
{kind=link}
[ad_1]
Amazon Redshift is a totally managed cloud knowledge warehouse that makes it easy and cost-effective to research all of your knowledge utilizing SQL and your extract, rework, and cargo (ETL), enterprise intelligence (BI), and reporting instruments. Tens of hundreds of consumers use Amazon Redshift to course of exabytes of information per day and energy analytics workloads.
Etleap is an AWS Superior Know-how Accomplice with the AWS Information & Analytics Competency and Amazon Redshift Service Prepared designation. Etleap ETL removes the complications skilled constructing knowledge pipelines. A cloud-native platform that seamlessly integrates with AWS infrastructure, Etleap ETL consolidates knowledge with out the necessity for coding. Automated situation detection pinpoints issues so knowledge groups can keep centered on enterprise initiatives, not knowledge pipelines.
On this publish, we present how Etleap clients are integrating with the brand new streaming ingestion function in Amazon Redshift (presently in restricted preview) to load knowledge instantly from Amazon Kinesis Information Streams. This reduces load occasions from minutes to seconds and helps you achieve sooner knowledge insights.
Amazon Redshift streaming ingestion with Kinesis Information Streams
Historically, you had to make use of Amazon Kinesis Information Firehose to land your stream into Amazon Easy Storage Service (Amazon S3) information after which make use of a COPY command to maneuver the information into Amazon Redshift. This technique incurs latencies within the order of minutes.
Now, the native streaming ingestion function in Amazon Redshift enables you to ingest knowledge instantly from Kinesis Information Streams. The brand new function allows you to ingest a whole bunch of megabytes of information per second and question it at exceptionally low latency—in lots of instances solely 10 seconds after coming into the information stream.
Configure Amazon Redshift streaming ingestion with SQL queries
Amazon Redshift streaming ingestion makes use of SQL to attach with a number of Kinesis knowledge streams concurrently. On this part, we stroll by the steps to configure streaming ingestion.
Create an exterior schema
We start by creating an exterior schema referencing Kinesis utilizing syntax tailored from Redshift’s help for Federated Queries:
This exterior schema command creates an object inside Amazon Redshift that acts as a proxy to Kinesis Information Streams. Particularly, to the gathering of information streams which might be accessible by way of the AWS Identification and Entry Administration (IAM) position. You need to use both the default Amazon Redshift cluster IAM position or a specified IAM position that has been connected to the cluster beforehand.
Create a materialized view
You need to use Amazon Redshift materialized views to materialize a point-in-time view of a Kinesis knowledge stream, as amassed as much as the time it’s queried. The next command creates a materialized view over a stream from the beforehand outlined schema:
Be aware using the dot syntax to select the actual stream desired. The attributes of the stream embrace a timestamp area, partition key, sequence quantity, and a VARBYTE knowledge payload.
Though the earlier materialized view definition merely performs a SELECT *, extra subtle processing is feasible, for example, making use of filtering circumstances or shredding JSON knowledge into columns. To display, think about the next Kinesis knowledge stream with JSON payloads:
To display this, write a materialized view that shreds the JSON into columns, focusing solely on the entered store motion:
On the Amazon Redshift chief node, the view definition is parsed and analyzed. On success, it’s added to the system catalogs. No additional communication with Kinesis Information Streams happens till the preliminary refresh.
Refresh the materialized view
The next command pulls knowledge from Kinesis Information Streams into Amazon Redshift:
You may provoke it manually (by way of the SQL previous command) or routinely by way of a scheduled question. In both case, it makes use of the IAM position related to the stream. Every refresh is incremental and massively parallel, storing its progress in every Kinesis shard within the system catalogs in order to be prepared for the following spherical of refresh.
With this course of, now you can question near-real-time knowledge out of your Kinesis knowledge stream by Amazon Redshift.
Use Amazon Redshift streaming ingestion with Etleap
Etleap pulls knowledge from databases, purposes, file shops, and occasion streams, and transforms it earlier than loading it into an AWS knowledge repository. Information ingestion pipelines usually course of batches each 5–60 minutes, so whenever you question your knowledge in Amazon Redshift, it’s at the very least 5 minutes outdated. For a lot of use instances, resembling advert hoc queries and BI reporting, this latency time is suitable.
However what about when your crew calls for extra up-to-date knowledge? An instance is operational dashboards, the place it’s essential to monitor KPIs in near-real time. Amazon Redshift load occasions are bottlenecked by COPY instructions that transfer knowledge from Amazon S3 into Amazon Redshift, as talked about earlier.
That is the place streaming ingestion is available in: by staging the information in Kinesis Information Streams reasonably than Amazon S3, Etleap can cut back knowledge latency in Amazon Redshift to lower than 10 seconds. To preview this function, we ingest knowledge from SQL databases resembling MySQL and Postgres that help change knowledge seize (CDC). The info move is proven within the following diagram.
 to make knowledge accessible in seconds")
Etleap manages the end-to-end knowledge move by AWS Database Migration Service (AWS DMS) and Kinesis Information Streams, and creates and schedules Amazon Redshift queries, offering up-to-date knowledge.
AWS DMS consumes the replication logs from the supply, and produces insert, replace, and delete occasions. These occasions are written to a Kinesis knowledge stream that has a number of shards to be able to deal with the occasion load. Etleap transforms these occasions in response to user-specified guidelines, and writes them to a different knowledge stream. Lastly, a sequence of Amazon Redshift instructions load knowledge from the stream right into a vacation spot desk. This process takes lower than 10 seconds in real-world situations.
Beforehand, we explored how knowledge in Kinesis Information Streams might be accessed in Amazon Redshift utilizing SQL queries. On this part, we see how Etleap makes use of the streaming ingestion function to reflect a desk from MySQL into Amazon Redshift, and the end-to-end latency we will obtain.
Etleap clients which might be a part of the Streaming Ingestion Preview Program can ingest knowledge into Amazon Redshift instantly from an Etleap-managed Kinesis knowledge stream. All pipelines from a CDC-enabled supply routinely use this function.

The vacation spot desk in Amazon Redshift is Kind 1, a mirror of the desk within the supply database.
For instance, say you need to mirror a MySQL desk in Amazon Redshift. The desk represents the web buying carts that customers have open. On this case, low latency is vital in order that the platform advertising and marketing strategists can immediately establish deserted carts and excessive demand gadgets.
The cart desk has the next construction:
Adjustments from the supply desk are captured utilizing AWS DMS after which despatched to Etleap by way of a Kinesis knowledge stream. Etleap transforms these information and writes them to a different knowledge stream utilizing the next construction:
The construction encodes the row that was modified or inserted, in addition to the operation sort (represented by the op column), which may have three values: I (insert), U (replace) or D (delete).
This info is then materialized in Amazon Redshift from the information stream:
Within the materialized view, we expose the next columns:
PartitionKeyrepresents an Etleap sequence quantity, to make sure that updates are processed within the appropriate order.- We shred the first keys of the desk (
idwithin the previous instance) from the payload, utilizing them as a distribution key to enhance the replace efficiency. - The
Informationcolumn is parsed out right into a SUPER sort from the JSON object within the stream. That is shredded into the corresponding columns within the cart desk when the information is inserted.
With this staging materialized view, Etleap then updates the vacation spot desk (cart) that has the next schema:
To replace the desk, Etleap runs the next queries, choosing solely the modified rows from the staging materialized view, and applies them to the cart desk:
We run the next sequence of queries:
- Refresh the
cart_stagingmaterialized view to get new information from thecartstream. - Delete all information from the
cartdesk that have been up to date or deleted because the final time we ran the replace sequence. - Insert all of the up to date and newly inserted information from the
cart_stagingmaterialized view into thecartdesk. - Replace the
_etleap_sibookkeeping desk with the present place. Etleap makes use of this desk to optimize the question within the staging materialized view.
This replace sequence runs constantly to attenuate end-to-end latency. To measure efficiency, we simulated the change stream from a database desk that has as much as 100,000 inserts, updates, and deletes. We examined goal desk sizes of as much as 1.28 billion rows. Testing was carried out on a 2-node ra3.xlplus Amazon Redshift cluster and a Kinesis knowledge stream with 32 shards.
The next determine reveals how lengthy the replace sequence takes on common over 5 runs in numerous situations. Even within the busiest state of affairs (100,000 adjustments to a 1.28 billion row desk), the sequence takes simply over 10 seconds to run. In our experiment, the refresh time was impartial of the delta dimension, and took 3.7 seconds with a typical deviation of 0.4 seconds.
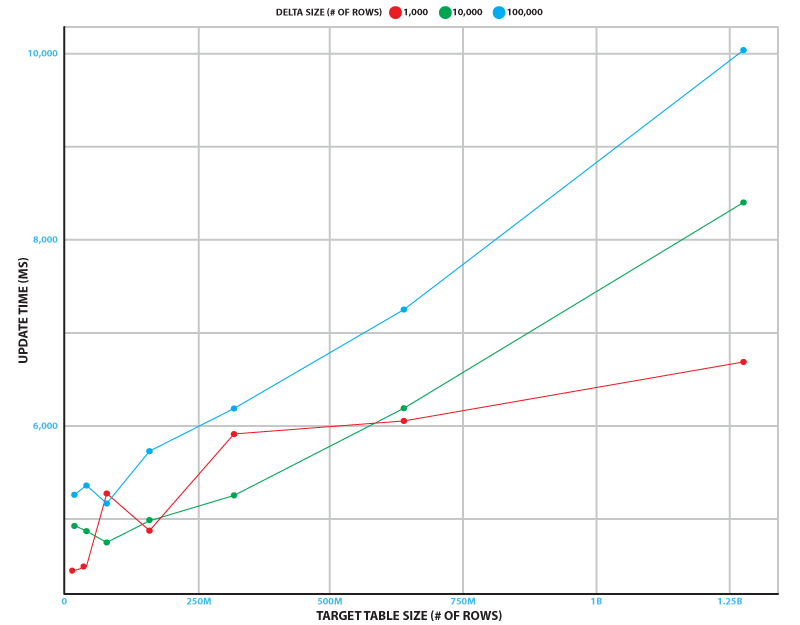
This reveals that the replace course of can sustain with supply database tables which have 1 billion rows and 10,000 inserts, updates, and deletes per second.
Abstract
On this publish, you discovered in regards to the native streaming ingestion function in Amazon Redshift and the way it achieves latency in seconds, whereas ingesting knowledge from Kinesis Information Streams into Amazon Redshift. You additionally discovered in regards to the structure of Amazon Redshift with the streaming ingestion function enabled, the way to configure it utilizing SQL instructions, and use the potential in Etleap.
To be taught extra about Etleap, check out the Etleap ETL on AWS Fast Begin, or go to their itemizing on AWS Market.
Concerning the Authors
 Caius Brindescu is an engineer at Etleap with over 3 years of expertise in creating ETL software program. Along with improvement work, he helps clients take advantage of out of Etleap and Amazon Redshift. He holds a PhD from Oregon State College and one AWS certification (Large Information – Specialty).
Caius Brindescu is an engineer at Etleap with over 3 years of expertise in creating ETL software program. Along with improvement work, he helps clients take advantage of out of Etleap and Amazon Redshift. He holds a PhD from Oregon State College and one AWS certification (Large Information – Specialty).
 Todd J. Inexperienced is a Principal Engineer with AWS Redshift. Earlier than becoming a member of Amazon, TJ labored at progressive database startups together with LogicBlox and RelationalAI, and was an Assistant Professor of Laptop Science at UC Davis. He acquired his PhD in Laptop Science from UPenn. In his profession as a researcher, TJ gained a lot of awards, together with the 2017 ACM PODS Check-of-Time Award.
Todd J. Inexperienced is a Principal Engineer with AWS Redshift. Earlier than becoming a member of Amazon, TJ labored at progressive database startups together with LogicBlox and RelationalAI, and was an Assistant Professor of Laptop Science at UC Davis. He acquired his PhD in Laptop Science from UPenn. In his profession as a researcher, TJ gained a lot of awards, together with the 2017 ACM PODS Check-of-Time Award.
 Maneesh Sharma is a Senior Database Engineer with Amazon Redshift. He works and collaborates with varied Amazon Redshift Companions to drive higher integration. In his spare time, he likes operating, enjoying ping pong, and exploring new journey locations.
Maneesh Sharma is a Senior Database Engineer with Amazon Redshift. He works and collaborates with varied Amazon Redshift Companions to drive higher integration. In his spare time, he likes operating, enjoying ping pong, and exploring new journey locations.
 Jobin George is a Large Information Options Architect with greater than a decade of expertise designing and implementing large-scale large knowledge and analytics options. He offers technical steerage, design recommendation, and thought management to a few of the key AWS clients and massive knowledge companions.
Jobin George is a Large Information Options Architect with greater than a decade of expertise designing and implementing large-scale large knowledge and analytics options. He offers technical steerage, design recommendation, and thought management to a few of the key AWS clients and massive knowledge companions.
[ad_2]