
: Run massive knowledge purposes with out managing servers")
{kind=link}
[ad_1]
As we speak we’re blissful to announce Amazon EMR Serverless, a brand new possibility in Amazon EMR that makes it simple and cost-effective for knowledge engineers and analysts to run petabyte-scale knowledge analytics within the cloud. With EMR Serverless, you may run purposes constructed utilizing open-source frameworks akin to Apache Spark, Hive, and Presto, with out having to configure, handle, optimize, or safe clusters. EMR Serverless routinely provisions and scales the compute and reminiscence assets required by your purposes, and also you solely pay for the assets that your purposes use.
On this submit, we talk about the advantages of EMR Serverless, stroll you thru the core ideas of EMR Serverless and the way you should use it, and present you a fast demo.
Overview of EMR Serverless
Tens of hundreds of consumers use Amazon EMR, a managed service for working open-source analytics frameworks akin to Apache Spark, Hive, and Presto, for large-scale knowledge analytics purposes. With Amazon EMR, you may provision clusters of any dimension in minutes. Amazon EMR routinely installs and configures the frameworks you select, and offers a performance-optimized runtime that’s appropriate with and over twice as quick as customary open-source.
Amazon EMR clients have full management over cluster configuration. The flexibility to customise clusters lets you optimize for price and efficiency primarily based on workload necessities. For instance, you should use Amazon Elastic Compute Cloud (Amazon EC2) reminiscence optimized cases to run SQL workloads with low latency, or use the EC2 Graviton2-based cases to enhance efficiency. You may also use EC2 Spot Situations, that are built-in in Amazon EMR so as to benefit from unused EC2 capability within the AWS Cloud to acquire cases at as much as a 90% low cost in comparison with On-Demand costs. In case you run your purposes on Kubernetes, you should use Amazon EMR on Amazon EKS to run your Amazon EMR analytics purposes on Amazon Elastic Kubernetes Service (Amazon EKS) clusters.
Nonetheless, tuning clusters for optimum price and efficiency requires engineers to have deep information of the underlying analytics frameworks. Moreover, the particular compute and reminiscence assets wanted to optimally run purposes depend upon numerous components, such because the schedule and complexity of knowledge processing jobs and the amount of knowledge being processed. When these traits change over time, it’s essential reevaluate and reconfigure clusters. As well as, directors must safe and monitor the clusters to make sure that they’re compliant with company safety insurance policies, and alter safety settings every time the cluster is reconfigured. Many purchasers don’t want this degree of customization and management, and desire a less complicated solution to course of knowledge utilizing open-source frameworks on the Amazon EMR performance-optimized runtime.
With this in thoughts, we constructed EMR Serverless. With EMR Serverless, you will get all the advantages of working Amazon EMR, however with a serverless surroundings. We had the next targets in thoughts once we constructed EMR Serverless:
- Present an easier expertise – EMR Serverless is easy to make use of since you don’t must configure, optimize, function, or safe clusters. You don’t have to fret about occasion varieties or cluster sizes, or about making use of OS patches. You merely specify the framework and model that you just need to use to your software, and submit your knowledge processing jobs. You continue to get all the advantages that you just anticipate out of Amazon EMR—open-source compatibility, open-source model forex, and performance-optimized runtime—however with out the necessity to handle clusters.
- No must guess cluster sizes – EMR Serverless eliminates the necessity to right-size clusters for various jobs and knowledge sizes. With EMR Serverless, you create an software utilizing an open-source framework model, and submit jobs to the applying. EMR Serverless routinely provides and removes employees at completely different phases of processing your job. Because of this, you don’t must reconfigure when knowledge volumes change, and also you solely pay for what your jobs require. You possibly can management prices by specifying the minimal and most variety of concurrent employees, and the VCPU and reminiscence per employee.
- Retain Amazon EMR’s performance-optimized runtime and open-source forex – EMR Serverless contains the Amazon EMR performance-optimized runtime for Apache Spark, Hive, and Presto. The Amazon EMR runtime is API-compatible and over twice as quick as customary open-source, so your jobs run sooner and incur much less compute prices.
- Seamless integration with EMR Studio – EMR Serverless contains EMR Studio, which offers absolutely managed serverless Jupyter Notebooks and acquainted open-source instruments akin to Spark UI and Tez UI that will help you develop, visualize, and debug your purposes.
- Computerized and fine-grained scaling – EMR Serverless routinely scales up employees at every stage of processing your job and scales them down once they’re not required. You’re charged for combination vCPU, reminiscence, and storage assets used from the time a employee begins working till it stops, rounded as much as the closest second with a 1-minute minimal. For instance, your job might require 10 employees for the primary 10 minutes of processing the job, and 50 employees for the subsequent 5 minutes. With fine-grained computerized scaling, you solely incur price for 10 employees for 10 minutes and 50 employees for five minutes. Because of this, you don’t must pay for underutilized assets.
- Resilience to Availability Zone failures – EMR Serverless is a Regional service. Once you submit jobs to an EMR Serverless software, it may possibly run in any Availability Zone within the Area. A job is run in a single Availability Zone to keep away from efficiency implications of community site visitors throughout Availability Zones. In case an Availability Zone is impaired, a job submitted to your EMR Serverless software is routinely run in a unique (wholesome) Availability Zone. When utilizing assets in a non-public VPC, EMR Serverless recommends you specify the personal VPC configuration for a number of Availability Zones in order that EMR Serverless can routinely choose a wholesome Availability Zone.
- Allow shared purposes – Once you submit jobs to an EMR Serverless software, you may specify the AWS Id and Entry Administration (IAM) function that have to be utilized by the job to entry AWS assets akin to Amazon Easy Storage Service (Amazon S3) objects. Because of this, completely different IAM principals can run jobs on a single EMR Serverless software, and every job can solely entry the AWS assets that the IAM principal is allowed to entry. This allows you to arrange eventualities the place a single software with a pre-initialized pool of employees is made out there to a number of tenants whereby every tenant can submit jobs utilizing a unique IAM function however use the frequent pool of pre-initialized employees to instantly course of requests.
- Allow interactive purposes – Interactive purposes that enable knowledge scientists and analysts to run interactive SQL queries for knowledge exploration require a quick response time to consumer requests. For such interactive purposes, EMR Serverless lets you pre-initialize a pool of employees. You can begin your EMR Serverless software and pre-initialize the pool of employees as quickly as a consumer begins the applying, and cease the applying to cease employees when no interactive customers are energetic. If processing consumer requests requires extra employees than what have been pre-initialized, EMR Serverless routinely provides extra employees as much as the utmost concurrent limits that you just specify. Due to this fact, by controlling the variety of employees to pre-initialize and the utmost concurrent employees, you may optimize consumer expertise and price to your interactive purposes.
- Make it simple to change from one deployment mannequin to a different – The identical Amazon EMR releases are supplied for purposes utilizing EMR clusters, Amazon EMR on EKS, and EMR Serverless. Once you construct an software utilizing an Amazon EMR launch (for instance a Spark job utilizing Amazon EMR launch 6.4), you may select to run it on an EMR cluster, Amazon EMR on EKS, or EMR Serverless with out having to rewrite the applying. This lets you construct purposes for a given framework model, and retain the pliability to alter the deployment mannequin primarily based on future operational wants.
Core ideas
On this part, we talk about the core ideas in EMR Serverless: purposes, jobs, employees, and pre-initialized employees.
Utility
With EMR Serverless, you may create a number of purposes that use open-source analytics frameworks. To create an software, you specify the open-source framework that you just need to use (for instance, Apache Spark or Apache Hive), the Amazon EMR launch for the open-source framework model (for instance, Amazon EMR launch 6.4, which corresponds to Apache Spark 3.1.2), and a reputation to your software. After you create an software, you may submit knowledge processing jobs or interactive requests to your software.
The next are a couple of examples the place you could need to create a number of purposes:
- To make use of completely different open-source frameworks (for instance, Hive or Spark)
- To make use of completely different variations of open-source frameworks for various use circumstances (for instance, use a more moderen model of Spark for a brand new software with out having to improve older purposes)
- To carry out A/B testing when upgrading from one model to a different (for instance, migrating from Spark 2.4 to Spark 3.1)
- To take care of separate logical environments for take a look at and manufacturing eventualities
- To supply separate logical environments for various groups with unbiased price controls and utilization monitoring
- To logically separate completely different line-of-business purposes (for instance, finance vs. advertising)
Job
A job is a request submitted to an EMR Serverless software that’s asynchronously run and tracked via completion. You possibly can run a number of jobs concurrently in an software.
Staff
An EMR Serverless software internally makes use of employees to run your jobs. By default, every software makes use of employees with 4 VCPU, 30 reminiscence, and 20 GB of native storage per employee. You could have the flexibility to customise this configuration.
Pre-initialized employees
EMR Serverless offers an non-obligatory function to pre-initialize employees when your software begins up, in order that the employees are able to course of requests instantly when a job is submitted to the applying. Pre-initialized employees can help you preserve a heat pool of employees for the applying in order that it may possibly present a sub-second response to start out processing requests.
Frequent utilization patterns utilized to EMR Serverless
Now let’s study some frequent utilization eventualities and the way EMR Serverless offers you a easy answer.
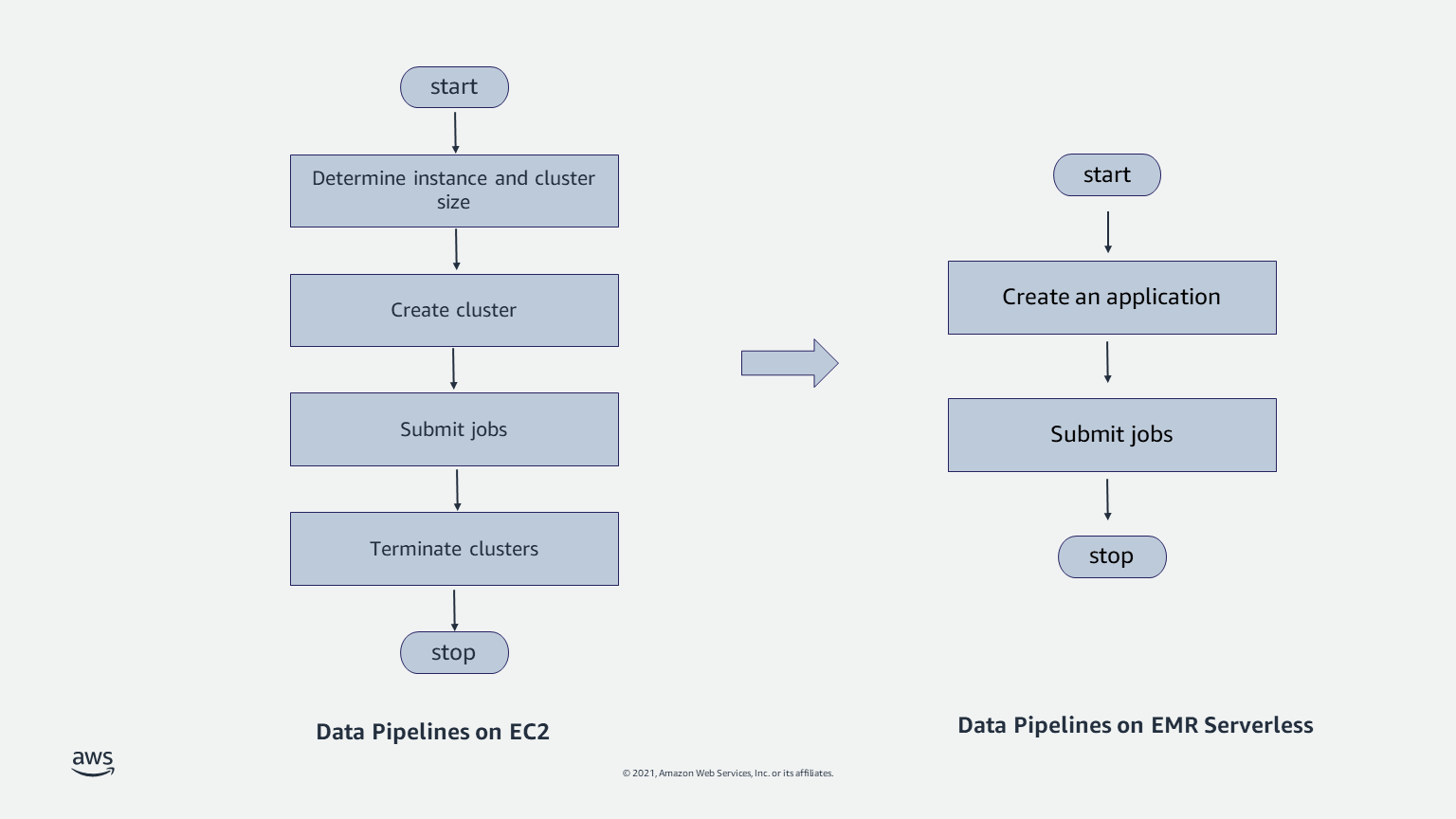
Sample #1: Knowledge pipelines
Knowledge pipelines are the spine of your analytics workloads. A standard sample with knowledge pipelines is to start out a cluster, run a job, and cease the cluster when the job is full. As a result of knowledge is separated from compute, the inputs and outputs for every job are continued individually from the cluster (for instance, in Amazon S3). These steps are incessantly automated utilizing workflow orchestration purposes akin to Apache Airflow. You may also use AWS providers akin to AWS Step Capabilities and AWS Managed Workflows for Apache Airflow (Amazon MWAA) to create such workflows.
Though automating these steps isn’t complicated, knowledge engineers must spend time figuring out the suitable EC2 occasion and cluster dimension. They’ve to find out the Availability Zone the place the cluster is run, and deal with failover. They’ve to check their purposes when adopting OS updates. When knowledge sizes change over time, they must resize clusters, or use options like Amazon EMR managed scaling that routinely resize clusters. EMR Serverless offers an easier answer by eliminating the necessity so that you can deal with these eventualities. You merely select the open-source framework and model to your software, and submit jobs. You don’t have to fret about occasion choice, cluster sizes, cluster startup, cluster resize, stopping nodes, Availability Zone failover, or OS updates.
Sample #2: Shared clusters
One other frequent sample is for groups to make use of a shared long-running cluster to run a number of jobs. On this case, engineers implement queues in Apache YARN for various workloads on a standard cluster, and arrange guidelines to routinely scale the cluster up or down primarily based on total workload. With Amazon EMR on EC2 clusters, you should use Amazon EMR managed scaling, a function that routinely scales clusters up or down relying on the workload. With EMR Serverless, employees are assigned to every job when required, so your jobs get the assets they want. Furthermore, since you solely pay for the employees that your jobs require, you don’t incur price for over-provisioned assets. Lastly, as a result of every job can specify the IAM function that ought to be used to entry AWS assets when working the job, you don’t must arrange complicated configurations to handle queues and permissions.
Sample #3: Interactive workloads
A 3rd sample of use is when groups maintain a cluster of cases out there to help interactive evaluation. On this case, the cluster is about up and initialized with purposes that await interactive consumer requests. Purposes are pre-initialized in order that they’ll instantly begin processing consumer requests and supply an interactive consumer expertise. EMR Serverless permits this situation with out requiring you to handle clusters. You possibly can specify the variety of employees that you just need to pre-initialize whenever you begin an EMR Serverless software. Subsequently, when customers submit requests, the pre-initialized employees can be utilized to instantly course of consumer requests. If processing the consumer requests requires extra employees than what you’ve gotten chosen to pre-initialize, EMR Serverless routinely provides extra employees (as much as the utmost concurrent restrict that you just specify). When the requests are processed, EMR Serverless routinely reverts again to sustaining the pre-initialized employees that you just specified. You possibly can management when the pre-initialized employees begin by controlling when to start out and cease your EMR Serverless software. For instance, you can begin your software when customers start interactive evaluation and switch it off when there are not any consumer requests and the applying stays idle.
Demo
Conclusion
On this submit, we mentioned the core ideas and customary utilization patterns of EMR Serverless, and confirmed you a fast demo. EMR Serverless is in Preview, in which you’ll be able to run workloads utilizing Spark 3.1.2 and Hive 2.0 utilizing the API, AWS Command Line Interface (AWS CLI), and SDK. Join for now, and for extra info, see EMR Serverless documentation.
In regards to the Authors
 Damon Cortesi is a Principal Developer Advocate with Amazon Net Providers.
Damon Cortesi is a Principal Developer Advocate with Amazon Net Providers.
 Mehul Y. Shah is the GM for Amazon EMR.
Mehul Y. Shah is the GM for Amazon EMR.
 Abhishek Sinha is a Principal Product Supervisor at Amazon Net Providers.
Abhishek Sinha is a Principal Product Supervisor at Amazon Net Providers.
[ad_2]