

[ad_1]
[*]
Ingesting and querying JSON with semi-structured information may be tedious and time-consuming, however Auto Loader and Delta Lake make it straightforward. JSON information may be very versatile, which makes it highly effective, but in addition tough to ingest and question. The largest challenges embody:
- It’s a tedious and fragile course of to outline a schema of the JSON file being ingested.
- The schema can change over time, and also you want to have the ability to deal with these modifications routinely.
- Software program doesn’t at all times decide the proper schema to your information, and it’s possible you’ll have to trace on the right format. For instance, the quantity 32 might be interpreted as both an integer or a protracted.
- Typically information engineers don’t have any management of upstream information sources producing the semi-structured information. For instance, the column title could also be higher or decrease case however denotes the identical column, or the information sort generally modifications, and it’s possible you’ll not need to utterly rewrite the already ingested information in Delta Lake.
- You could not need to do the upfront work of flattening out JSON paperwork and extracting each single column, and doing so could make the information very exhausting to make use of.
- Querying semi-structured information in SQL is tough. You want to have the ability to question this information in a fashion that’s straightforward to know.
On this weblog and the accompanying pocket book we are going to present what built-in options make working with JSON easy at scale within the Databricks Lakehouse. Beneath is an incremental ETL structure. The left-hand facet represents steady and scheduled ingest, and we are going to focus on how you can do each sorts of ingest with Auto Loader. After the JSON file is ingested right into a bronze Delta Lake desk, we are going to focus on the options that make it straightforward to question advanced and semi-structured information varieties which might be widespread in JSON information.
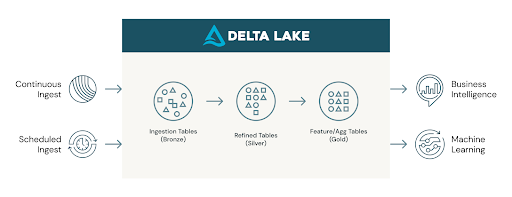
Within the accompanying pocket book, we used gross sales order information to show how you can simply ingest JSON. The nested JSON gross sales order datasets get advanced in a short time.
Trouble-free JSON ingestion with Auto Loader
Auto Loader offers Python and Scala interfaces to ingest new information from a folder location in object storage (S3, ADLS, GCS) right into a Delta Lake desk. Auto Loader makes ingestion straightforward and hassle-free by enabling information ingestion into Delta Lake tables immediately from object storage in both a steady or scheduled means.
Earlier than discussing the overall options of Auto Loader, let’s dig into the options that make ingesting the JSON extraordinarily straightforward. Beneath is an instance of how you can ingest very advanced JSON information.
df = spark.readStream.format("cloudFiles") .possibility("cloudFiles.schemaLocation", schemaLocation) .possibility("cloudFiles.format", "json") .possibility("cloudFiles.inferColumnTypes", "true") .possibility("cloudFiles.schemaEvolutionMode", "addNewColumns") .possibility("cloudFiles.schemaHints", schemaHints) .load(landingZoneLocation)Flexibility and ease of defining the schema: Within the code above, we use two options of Auto Loader to simply outline the schema whereas giving guardrails for problematic information. The 2 helpful options are cloudFiles.inferColumnTypes (Highly effective Function No. 1 – InferColumnTypes) and cloudFiles.schemaHints (Highly effective Function No.2 – Schema Hints). Let’s take a better have a look at the definitions:
- cloudFiles.inferColumnTypes is the choice to activate/off the mechanism to deduce information varieties, for instance, string, integers, longs and floats, throughout the schema inference course of. The default worth for cloudFiles.inferColumnTypes is fake as a result of, usually, it’s higher to have the top-level columns be strings for schema evolution robustness and keep away from points resembling numeric sort mismatches(integers, longs, floats) throughout the schema evolution course of.
- cloudFiles.schemaHints is the choice to specify desired information varieties to a number of the columns, aka “schemaHints”, throughout the schema inference course of. Schema hints are used provided that you don’t present a schema to Auto Loader. You should use schema hints whether or not cloudFiles.inferColumnTypes is enabled or disabled. Extra particulars may be discovered right here.
On this use case (pocket book), we really set cloudFiles.inferColumnTypes to true since we wish the columns and the advanced information varieties to be inferred, as a substitute of Auto Loader’s default inferred information sort of string. Inferring most columns will give the constancy of this advanced JSON and supply flexibility for querying later. As well as, whereas inferring the column varieties may be very handy, we additionally know there are problematic columns ingested. That is the place cloudFiles.schemaHints comes into play, working along with cloudFiles.inferColumnTypes. The mixture of the 2 choices permits for inferring most columns’ advanced information varieties whereas specifying the specified information sort (string) for solely two of the columns.
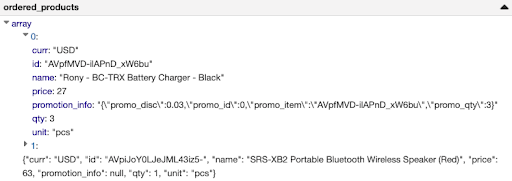
Let’s take a better have a look at the 2 problematic columns. From the semi-structured JSON information we use within the pocket book, we now have recognized two columns of problematic information: “ordered_products.aspect.promotion_info” and “clicked_items”. Therefore, we trace that they need to are available in as strings (see information snippets for one of many columns above: “ordered_products.aspect.promotion_info”). For these columns, we will simply question the semi-structured JSON in SQL, which we are going to focus on later. You’ll be able to see that one of many hints is on a nested column inside an array, which makes this characteristic actually practical on advanced schemas!
Dealing with schema modifications over time make the ingest and information extra resilient: Like schema inference, schema evolution (Highly effective Function No.3) is easy to implement with Auto Loader. All it’s a must to do is ready cloudFiles.schemaLocation, which saves the schema to that location within the object storage, after which the schema evolution may be accommodated over time. To make clear, schema evolution is when the schema of the ingested information modifications and the schema of the Delta Lake desk modifications accordingly.
For instance, in the accompanying pocket book, an additional column named fulfillment_days is added to the information ingested by Auto Loader. This column is recognized by Auto Loader and utilized routinely to the Delta Lake desk. Per the documentation, you possibly can change the schema evolution mode to your liking. Here’s a fast overview of the supported modes for Auto Loader’s possibility cloudFiles.schemaEvolutionMode:
- addNewColumns: The default mode when a schema will not be offered to Auto Loader. New columns are added to the schema. Current columns don’t evolve information varieties.
- failOnNewColumns: If Auto Loader detects a brand new column, the stream will fail. It is not going to restart until the offered schema is up to date, or the offending information file is eliminated.
- rescue: The stream runs with the very first inferred or offered schema. Any information sort modifications or new columns are routinely saved within the rescued information column as _rescued_data in your stream’s schema. On this mode, your stream is not going to fail as a result of schema modifications.
- none: The default mode when a schema is offered to Auto Loader. It doesn’t evolve the schema. New columns are ignored, and information will not be rescued until the rescued information column is offered individually as an possibility.
The instance above (additionally within the pocket book) doesn’t embody a schema, therefore we use the default possibility .possibility(“cloudFiles.schemaEvolutionMode”, “addNewColumns”) on readStream to accommodate schema evolution.
Seize unhealthy information in an additional column, so nothing is misplaced: The rescued information column (Highly effective Function No. 4) is the place all unparsed information is stored, which ensures that you just by no means lose information throughout ETL. If information doesn’t adhere to the present schema and may’t go into its required column, the information received’t be misplaced with the rescued information column. On this use case (pocket book), we didn’t use this feature. To activate this feature, you possibly can specify the next: .possibility(“cloudFiles.schemaEvolutionMode”, “rescue”). Please see extra info right here.
Now that we now have explored the Auto Loader options that make it nice for JSON information and the tackled challenges talked about firstly, let’s have a look at a number of the options that make it hassle-free for all ingest:
df.writeStream .format("delta") .set off(as soon as=True) .possibility("mergeSchema", "true") .possibility("checkpointLocation", bronzeCheckPointLocation) .begin(bronzeTableLocation)Steady vs. scheduled ingest: Whereas Auto Loader is an Apache Spark™ Structured Streaming supply, it doesn’t must run constantly. You should use the set off as soon as possibility (Highly effective Function No. 5) to show it right into a scheduled job that turns itself off when all recordsdata have been ingested. This turns out to be useful once you don’t have the necessity for constantly working ingest. But, it additionally offers you the power to drop the cadence of the schedule over time, after which ultimately go to constantly working ingest with out altering the code. In DBR 10.1 and later, we now have launched Set off.AvailableNow, which offers the identical information processing semantics as set off as soon as, however may also carry out charge limiting to make sure that your information processing can scale to very massive quantities of knowledge
The right way to deal with state: State is the data wanted to start out up the place the ingestion course of left off if the method is stopped. For instance, with Auto Loader, the state would come with the set of recordsdata already ingested. Checkpoints save the state if the ETL is stopped at any level, whether or not on function or as a result of failure. By leveraging checkpoints, Auto Loader can run constantly and in addition be part of a periodic or scheduled job. Within the instance above, the checkpoint is saved within the possibility checkpointLocation (Highly effective Function No. 6 – Checkpoints). If the Auto Loader is terminated after which restarted, it’ll use the checkpoint to return to its newest state and won’t reprocess recordsdata which have already been processed.
Querying semi-structured and sophisticated structured information
Now that we now have our JSON information in a Delta Lake desk, let’s discover the highly effective methods you possibly can question semi-structured and sophisticated structured information. Let’s deal with the final problem of Querying semi-structured information.
Till this level, we now have used Auto Loader to jot down a Delta Desk to a selected location. We will entry this desk by location in SQL, however for readability, we level an exterior desk to the placement utilizing the next SQL code.
CREATE TABLE autoloaderBronzeTable LOCATION '${c.bronzeTablePath}';Simply entry prime stage and nested information in semi-structured JSON columns utilizing syntax for casting values:
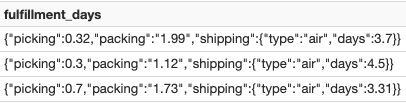
SELECT fulfillment_days, fulfillment_days:choosing, fulfillment_days:packing::double, fulfillment_days:transport.days FROM autoloaderBronzeTable WHERE fulfillment_days IS NOT NULLWhen ingesting information, it’s possible you’ll have to maintain it in a JSON string, and a few information is probably not within the right information sort. In these circumstances, syntax within the above instance makes querying elements of the semi-structured information easy and simple to learn. To double click on on this instance, let’s have a look at information within the column filfillment_days, which is a JSON string column:
{kind=link}
- Accessing top-level columns: Use a single colon (:) to entry the top-level of a JSON string column (Highly effective Function No. 7 – Extract JSON Columns). For instance, filfillment_days:choosing returns the worth 0.32 for the primary row above.
- Accessing nested fields: Use the dot notation to entry nested fields (Highly effective Function No. 8 – Dot Notation). For instance, fulfillment_days:transport.days returns the worth 3.7 for the primary row above.
- Casting values: Use a double colon (::) and adopted by the information sort to solid values (Highly effective Function No. 9 – Forged Values). For instance, fulfillment_days:packing::double returns the double information sort worth 1.99 for the string worth of packing for the primary row above.
Extracting values from semi-structured arrays even when the information is ill-formed:
SELECT *, scale back(all_click_count_array, 0, (acc, worth) -> acc + worth) as
sum
FROM (
SELECT order_number, clicked_items:[*][1] as all_click_counts,
from_json(clicked_items:[*][1], 'ARRAY')::ARRAY as all_click_count_array
FROM autoloaderBronzeTable
)
Sadly, not all information involves us in a usable construction. For instance, the column clicked_items is a complicated array of arrays by which the depend is available in as a string. Beneath is a snippet of the information within the column clicked_items:

- Extracting values from arrays(Highly effective Function No. 10): Use an asterisk (*) to extract all values in a JSON array string. For the precise array indices, use a 0-based worth. For instance, SQL clicked_items:[*][1]returns the string worth of [“54″,”85”].
- Casting advanced array values: After extracting the proper values for the array of arrays, we will use from_json and ::ARRAY
to solid the array right into a format that may be summed utilizing scale back. Ultimately, the primary row returns the summed worth of 139 (54 + 89). It’s fairly superb how simply we will sum values from ill-formed JSON in SQL!
Aggregations in SQL with advanced structured information:
Accessing advanced structured information, in addition to shifting between structured and semi-structured information, has been obtainable for fairly a while in Databricks.
SELECT order_date, ordered_products_explode.title as product_name,
SUM(ordered_products_explode.qty) as amount
FROM (
SELECT DATE(from_unixtime(order_datetime)) as order_date,
EXPLODE(ordered_products) as ordered_products_explode
FROM autoloaderBronzeTable
WHERE DATE(from_unixtime(order_datetime)) will not be null
)
GROUP BY order_date, ordered_products_explode.title
ORDER BY order_date, ordered_products_explode.title
Earlier within the weblog, we used possibility(“cloudFiles.inferColumnTypes”, “true”) in Auto Loader to learn JSON on this part to deduce the advanced information sort for the column ordered_products. Within the SQL question above, we explored how you can entry and combination information from the advanced structured information. Beneath is an instance of 1 row of the column ordered_products, and we need to discover the amount of every product bought every day. As you possibly can see, each the product and amount are nested in an array.

- Accessing array parts as rows: Use explode on the ordered_products column so that every aspect is its personal row, as seen beneath.

- Accessing nested fields: Use the dot notation to entry nested fields in the identical method as semi-structured JSON. For instance, ordered_products_explode.qty returns the worth 1 for the primary row above. We will then group and sum the portions by date and the product title.
Extra Sources: we now have lined many matters on querying structured and semi-structured JSON information, however you will discover extra info right here:
Conclusion
At Databricks, we try to make the not possible attainable and the exhausting straightforward. Auto Loader makes ingesting advanced JSON use circumstances at scale straightforward and attainable. The SQL syntax for semi-structured and sophisticated information makes manipulating information straightforward. Now that you know the way to ingest and question advanced JSON with Auto Loader and SQL with these 10 highly effective options, we will’t wait to see what you construct with them.
[*][ad_2]