
{kind=link}
[ad_1]
CI/CD within the context of software improvement is a well-understood subject, and builders can select from quite a few patterns and instruments to construct their pipelines to deal with the construct, take a look at, and deploy cycle when a brand new commit will get into model management. For saved procedures and even schema adjustments which can be straight associated to the applying, that is usually a part of the code base and is included within the code repository of the applying. These adjustments are then utilized when the applying will get deployed to the take a look at or prod surroundings.
This put up demonstrates how one can apply the identical set of approaches to saved procedures, and even schema adjustments to information warehouses like Amazon Redshift.
Saved procedures are thought of code and as such ought to bear the identical rigor as software code. Because of this the pipeline ought to contain operating exams in opposition to adjustments to guarantee that no regressions are launched to the manufacturing surroundings. As a result of we automate the deployment of each saved procedures and schema adjustments, this considerably reduces inconsistencies in between environments.
Resolution overview
The next diagram illustrates our answer structure. We use AWS CodeCommit to retailer our code, AWS CodeBuild to run the construct course of and take a look at surroundings, and AWS CodePipeline to orchestrate the general deployment, from supply, to check, to manufacturing.
Database migrations and exams additionally require connection info to the related Amazon Redshift cluster; we exhibit combine this securely utilizing AWS Secrets and techniques Supervisor.

We talk about every service part in additional element later within the put up.
You’ll be able to see how all these parts work collectively by finishing the next steps:
- Clone the GitHub repo.
- Deploy the AWS CloudFormation template.
- Push code to the CodeCommit repository.
- Run the CI/CD pipeline.
Clone the GitHub repository
The CloudFormation template and the supply code for the instance software can be found within the GitHub repo. Earlier than you get began, you must clone the repository utilizing the next command:
This creates a brand new folder, amazon-redshift-devops-blog, with the recordsdata inside.
Deploy the CloudFormation template
The CloudFormation stack creates the VPC, Amazon Redshift clusters, CodeCommit repository, CodeBuild tasks for each take a look at and prod, and the pipeline utilizing CodePipeline to orchestrate the change launch course of.
- On the AWS CloudFormation console, select Create stack.
- Select With new sources (customary).
- Choose Add a template file.
- Select Select file and find the template file (
<cloned_directory>/cloudformation_template.yml). - Select Subsequent.

- For Stack identify, enter a reputation.
- Within the Parameters part, present the first person identify and password for each the take a look at and prod Amazon Redshift clusters.
The username should be 1–128 alphanumeric characters, and it might probably’t be a reserved phrase.
The password has the next standards:
- Have to be 8-64 characters
- Should include not less than one uppercase letter
- Should include not less than one lowercase letter
- Should include not less than one quantity
- Can solely include ASCII characters (ASCII codes 33–126), besides ‘ (single citation mark), ” (double citation mark), /, , or @
Please be aware that manufacturing credentials could possibly be created individually by privileged admins, and you would go within the ARN of a pre-existing secret as a substitute of the particular password in the event you so select.
- Select Subsequent.
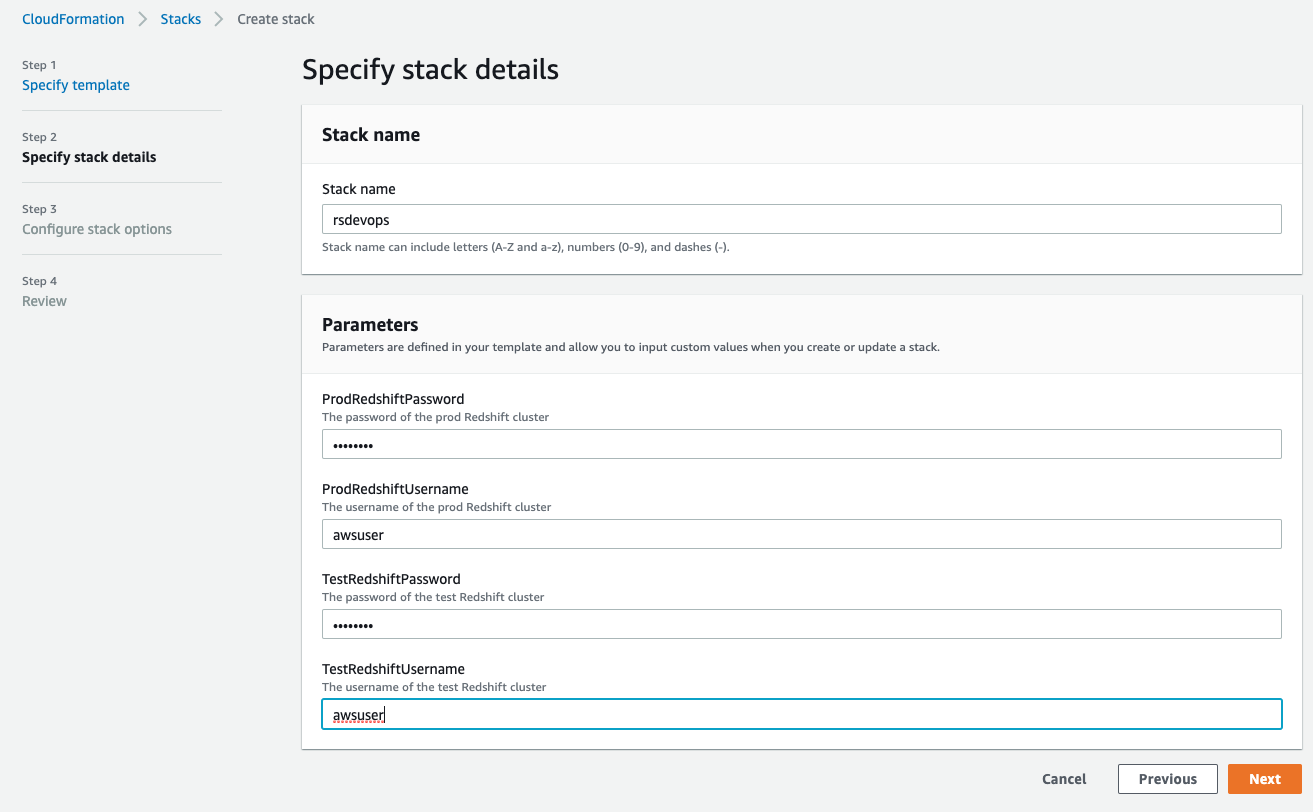
- Go away the remaining settings at their default and select Subsequent.

- Choose I acknowledge that AWS CloudFormation may create IAM sources.
- Select Create stack.

You’ll be able to select the refresh icon on the stack’s Occasions web page to trace the progress of the stack creation.

Push code to the CodeCommit repository
When stack creation is full, go to the CodeCommit console. Find the redshift-devops-repo repository that the stack created. Select the repository to view its particulars.
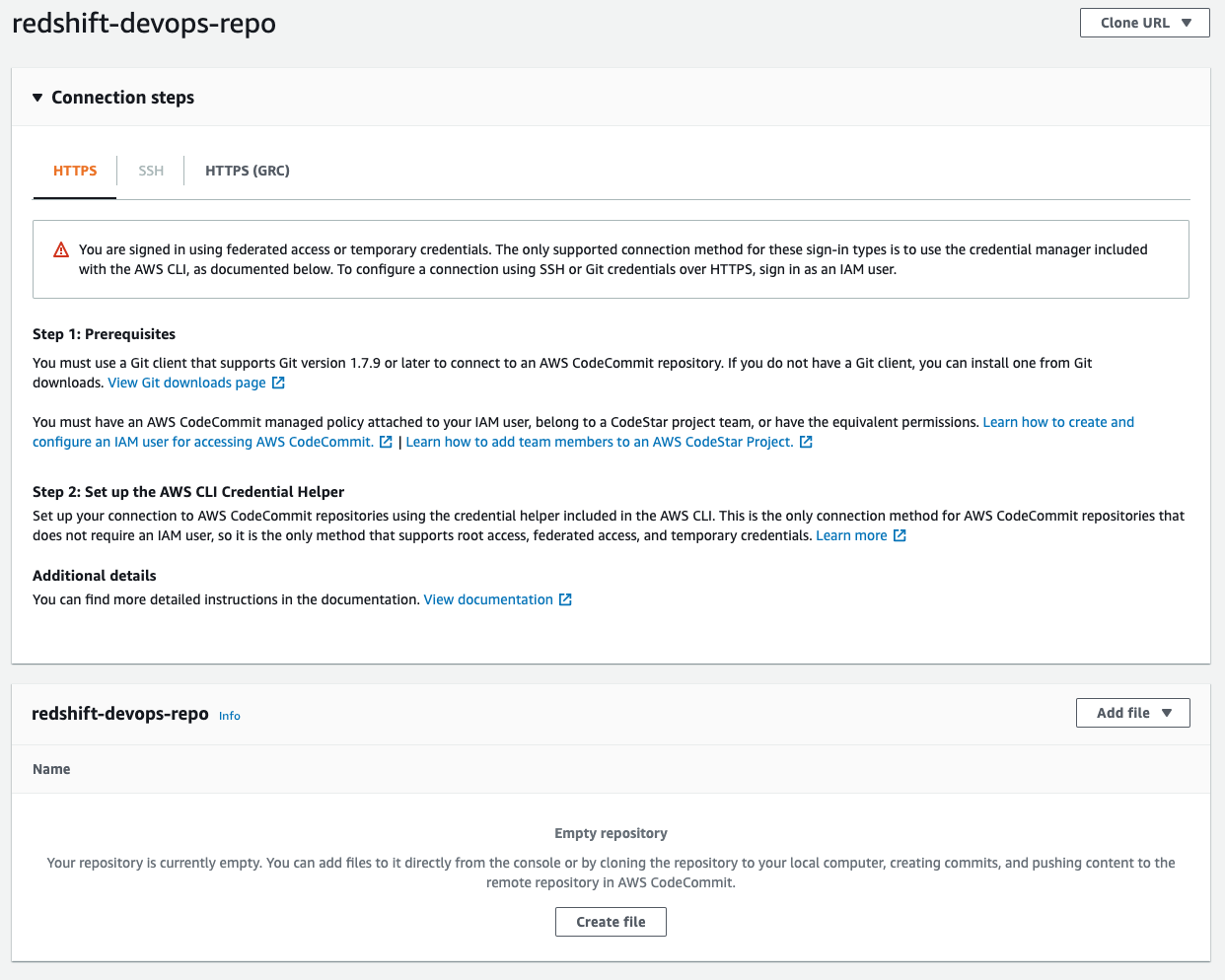
Earlier than you may push any code into this repo, it’s important to arrange your Git credentials utilizing directions right here Setup for HTTPS customers utilizing Git credentials. At Step 4 of the Setup for HTTPS customers utilizing Git credentials, copy the HTTPS URL, and as a substitute of cloning, add the CodeCommit repo URL into the code that we cloned earlier:
The final step populates the repository; you may examine it by refreshing the CodeCommit console. In the event you get prompted for a person identify and password, enter the Git credentials that you just generated and downloaded from Step 3 of the Setup for HTTPS customers utilizing Git credentials
Run the CI/CD pipeline
After you push the code to the CodeCommit repository, this triggers the pipeline to deploy the code into each the take a look at and prod Amazon Redshift clusters. You’ll be able to monitor the progress on the CodePipeline console.
To dive deeper into the progress of the construct, select Particulars.

You’re redirected to the CodeBuild console, the place you may see the run logs in addition to the results of the take a look at.
Elements and dependencies
Though from a high-level perspective the take a look at and prod surroundings look the identical, there are some nuances close to how these environments are configured. Earlier than diving deeper into the code, let’s have a look at the parts first:
- CodeCommit – That is the model management system the place you retailer your code.
- CodeBuild – This service runs the construct course of and take a look at utilizing Maven.
- Construct – Throughout the construct course of, Maven makes use of FlyWay to connect with Amazon Redshift to find out the present model of the schema and what must be run to carry it as much as the newest model.
- Take a look at – Within the take a look at surroundings, Maven runs JUnit exams in opposition to the take a look at Amazon Redshift cluster. These exams might contain loading information and testing the habits of the saved procedures. The outcomes of the unit exams are revealed into the CodeBuild take a look at experiences.
- Secrets and techniques Supervisor – We use Secrets and techniques Supervisor to securely retailer connection info to the assorted Amazon Redshift clusters. This consists of host identify, port, person identify, password, and database identify. CodeBuild refers to Secrets and techniques Supervisor for the related connection info when a construct will get triggered. The underlying CodeBuild service function must have the corresponding permission to entry the related secrets and techniques.
- CodePipeline – CodePipeline is answerable for the general orchestration from supply to check to manufacturing.
As referenced within the parts, we additionally use some extra dependencies on the code stage:
- Flyway – This framework is answerable for preserving totally different Amazon Redshift clusters in several environments in sync so far as schema and saved procedures are involved.
- JUnit – Unit testing framework written in Java.
- Apache Maven – A dependency administration and construct instrument. Maven is the place we combine Flyway and JUnit.
Within the following sections, we dive deeper into how these dependencies are built-in.
Apache Maven
For Maven, the configuration file is pom.xml. For an instance, you may take a look at the pom file from our demo app. The pertinent a part of the xml is the construct part:
This part describes two issues:
- By default, the Surefire plugin triggers in the course of the take a look at section of Maven. The plugin runs the unit exams and generates experiences based mostly on the outcomes of these exams. These experiences are saved within the
goal/surefire-reportsfolder. We reference this folder within the CodeBuild part. - Flyway is triggered in the course of the
process-resourcessection of Maven, and it triggers the migrate objective of Flyway. Maven’s lifecycle, this section is at all times triggered first and deploys the newest model of saved procedures and schemas to the take a look at surroundings earlier than operating take a look at circumstances.
Flyway
Modifications to the database are referred to as migrations, and these will be both versioned or repeatable. Builders can outline which kind of migration by the naming conference utilized by Flyway to find out which one is which. The next diagram illustrates the naming conference.

A versioned migration consists of the common SQL script that’s run and an non-obligatory undo SQL script to reverse the particular model. It’s important to create this undo script so as to allow the undo performance for a particular model. For instance, an everyday SQL script consists of making a brand new desk, and the corresponding undo script consists of dropping that desk. Flyway is answerable for preserving monitor of which model a database is at the moment at, and runs N variety of migrations relying on how far again the goal database is in comparison with the newest model. Versioned migrations are the commonest use of Flyway and are primarily used to keep up desk schema and hold reference or lookup tables updated by operating information masses or updates by way of SQL statements. Versioned migrations are utilized so as precisely one time.
Repeatable migrations don’t have a model; as a substitute they’re rerun each time their checksum adjustments. They’re helpful for sustaining user-defined capabilities and saved procedures. As an alternative of getting a number of recordsdata to trace adjustments over time, we are able to simply use a single file and Flyway retains monitor of when to rerun the assertion to maintain the goal database updated.
By default, these migration recordsdata are situated within the classpath beneath db/migration, the complete path being src/fundamental/sources/db/migration. For our instance software, you could find the supply code on GitHub.
JUnit
When Flyway finishes operating the migrations, the take a look at circumstances are run. These take a look at circumstances are beneath the folder src/take a look at/java. Yow will discover examples on GitHub that run a saved process by way of JDBC and validate the output or the influence.
One other side of unit testing to contemplate is how the take a look at information is loaded and maintained within the take a look at Amazon Redshift cluster. There are a few approaches to contemplate:
- As per our instance, we’re packaging the take a look at information as a part of our model management and loading the information when the primary unit take a look at is run. The benefit of this strategy is that you just get flexibility of when and the place you run the take a look at circumstances. You can begin with both a totally empty or partially populated take a look at cluster and also you get with the correct surroundings for the take a look at case to run. Different benefits are which you could take a look at information loading queries and have extra granular management over the datasets which can be being loaded for every take a look at. The draw back of this strategy is that, relying on how large your take a look at information is, it might add extra time on your take a look at circumstances to finish.
- Utilizing an Amazon Redshift snapshot devoted to the take a look at surroundings is one other option to handle the take a look at information. With this strategy, you’ve a pair extra choices:
- Transient cluster – You’ll be able to provision a transient Amazon Redshift cluster based mostly on the snapshot when the CI/CD pipeline will get triggered. This cluster stops after the pipeline completes to save lots of value. The draw back of this strategy is that it’s important to consider Amazon Redshift provisioning time in your end-to-end runtime.
- Lengthy-running cluster – Your take a look at circumstances can hook up with an current cluster that’s devoted to operating take a look at circumstances. The take a look at circumstances are answerable for ensuring that data-related setup and teardown are completed accordingly relying on the character of the take a look at that’s operating. You should utilize
@BeforeAlland@AfterAllJUnit annotations to set off the setup and teardown, respectively.
CodeBuild
CodeBuild gives an surroundings the place all of those dependencies run. As proven in our structure diagram, we use CodeBuild for each take a look at and prod. The variations are within the precise instructions that run in every of these environments. These instructions are saved within the buildspec.yml file. In our instance, we offer a separate buildspec file for take a look at and a special one for prod. Throughout the creation of a CodeBuild venture, we are able to specify which buildspec file to make use of.
There are a couple of variations between the take a look at and prod CodeBuild venture, which we talk about within the following sections.
Buildspec instructions
Within the take a look at surroundings, we use mvn clear take a look at and package deal the Surefire experiences so the take a look at outcomes will be displayed by way of the CodeBuild console. Whereas within the prod surroundings, we simply run mvn clear process-resources. The explanation for it’s because within the prod surroundings, we solely have to run the Flyway migrations, that are hooked as much as the process-resources Maven lifecycle, whereas within the take a look at surroundings, we not solely run the Flyway migrations, but in addition guarantee that it didn’t introduce any regressions by operating take a look at circumstances. These take a look at circumstances may have an effect on the underlying information, which is why we don’t run it in opposition to the manufacturing Amazon Redshift cluster. If you wish to run the take a look at circumstances in opposition to manufacturing information, you need to use an Amazon Redshift manufacturing cluster snapshot and run the take a look at circumstances in opposition to that.
Secrets and techniques by way of Secrets and techniques Supervisor
Each Flyway and JUnit want info to establish and hook up with Amazon Redshift. We retailer this info in Secrets and techniques Supervisor. Utilizing Secrets and techniques Supervisor has a number of advantages:
- Secrets and techniques are encrypted robotically
- Entry to secrets and techniques will be tightly managed by way of fine-grained AWS Id and Entry Administration (IAM) insurance policies
- All exercise with secrets and techniques is recorded, which permits straightforward auditing and monitoring
- You’ll be able to rotate secrets and techniques securely and safely with out impacting purposes
For our instance software, we outline the key as follows:
CodeBuild is built-in with Secrets and techniques Supervisor, so we outline the next surroundings variables as a part of the CodeBuild venture:
- TEST_HOST:
arn:aws:secretsmanager:<area>:<AWS Account Id>:secret:<secret identify>:host - TEST_JDBC_USER:
arn:aws:secretsmanager:<area>:<AWS Account Id>:secret:<secret identify>:username - TEST_JDBC_PASSWORD:
arn:aws:secretsmanager:<area>:<AWS Account Id>:secret:<secret identify>:password - TEST_PORT:
arn:aws:secretsmanager:<area>:<AWS Account Id>:secret:<secret identify>:port - TEST_DB_NAME:
arn:aws:secretsmanager:<area>:<AWS Account Id>:secret:<secret identify>:dbName - TEST_REDSHIFT_IAM_ROLE:
<ARN of IAM function>(This may be in plaintext and needs to be hooked up to the Amazon Redshift cluster) - TEST_DATA_S3_BUCKET:
<bucket identify>(That is the place the take a look at information is staged)
CodeBuild robotically retrieves the parameters from Secrets and techniques Supervisor and so they’re accessible within the software as surroundings variables. In the event you have a look at the buildspec_prod.yml instance, we use the previous variables to populate the Flyway surroundings variables and JDBC connection URL.
VPC configuration
For CodeBuild to have the ability to hook up with Amazon Redshift, you must configure which VPC it runs in. This consists of the subnets and safety group that it makes use of. The Amazon Redshift cluster’s safety group additionally wants to permit entry from the CodeBuild safety group.
CodePipeline
To carry all these parts collectively, we use CodePipeline to orchestrate the circulation from the supply code by way of prod deployment. CodePipeline additionally has extra capabilities. For instance, you may add an approval step between take a look at and prod so a launch supervisor can assessment the outcomes of the exams earlier than releasing the adjustments to manufacturing.
Instance state of affairs
You should utilize exams as a type of documentation of what’s the anticipated habits of a perform. To additional illustrate this level, let’s have a look at a easy saved process:
In the event you deployed the instance app from the earlier part, you may comply with alongside by copying the saved process code and pasting it in src/fundamental/sources/db/migration/R__MergeStagedProducts.sql. Put it aside and push the change to the CodeCommit repository by issuing the next instructions (assuming that you just’re on the high of the venture folder):
After you push the adjustments to the CodeCommit repository, you may comply with the progress of the construct and take a look at phases on the CodePipeline console.
We implement a fundamental Slowly Altering Dimension Sort 2 strategy by which we mark outdated information as CLOSED and append newer variations of the information. Though the saved process works as is, our take a look at has the next expectations:
- The variety of
closedstanding within the merchandise desk must correspond to the variety of duplicate entries within the staging desk. - The merchandise desk has a
close_datecolumn that must be populated so we all know when it was deprecated - On the finish of the merge, the staging desk must be cleared for subsequent ETL runs
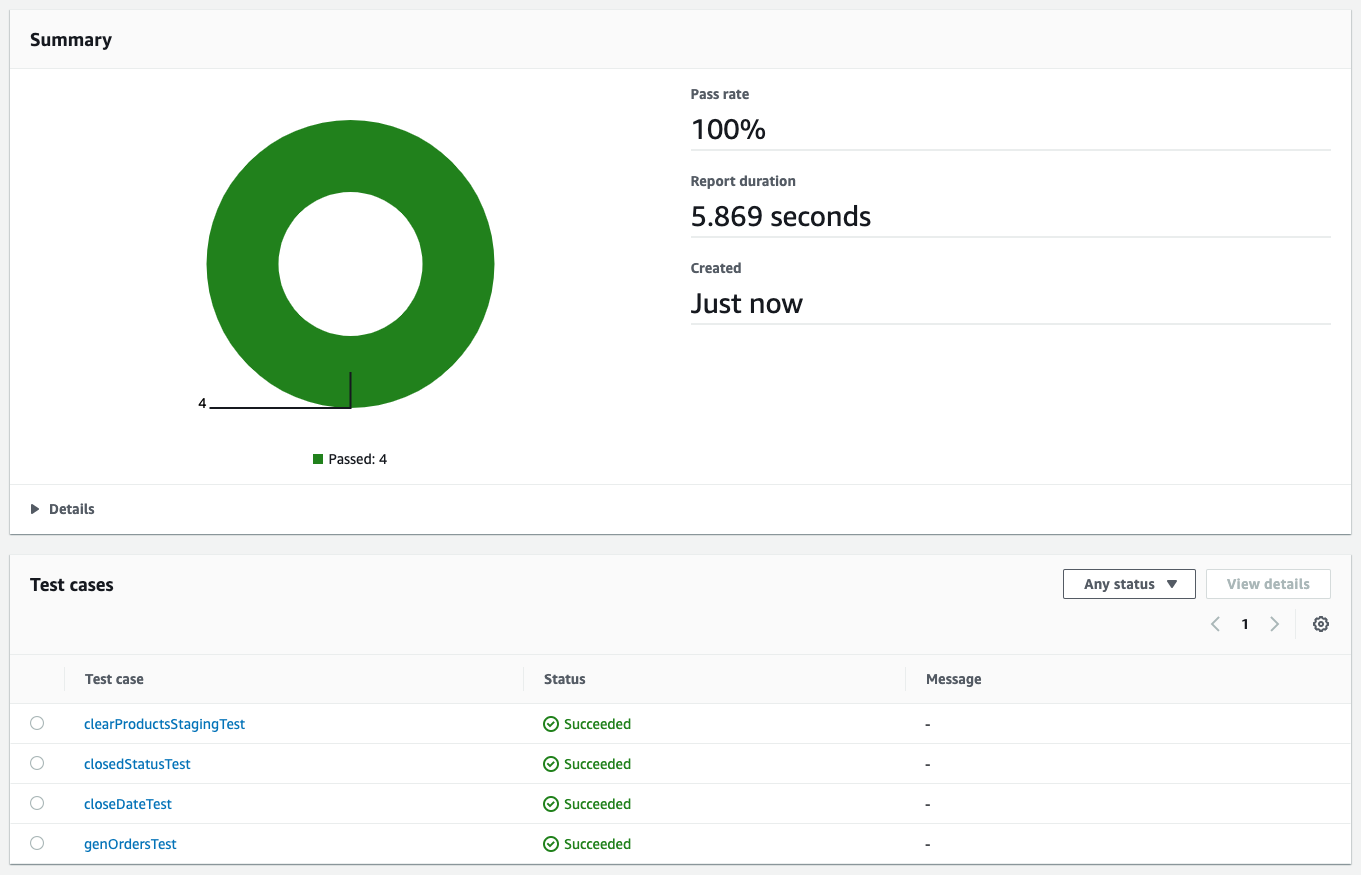
The saved process will go the primary take a look at, however fail later exams. After we push this transformation to CodeCommit and the CI/CD course of runs, we are able to see outcomes like within the following screenshot.

The exams present that the second and third exams failed. Failed exams consequence within the pipeline stopping, which suggests these unhealthy adjustments don’t find yourself in manufacturing.
We will replace the saved process and push the change to CodeCommit to set off the pipeline once more. The up to date saved process is as follows:
All of the exams handed this time, which permits CodePipeline to proceed with deployment to manufacturing.
We used Flyway’s repeatable migrations to make the adjustments to the saved process. Code is saved in a single file and Flyway verifies the checksum of the file to detect any adjustments and reapplies the migration if the checksum is totally different from the one which’s already deployed.
Clear up
After you’re completed, it’s essential to tear down the surroundings to keep away from incurring extra costs past your testing. Earlier than you delete the CloudFormation stack, go to the Assets tab of your stack and ensure the 2 buckets that have been provisioned are empty. In the event that they’re not empty, delete all of the contents of the buckets.

Now that the buckets are empty, you may return to the AWS CloudFormation console and delete the stack to finish the cleanup of all of the provisioned sources.
Conclusion
Utilizing CI/CD ideas within the context of Amazon Redshift saved procedures and schema adjustments tremendously improves confidence when updates are getting deployed to manufacturing environments. Much like CI/CD in software improvement, correct take a look at protection of saved procedures is paramount to capturing potential regressions when adjustments are made. This consists of testing each success paths in addition to all potential failure modes.
As well as, versioning migrations permits consistency throughout a number of environments and prevents points arising from schema adjustments that aren’t utilized correctly. This will increase confidence when adjustments are being made and improves improvement velocity as groups spend extra time creating performance somewhat than looking for points on account of surroundings inconsistencies.
We encourage you to attempt constructing a CI/CD pipeline for Amazon Redshift utilizing these steps described on this weblog.
Concerning the Authors
 Ashok Srirama is a Senior Options Architect at Amazon Net Companies, based mostly in Washington Crossing, PA. He focuses on serverless purposes, containers, devops, and architecting distributed methods. When he’s not spending time along with his household, he enjoys watching cricket, and driving his bimmer.
Ashok Srirama is a Senior Options Architect at Amazon Net Companies, based mostly in Washington Crossing, PA. He focuses on serverless purposes, containers, devops, and architecting distributed methods. When he’s not spending time along with his household, he enjoys watching cricket, and driving his bimmer.
 Indira Balakrishnan is a Senior Options Architect within the AWS Analytics Specialist SA Group. She is captivated with serving to prospects construct cloud-based analytics options to unravel their enterprise issues utilizing data-driven selections. Exterior of labor, she volunteers at her youngsters’ actions and spends time together with her household.
Indira Balakrishnan is a Senior Options Architect within the AWS Analytics Specialist SA Group. She is captivated with serving to prospects construct cloud-based analytics options to unravel their enterprise issues utilizing data-driven selections. Exterior of labor, she volunteers at her youngsters’ actions and spends time together with her household.
 Vaibhav Agrawal is an Analytics Specialist Options Architect at AWS.All through his profession, he has targeted on serving to prospects design and construct well-architected analytics and resolution assist platforms.
Vaibhav Agrawal is an Analytics Specialist Options Architect at AWS.All through his profession, he has targeted on serving to prospects design and construct well-architected analytics and resolution assist platforms.
 Rajesh Francis is a Sr. Analytics Buyer Expertise Specialist at AWS. He focuses on Amazon Redshift and works with prospects to construct scalable Analytic options.
Rajesh Francis is a Sr. Analytics Buyer Expertise Specialist at AWS. He focuses on Amazon Redshift and works with prospects to construct scalable Analytic options.
 Jeetesh Srivastva is a Sr. Supervisor, Specialist Options Architect at AWS. He focuses on Amazon Redshift and works with prospects to implement scalable options utilizing Amazon Redshift and different AWS Analytic providers. He has labored to ship on-premises and cloud-based analytic options for patrons in banking and finance and hospitality trade verticals.
Jeetesh Srivastva is a Sr. Supervisor, Specialist Options Architect at AWS. He focuses on Amazon Redshift and works with prospects to implement scalable options utilizing Amazon Redshift and different AWS Analytic providers. He has labored to ship on-premises and cloud-based analytic options for patrons in banking and finance and hospitality trade verticals.
[ad_2]