

{kind=link}
[ad_1]
Cross-posted from Bounded Remorse.
Earlier this yr, my analysis group commissioned 6 questions for skilled forecasters to foretell about AI. Broadly talking, 2 have been on geopolitical facets of AI and 4 have been on future capabilities:
- Geopolitical:
- How a lot bigger or smaller will the most important Chinese language ML experiment be in comparison with the most important U.S. ML experiment, as measured by quantity of compute used?
- How a lot computing energy can have been utilized by the most important non-incumbent (OpenAI, Google, DeepMind, FB, Microsoft), non-Chinese language group?
- Future capabilities:
- What is going to SOTA (state-of-the-art accuracy) be on the MATH dataset?
- What is going to SOTA be on the Huge Multitask dataset (a broad measure of specialised topic information, based mostly on highschool, faculty, {and professional} exams)?
- What would be the finest adversarially strong accuracy on CIFAR-10?
- What is going to SOTA be on One thing One thing v2? (A video recognition dataset)
Forecasters output a chance distribution over outcomes for 2022, 2023, 2024, and 2025. They’ve monetary incentives to supply correct forecasts; the rewards whole $5k per query ($30k whole) and payoffs are (near) a correct scoring rule, that means forecasters are rewarded for outputting calibrated possibilities.
Relying on who you’re, you might need any of a number of questions:
- What the heck is an expert forecaster?
- Has this type of factor been completed earlier than?
- What do the forecasts say?
- Why did we select these questions?
- What classes did we be taught?
You’re in luck, as a result of I’m going to reply every of those within the following sections! Be happy to skim to those that curiosity you essentially the most.
And earlier than going into element, right here have been my largest takeaways from doing this:
- Projected progress on math and on broad specialised information are each sooner than I might have anticipated. I now anticipate extra progress in AI over the subsequent 4 years than I did beforehand.
- The relative dominance of the U.S. vs. China is unsure to an unsettling diploma. Forecasters are near 50-50 on who can have extra compute directed in direction of AI, though they do at the very least anticipate it to be inside an element of 10 both approach.
- It’s tough to give you forecasts that reliably monitor what you intuitively care about. Organizations would possibly cease reporting compute estimates for aggressive causes, which might confound each of the geopolitical metrics. They could equally cease publishing the SOTA efficiency of their finest fashions, or do it on a lag, which might confound the opposite metrics as properly. I focus on these and different points within the “Classes realized” part.
- Skilled forecasting appears actually priceless and underincentivized. (On that observe, I’m considering hiring forecasting consultants for my lab–please e-mail me should you’re !)
Acknowledgments. The actual questions have been designed by my college students Alex Wei, Collin Burns, Jean-Stanislas Denain, and Dan Hendrycks. Open Philanthropy supplied the funding for the forecasts, and Hypermind ran the forecasting competitors and constructed the mixture summaries that you simply see under. A number of folks supplied helpful suggestions on this submit, particularly Luke Muehlhauser and Emile Servan-Schreiber.
Skilled forecasters are people, or typically groups, who earn money by putting correct predictions in prediction markets or forecasting competitions. An excellent widespread remedy of that is Philip Tetlock’s guide Superforecasting, however the fundamental concept is that there are a variety of basic instruments and expertise that may enhance prediction capacity and forecasters who observe these normally outperform even area consultants (although most robust forecasters have some technical background and can typically learn up on the area they’re predicting in). Traditionally, many forecasts have been about geopolitical occasions (maybe reflecting authorities funding curiosity), however there have been latest forecasting competitions about Covid–19 and the way forward for meals, amongst others.
At this level, you is likely to be skeptical. Isn’t predicting the long run actually laborious, and mainly unattainable? An vital factor to comprehend right here is that forecasters normally output possibilities over outcomes, slightly than a single quantity. So whereas I most likely can’t inform you what US GDP might be in 2025, I can provide you a chance distribution. I’m personally fairly assured it is going to be greater than $700 billion and fewer than $700 trillion (it’s at the moment $21 trillion), though an expert forecaster would do significantly better than that.
There are a pair different vital factors right here. The primary is that forecasters’ chance distributions are sometimes considerably wider than the types of belongings you’d see pundits on TV say (in the event that they even hassle to enterprise a spread slightly than a single quantity). This displays the long run really being fairly unsure, however even a variety might be informative, and generally I see forecasted ranges which can be loads narrower than I anticipated.
The opposite level is that the majority forecasts are for at most a yr or two into the long run. Just lately there have been some experimental makes an attempt to forecast out to 2030, however I’m undecided we are able to say but how profitable they have been. Our personal forecasts exit to 2025, so we aren’t as bold because the 2030 experiments, however we’re nonetheless avant-garde in comparison with the standard 1-2 yr window. In case you’re considering what we at the moment know in regards to the feasibility of long-range forecasting, I like to recommend this detailed weblog submit by Luke Muehlhauser.
So, to summarize, an expert forecaster is somebody who’s paid to make correct probabilistic forecasts in regards to the future. Relative to pundits, they categorical considerably extra uncertainty. The moniker “skilled” is likely to be a misnomer, since most revenue comes from prizes and I’d guess that the majority forecasters have a day job that produces most of their revenue. I’d personally like to dwell in a world with actually skilled forecasters who might totally specialize on this vital ability.
Different forecasting competitions. Broadly, there are all kinds of forecasting competitions, typically hosted on Hypermind, Metaculus, or Good Judgment. There are additionally prediction markets (e.g. PredictIt), that are a bit completely different but additionally incentivize correct predictions. Particularly on AI, Metaculus had a latest AI prediction event, and Hypermind ran the identical questions on their very own platform (AI2023, AI2030). I’ll focus on under how a few of our questions relate to the AI2023 event specifically.
Listed here are the purpose estimate forecasts put collectively right into a single chart (expert-level is approximated as ~90%):
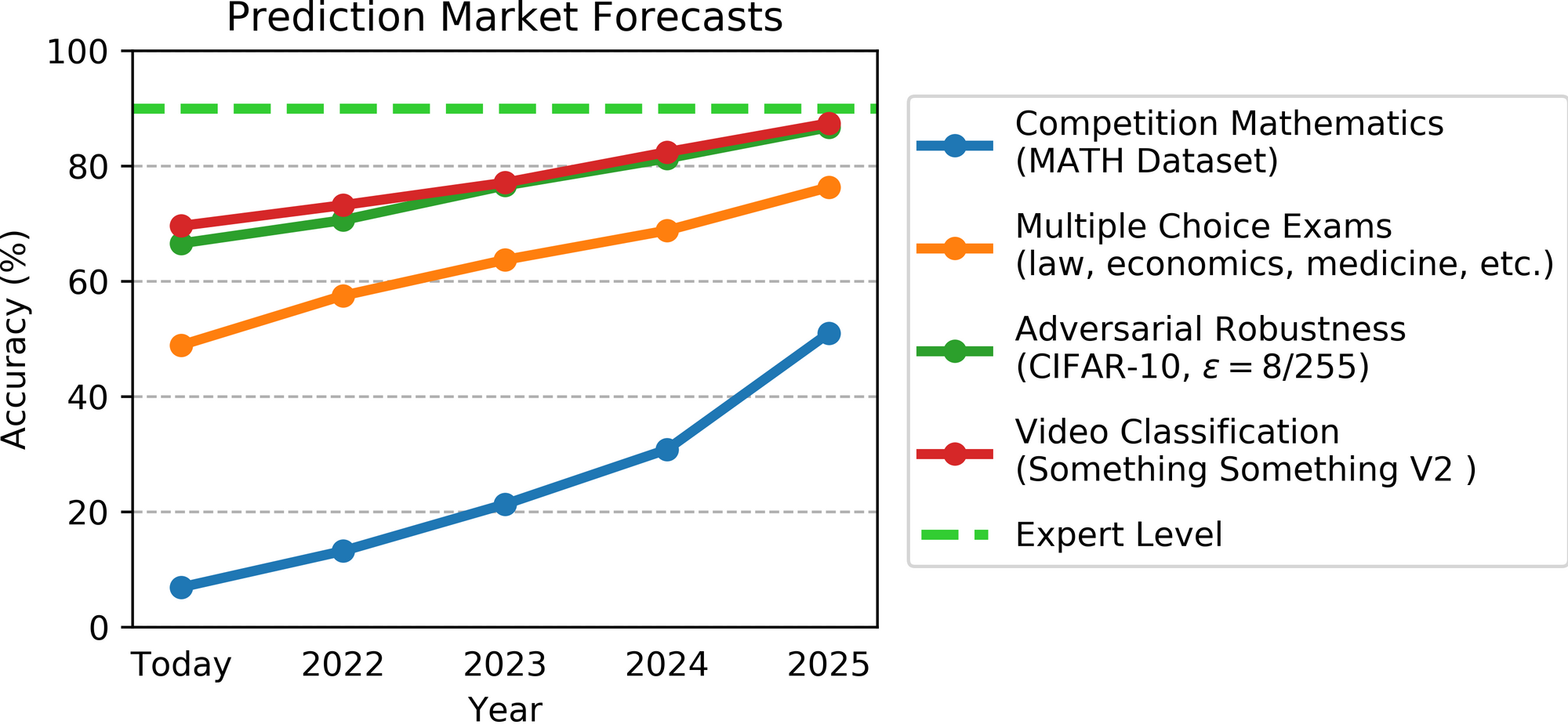
The MATH and Multitask outcomes have been essentially the most fascinating to me, as they predict speedy progress ranging from a low present-day baseline. I’ll focus on these intimately within the following subsections, after which summarize the opposite duties and forecasts.
To get a way of the uncertainty unfold, I’ve additionally included mixture outcomes under (for 2025) on every of the 6 questions; yow will discover the outcomes for different years right here. The mixture combines all crowd forecasts however locations increased weight on forecasters with a very good monitor report.






MATH
The MATH dataset consists of competitors math issues for highschool college students. A Berkeley PhD scholar obtained within the ~75% vary, whereas an IMO gold medalist obtained ~90%, however most likely would have gotten 100% with out arithmetic errors. The questions are free-response and never multiple-choice, and may comprise solutions resembling $frac{1 + sqrt{2}}{2}$.
Present efficiency on this dataset is sort of low–6.9%–and I anticipated this process to be fairly laborious for ML fashions within the close to future. Nonetheless, forecasters predict greater than 50% accuracy* by 2025! This was a giant replace for me. (*Extra particularly, their median estimate is 52%; the boldness vary is ~40% to 60%, however that is doubtlessly artifically slim as a consequence of some restrictions on how forecasts may very well be enter into the platform.)
To get some taste, listed below are 5 randomly chosen issues from the “Counting and Chance” class of the benchmark:
- What number of (non-congruent) isosceles triangles exist which have a fringe of 10 and integer aspect lengths?
- A buyer ordered 15 items of gourmand chocolate. The order might be packaged in small bins that comprise 1, 2 or 4 items of chocolate. Any field that’s used have to be full. What number of completely different mixtures of bins can be utilized for the shopper’s 15 chocolate items? One such mixture to be included is to make use of seven 2-piece bins and one 1-piece field.
- A theater group has eight members, of which 4 are females. What number of methods are there to assign the roles of a play that contain one feminine lead, one male lead, and three completely different objects that may be performed by both gender?
- What’s the worth of $101^{3} – 3 cdot 101^{2} + 3 cdot 101 -1$?
- 5 white balls and $ok$ black balls are positioned right into a bin. Two of the balls are drawn at random. The chance that one of many drawn balls is white and the opposite is black is $frac{10}{21}$. Discover the smallest potential worth of $ok$.
Listed here are 5 randomly chosen issues from the “Intermediate Algebra” class (I skipped one which concerned a diagram):
- Suppose that $x$, $y$, and $z$ fulfill the equations $xyz = 4$, $x^3 + y^3 + z^3 = 4$, $xy^2 + x^2 y + xz^2 + x^2 z + yz^2 + y^2 z = 12$. Calculate the worth of $xy + yz + zx$.
- If $|z| = 1$, categorical $overline{z}$ as a simplified fraction by way of $z$.
- Within the coordinate airplane, the graph of $|x + y – 1| + ||x| – x| + ||x – 1| + $ $x – 1| = 0$ is a sure curve. Discover the size of this curve.
- Let $alpha$, $beta$, $gamma$, and $delta$ be the roots of $x^4 + kx^2 + 90x – 2009 = 0$. If $alpha beta = 49$, discover $ok$.
- Let $tau = frac{1 + sqrt{5}}{2}$, the golden ratio. Then $frac{1}{tau} + frac{1}{tau^2} + frac{1}{tau^3} + dotsb = tau^n$ for some integer $n$. Discover $n$.
You’ll be able to see the entire questions at this git repo.
If I think about an ML system getting greater than half of those questions proper, I might be fairly impressed. In the event that they obtained 80% proper, I might be super-impressed. The forecasts themselves predict accelerating progress via 2025 (21% in 2023, then 31% in 2024 and 52% in 2025), so 80% by 2028 or so is in keeping with the expected development. This nonetheless simply appears wild to me and I’m actually curious how the forecasters are reasoning about this.
Multitask
The Huge Multitask dataset additionally consists of examination questions, however this time they’re a spread of highschool, faculty, {and professional} exams on 57 completely different topics, and these are a number of selection (4 reply decisions whole). Listed here are 5 instance questions:
- (Jurisprudence) Which place does Rawls declare is the least prone to be adopted by the POP (folks within the authentic place)?
- (A) The POP would select equality above liberty.
- (B) The POP would go for the ‘maximin’ technique.
- (C) The POP would go for the ‘distinction precept.’
- (D) The POP would reject the ‘system of pure liberty.
- (Philosophy) In accordance with Moore’s “superb utilitarianism,” the appropriate motion is the one which brings in regards to the best quantity of:
- (A) pleasure. (B) happiness. (C) good. (D) advantage.
- (School Drugs) In a genetic take a look at of a new child, a uncommon genetic dysfunction is discovered that has X-linked recessive transmission. Which of the next statements is probably going true relating to the pedigree of this dysfunction?
- (A) All descendants on the maternal aspect can have the dysfunction.
- (B) Females might be roughly twice as affected as males on this household.
- (C) All daughters of an affected male might be affected.
- (D) There might be equal distribution of women and men affected.
- (Conceptual Physics) A mannequin airplane flies slower when flying into the wind and sooner with wind at its again. When launched at proper angles to the wind, a cross wind, its groundspeed in contrast with flying in nonetheless air is
- (A) the identical (B) higher (C) much less (D) both higher or much less relying on wind velocity
- (Excessive Faculty Statistics) Jonathan obtained a rating of 80 on a statistics examination, putting him on the ninetieth percentile. Suppose 5 factors are added to everybody’s rating. Jonathan’s new rating might be on the
- (A) eightieth percentile.
- (B) eighty fifth percentile.
- (C) ninetieth percentile.
- (D) ninety fifth percentile.
In comparison with MATH, these contain considerably much less reasoning however extra world information. I don’t know the solutions to those questions (besides the final one), however I believe I might determine them out with entry to Google. In that sense, it might be much less mind-blowing if an ML system did properly on this process, though it might be carrying out an mental feat that I’d guess only a few people might accomplish unaided.
The precise forecast is that ML methods might be round 75% on this by 2025 (vary is roughly 70-85, with some right-tailed uncertainty). I don’t discover this as spectacular/wild because the MATH forecast, but it surely’s nonetheless fairly spectacular.
My general take from this process and the earlier one is that forecasters are fairly assured that we received’t have the singularity earlier than 2025, however on the similar time there might be demonstrated progress in ML that I might anticipate to persuade a major fraction of skeptics (within the sense that it’ll look untenable to carry positions that “Deep studying can’t do X”).
Lastly, to provide an instance of a few of the more durable kinds of questions (albeit not randomly chosen), listed below are two from Skilled Legislation and School Physics:
- (School Physics) One finish of a Nichrome wire of size 2L and cross-sectional space A is connected to an finish of one other Nichrome wire of size L and cross- sectional space 2A. If the free finish of the longer wire is at an electrical potential of 8.0 volts, and the free finish of the shorter wire is at an electrical potential of 1.0 volt, the potential on the junction of the 2 wires is most almost equal to
- (A) 2.4 V (B) 3.3 V (C) 4.5 V (D) 5.7 V
- (Skilled Legislation) The night time earlier than his bar examination, the examinee’s next-door neighbor was having a celebration. The music from the neighbor’s dwelling was so loud that the examinee couldn’t go to sleep. The examinee known as the neighbor and requested her to please preserve the noise down. The neighbor then abruptly hung up. Angered, the examinee went into his closet and obtained a gun. He went outdoors and fired a bullet via the neighbor’s lounge window. Not meaning to shoot anybody, the examinee fired his gun at such an angle that the bullet would hit the ceiling. He merely needed to trigger some injury to the neighbor’s dwelling to alleviate his indignant rage. The bullet, nevertheless, ricocheted off the ceiling and struck a partygoer within the again, killing him. The jurisdiction makes it a misdemeanor to discharge a firearm in public. The examinee will most certainly be discovered responsible for which of the next crimes in connection to the dying of the partygoer?
- (A) Homicide (B) Involuntary manslaughter (C) Voluntary manslaughter (D) Discharge of a firearm in public
You’ll be able to view all of the questions at this git repo.
Different questions
The opposite 4 questions weren’t fairly as stunning, so I’ll undergo them extra rapidly.
SOTA robustness: The forecasts anticipate constant progress at ~7% per yr. Looking back this one was most likely not too laborious to get simply from development extrapolation. (SOTA was 44% in 2018 and 66% in 2021, with smooth-ish progress in-between.)
US vs. China: Forecasters have vital uncertainty in each instructions, skewed in direction of the US being forward within the subsequent 2 years and China after that (seemingly primarily as a consequence of heavier-tailed uncertainty), however both one may very well be forward and as much as 10x the opposite. One problem in decoding that is that both nation would possibly cease publishing compute outcomes in the event that they view it as a aggressive benefit in nationwide safety (or particular person firms would possibly do the identical for aggressive causes).
Incumbents vs. remainder of area: forecasters anticipate newcomers to extend measurement by ~10x per yr for the subsequent 4 years, with a central estimate of 21 EF-days in 2023. Observe the AI2023 outcomes predict the most important experiment by anybody (not simply newcomers) to be 261EFLOP-s days in 2023, so this expects newcomers to be ~10x behind the incumbents, however only one yr behind. That is additionally an instance the place forecasters have vital uncertainty–newcomers in 2023 might simply be in single-digit EF-days, or at 75 EF-days. Looking back I want I had included Anthropic on the listing, as they’re a brand new “big-compute” org that may very well be driving some fraction of the outcomes, and who I wouldn’t have supposed to rely as a newcomer (since they exist already).
Video understanding: Forecasters anticipate us to hit 88% accuracy (vary: ~82%-95%) in 2025. As well as, they anticipate accuracy to extend at roughly 5%/yr (although this presumably has to degree off quickly after 2025). That is sooner than ImageNet, which has solely been growing at roughly 2%/yr. Looking back this was an “straightforward” prediction within the sense that accuracy has elevated by 14% from Jan’18 to Jan’21 (shut to five%/yr), however it’s also “daring” within the sense that progress since Jan’19 has been minimal. (Apparently forecasters are extra inclined to common over the longest out there time window.) When it comes to implications, video recognition is among the final remaining “instinctive” modalities that people are excellent at, aside from bodily duties (greedy, locomotion, and so on.). It appears like we’ll be fairly good at a “fundamental” model of it by 2025, for a process that I’d intuitively fee as much less complicated than ImageNet however about as complicated as CIFAR-100. Primarily based on imaginative and prescient and language I anticipate a further 4-5 years to grasp the “full” model of the duty, so anticipate ML to have largely mastered video by 2030. As earlier than, this concurrently argues towards “the singularity is close to” however for “surprisingly quick, extremely impactful progress”.
We appreciated the AI2023 questions (the earlier prediction contest), however felt there have been a pair classes that have been lacking. One was geopolitical (the primary 2 questions), however the different one was benchmarks that may be extremely informative about progress. The AI2023 problem contains forecasts about numerous benchmarks, e.g. Pascal, Cityscape, few-shot on Mini-ImageNet, and so on. However there aren’t ones the place, should you informed me we’d have a ton of progress on them by 2025, it might replace my mannequin of the world considerably. It’s because the duties included in AI2023 are largely within the regime the place NNs do fairly properly and I anticipate gradual progress to proceed. (I might have been stunned by the few-shot Mini-ImageNet numbers 3 years in the past, however not since GPT-3 confirmed that few-shot works properly at scale).
It’s not so stunning that the AI2023 benchmarks have been primarily ones that ML already does properly on, as a result of most ML benchmarks are created to be plausibly tractable. To allow extra fascinating forecasts, we created our personal “laborious” benchmarks the place vital progress can be stunning. This was the motivation behind the MATH and Multitask datasets (we created each of these ourselves). As talked about, I used to be fairly stunned by how optimistic forecasters have been on each duties, which up to date me downward a bit on the duty issue but additionally upward on how a lot progress we should always anticipate within the subsequent 4 years.
The opposite two benchmarks already existed however have been rigorously chosen. Strong accuracy on CIFAR was based mostly on the premise that adversarial robustness is actually laborious and we haven’t seen a lot progress–maybe it’s a very tough problem, which might be worrying if we care in regards to the security of AI methods. Forecasters as an alternative predicted regular progress, however looking back I might have seen this myself. Although adversarial robustness “feels” laborious (maybe as a result of I work on it and spend lots of time attempting to make it work higher), the precise year-on-year numbers confirmed a fairly clear 7%/yr enchancment.
The final process, video recognition, is an space that not many individuals work in at the moment, because it appears difficult in comparison with pictures (maybe as a consequence of {hardware} constraints). However it appears like we should always anticipate regular progress on it within the coming years.
It could possibly generally be surprisingly tough to formalize questions that monitor an intuitive amount you care about.
As an illustration, we initially needed to incorporate questions on financial impacts of AI, however have been unable to. As an illustration, we needed to ask “How a lot personal vs. public funding will there be in AI?” However this runs into the query of what counts as funding–Will we rely one thing like making use of information science to agriculture? In case you take a look at most metrics that you simply’d hope monitor this amount, they embrace all kinds of bizarre issues like that, and the bizarre issues most likely dominate the metric. We bumped into related points for indicators of AI-based automation–e.g. do industrial robots on meeting traces rely, even when they don’t use a lot AI? For a lot of financial variables, short-term results may additionally disort outcomes (funding would possibly drop due to a pandemic or different shock).
There have been different instances the place we did assemble a query, however needed to be cautious about framing. We initially thought of utilizing parameters slightly than compute for the 2 geopolitical questions, but it surely’s potential to realize actually excessive parameter counts in foolish methods and a few organizations would possibly even accomplish that for publicity (certainly we expect that is already taking place to some extent). Compute is more durable to faux in the identical approach.
As mentioned above, secrecy might cloud lots of the metrics we used. Some organizations may not publish compute numbers for aggressive causes, and the identical may very well be true of SOTA outcomes on leaderboards. That is extra seemingly if AI heats up considerably, so sadly I anticipate forecasts to be least dependable after we want them most. We might doubtlessly get round this subject by interrogating forecasters’ precise reasoning, slightly than simply the ultimate output.
I additionally got here to understand the worth of doing plenty of legwork to create a very good forecasting goal. The MATH dataset clearly was a lot of labor to assemble, however I’m actually glad we did as a result of it created the only largest replace for me. I believe future forecasting efforts ought to extra strongly take into account this lever.
Lastly, even whereas typically expressing vital uncertainty, forecasters could make daring predictions. I’m nonetheless stunned that forecasters predicted 52% on MATH, when present accuracy is 7% (!). My estimate would have had excessive uncertainty, however I’m undecided the highest finish of my vary would have included 50%. I assume the forecasters are proper and never me, however I’m actually curious how they obtained their numbers.
Due to the potential for such stunning outcomes, forecasting appears actually priceless. I hope that there’s vital future funding on this space. Each group that’s critical in regards to the future ought to have a resident or advisor forecaster. I’m placing my cash the place my mouth is and at the moment hiring forecasting consultants for my analysis group; please e-mail me if this sounds fascinating to you.
[ad_2]