

{kind=link}
[ad_1]
We suspected that knowledge high quality was a subject brimming with curiosity. These suspicions had been confirmed after we rapidly acquired greater than 1,900 responses to our mid-November survey request. The responses present a surfeit of issues round knowledge high quality and a few uncertainty about how finest to handle these issues.
Key survey outcomes:

Study quicker. Dig deeper. See farther.
- The C-suite is engaged with knowledge high quality. CxOs, vice presidents, and administrators account for 20% of all survey respondents. Information scientists and analysts, knowledge engineers, and the individuals who handle them comprise 40% of the viewers; builders and their managers, about 22%.
- Information high quality would possibly worsen earlier than it will get higher. Comparatively few organizations have created devoted knowledge high quality groups. Simply 20% of organizations publish knowledge provenance and knowledge lineage. Most of those that don’t say they haven’t any plans to start out.
- Adopting AI may help knowledge high quality. Nearly half (48%) of respondents say they use knowledge evaluation, machine studying, or AI instruments to handle knowledge high quality points. These respondents usually tend to floor and deal with latent knowledge high quality issues. Can AI be a catalyst for improved knowledge high quality?
- Organizations are coping with a number of, simultaneous knowledge high quality points. They’ve too many various knowledge sources and an excessive amount of inconsistent knowledge. They don’t have the assets they should clear up knowledge high quality issues. And that’s just the start.
- The constructing blocks of knowledge governance are sometimes missing inside organizations. These embrace the fundamentals, similar to metadata creation and administration, knowledge provenance, knowledge lineage, and different necessities.
The highest-line excellent news is that folks in any respect ranges of the enterprise appear to be alert to the significance of knowledge high quality. The highest-line unhealthy information is that organizations aren’t doing sufficient to handle their knowledge high quality points. They’re making do with insufficient—or non-existent—controls, instruments, and practices. They’re nonetheless fighting the fundamentals: tagging and labeling knowledge, creating (and managing) metadata, managing unstructured knowledge, and so on.
Respondent demographics
Analysts and engineers predominate
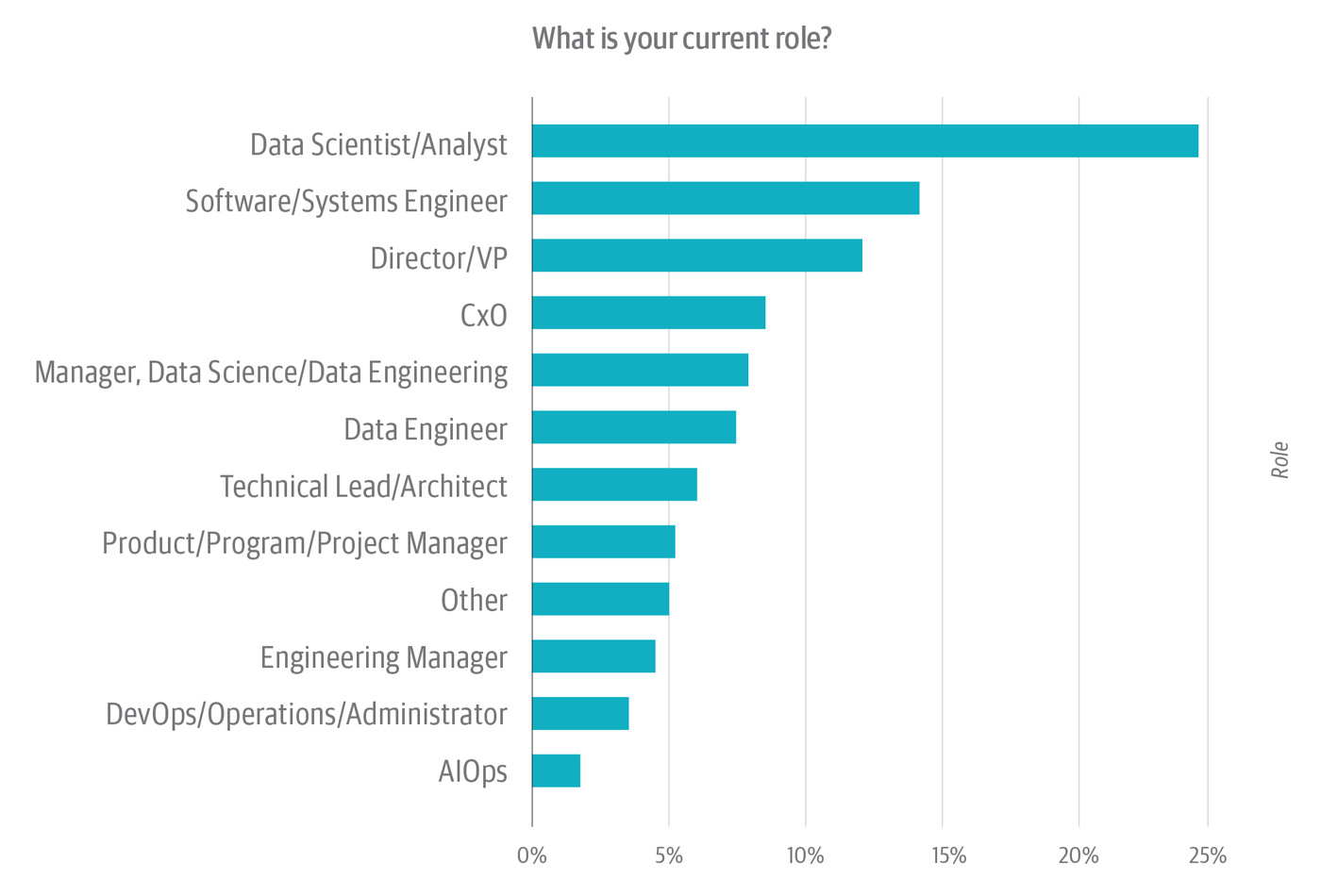
Almost one-quarter of respondents work as knowledge scientists or analysts (see Determine 1). A further 7% are knowledge engineers. On high of this, shut to eight% handle knowledge scientists or engineers. That implies that about 40% of the pattern consists of front-line practitioners. That is hardly stunning. Analysts and knowledge engineers are, arguably, the individuals who work most intently with knowledge.
In follow, nevertheless, nearly each knowledge scientist and analyst additionally doubles as an information engineer: she spends a major proportion of her time finding, making ready, and cleansing up knowledge to be used in evaluation. On this manner, knowledge scientists and knowledge analysts arguably have a private stake in knowledge high quality. They’re usually the primary to floor knowledge high quality issues; in organizations that would not have devoted knowledge high quality groups (or analogous assets, similar to knowledge high quality facilities of excellence), analysts play a number one function in cleansing up and correcting knowledge high quality points, too.
A switched-on C-suite?
Respondents who work in higher administration—i.e., as administrators, vice presidents, or CxOs—represent a mixed one-fifth of the pattern. That is stunning. These outcomes recommend that knowledge high quality has achieved salience of some form within the minds of upper-level administration. However what sort of salience? That’s a tough query.
Position-wise, the survey pattern is dominated by (1) practitioners who work with knowledge and/or code and (2) the individuals who immediately handle them—most of whom, notionally, even have backgrounds in knowledge and/or code. This final level is vital. An individual who manages an information science or knowledge engineering group—or, for that matter, a DevOps or AIOps follow—capabilities for all intents and functions as an interface between her group(s) and the individual (additionally sometimes a supervisor) to whom she immediately stories. She’s “administration,” however she’s nonetheless on the entrance line. And he or she possible additionally groks the sensible, logistical, and political points that (of their intersectionality) mix to make knowledge high quality such a thorny downside.
Executives deliver a special, transcendent, perspective to bear in assessing knowledge high quality, significantly with respect to its impression on enterprise operations and technique. Executives see the large image, not solely vis-à-vis operations and technique, but in addition with respect to issues—and, particularly, complaints—within the items that report back to them. Govt buy-in and assist is normally seen as one of many pillars of any profitable knowledge high quality program as a result of knowledge high quality is extra a people-and-process-laden downside than a technological one. It isn’t simply that totally different teams have differing requirements, expectations, or priorities in relation to knowledge high quality; it’s that totally different teams will go to struggle over these requirements, expectations, and priorities. Information high quality options nearly all the time boil down to 2 huge points: politics and price. Some group(s) are going to have to alter the best way they do issues; the cash to pay for knowledge high quality enhancements should come out of this or that group’s funds.
Govt curiosity generally is a helpful—if not infallible—proxy for a corporation’s posture with respect to knowledge high quality. Traditionally, the manager who understood the significance of knowledge high quality was an exception, with few enlightened CxOs spearheading knowledge high quality initiatives or serving to kick-start an information high quality heart of excellence. Whether or not resulting from organizations changing into extra knowledge pushed, or the elevated consideration paid to the results of knowledge high quality on AI efforts, elevated C-suite buy-in is a constructive improvement.
Organizational demographics
About half of survey respondents are primarily based in North America. Barely greater than 1 / 4 are in Europe—inclusive of the UK—whereas about one-sixth are in Asia. Mixed, respondents in South America and the Center East account for slightly below 10% of the survey pattern.
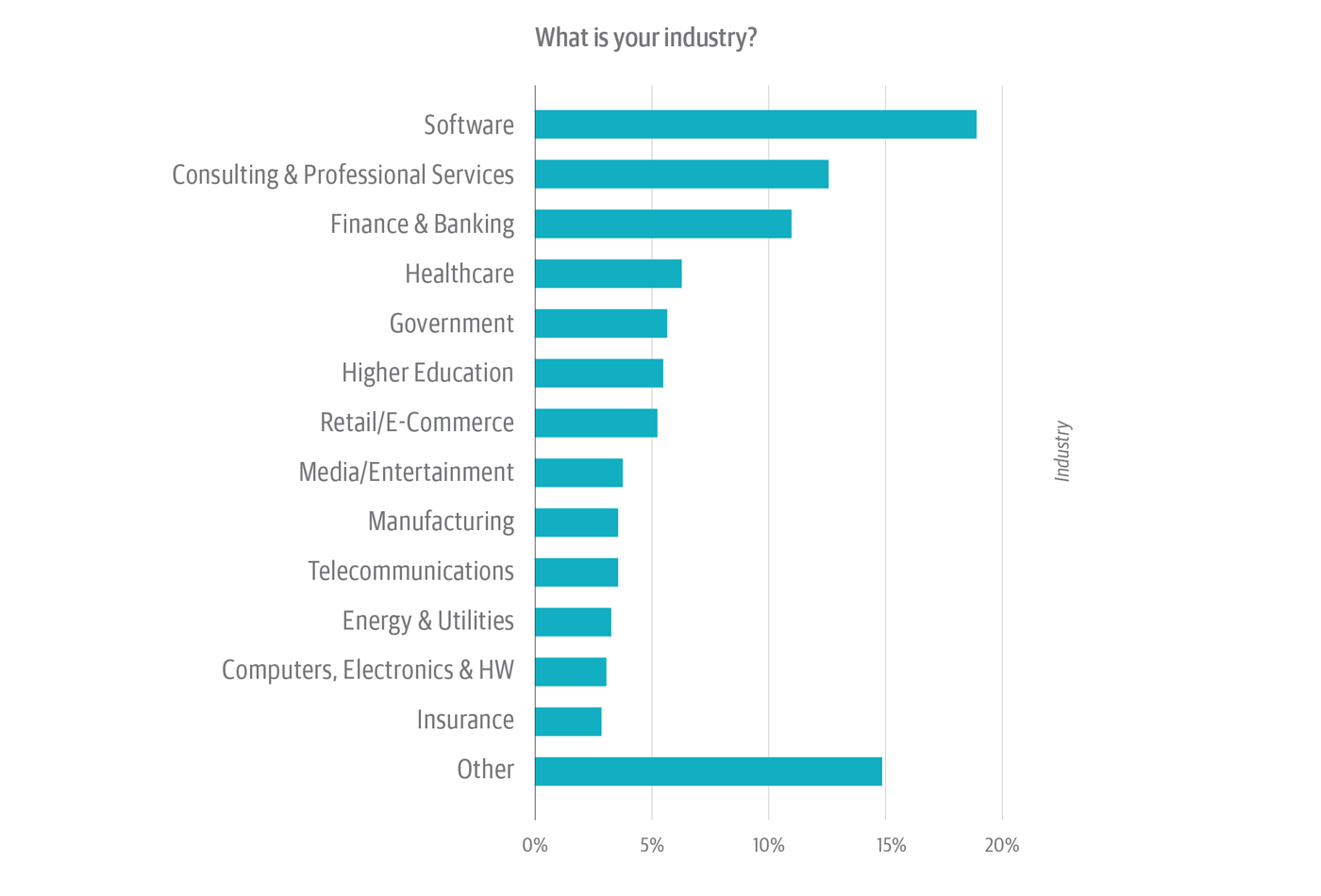
Drilling down deeper, nearly two-fifths of the survey viewers works in tech-laden verticals similar to software program, consulting/skilled providers, telcos, and computer systems/{hardware} (Determine 2). This might impart a slight tech bias to the outcomes. However, between 5% and 10% of respondents work in every of a broad swath of different verticals, together with: healthcare, authorities, greater training, and retail/e-commerce. (“Different,” the second largest class, with about 15% of respondents, encompasses greater than a dozen different verticals.) So concern about tech-industry bias may very well be offset by the truth that nearly all industries are, in impact, tech-dependent.
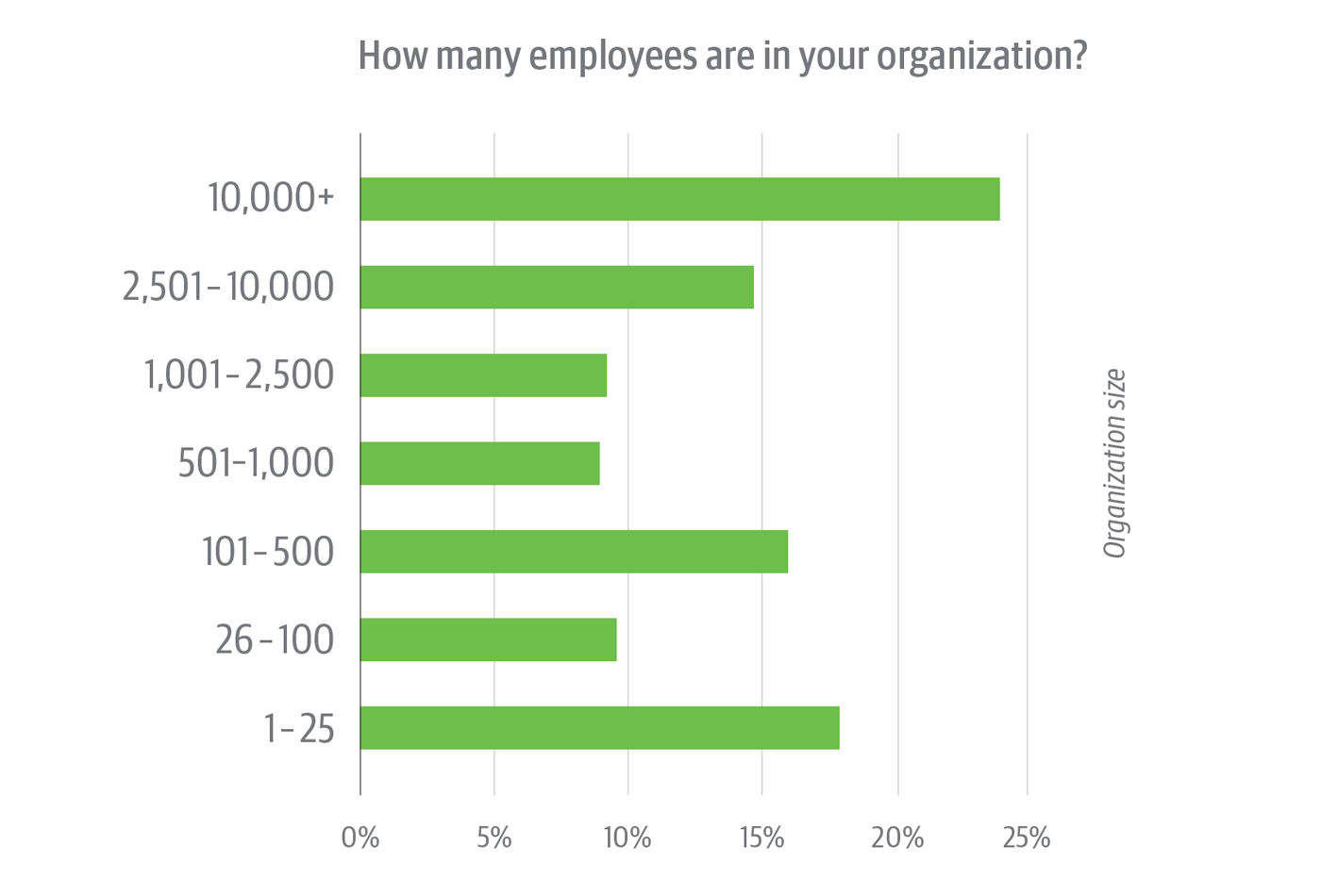
Dimension-wise, there’s a superb combine within the survey base: practically half of respondents work in organizations with 1,000 staff or extra; barely greater than half, at organizations with 1,000 staff or much less.
Information high quality points and impacts
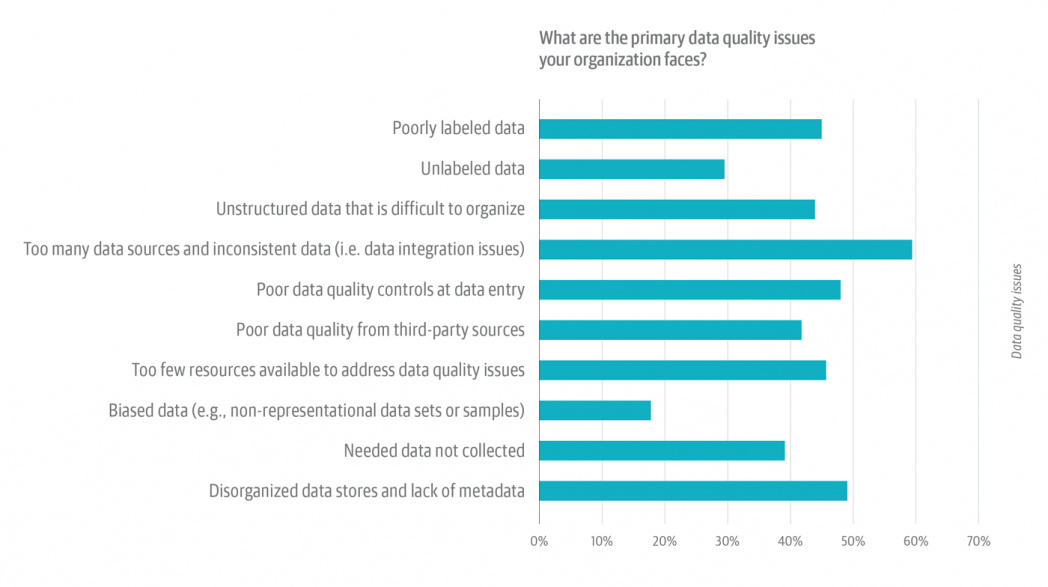
We requested respondents to pick from amongst a listing of frequent knowledge high quality issues. Respondents had been inspired to pick all points that apply to them (Determine 4).
Too many knowledge sources, too little consistency
By a large margin, respondents charge the sheer preponderance of knowledge sources as the one most typical knowledge high quality difficulty. Greater than 60% of respondents chosen “Too many knowledge sources and inconsistent knowledge,” adopted by “Disorganized knowledge shops and lack of metadata,” which was chosen by slightly below 50% of respondents (Determine 4).
There’s one thing else to consider, too. This was a select-all-that-apply-type query, which implies that you’d count on to see some inflation for the very first possibility on the record, i.e., “Poorly labeled knowledge,” which was chosen by slightly below 44% of respondents. Selecting the primary merchandise in a select-all-that-apply record is a human habits statisticians have discovered to count on and (if crucial) to regulate for.
However “Poorly labeled knowledge” was truly the fifth most typical downside, trailing not solely the problems above, however “Poor knowledge qc at knowledge entry” (chosen by near 47%) and “Too few assets obtainable to handle knowledge high quality points” (chosen by lower than 44%), as nicely. However, the mixture of “Poorly labeled knowledge” and “Unlabeled knowledge” tallies near 70%.
There’s good and unhealthy on this. First, the unhealthy: decreasing the variety of knowledge sources is difficult.
IT fought the equal of a rear-guard motion towards this very downside via a lot of the Nineties and 2000s. Information administration practitioners even coined a time period—“spreadmart hell”—to explain what occurs when a number of totally different people or teams preserve spreadsheets of the identical knowledge set. The self-service use case helped exacerbate this downside: the primary era of self-service knowledge evaluation instruments eschewed options (similar to metadata creation and administration, provenance/lineage monitoring, and knowledge synchronization) which can be important for knowledge high quality and good knowledge governance.
In different phrases, the sheer preponderance of knowledge sources isn’t a bug: it’s a characteristic. If historical past is any indication, it’s an issue that isn’t going to go away: a number of, redundant, typically inconsistent copies of helpful knowledge units will all the time be with us.
On the great facet, technological progress—e.g., front-end instruments that generate metadata and seize provenance and lineage; knowledge cataloging software program that manages provenance and lineage—might tamp down on this. So, too, might cultural transformation: e.g., a top-down push to teach folks about knowledge high quality, knowledge governance, and common knowledge literacy.
Organizations are flunking Information Governance 101
Some frequent knowledge high quality points level to bigger, institutional issues. “Disorganized knowledge shops and lack of metadata” is essentially a governance difficulty. However simply 20% of survey respondents say their organizations publish details about knowledge provenance or knowledge lineage, which—together with sturdy metadata—are important instruments for diagnosing and resolving knowledge high quality points. If the administration of knowledge provenance/lineage is taken as a proxy for good governance, few organizations are making the minimize. Neither is it stunning that so many respondents additionally cite unlabeled/poorly labeled knowledge as an issue. You’ll be able to’t pretend good governance.
Nonetheless one other exhausting downside is that of “Poor knowledge qc at knowledge entry.” Anybody who has labored with knowledge is aware of that knowledge entry points are persistent and endemic, if not intractable.
Another frequent knowledge high quality points (Determine 4)—e.g., poor knowledge high quality from third-party sources (cited by about 36% of respondents), lacking knowledge (about 37%), and unstructured knowledge (greater than 40%)—are much less insidious, however no much less irritating. Practitioners might have little or no management over suppliers of third-party knowledge. Lacking knowledge will all the time be with us—as will an institutional reluctance to make it complete. As for a scarcity of assets (cited by greater than 40% of respondents), there’s no less than some cause for hope: machine studying (ML) and synthetic intelligence (AI) might present a little bit of a lift. Information engineering and knowledge evaluation instruments use ML to simplify and substantively automate a few of the duties concerned in discovering, profiling, and indexing knowledge.
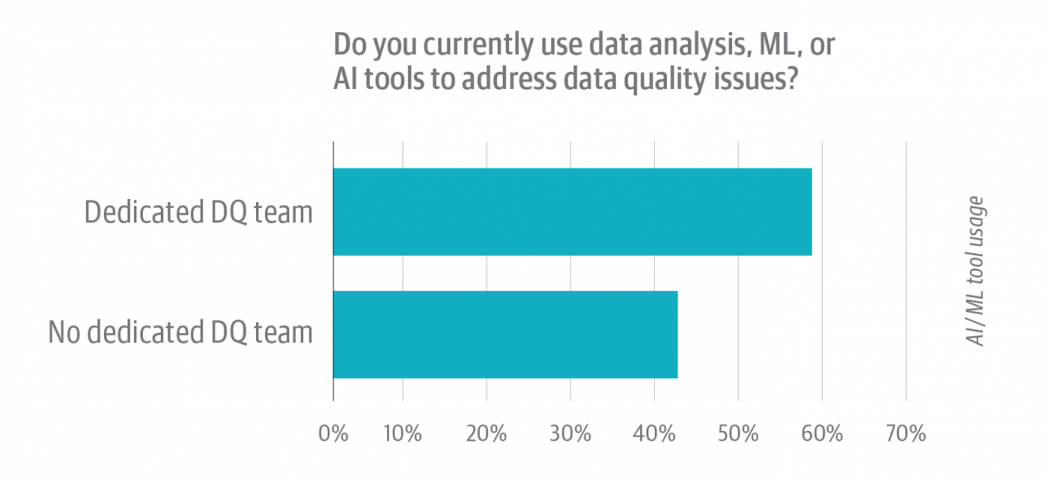
Not surprisingly, nearly half (48%) of respondents say they use knowledge evaluation, machine studying, or AI instruments to handle knowledge high quality points. A deeper dive (Determine 5) gives an fascinating take: organizations which have devoted knowledge high quality groups use analytic and AI instruments at a better charge, 59% in comparison with the 42% of respondents from organizations with no devoted knowledge high quality group. Having a group centered on knowledge high quality can present the area and motivation to spend money on making an attempt and studying instruments that make the group extra productive. Few knowledge analysts or knowledge engineers have the time or capability to make that dedication, as an alternative counting on advert hoc strategies to handle the information high quality points they face.
That being mentioned, knowledge high quality, like knowledge governance, is essentially a socio-technical downside. ML and AI may help to an extent, however it’s incumbent on the group itself to make the mandatory folks and course of modifications. In any case, folks and processes are nearly all the time implicated in each the creation and the perpetuation of knowledge high quality points. Finally, diagnosing and resolving knowledge high quality issues requires a real dedication to governance.
Information conditioning is pricey and useful resource intensive (and decidedly not attractive), one of many causes we don’t see extra formal assist for knowledge high quality amongst respondents. To extend the give attention to resolving knowledge points requires fastidiously scrutinizing the ROI of knowledge conditioning efforts to give attention to essentially the most worthwhile, productive, and efficient efforts.
Biases, damned biases, and lacking knowledge
Slightly below 20% of respondents cited “Biased knowledge” as a major knowledge high quality difficulty (Determine 4). We regularly speak about the necessity to deal with bias and equity in knowledge. However right here the proof means that respondents see bias as much less problematic than different frequent knowledge high quality points. Do they know one thing we don’t? Or are respondents themselves biased—on this case, by what they will’t think about? This consequence underscores the significance of acknowledging that knowledge accommodates biases; that we should always assume (not rule out) the existence of unknown biases; and that we should always promote the event of formal variety (cognitive, cultural, socio-economic, bodily, background, and so on.) and processes to detect, acknowledge, and deal with these biases.
Lacking knowledge performs into this, too. It isn’t simply that we lack the information we imagine we’d like for the work we wish to do. Generally we don’t know or can’t think about what knowledge we’d like. A textbook instance of this comes through Abraham Wald’s evaluation of how you can enhance the location of armor on World Battle II-era bombers: Wald needed to check the bombers that had been shot down, which was virtually unattainable. Nonetheless, he was in a position to make inferences concerning the impact of what’s now referred to as survivor bias by factoring in what was lacking, i.e., that the planes that returned from profitable missions had an inverse sample of injury relative to people who had been shot down. His perception was a corrective to the collective bias of the Military’s Statistical Analysis Group (SRG). The SRG couldn’t think about that it was lacking knowledge.
No knowledge high quality difficulty is an island complete of itself
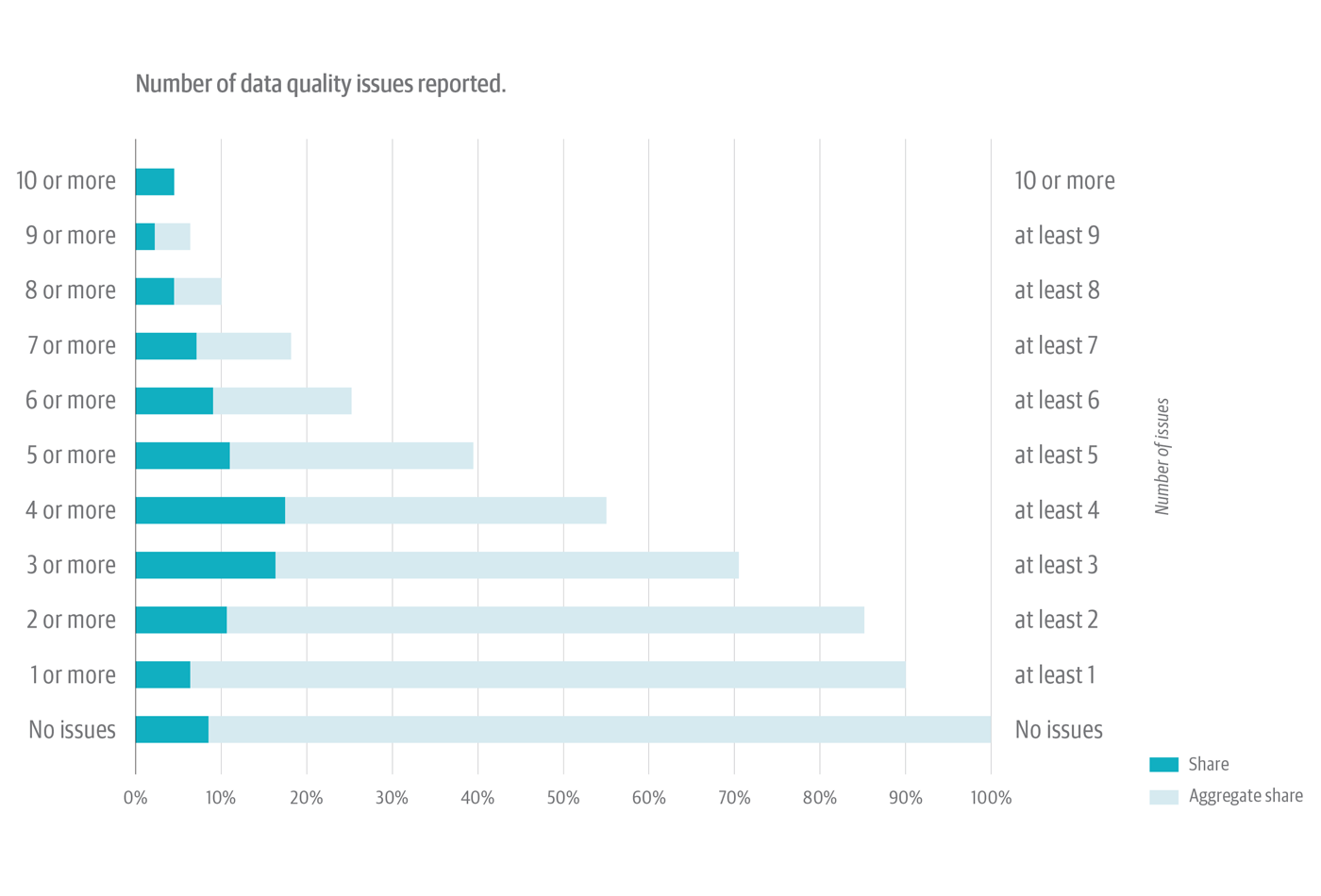
Organizations aren’t coping with just one knowledge high quality difficulty. It’s extra sophisticated than that—with greater than half of respondents reporting no less than 4 knowledge high quality points.
Determine 6, under, combines two issues. The darkish inexperienced portion of every horizontal bar reveals the share of survey respondents who reported that particular variety of discrete knowledge high quality points at their organizations (i.e., 3 points or 4 points, and so on.). The sunshine grey/inexperienced portion of every bar reveals the combination share of respondents who reported no less than that variety of knowledge high quality points (i.e., no less than 2 points, no less than 3 points, and so on.).
A number of highlights to assist navigate this advanced chart:
- Respondents most frequently report both three or 4 knowledge high quality points. The darkish inexperienced portion of the horizontal bars present about 16% of respondents for every of those outcomes.
- Trying on the aggregates of the “no less than 4” and “no less than 3” objects, we see the sunshine grey/inexperienced part of the chart reveals 56% of respondents reporting no less than 4 knowledge high quality points and 71% reporting no less than three knowledge high quality points.
That organizations face myriad knowledge high quality points shouldn’t be a shock. What’s stunning is that organizations don’t extra usually take a structured or formal method to addressing their very own distinctive, gnarly mixture of knowledge high quality challenges.
Lineage and provenance proceed to lag
A major majority of respondents—nearly 80%—say their organizations don’t publish details about knowledge provenance or knowledge lineage.
If that is stunning, it shouldn’t be. Lineage and provenance are inextricably certain with knowledge governance, which overlaps considerably with knowledge high quality. As we noticed, most organizations are failing Information Governance 101. Information scientists, knowledge engineers, software program builders, and different technologists use provenance knowledge to confirm the output of a workflow or knowledge processing pipeline—or, as usually as not, to diagnose issues. Provenance notes the place the information in an information set got here from; which transformations, if any, have been utilized to it; and different technical trivia.
With respect to enterprise intelligence and analytics, knowledge lineage gives a mechanism enterprise folks, analysts, and auditors can use to belief and confirm knowledge. If an auditor has questions concerning the values in a report or the contents of an information set, they will use the information lineage document to retrace its historical past. On this manner, provenance and lineage give us confidence that the content material of an information set is each explicable and reproducible.
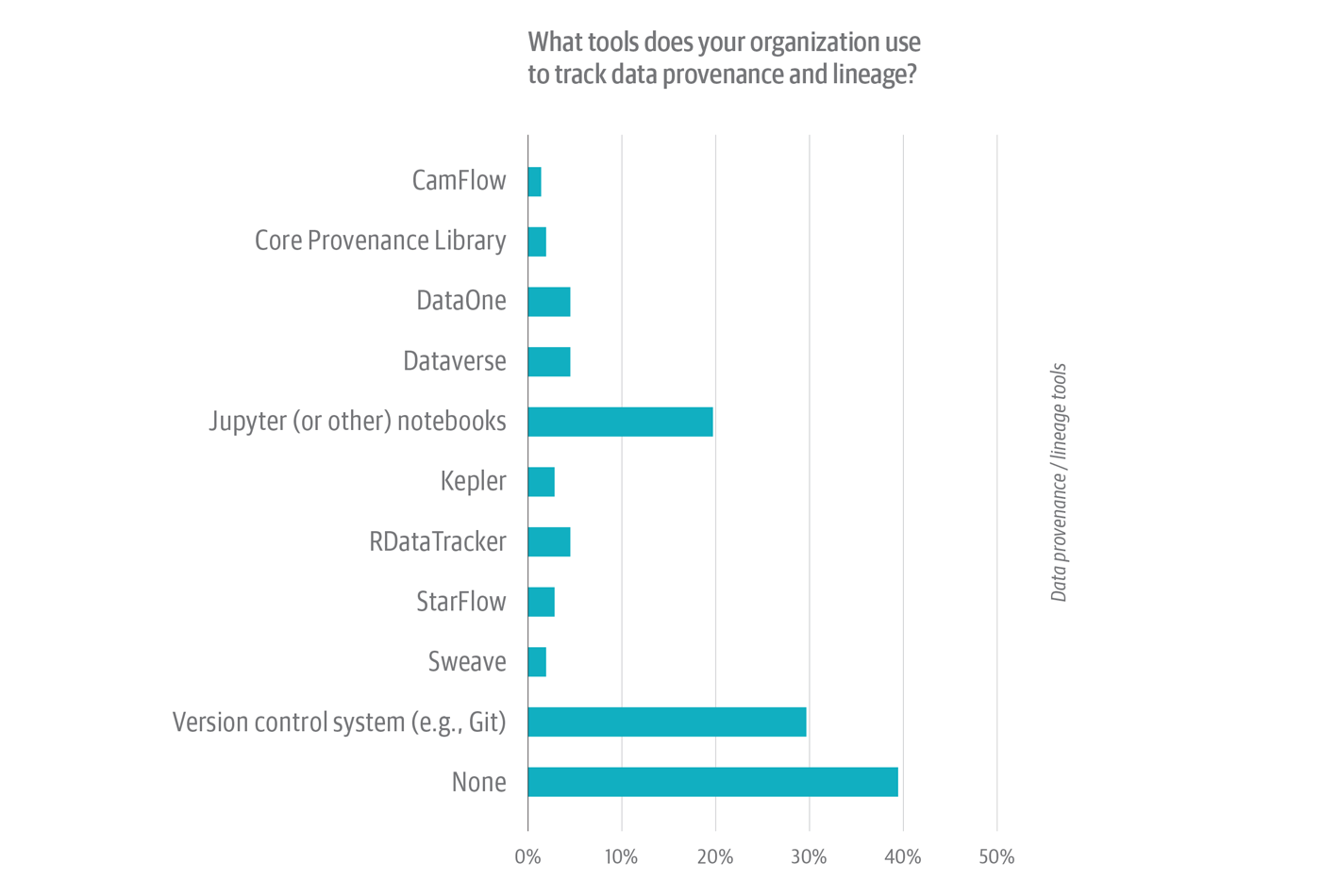
Of the 19% of survey respondents whose organizations do handle lineage and provenance, barely lower than 30% say they use a model management system—a la Git—to do that (Determine 7). One other one-fifth use a pocket book setting (similar to Jupyter). The remaining 50% (i.e., of respondents whose organizations do publish lineage and provenance) use a smattering of open supply and industrial libraries and instruments, most of that are mechanisms for managing provenance, not lineage.
If provenance and lineage are so vital, why do few organizations publish details about them?
As a result of lineage, particularly, is difficult. It imposes entry and use constraints that make it harder for enterprise folks to do what they need with knowledge—particularly as regards sharing and/or altering it. First-generation self-service analytic instruments made it simpler—and, in some circumstances, doable—for folks to share and experiment with knowledge. However the ease-of-use and company that these instruments promoted got here at a value: first-gen self-service instruments eschewed knowledge lineage, metadata administration, and different, comparable mechanisms.
A finest follow for capturing knowledge lineage is to include mechanisms for producing and managing metadata—together with lineage metadata—into front- and back-end instruments. ETL instruments are a textbook instance of this: nearly all ETL instruments generate granular (“technical”) lineage knowledge. Till just lately, nevertheless, most self-service instruments lacked wealthy metadata administration options or capabilities.
This would possibly clarify why practically two-thirds of respondents whose organizations do not publish provenance and lineage answered “No” to the follow-up query: “Does your group plan on implementing instruments or processes to publish knowledge provenance and lineage?” For the overwhelming majority of organizations, provenance and lineage is a dream deferred (Determine 8).
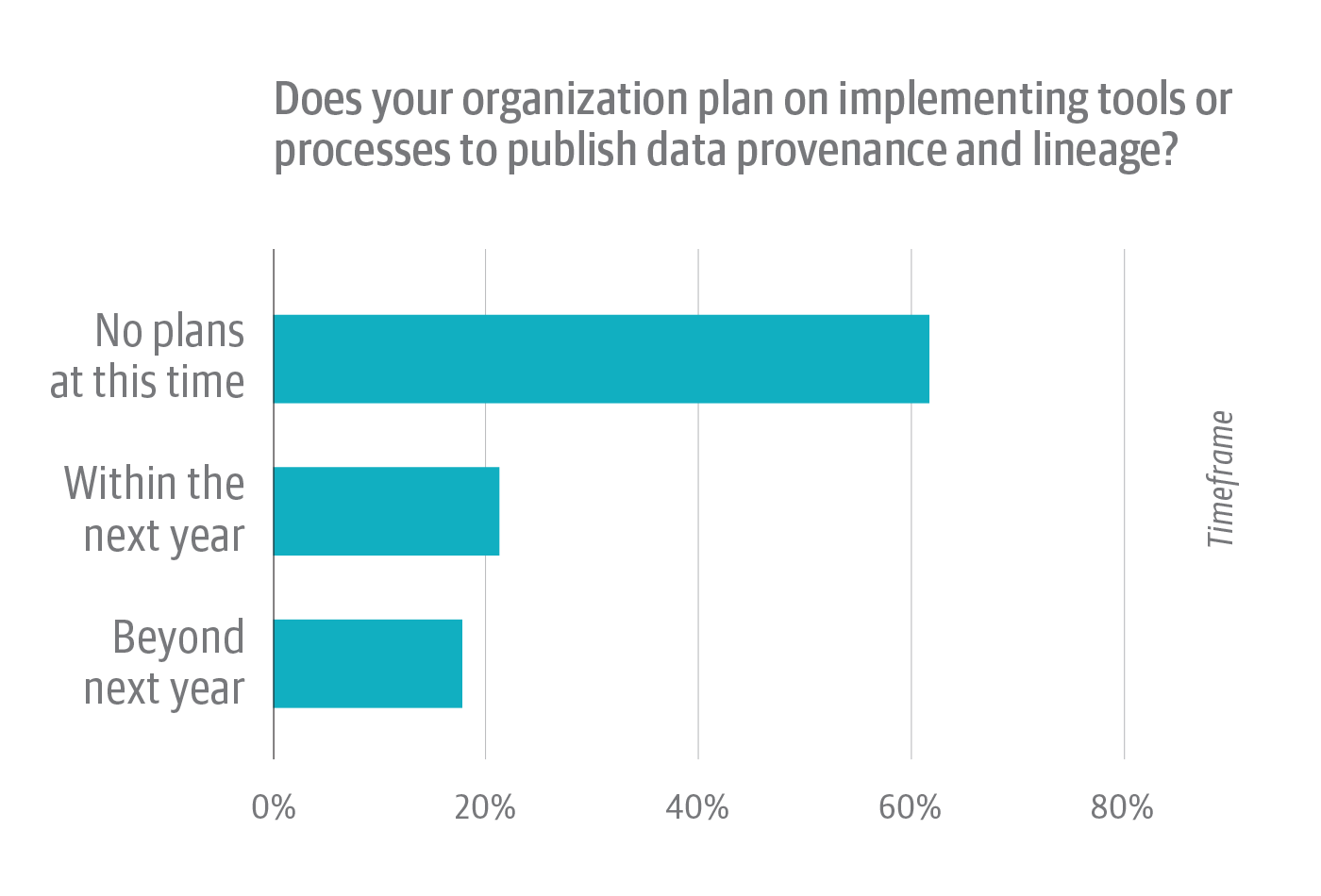
The excellent news is that the pendulum may very well be swinging within the course of governance.
Barely greater than one-fifth chosen “Inside the subsequent yr” in response to this query, whereas about one-sixth answered “Past subsequent yr.” Hottest open supply programming and analytic environments (Jupyter Notebooks, the R setting, even Linux itself) assist knowledge provenance through built-in or third-party initiatives and libraries. Business knowledge evaluation instruments now provide more and more sturdy metadata administration options. In the identical manner, knowledge catalog distributors, too, are making metadata administration—with an emphasis on knowledge lineage—a precedence. In the meantime, the Linux Basis sponsors Egeria, an open supply commonplace for metadata administration and alternate.
Information high quality shouldn’t be a group effort
Based mostly on suggestions from respondents, comparatively few organizations have created devoted knowledge high quality groups (Determine 9). Most (70%) answered “No” to the query “Does your group have a devoted knowledge high quality group?”
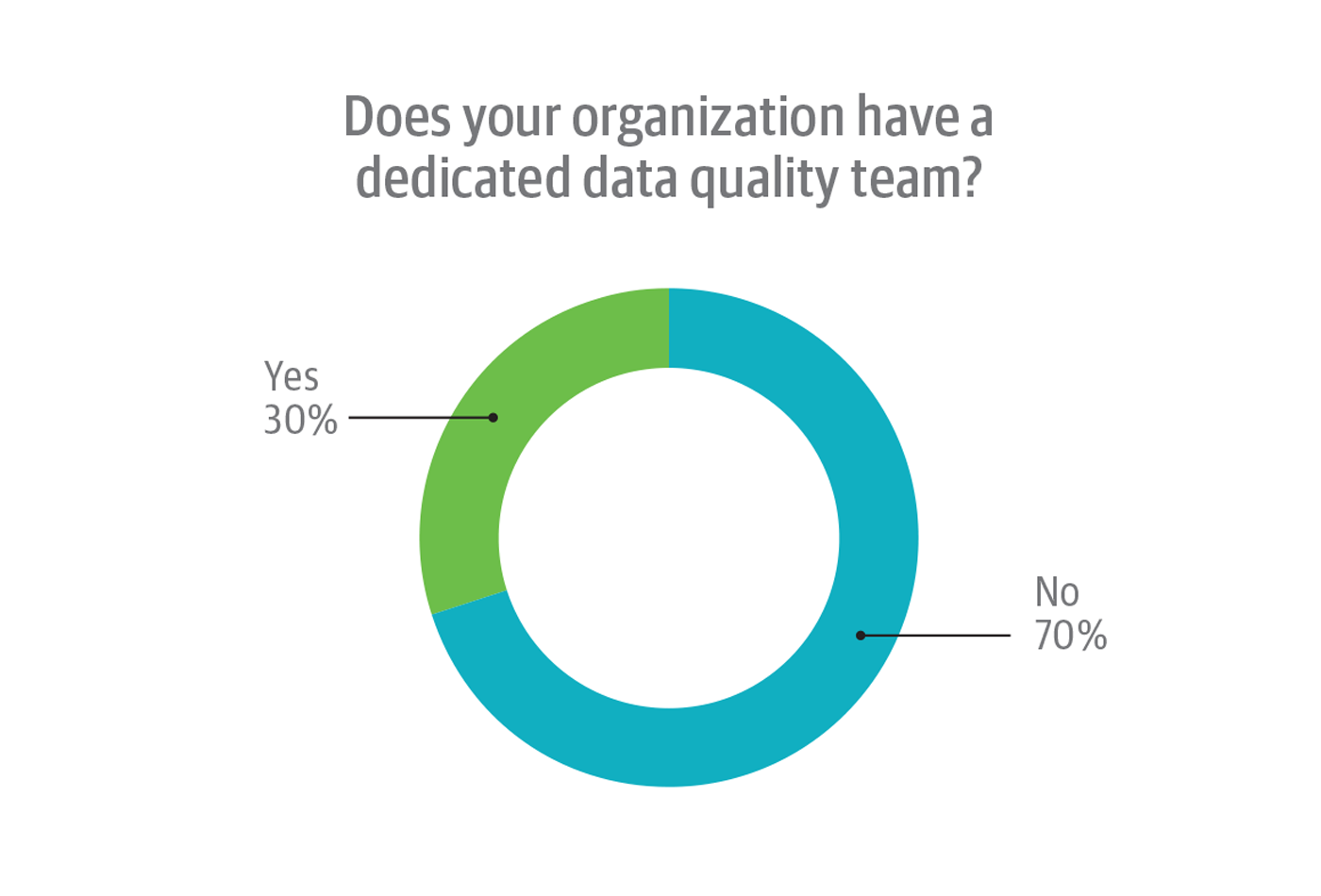
Few respondents who answered “Sure” to this query truly work on their group’s devoted knowledge high quality group. Almost two-thirds (62%) answered “No” to the follow-up query “Do you’re employed on the devoted knowledge high quality group?”; simply 38% answered “Sure.” Solely respondents who answered “Sure” to the query “Does your group have a devoted knowledge high quality group?” had been permitted to reply the follow-up. All instructed, 12% of all survey respondents work on a devoted knowledge high quality group.
Actual-time knowledge on the rise
Relatedly, we requested respondents who work in organizations that do have devoted knowledge high quality groups if these groups additionally work with real-time knowledge.
Nearly two-thirds (about 61%) answered “Sure.” We all know from different analysis that organizations are prioritizing efforts to do extra with real-time knowledge. In our latest evaluation of Strata Convention audio system’ proposals, for instance, phrases that correlate with real-time use circumstances had been entrenched within the first tier of proposal matters. “Stream” was the No. 4 total time period; “Apache Kafka,” a stream-processing platform, was No. 17; and “real-time” itself sat at No. 44.
“Streaming” isn’t similar with “real-time,” after all. However there is proof for overlap between using stream-processing applied sciences and so-called “real-time” use circumstances. Equally, the rise of next-gen architectural regimes (similar to microservices structure) can be driving demand for real-time knowledge: A microservices structure consists of a whole bunch, 1000’s, or tens of 1000’s of providers, every of which generates logging and diagnostic knowledge in real-time. Architects and software program engineers are constructing observability—mainly, monitoring on steroids—into these next-gen apps to make it simpler to diagnose and repair issues. This can be a compound real-time knowledge and real-time analytics downside.
The world shouldn’t be a monolith
For essentially the most half, organizations in North America appear to be coping with the identical issues as their counterparts in different areas. Business illustration, job roles, employment expertise, and different indicia had been surprisingly constant throughout all areas—though there have been a number of intriguing variances. For instance, the proportion of “administrators/vice presidents” was about one-third greater for North American respondents than for the remainder of the world, whereas the North American proportion of consulting/skilled providers respondents was near half the tally for the remainder of the globe.
Our evaluation surfaced no less than one different intriguing geographical variance. As famous in Determine 9, we requested every participant if their group maintains a devoted knowledge high quality group. Whereas North America and the remainder of the world had about the identical share of respondents with devoted knowledge high quality groups, our North American respondents had been much less more likely to work on that knowledge high quality group.
Takeaways
A assessment of the survey outcomes yields a number of takeaways organizations can use to realistically deal with how they will situation their knowledge to enhance the efficacy of their analytics and fashions.
- Most organizations ought to take formal steps to situation and enhance their knowledge, similar to creating devoted knowledge high quality groups. However conditioning knowledge is an on-going course of, not a one-and-done panacea. Because of this C-suite buy-in—as troublesome as it’s to acquire—is a prerequisite for sustained knowledge high quality remediation. Selling C-suite understanding and dedication might require training as many execs have little or no expertise working with knowledge or analytics.
- Conditioning is neither straightforward nor low cost. Committing to formal processes and devoted groups helps set expectations concerning the troublesome work of remediating knowledge points. Excessive prices ought to compel organizations to take an ROI-based method to how and the place to deploy their knowledge conditioning assets. This consists of deciding what shouldn’t be value addressing.
- Organizations that pursue AI initiatives normally uncover that they’ve knowledge high quality points hiding in plain sight. The issue (and partial resolution) is that they want high quality knowledge to energy their AI initiatives. Consider AI because the carrot, and of poor knowledge because the proverbial stick. The upshot is that funding in AI can develop into a catalyst for knowledge high quality remediation.
- AI is a solution, however not the one one. AI-enriched instruments can enhance productiveness and simplify a lot of the work concerned in enhancing knowledge efficacy. However our survey outcomes recommend {that a} devoted knowledge high quality group additionally helps to foster using AI-enriched instruments. What’s extra, a devoted group is motivated to spend money on studying to make use of these instruments nicely; conversely, few analysts and knowledge engineers have the time or capability to totally grasp these instruments.
- Information governance is all nicely and good, however organizations want to start out with extra fundamental stuff: knowledge dictionaries to assist clarify knowledge; monitoring provenance, lineage, recency; and different necessities.
[ad_2]