

{kind=link}
[ad_1]
Processing uncooked sensory inputs is essential for making use of deep RL algorithms to real-world issues.
For instance, autonomous automobiles should make choices about the best way to drive safely given data flowing from cameras, radar, and microphones concerning the situations of the highway, visitors indicators, and different automobiles and pedestrians.
Nonetheless, direct “end-to-end” RL that maps sensor information to actions (Determine 1, left) could be very tough as a result of the inputs are high-dimensional, noisy, and comprise redundant data.
As a substitute, the problem is commonly damaged down into two issues (Determine 1, proper): (1) extract a illustration of the sensory inputs that retains solely the related data, and (2) carry out RL with these representations of the inputs because the system state.

Determine 1. Illustration studying can extract compact representations of states for RL.
All kinds of algorithms have been proposed to be taught lossy state representations in an unsupervised vogue (see this latest tutorial for an outline).
Just lately, contrastive studying strategies have confirmed efficient on RL benchmarks similar to Atari and DMControl (Oord et al. 2018, Stooke et al. 2020, Schwarzer et al. 2021), in addition to for real-world robotic studying (Zhan et al.).
Whereas we might ask which goals are higher through which circumstances, there may be an much more primary query at hand: are the representations realized through these strategies assured to be ample for management?
In different phrases, do they suffice to be taught the optimum coverage, or would possibly they discard some vital data, making it not possible to resolve the management drawback?
For instance, within the self-driving automobile state of affairs, if the illustration discards the state of stoplights, the automobile can be unable to drive safely.
Surprisingly, we discover that some extensively used goals usually are not ample, and actually do discard data that could be wanted for downstream duties.
Defining the Sufficiency of a State Illustration
As launched above, a state illustration is a perform of the uncooked sensory inputs that discards irrelevant and redundant data.
Formally, we outline a state illustration $phi_Z$ as a stochastic mapping from the unique state area $mathcal{S}$ (the uncooked inputs from all of the automobile’s sensors) to a illustration area $mathcal{Z}$: $p(Z | S=s)$.
In our evaluation, we assume that the unique state $mathcal{S}$ is Markovian, so every state illustration is a perform of solely the present state.
We depict the illustration studying drawback as a graphical mannequin in Determine 2.
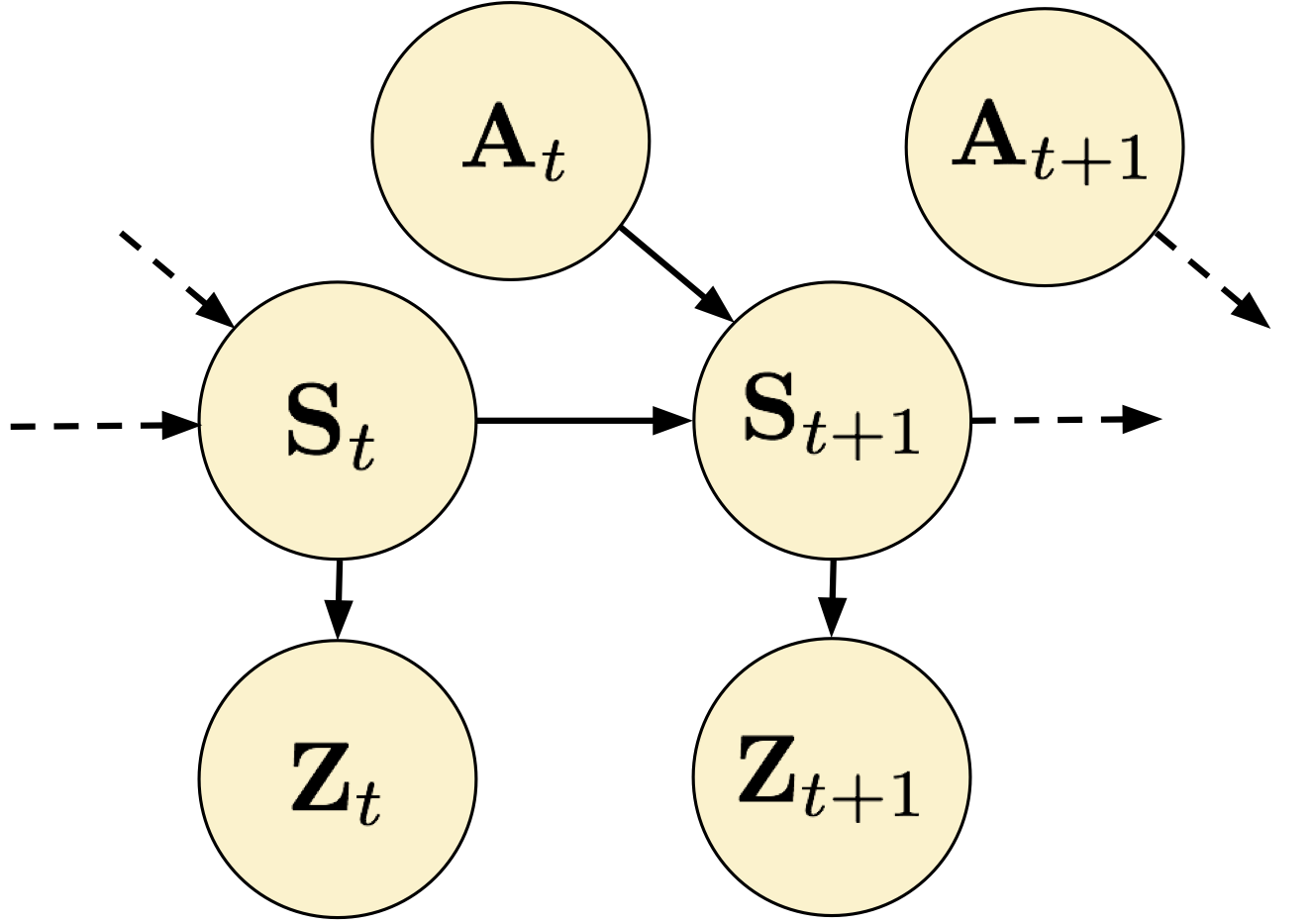
Determine 2. The illustration studying drawback in RL as a graphical mannequin.
We are going to say {that a} illustration is ample whether it is assured that an RL algorithm utilizing that illustration can be taught the optimum coverage.
We make use of a consequence from Li et al. 2006, which proves that if a state illustration is able to representing the optimum $Q$-function, then $Q$-learning run with that illustration as enter is assured to converge to the identical answer as within the authentic MDP (in the event you’re , see Theorem 4 in that paper).
So to check if a illustration is ample, we will examine if it is ready to signify the optimum $Q$-function.
Since we assume we don’t have entry to a job reward throughout illustration studying, to name a illustration ample we require that it might probably signify the optimum $Q$-functions for all attainable reward capabilities within the given MDP.
Analyzing Representations realized through MI Maximization
Now that we’ve established how we’ll consider representations, let’s flip to the strategies of studying them.
As talked about above, we purpose to review the favored class of contrastive studying strategies.
These strategies can largely be understood as maximizing a mutual data (MI) goal involving states and actions.
To simplify the evaluation, we analyze illustration studying in isolation from the opposite elements of RL by assuming the existence of an offline dataset on which to carry out illustration studying.
This paradigm of offline illustration studying adopted by on-line RL is changing into more and more standard, significantly in functions similar to robotics the place amassing information is onerous (Zhan et al. 2020, Kipf et al. 2020).
Our query is due to this fact whether or not the target is ample by itself, not as an auxiliary goal for RL.
We assume the dataset has full assist on the state area, which could be assured by an epsilon-greedy exploration coverage, for instance.
An goal could have multiple maximizing illustration, so we name a illustration studying goal ample if all the representations that maximize that goal are ample.
We are going to analyze three consultant goals from the literature when it comes to sufficiency.
Representations Discovered by Maximizing “Ahead Data”
We start with an goal that appears more likely to retain quite a lot of state data within the illustration.
It’s carefully associated to studying a ahead dynamics mannequin in latent illustration area, and to strategies proposed in prior works (Nachum et al. 2018, Shu et al. 2020, Schwarzer et al. 2021): $J_{fwd} = I(Z_{t+1}; Z_t, A_t)$.
Intuitively, this goal seeks a illustration through which the present state and motion are maximally informative of the illustration of the subsequent state.
Due to this fact, all the pieces predictable within the authentic state $mathcal{S}$ needs to be preserved in $mathcal{Z}$, since this could maximize the MI.
Formalizing this instinct, we’re in a position to show that each one representations realized through this goal are assured to be ample (see the proof of Proposition 1 within the paper).
Whereas reassuring that $J_{fwd}$ is ample, it’s value noting that any state data that’s temporally correlated will probably be retained in representations realized through this goal, regardless of how irrelevant to the duty.
For instance, within the driving state of affairs, objects within the agent’s visual view that aren’t on the highway or sidewalk would all be represented, although they’re irrelevant to driving.
Is there one other goal that may be taught ample however lossier representations?
Representations Discovered by Maximizing “Inverse Data”
Subsequent, we contemplate what we time period an “inverse data” goal: $J_{inv} = I(Z_{t+ok}; A_t | Z_t)$.
One method to maximize this goal is by studying an inverse dynamics mannequin – predicting the motion given the present and subsequent state – and lots of prior works have employed a model of this goal (Agrawal et al. 2016, Gregor et al. 2016, Zhang et al. 2018 to call a number of).
Intuitively, this goal is interesting as a result of it preserves all of the state data that the agent can affect with its actions.
It due to this fact could seem to be an excellent candidate for a ample goal that discards extra data than $J_{fwd}$.
Nonetheless, we will really assemble a sensible state of affairs through which a illustration that maximizes this goal will not be ample.
For instance, contemplate the MDP proven on the left facet of Determine 4 through which an autonomous automobile is approaching a visitors gentle.
The agent has two actions obtainable, cease or go.
The reward for following visitors guidelines depends upon the colour of the stoplight, and is denoted by a purple X (low reward) and inexperienced examine mark (excessive reward).
On the correct facet of the determine, we present a state illustration through which the colour of the stoplight will not be represented within the two states on the left; they’re aliased and represented as a single state.
This illustration will not be ample, since from the aliased state it isn’t clear whether or not the agent ought to “cease” or “go” to obtain the reward.
Nonetheless, $J_{inv}$ is maximized as a result of the motion taken remains to be precisely predictable given every pair of states.
In different phrases, the agent has no management over the stoplight, so representing it doesn’t enhance MI.
Since $J_{inv}$ is maximized by this inadequate illustration, we will conclude that the target will not be ample.
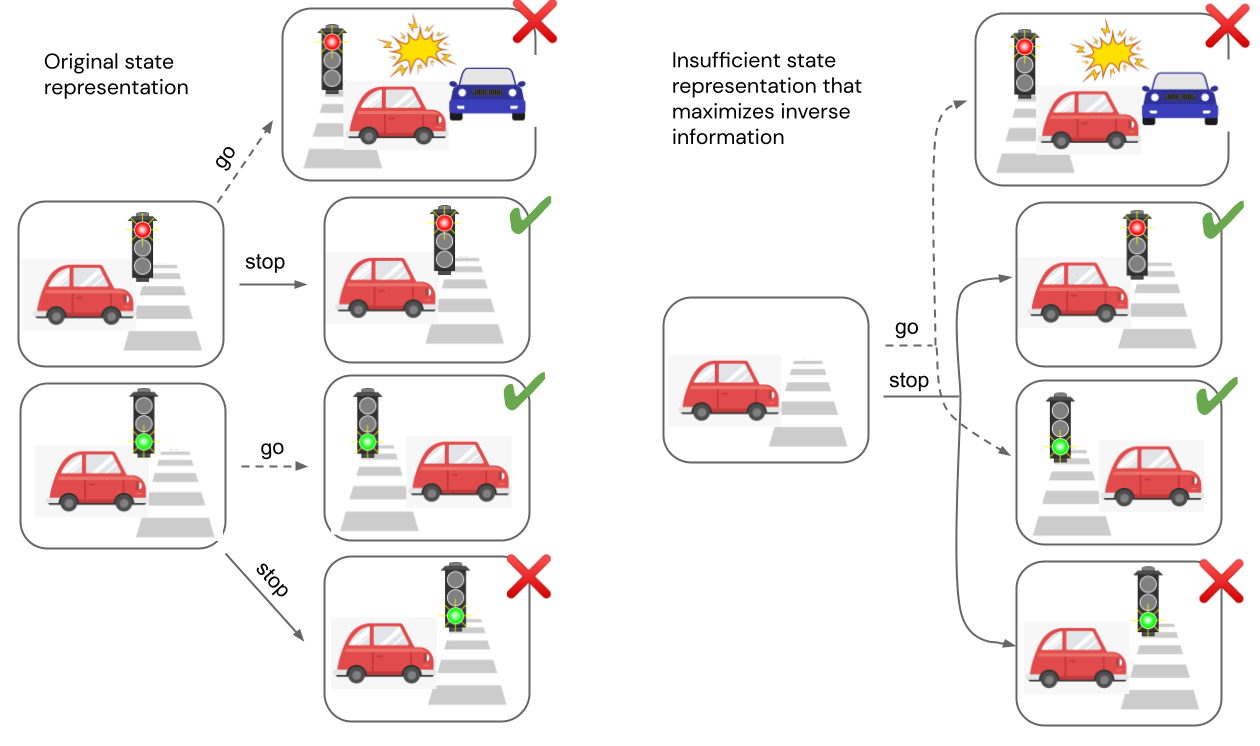
Determine 4. Counterexample proving the insufficiency of $J_{inv}$.
Because the reward depends upon the stoplight, maybe we will treatment the problem by moreover requiring the illustration to be able to predicting the instant reward at every state.
Nonetheless, that is nonetheless not sufficient to ensure sufficiency – the illustration on the correct facet of Determine 4 remains to be a counterexample for the reason that aliased states have the identical reward.
The crux of the issue is that representing the motion that connects two states will not be sufficient to have the ability to select the perfect motion.
Nonetheless, whereas $J_{inv}$ is inadequate within the basic case, it will be revealing to characterize the set of MDPs for which $J_{inv}$ could be confirmed to be ample.
We see this as an fascinating future route.
Representations Discovered by Maximizing “State Data”
The ultimate goal we contemplate resembles $J_{fwd}$ however omits the motion: $J_{state} = I(Z_t; Z_{t+1})$ (see Oord et al. 2018, Anand et al. 2019, Stooke et al. 2020).
Does omitting the motion from the MI goal impression its sufficiency?
It seems the reply is sure.
The instinct is that maximizing this goal can yield inadequate representations that alias states whose transition distributions differ solely with respect to the motion.
For instance, contemplate a state of affairs of a automobile navigating to a metropolis, depicted under in Determine 5.
There are 4 states from which the automobile can take actions “flip proper” or “flip left.”
The optimum coverage takes first a left flip, then a proper flip, or vice versa.
Now contemplate the state illustration proven on the correct that aliases $s_2$ and $s_3$ right into a single state we’ll name $z$.
If we assume the coverage distribution is uniform over left and proper turns (an inexpensive state of affairs for a driving dataset collected with an exploration coverage), then this illustration maximizes $J_{state}$.
Nonetheless, it might probably’t signify the optimum coverage as a result of the agent doesn’t know whether or not to go proper or left from $z$.
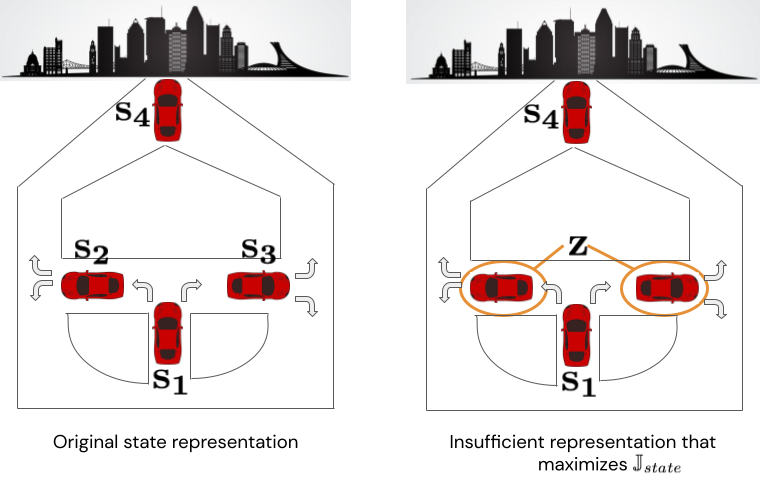
Determine 5. Counterexample proving the insufficiency of $J_{state}$.
Can Sufficiency Matter in Deep RL?
To grasp whether or not the sufficiency of state representations can matter in apply, we carry out easy proof-of-concept experiments with deep RL brokers and picture observations. To separate illustration studying from RL, we first optimize every illustration studying goal on a dataset of offline information, (just like the protocol in Stooke et al. 2020). We accumulate the fastened datasets utilizing a random coverage, which is ample to cowl the state area in our environments. We then freeze the weights of the state encoder realized within the first part and practice RL brokers with the illustration as state enter (see Determine 6).
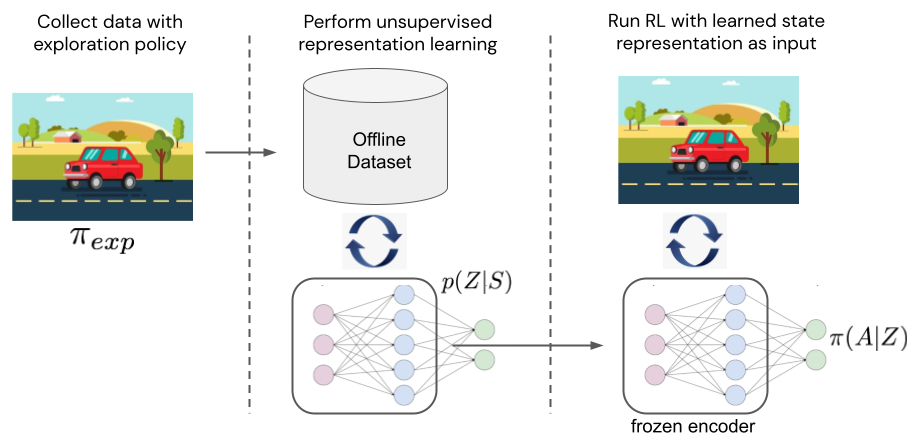
Determine 6. Experimental setup for evaluating realized representations.
We experiment with a easy online game MDP that has the same attribute to the self-driving automobile instance described earlier. On this recreation known as catcher, from the PyGame suite, the agent controls a paddle that it might probably transfer backwards and forwards to catch fruit that falls from the highest of the display screen (see Determine 7). A constructive reward is given when the fruit is caught and a unfavorable reward when the fruit will not be caught. The episode terminates after one piece of fruit falls. Analogous to the self-driving instance, the agent doesn’t management the place of the fruit, and so a illustration that maximizes $J_{inv}$ would possibly discard that data. Nonetheless, representing the fruit is essential to acquiring reward, for the reason that agent should transfer the paddle beneath the fruit to catch it. We be taught representations with $J_{inv}$ and $J_{fwd}$, optimizing $J_{fwd}$ with noise contrastive estimation (NCE), and $J_{inv}$ by coaching an inverse mannequin through most chance. (For brevity, we omit experiments with $J_{state}$ on this submit – please see the paper!) To pick essentially the most compressed illustration from amongst people who maximize every goal, we apply an data bottleneck of the shape $min I(Z; S)$. We additionally evaluate to operating RL from scratch with the picture inputs, which we name “end-to-end.” For the RL algorithm, we use the Delicate Actor-Critic algorithm.

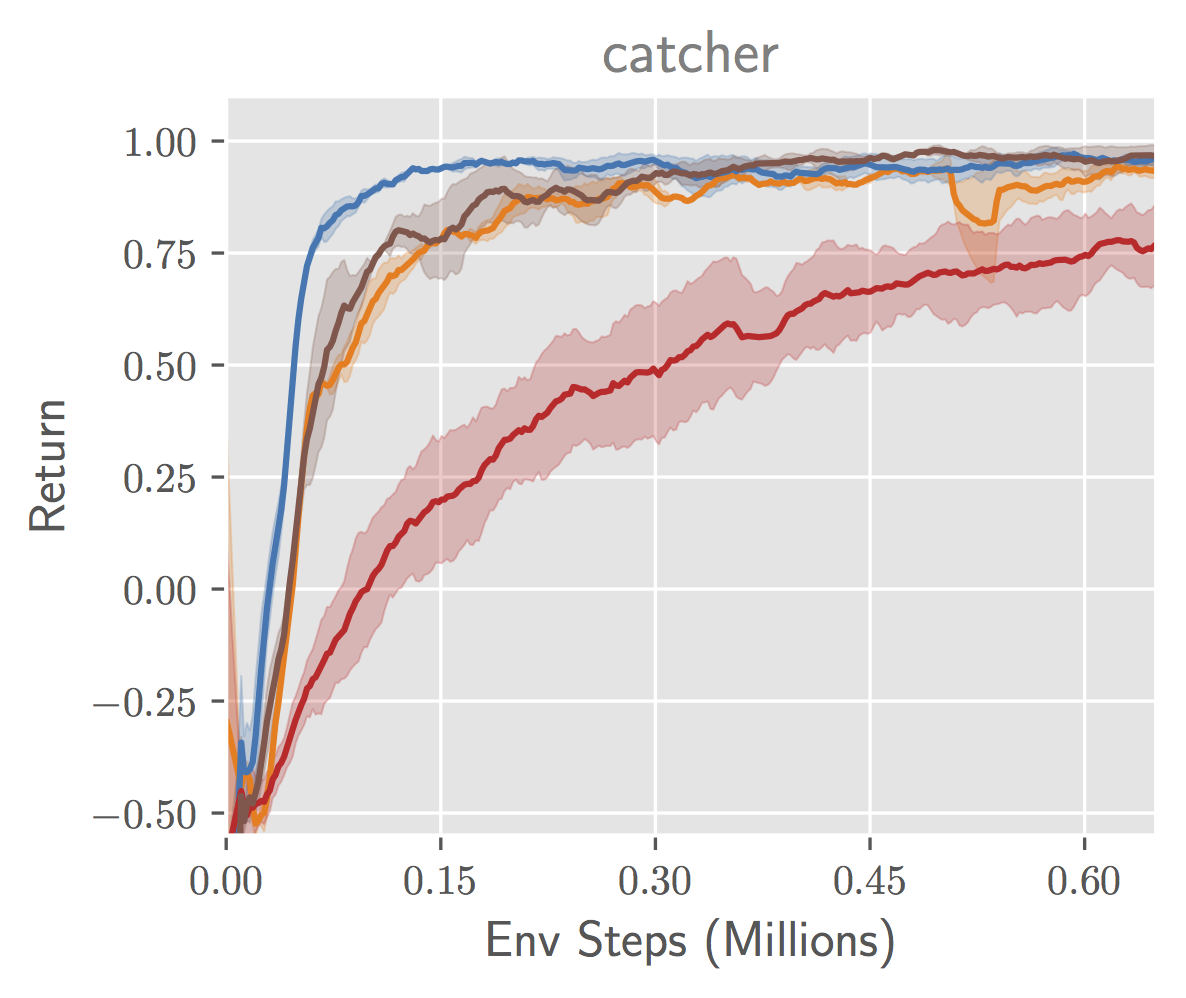
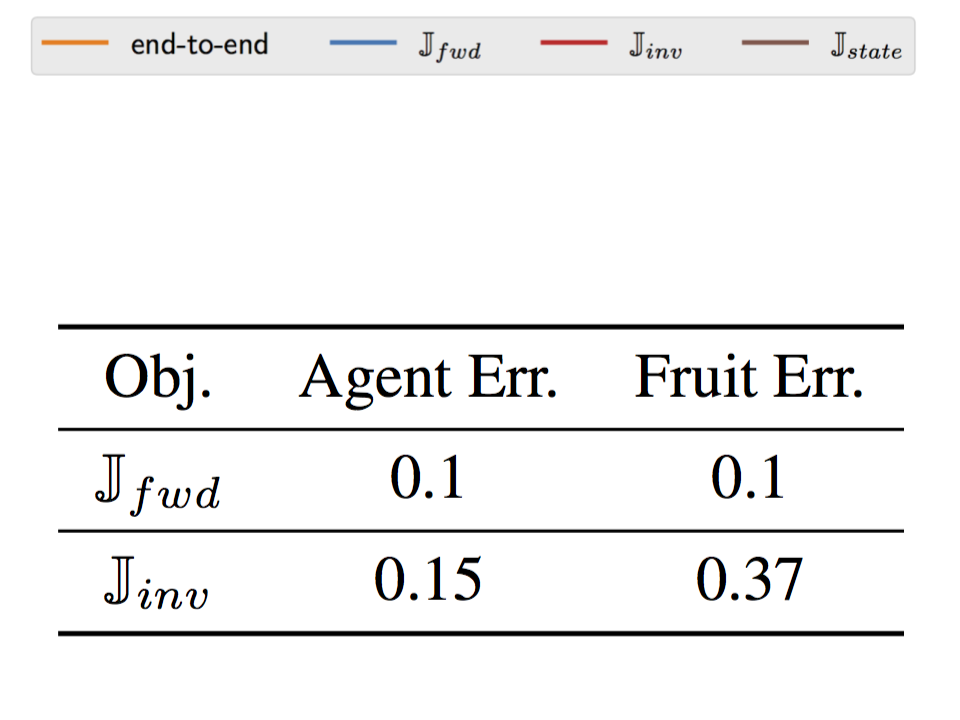
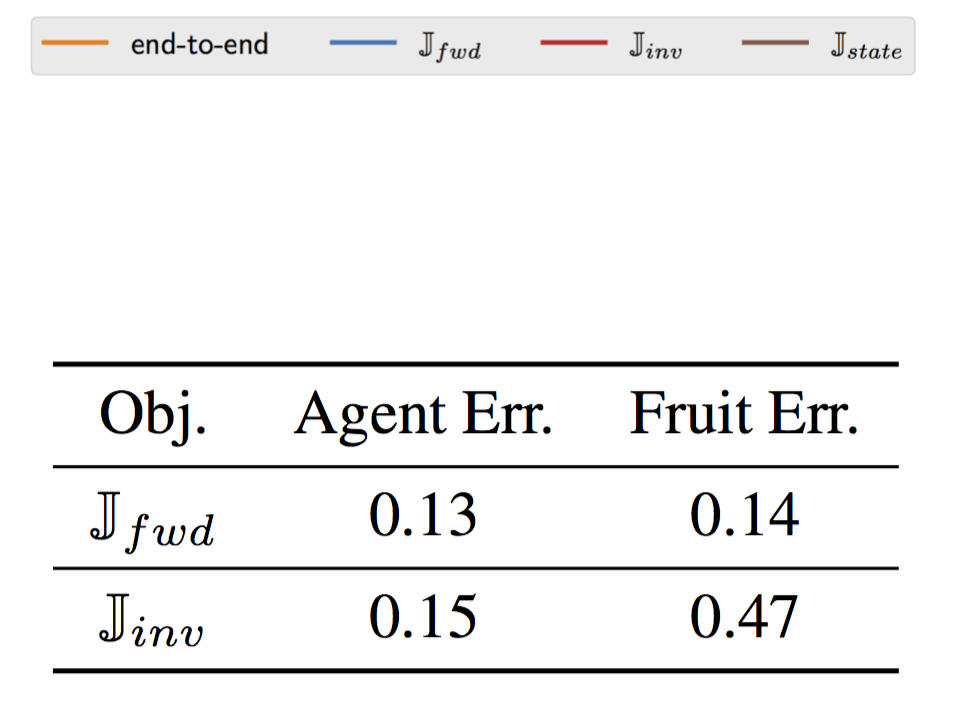
Determine 7. (left) Depiction of the catcher recreation. (center) Efficiency of RL brokers educated with totally different state representations. (proper) Accuracy of reconstructing floor reality state parts from realized representations.
We observe in Determine 7 (center) that certainly the illustration educated to maximise $J_{inv}$ leads to RL brokers that converge slower and to a decrease asymptotic anticipated return. To higher perceive what data the illustration incorporates, we then try to be taught a neural community decoder from the realized illustration to the place of the falling fruit. We report the imply error achieved by every illustration in Determine 7 (proper). The illustration realized by $J_{inv}$ incurs a excessive error, indicating that the fruit will not be exactly captured by the illustration, whereas the illustration realized by $J_{fwd}$ incurs low error.
Growing statement complexity with visible distractors
To make the illustration studying drawback more difficult, we repeat this experiment with visible distractors added to the agent’s observations. We randomly generate pictures of 10 circles of various colours and exchange the background of the sport with these pictures (see Determine 8, left, for instance observations). As within the earlier experiment, we plot the efficiency of an RL agent educated with the frozen illustration as enter (Determine 8, center), in addition to the error of decoding true state parts from the illustration (Determine 8, proper). The distinction in efficiency between ample ($J_{fwd}$) and inadequate ($J_{inv}$) goals is much more pronounced on this setting than within the plain background setting. With extra data current within the statement within the type of the distractors, inadequate goals that don’t optimize for representing all of the required state data could also be “distracted” by representing the background objects as a substitute, leading to low efficiency. On this more difficult case, end-to-end RL from pictures fails to make any progress on the duty, demonstrating the problem of end-to-end RL.
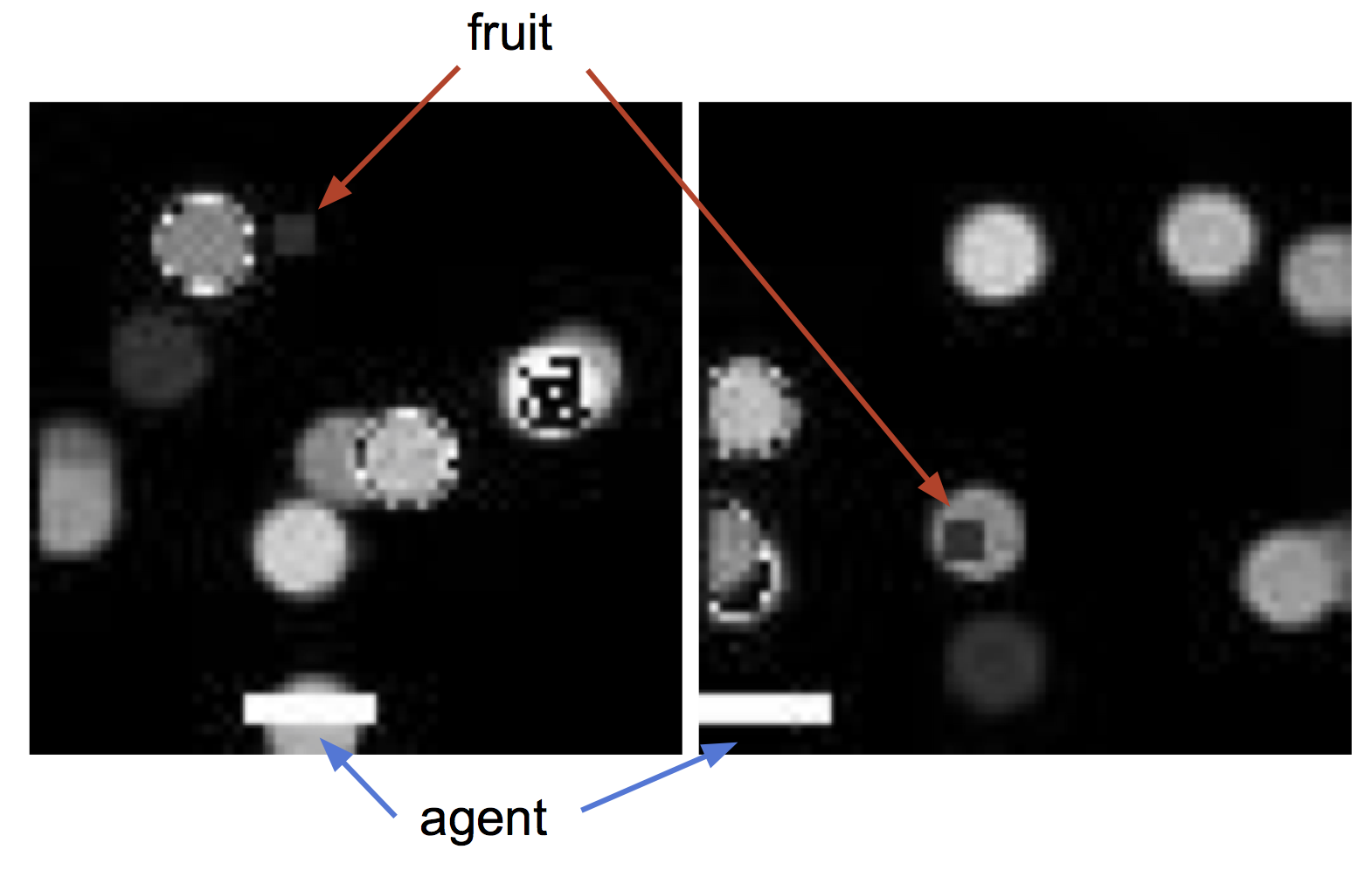
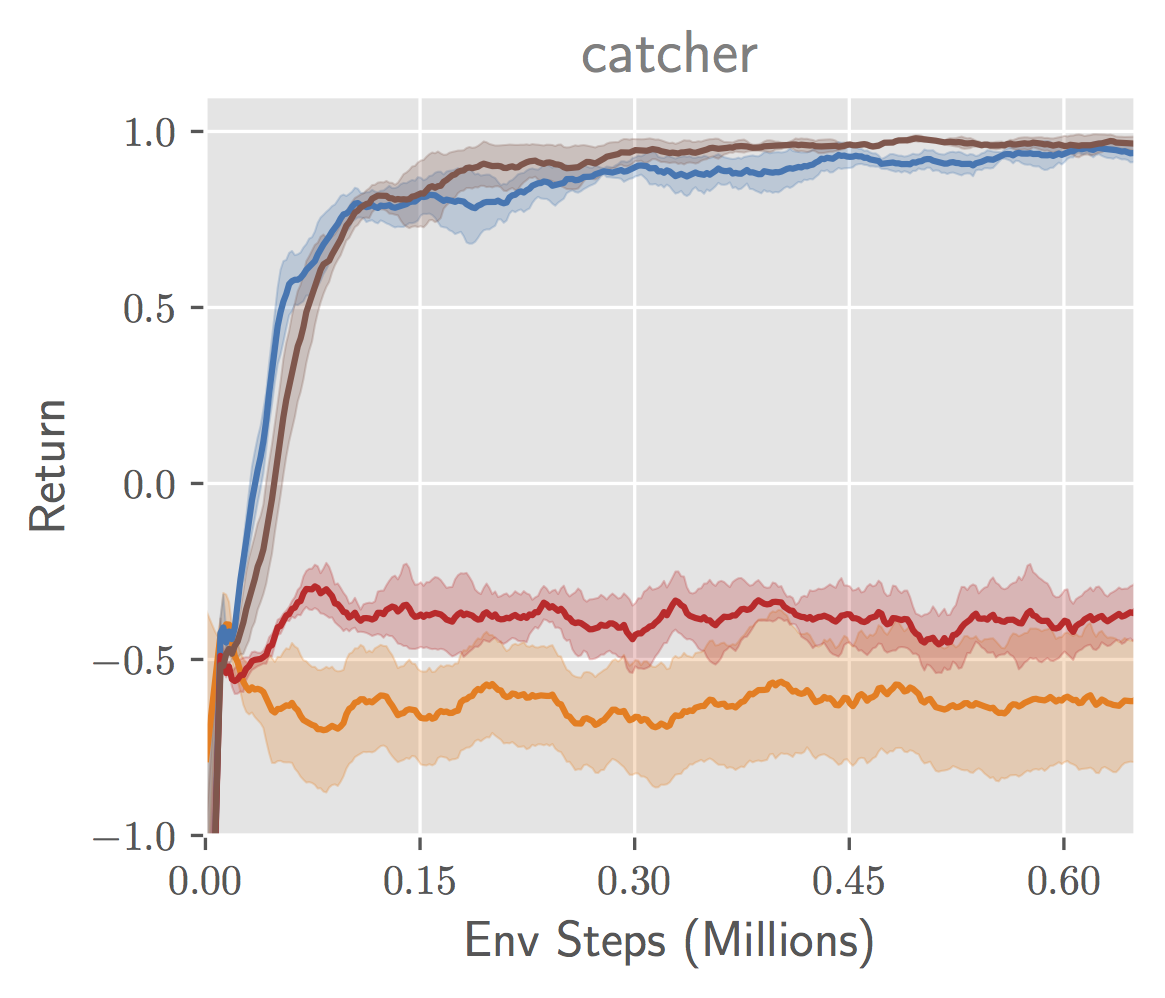
Determine 8. (left) Instance agent observations with distractors. (center) Efficiency of RL brokers educated with totally different state representations. (proper) Accuracy of reconstructing floor reality state parts from state representations.
Conclusion
These outcomes spotlight an vital open drawback: how can we design illustration studying goals that yield representations which might be each as lossy as attainable and nonetheless ample for the duties at hand?
With out additional assumptions on the MDP construction or data of the reward perform, is it attainable to design an goal that yields ample representations which might be lossier than these realized by $J_{fwd}$?
Can we characterize the set of MDPs for which inadequate goals $J_{inv}$ and $J_{state}$ can be ample?
Additional, extending the proposed framework to partially noticed issues can be extra reflective of real looking functions. On this setting, analyzing generative fashions similar to VAEs when it comes to sufficiency is an fascinating drawback. Prior work has proven that maximizing the ELBO alone can not management the content material of the realized illustration (e.g., Alemi et al. 2018). We conjecture that the zero-distortion maximizer of the ELBO can be ample, whereas different options needn’t be. Total, we hope that our proposed framework can drive analysis in designing higher algorithms for unsupervised illustration studying for RL.
This submit is predicated on the paper Which Mutual Data Illustration Studying Goals are Ample for Management?, to be offered at Neurips 2021. Thanks to Sergey Levine and Abhishek Gupta for his or her precious suggestions on this weblog submit.
[ad_2]