wine class. That is populated by numerous wine tasters from a number of international locations.
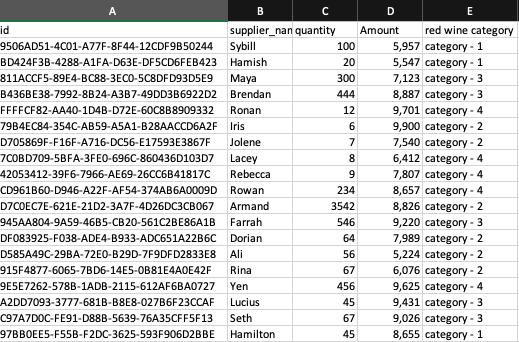
The next screenshot exhibits a provider dataset from the information lake with wine classes ordered per provider.
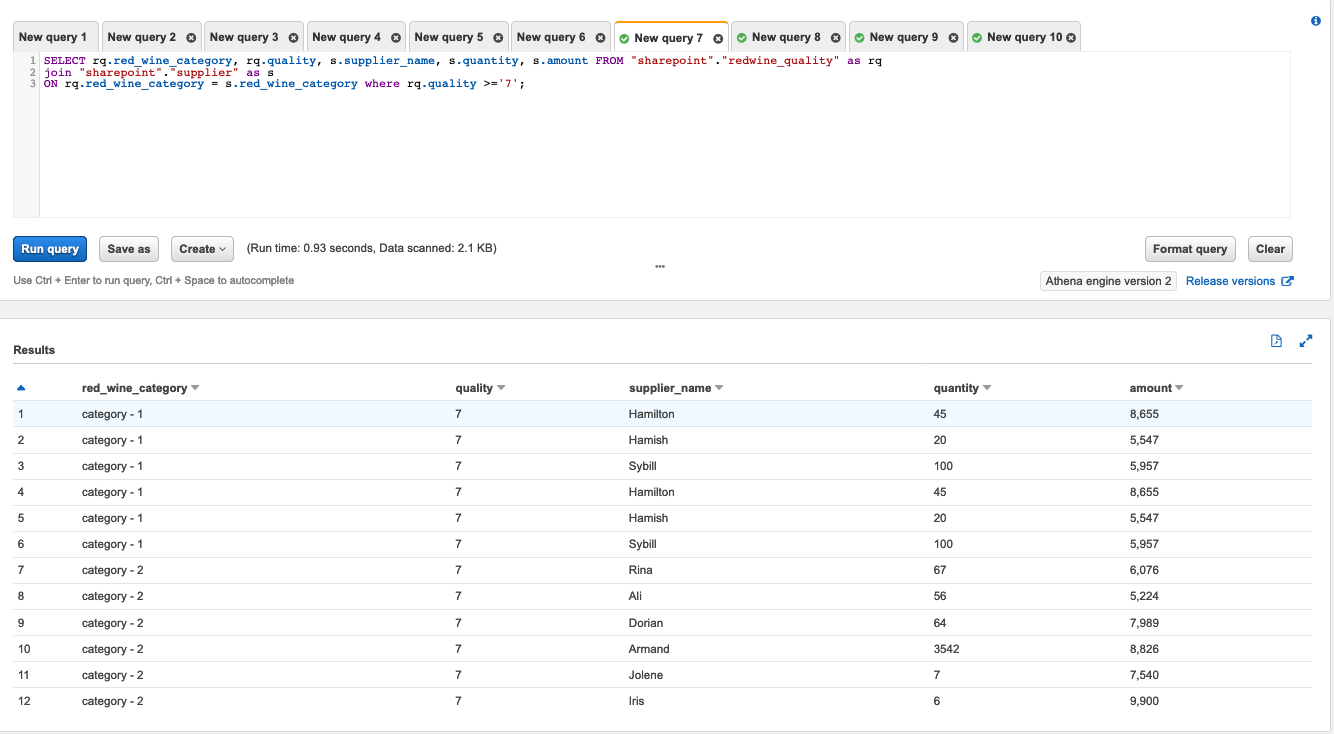
We course of the purple wine dataset utilizing this resolution and use Athena to question the purple wine knowledge and provider knowledge the place wine high quality is bigger than or equal to 7.
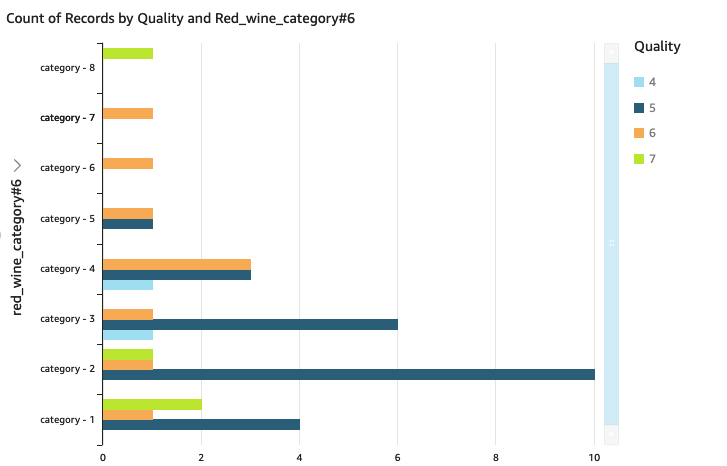
We will visualize the processed dataset utilizing QuickSight.
Clear up
To keep away from incurring pointless expenses, you need to use the AWS CloudFormation console to delete the stack that you just deployed. This removes all of the sources you created when deploying the answer.
Conclusion
Occasion-driven architectures present entry to near-real-time info and aid you make enterprise selections on recent knowledge. On this put up, we demonstrated how one can ingest and course of SharePoint knowledge utilizing AWS serverless companies like AWS Glue and EventBridge. We noticed how one can configure a rule in EventBridge to ahead occasions to AWS Glue. You should use this sample to your analytical use instances, akin to becoming a member of SharePoint knowledge with different knowledge in your lake to generate insights, or auditing SharePoint knowledge and compliance necessities.
In regards to the Creator
 Venkata Sistla is a Large Information & Analytics Guide on the AWS Skilled Providers group. He makes a speciality of constructing knowledge processing capabilities and serving to prospects take away constraints that stop them from leveraging their knowledge to develop enterprise insights.
Venkata Sistla is a Large Information & Analytics Guide on the AWS Skilled Providers group. He makes a speciality of constructing knowledge processing capabilities and serving to prospects take away constraints that stop them from leveraging their knowledge to develop enterprise insights.
[ad_2]