

{kind=link}
[ad_1]
Python is a wonderful software to automate repetitive duties in addition to achieve further insights into knowledge.
On this article, you’ll discover ways to construct a software to verify which key phrases are near rating in positions one to 3 and advises whether or not there is a chance to naturally work these key phrases into the web page.
It’s good for Python novices and execs alike and is a good introduction to utilizing Python for website positioning.
Should you’d identical to to get caught in there’s a useful Streamlit app obtainable for the code. That is easy to make use of and requires no coding expertise.
There’s additionally a Google Colaboratory Sheet in case you’d prefer to poke round with the code. Should you can crawl a web site, you need to use this script!
Right here’s an instance of what we’ll be making in the present day:
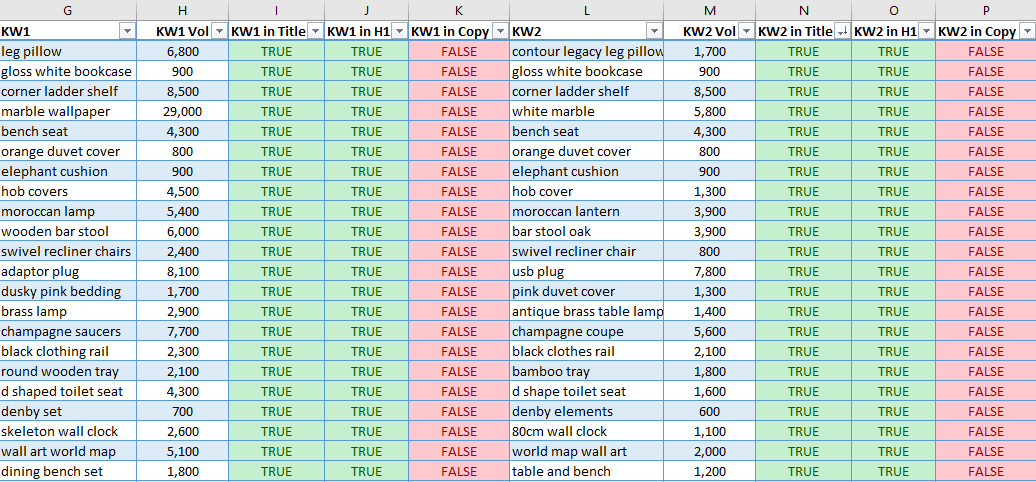 Screenshot from Microsoft Excel, October 2021
Screenshot from Microsoft Excel, October 2021These key phrases are discovered within the web page title and H1, however not within the copy. Including these key phrases naturally to the prevailing copy can be a simple solution to improve relevancy for these key phrases.
By taking the trace from engines like google and naturally together with any lacking key phrases a website already ranks for, we improve the boldness of engines like google to rank these key phrases greater within the SERPs.
This report could be created manually, however it’s fairly time-consuming.
So, we’re going to automate the method utilizing a Python website positioning script.
Preview Of The Output
It is a pattern of what the ultimate output will seem like after working the report:
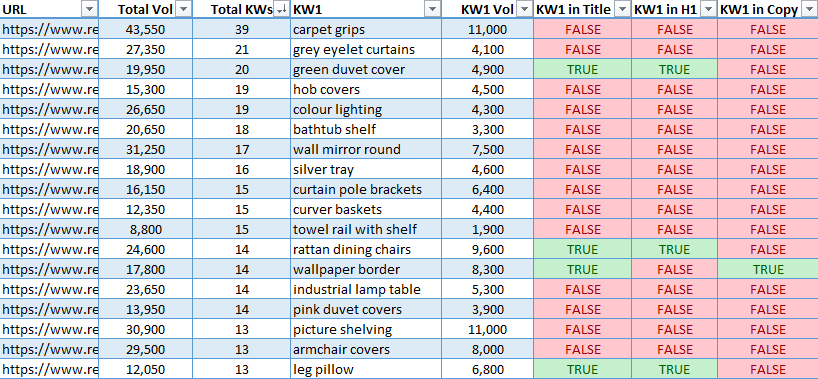 Screenshot from Microsoft Excel, October 2021
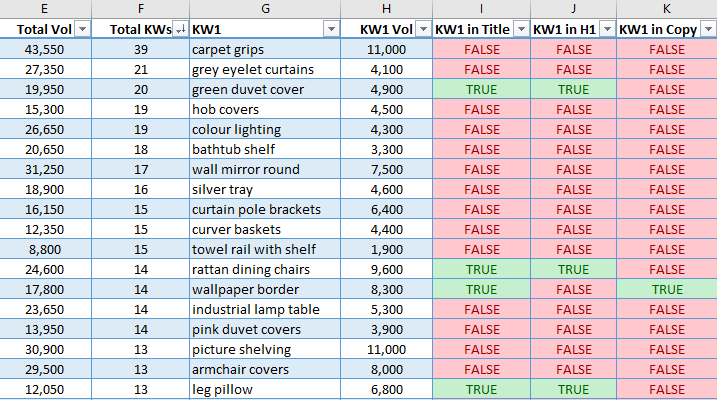
Screenshot from Microsoft Excel, October 2021The ultimate output takes the highest 5 alternatives by search quantity for every web page and neatly lays every one horizontally together with the estimated search quantity.
It additionally exhibits the entire search quantity of all key phrases a web page has inside placing distance, in addition to the entire variety of key phrases inside attain.
The highest 5 key phrases by search quantity are then checked to see if they’re discovered within the title, H1, or copy, then flagged TRUE or FALSE.
That is nice for locating fast wins! Simply add the lacking key phrase naturally into the web page copy, title, or H1.
Getting Began
The setup is pretty easy. We simply want a crawl of the location (ideally with a customized extraction for the copy you’d prefer to verify), and an exported file of all key phrases a website ranks for.
This put up will stroll you thru the setup, the code, and can hyperlink to a Google Colaboratory sheet in case you simply wish to get caught in with out coding it your self.
To get began you’ll need:
We’ve named this the Putting Distance Report because it flags key phrases which might be simply inside placing distance.
(We have now outlined placing distance as key phrases that rank in positions 4 to twenty, however have made this a configurable choice in case you wish to outline your individual parameters.)
Putting Distance website positioning Report: Getting Began
1. Crawl The Goal Web site
- Set a customized extractor for the web page copy (non-compulsory, however advisable).
- Filter out pagination pages from the crawl.
2. Export All Key phrases The Web site Ranks For Utilizing Your Favourite Supplier
- Filter key phrases that set off as a website hyperlink.
- Take away key phrases that set off as a picture.
- Filter branded key phrases.
- Use each exports to create an actionable Putting Distance report from the key phrase and crawl knowledge with Python.
Crawling The Web site
I’ve opted to make use of Screaming Frog to get the preliminary crawl. Any crawler will work, as long as the CSV export makes use of the identical column names or they’re renamed to match.
The script expects to seek out the next columns within the crawl CSV export:
"Deal with", "Title 1", "H1-1", "Copy 1", "Indexability"
Crawl Settings
The very first thing to do is to go over to the principle configuration settings inside Screaming Frog:
Configuration > Spider > Crawl
The primary settings to make use of are:
Crawl Inside Hyperlinks, Canonicals, and the Pagination (Rel Subsequent/Prev) setting.
(The script will work with every thing else chosen, however the crawl will take longer to finish!)
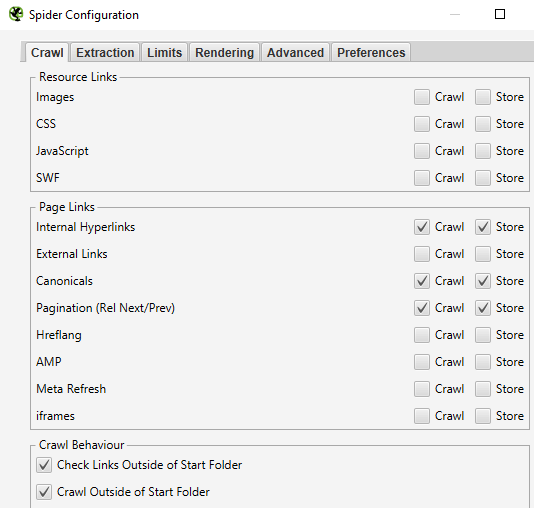 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021Subsequent, it’s on to the Extraction tab.
Configuration > Spider > Extraction
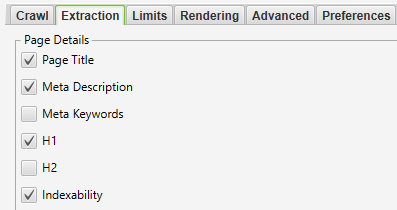 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021At a naked minimal, we have to extract the web page title, H1, and calculate whether or not the web page is indexable as proven under.
Indexability is beneficial as a result of it’s a simple method for the script to determine which URLs to drop in a single go, leaving solely key phrases which might be eligible to rank within the SERPs.
If the script can not discover the indexability column, it’ll nonetheless work as regular however received’t differentiate between pages that may and can’t rank.
Setting A Customized Extractor For Web page Copy
With a purpose to verify whether or not a key phrase is discovered throughout the web page copy, we have to set a customized extractor in Screaming Frog.
Configuration > Customized > Extraction
Identify the extractor “Copy” as seen under.
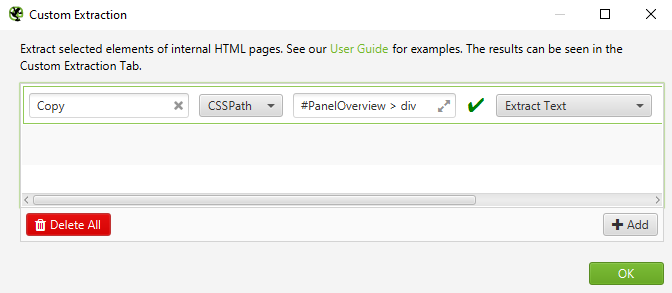 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021Necessary: The script expects the extractor to be named “Copy” as above, so please double verify!
Lastly, ensure that Extract Textual content is chosen to export the copy as textual content, fairly than HTML.
There are a lot of guides on utilizing customized extractors on-line in case you need assistance setting one up, so I received’t go over it once more right here.
As soon as the extraction has been set it’s time to crawl the location and export the HTML file in CSV format.
Exporting The CSV File
Exporting the CSV file is as simple as altering the drop-down menu displayed beneath Inside to HTML and urgent the Export button.
Inside > HTML > Export
 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021After clicking Export, It’s vital to verify the sort is ready to CSV format.
The export display ought to seem like the under:
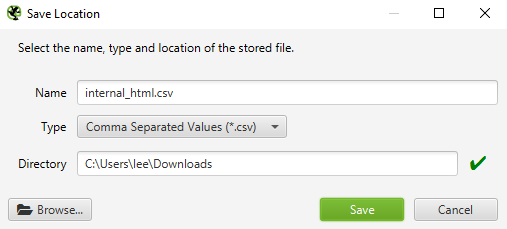 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021Tip 1: Filtering Out Pagination Pages
I like to recommend filtering out pagination pages out of your crawl both by deciding on Respect Subsequent/Prev underneath the Superior settings (or simply deleting them from the CSV file, in case you choose).
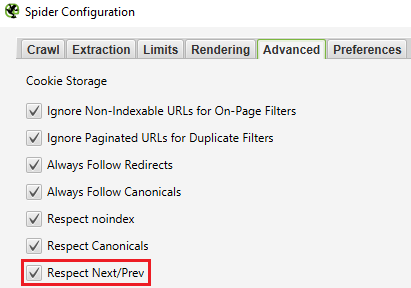 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021Tip 2: Saving The Crawl Settings
After you have set the crawl up, it’s value simply saving the crawl settings (which may even keep in mind the customized extraction).
This can save a whole lot of time if you wish to use the script once more sooner or later.
File > Configuration > Save As
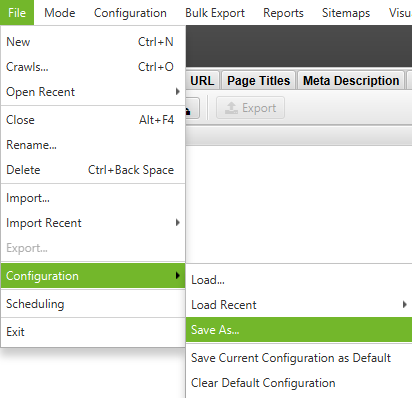 Screenshot from Screaming Frog, October 2021
Screenshot from Screaming Frog, October 2021Exporting Key phrases
As soon as we have now the crawl file, the subsequent step is to load your favourite key phrase analysis software and export all the key phrases a website ranks for.
The objective right here is to export all of the key phrases a website ranks for, filtering out branded key phrases and any which triggered as a sitelink or picture.
For this instance, I’m utilizing the Natural Key phrase Report in Ahrefs, however it’ll work simply as effectively with Semrush if that’s your most popular software.
In Ahrefs, enter the area you’d prefer to verify in Web site Explorer and select Natural Key phrases.
 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021Web site Explorer > Natural Key phrases
 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021This can convey up all key phrases the location is rating for.
Filtering Out Sitelinks And Picture hyperlinks
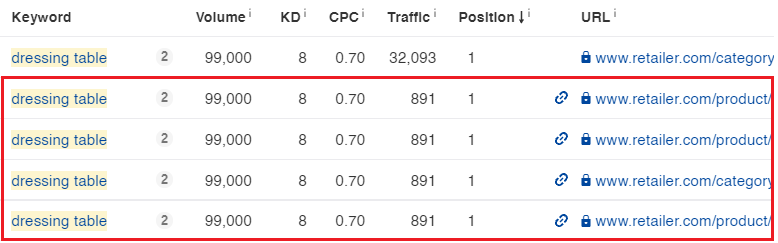
The following step is to filter out any key phrases triggered as a sitelink or a picture pack.
The rationale we have to filter out sitelinks is that they haven’t any affect on the father or mother URL rating. It’s because solely the father or mother web page technically ranks for the key phrase, not the sitelink URLs displayed underneath it.
Filtering out sitelinks will be certain that we’re optimizing the proper web page.
 Screenshot from Ahrefs.com, October 2021
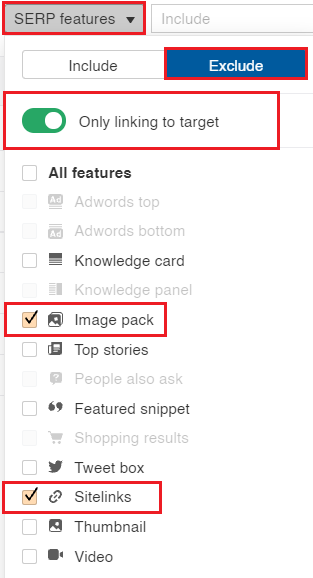
Screenshot from Ahrefs.com, October 2021Right here’s tips on how to do it in Ahrefs.
 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021Lastly, I like to recommend filtering out any branded key phrases. You are able to do this by filtering the CSV output straight, or by pre-filtering within the key phrase software of your alternative earlier than the export.
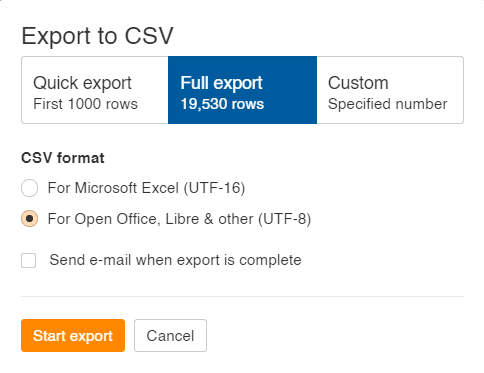
Lastly, when exporting ensure that to decide on Full Export and the UTF-8 format as proven under.
 Screenshot from Ahrefs.com, October 2021
Screenshot from Ahrefs.com, October 2021By default, the script works with Ahrefs (v1/v2) and Semrush key phrase exports. It may possibly work with any key phrase CSV file so long as the column names the script expects are current.
Processing
The next directions pertain to working a Google Colaboratory sheet to execute the code.
There’s now an easier choice for people who choose it within the type of a Streamlit app. Merely observe the directions supplied to add your crawl and key phrase file.
Now that we have now our exported information, all that’s left to be performed is to add them to the Google Colaboratory sheet for processing.
Choose Runtime > Run all from the highest navigation to run all cells within the sheet.
 Screenshot from Colab.analysis.google.com, October 2021
Screenshot from Colab.analysis.google.com, October 2021The script will immediate you to add the key phrase CSV from Ahrefs or Semrush first and the crawl file afterward.

That’s it! The script will mechanically obtain an actionable CSV file you need to use to optimize your website.
 Screenshot from Microsoft Excel, October 2021
Screenshot from Microsoft Excel, October 2021When you’re aware of the entire course of, utilizing the script is basically easy.
Code Breakdown And Clarification
Should you’re studying Python for website positioning and concerned about what the code is doing to provide the report, stick round for the code walkthrough!
Set up The Libraries
Let’s set up pandas to get the ball rolling.
!pip set up pandas
Import The Modules
Subsequent, we have to import the required modules.
import pandas as pd from pandas import DataFrame, Collection from typing import Union from google.colab import information
Set The Variables
Now it’s time to set the variables.
The script considers any key phrases between positions 4 and 20 as inside placing distance.
Altering the variables right here will allow you to outline your individual vary if desired. It’s value experimenting with the settings to get the very best output to your wants.
# set all variables right here min_volume = 10 # set the minimal search quantity min_position = 4 # set the minimal place / default = 4 max_position = 20 # set the utmost place / default = 20 drop_all_true = True # If all checks (h1/title/copy) are true, take away the advice (Nothing to do) pagination_filters = "filterby|web page|p=" # filter patterns used to detect and drop paginated pages
Add The Key phrase Export CSV File
The following step is to learn within the listing of key phrases from the CSV file.
It’s set as much as settle for an Ahrefs report (V1 and V2) in addition to a Semrush export.
This code reads within the CSV file right into a Pandas DataFrame.
add = information.add()
add = listing(add.keys())[0]
df_keywords = pd.read_csv(
(add),
error_bad_lines=False,
low_memory=False,
encoding="utf8",
dtype={
"URL": "str",
"Key phrase": "str",
"Quantity": "str",
"Place": int,
"Present URL": "str",
"Search Quantity": int,
},
)
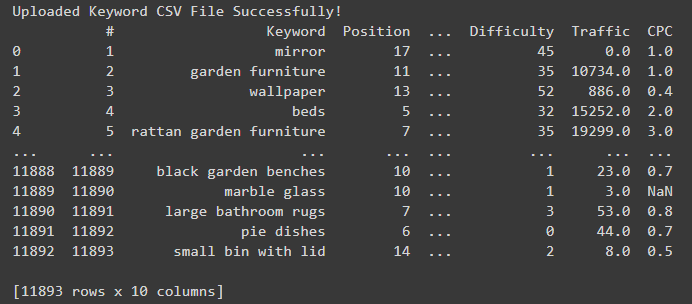
print("Uploaded Key phrase CSV File Efficiently!")
If every thing went to plan, you’ll see a preview of the DataFrame created from the key phrase CSV export.
 Screenshot from Colab.analysis.google.com, October 2021
Screenshot from Colab.analysis.google.com, October 2021Add The Crawl Export CSV File
As soon as the key phrases have been imported, it’s time to add the crawl file.
This pretty easy piece of code reads within the crawl with some error dealing with choice and creates a Pandas DataFrame named df_crawl.
add = information.add()
add = listing(add.keys())[0]
df_crawl = pd.read_csv(
(add),
error_bad_lines=False,
low_memory=False,
encoding="utf8",
dtype="str",
)
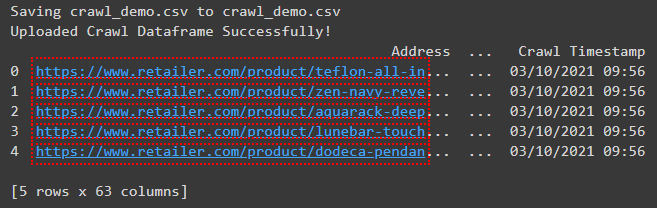
print("Uploaded Crawl Dataframe Efficiently!")
As soon as the CSV file has completed importing, you’ll see a preview of the DataFrame.
 Screenshot from Colab.analysis.google.com, October 2021
Screenshot from Colab.analysis.google.com, October 2021Clear And Standardize The Key phrase Knowledge
The following step is to rename the column names to make sure standardization between the commonest kinds of file exports.
Basically, we’re getting the key phrase DataFrame into an excellent state and filtering utilizing cutoffs outlined by the variables.
df_keywords.rename(
columns={
"Present place": "Place",
"Present URL": "URL",
"Search Quantity": "Quantity",
},
inplace=True,
)
# hold solely the next columns from the key phrase dataframe
cols = "URL", "Key phrase", "Quantity", "Place"
df_keywords = df_keywords.reindex(columns=cols)
attempt:
# clear the info. (v1 of the ahrefs key phrase export combines strings and ints within the quantity column)
df_keywords["Volume"] = df_keywords["Volume"].str.exchange("0-10", "0")
besides AttributeError:
go
# clear the key phrase knowledge
df_keywords = df_keywords[df_keywords["URL"].notna()] # take away any lacking values
df_keywords = df_keywords[df_keywords["Volume"].notna()] # take away any lacking values
df_keywords = df_keywords.astype({"Quantity": int}) # change knowledge kind to int
df_keywords = df_keywords.sort_values(by="Quantity", ascending=False) # kind by highest vol to maintain the highest alternative
# make new dataframe to merge search quantity again in later
df_keyword_vol = df_keywords[["Keyword", "Volume"]]
# drop rows if minimal search quantity does not match specified standards
df_keywords.loc[df_keywords["Volume"] < min_volume, "Volume_Too_Low"] = "drop"
df_keywords = df_keywords[~df_keywords["Volume_Too_Low"].isin(["drop"])]
# drop rows if minimal search place does not match specified standards
df_keywords.loc[df_keywords["Position"] <= min_position, "Position_Too_High"] = "drop"
df_keywords = df_keywords[~df_keywords["Position_Too_High"].isin(["drop"])]
# drop rows if most search place does not match specified standards
df_keywords.loc[df_keywords["Position"] >= max_position, "Position_Too_Low"] = "drop"
df_keywords = df_keywords[~df_keywords["Position_Too_Low"].isin(["drop"])]
Clear And Standardize The Crawl Knowledge
Subsequent, we have to clear and standardize the crawl knowledge.
Basically, we use reindex to solely hold the “Deal with,” “Indexability,” “Web page Title,” “H1-1,” and “Copy 1” columns, discarding the remainder.
We use the useful “Indexability” column to solely hold rows which might be indexable. This can drop canonicalized URLs, redirects, and so forth. I like to recommend enabling this selection within the crawl.
Lastly, we standardize the column names in order that they’re a little bit nicer to work with.
# hold solely the next columns from the crawl dataframe
cols = "Deal with", "Indexability", "Title 1", "H1-1", "Copy 1"
df_crawl = df_crawl.reindex(columns=cols)
# drop non-indexable rows
df_crawl = df_crawl[~df_crawl["Indexability"].isin(["Non-Indexable"])]
# standardise the column names
df_crawl.rename(columns={"Deal with": "URL", "Title 1": "Title", "H1-1": "H1", "Copy 1": "Copy"}, inplace=True)
df_crawl.head()
Group The Key phrases
As we method the ultimate output, it’s essential to group our key phrases collectively to calculate the entire alternative for every web page.
Right here, we’re calculating what number of key phrases are inside placing distance for every web page, together with the mixed search quantity.
# teams the URLs (take away the dupes and combines stats)
# make a replica of the key phrases dataframe for grouping - this ensures stats could be merged again in later from the OG df
df_keywords_group = df_keywords.copy()
df_keywords_group["KWs in Striking Dist."] = 1 # used to depend the variety of key phrases in placing distance
df_keywords_group = (
df_keywords_group.groupby("URL")
.agg({"Quantity": "sum", "KWs in Putting Dist.": "depend"})
.reset_index()
)
df_keywords_group.head()
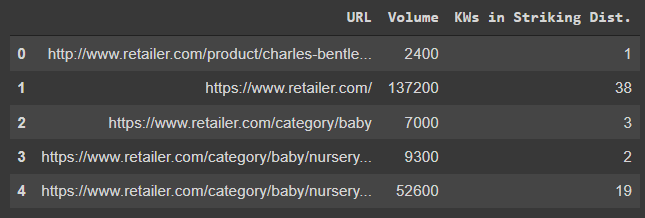 Screenshot from Colab.analysis.google.com, October 2021
Screenshot from Colab.analysis.google.com, October 2021As soon as full, you’ll see a preview of the DataFrame.
Show Key phrases In Adjoining Rows
We use the grouped knowledge as the premise for the ultimate output. We use Pandas.unstack to reshape the DataFrame to show the key phrases within the fashion of a GrepWords export.
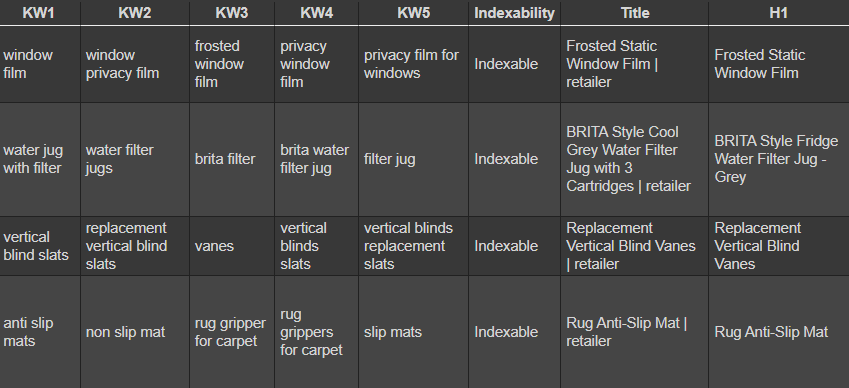 Screenshot from Colab.analysis.google.com, October 2021
Screenshot from Colab.analysis.google.com, October 2021# create a brand new df, mix the merged knowledge with the unique knowledge. show in adjoining rows ala grepwords
df_merged_all_kws = df_keywords_group.merge(
df_keywords.groupby("URL")["Keyword"]
.apply(lambda x: x.reset_index(drop=True))
.unstack()
.reset_index()
)
# kind by largest alternative
df_merged_all_kws = df_merged_all_kws.sort_values(
by="KWs in Putting Dist.", ascending=False
)
# reindex the columns to maintain simply the highest 5 key phrases
cols = "URL", "Quantity", "KWs in Putting Dist.", 0, 1, 2, 3, 4
df_merged_all_kws = df_merged_all_kws.reindex(columns=cols)
# create union and rename the columns
df_striking: Union[Series, DataFrame, None] = df_merged_all_kws.rename(
columns={
"Quantity": "Putting Dist. Vol",
0: "KW1",
1: "KW2",
2: "KW3",
3: "KW4",
4: "KW5",
}
)
# merges placing distance df with crawl df to merge within the title, h1 and class description
df_striking = pd.merge(df_striking, df_crawl, on="URL", how="internal")
Set The Ultimate Column Order And Insert Placeholder Columns
Lastly, we set the ultimate column order and merge within the authentic key phrase knowledge.
There are a whole lot of columns to kind and create!
# set the ultimate column order and merge the key phrase knowledge in
cols = [
"URL",
"Title",
"H1",
"Copy",
"Striking Dist. Vol",
"KWs in Striking Dist.",
"KW1",
"KW1 Vol",
"KW1 in Title",
"KW1 in H1",
"KW1 in Copy",
"KW2",
"KW2 Vol",
"KW2 in Title",
"KW2 in H1",
"KW2 in Copy",
"KW3",
"KW3 Vol",
"KW3 in Title",
"KW3 in H1",
"KW3 in Copy",
"KW4",
"KW4 Vol",
"KW4 in Title",
"KW4 in H1",
"KW4 in Copy",
"KW5",
"KW5 Vol",
"KW5 in Title",
"KW5 in H1",
"KW5 in Copy",
]
# re-index the columns to position them in a logical order + inserts new clean columns for kw checks.
df_striking = df_striking.reindex(columns=cols)
Merge In The Key phrase Knowledge For Every Column
This code merges the key phrase quantity knowledge again into the DataFrame. It’s roughly the equal of an Excel VLOOKUP perform.
# merge in key phrase knowledge for every key phrase column (KW1 - KW5) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW1", right_on="Key phrase", how="left") df_striking['KW1 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW2", right_on="Key phrase", how="left") df_striking['KW2 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW3", right_on="Key phrase", how="left") df_striking['KW3 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW4", right_on="Key phrase", how="left") df_striking['KW4 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True) df_striking = pd.merge(df_striking, df_keyword_vol, left_on="KW5", right_on="Key phrase", how="left") df_striking['KW5 Vol'] = df_striking['Volume'] df_striking.drop(['Keyword', 'Volume'], axis=1, inplace=True)
Clear The Knowledge Some Extra
The information requires further cleansing to populate empty values, (NaNs), as empty strings. This improves the readability of the ultimate output by creating clean cells, as a substitute of cells populated with NaN string values.
Subsequent, we convert the columns to lowercase in order that they match when checking whether or not a goal key phrase is featured in a particular column.
# exchange nan values with empty strings
df_striking = df_striking.fillna("")
# drop the title, h1 and class description to decrease case so kws could be matched to them
df_striking["Title"] = df_striking["Title"].str.decrease()
df_striking["H1"] = df_striking["H1"].str.decrease()
df_striking["Copy"] = df_striking["Copy"].str.decrease()
Test Whether or not The Key phrase Seems In The Title/H1/Copy and Return True Or False
This code checks if the goal key phrase is discovered within the web page title/H1 or copy.
It’ll flag true or false relying on whether or not a key phrase was discovered throughout the on-page components.
df_striking["KW1 in Title"] = df_striking.apply(lambda row: row["KW1"] in row["Title"], axis=1) df_striking["KW1 in H1"] = df_striking.apply(lambda row: row["KW1"] in row["H1"], axis=1) df_striking["KW1 in Copy"] = df_striking.apply(lambda row: row["KW1"] in row["Copy"], axis=1) df_striking["KW2 in Title"] = df_striking.apply(lambda row: row["KW2"] in row["Title"], axis=1) df_striking["KW2 in H1"] = df_striking.apply(lambda row: row["KW2"] in row["H1"], axis=1) df_striking["KW2 in Copy"] = df_striking.apply(lambda row: row["KW2"] in row["Copy"], axis=1) df_striking["KW3 in Title"] = df_striking.apply(lambda row: row["KW3"] in row["Title"], axis=1) df_striking["KW3 in H1"] = df_striking.apply(lambda row: row["KW3"] in row["H1"], axis=1) df_striking["KW3 in Copy"] = df_striking.apply(lambda row: row["KW3"] in row["Copy"], axis=1) df_striking["KW4 in Title"] = df_striking.apply(lambda row: row["KW4"] in row["Title"], axis=1) df_striking["KW4 in H1"] = df_striking.apply(lambda row: row["KW4"] in row["H1"], axis=1) df_striking["KW4 in Copy"] = df_striking.apply(lambda row: row["KW4"] in row["Copy"], axis=1) df_striking["KW5 in Title"] = df_striking.apply(lambda row: row["KW5"] in row["Title"], axis=1) df_striking["KW5 in H1"] = df_striking.apply(lambda row: row["KW5"] in row["H1"], axis=1) df_striking["KW5 in Copy"] = df_striking.apply(lambda row: row["KW5"] in row["Copy"], axis=1)
Delete True/False Values If There Is No Key phrase
This can delete true/false values when there isn’t a key phrase adjoining.
# delete true / false values if there isn't a key phrase df_striking.loc[df_striking["KW1"] == "", ["KW1 in Title", "KW1 in H1", "KW1 in Copy"]] = "" df_striking.loc[df_striking["KW2"] == "", ["KW2 in Title", "KW2 in H1", "KW2 in Copy"]] = "" df_striking.loc[df_striking["KW3"] == "", ["KW3 in Title", "KW3 in H1", "KW3 in Copy"]] = "" df_striking.loc[df_striking["KW4"] == "", ["KW4 in Title", "KW4 in H1", "KW4 in Copy"]] = "" df_striking.loc[df_striking["KW5"] == "", ["KW5 in Title", "KW5 in H1", "KW5 in Copy"]] = "" df_striking.head()
Drop Rows If All Values == True
This configurable choice is basically helpful for decreasing the quantity of QA time required for the ultimate output by dropping the key phrase alternative from the ultimate output whether it is present in all three columns.
def true_dropper(col1, col2, col3):
drop = df_striking.drop(
df_striking[
(df_striking[col1] == True)
& (df_striking[col2] == True)
& (df_striking[col3] == True)
].index
)
return drop
if drop_all_true == True:
df_striking = true_dropper("KW1 in Title", "KW1 in H1", "KW1 in Copy")
df_striking = true_dropper("KW2 in Title", "KW2 in H1", "KW2 in Copy")
df_striking = true_dropper("KW3 in Title", "KW3 in H1", "KW3 in Copy")
df_striking = true_dropper("KW4 in Title", "KW4 in H1", "KW4 in Copy")
df_striking = true_dropper("KW5 in Title", "KW5 in H1", "KW5 in Copy")
Obtain The CSV File
The final step is to obtain the CSV file and begin the optimization course of.
df_striking.to_csv('Key phrases in Putting Distance.csv', index=False)
information.obtain("Key phrases in Putting Distance.csv")
Conclusion
In case you are searching for fast wins for any web site, the placing distance report is a very easy solution to discover them.
Don’t let the variety of steps idiot you. It’s not as advanced because it appears. It’s so simple as importing a crawl and key phrase export to the equipped Google Colab sheet or utilizing the Streamlit app.
The outcomes are positively value it!
Extra Assets:
Featured Picture: aurielaki/Shutterstock
[ad_2]