
{kind=link}
[ad_1]
The Luong consideration sought to introduce a number of enhancements over the Bahdanau mannequin for neural machine translation, significantly by introducing two new courses of attentional mechanisms: a international strategy that attends to all supply phrases, and a native strategy that solely attends to a specific subset of phrases in predicting the goal sentence.
On this tutorial, you’ll uncover the Luong consideration mechanism for neural machine translation.
After finishing this tutorial, you’ll know:
- The operations carried out by the Luong consideration algorithm.
- How the worldwide and native attentional fashions work.
- How the Luong consideration compares to the Bahdanau consideration.
Let’s get began.

The Luong Consideration Mechanism
Picture by Mike Nahlii, some rights reserved.
Tutorial Overview
This tutorial is split into 5 elements; they’re:
- Introduction to the Luong Consideration
- The Luong Consideration Algorithm
- The International Attentional Mannequin
- The Native Attentional Mannequin
- Comparability to the Bahdanau Consideration
Conditions
For this tutorial, we assume that you’re already acquainted with:
Introduction to the Luong Consideration
Luong et al. (2015) encourage themselves from earlier consideration fashions, to suggest two consideration mechanisms:
On this work, we design, with simplicity and effectiveness in thoughts, two novel varieties of attention-based fashions: a world strategy which all the time attends to all supply phrases and a neighborhood one which solely appears to be like at a subset of supply phrases at a time.
– Efficient Approaches to Consideration-based Neural Machine Translation, 2015.
The international attentional mannequin resembles the mannequin of Bahdanau et al. (2014) in attending to all supply phrases, however goals to simplify it architecturally.
The native attentional mannequin is impressed from the onerous and tender consideration fashions of Xu et al. (2016), and attends to just a few of the supply positions.
The 2 attentional fashions share most of the steps of their prediction of the present phrase, however differ primarily of their computation of the context vector.
Let’s first check out the overarching Luong consideration algorithm, after which delve into the variations between the worldwide and native attentional fashions afterwards.
The Luong Consideration Algorithm
The eye algorithm of Luong et al. performs the next operations:
- The encoder generates a set of annotations, $H = mathbf{h}_i, i = 1, dots, T$, from the enter sentence.
- The present decoder hidden state is computed as: $mathbf{s}_t = textual content{RNN}_text{decoder}(mathbf{s}_{t-1}, y_{t-1})$. Right here, $mathbf{s}_{t-1}$ denotes the earlier hidden decoder state, and $y_{t-1}$ the earlier decoder output.
- An alignment mannequin, $a(.)$ makes use of the annotations and the present decoder hidden state to compute the alignment scores: $e_{t,i} = a(mathbf{s}_t, mathbf{h}_i)$.
- A softmax perform is utilized to the alignment scores, successfully normalizing them into weight values in a variety between 0 and 1: $alpha_{t,i} = textual content{softmax}(e_{t,i})$.
- These weights along with the beforehand computed annotations are used to generate a context vector by way of a weighted sum of the annotations: $mathbf{c}_t = sum^T_{i=1} alpha_{t,i} mathbf{h}_i$.
- An attentional hidden state is computed based mostly on a weighted concatenation of the context vector and the present decoder hidden state: $widetilde{mathbf{s}}_t = tanh(mathbf{W_c} [mathbf{c}_t ; ; ; mathbf{s}_t])$.
- The decoder produces a closing output by feeding it a weighted attentional hidden state: $y_t = textual content{softmax}(mathbf{W}_y widetilde{mathbf{s}}_t)$.
- Steps 2-7 are repeated till the tip of the sequence.
The International Attentional Mannequin
The worldwide attentional mannequin considers the entire supply phrases within the enter sentence when producing the alignment scores and, finally, when computing the context vector.
The thought of a world attentional mannequin is to think about all of the hidden states of the encoder when deriving the context vector, $mathbf{c}_t$.
– Efficient Approaches to Consideration-based Neural Machine Translation, 2015.
So as to take action, Luong et al. suggest three various approaches for computing the alignment scores. The primary strategy is just like Bahdanau’s and relies upon the concatenation of $mathbf{s}_t$ and $mathbf{h}_i$, whereas the second and third approaches implement multiplicative consideration (in distinction to Bahdanau’s additive consideration):
- $$a(mathbf{s}_t, mathbf{h}_i) = mathbf{v}_a^T tanh(mathbf{W}_a [mathbf{s}_t ; ; ; mathbf{s}_t)]$$
- $$a(mathbf{s}_t, mathbf{h}_i) = mathbf{s}^T_t mathbf{h}_i$$
- $$a(mathbf{s}_t, mathbf{h}_i) = mathbf{s}^T_t mathbf{W}_a mathbf{h}_i$$
Right here, $mathbf{W}_a$ is a trainable weight matrix and, equally, $mathbf{v}_a$ is a weight vector.
Intuitively, using the dot product in multiplicative consideration could be interpreted as offering a similarity measure between the vectors, $mathbf{s}_t$ and $mathbf{h}_i$, into consideration.
… if the vectors are comparable (that’s, aligned), the results of the multiplication might be a big worth and the eye might be centered on the present t,i relationship.
– Superior Deep Studying with Python, 2019.
The ensuing alignment vector, $mathbf{e}_t$, is of variable-length in accordance with the variety of supply phrases.
The Native Attentional Mannequin
In attending to all supply phrases, the worldwide attentional mannequin is computationally costly and will probably turn into impractical for translating longer sentences.
The native attentional mannequin seeks to handle these limitations by specializing in a smaller subset of the supply phrases to generate every goal phrase. So as to take action, it takes inspiration from the onerous and tender consideration fashions of the picture caption technology work of Xu et al. (2016):
- Soft consideration is equal to the worldwide consideration strategy, the place weights are softly positioned over all of the supply picture patches. Therefore, tender consideration considers the supply picture in its entirety.
- Onerous consideration attends to a single picture patch at a time.
The native attentional mannequin of Luong et al. generates a context vector by computing a weighted common over the set of annotations, $mathbf{h}_i$, inside a window centered over an aligned place, $p_t$:
$$[p_t – D, p_t + D]$$
Whereas a worth for $D$ is chosen empirically, Luong et al. take into account two approaches in computing a worth for $p_t$:
- Monotonic alignment: the place the supply and goal sentences are assumed to be monotonically aligned and, therefore, $p_t = t$.
- Predictive alignment: the place a prediction of the aligned place relies upon trainable mannequin parameters, $mathbf{W}_p$ and $mathbf{v}_p$, and the supply sentence size, $S$:
$$p_t = S cdot textual content{sigmoid}(mathbf{v}^T_p tanh(mathbf{W}_p, mathbf{s}_t))$$
To favour supply phrases nearer to the window centre, a Gaussian distribution is centered round $p_t$ when computing the alignment weights.
This time spherical, the ensuing alignment vector, $mathbf{e}_t$, has a set size of $2D + 1$.
Comparability to the Bahdanau Consideration
The Bahdanau mannequin and the worldwide consideration strategy of Luong et al. are largely comparable, however there are key variations between the 2:
Whereas our international consideration strategy is comparable in spirit to the mannequin proposed by Bahdanau et al. (2015), there are a number of key variations which replicate how we’ve each simplified and generalized from the unique mannequin.
– Efficient Approaches to Consideration-based Neural Machine Translation, 2015.
- Most notably, the computation of the alignment scores, $e_t$, within the Luong international attentional mannequin relies on the present decoder hidden state, $mathbf{s}_t$, reasonably than on the earlier hidden state, $mathbf{s}_{t-1}$, as within the Bahdanau consideration.
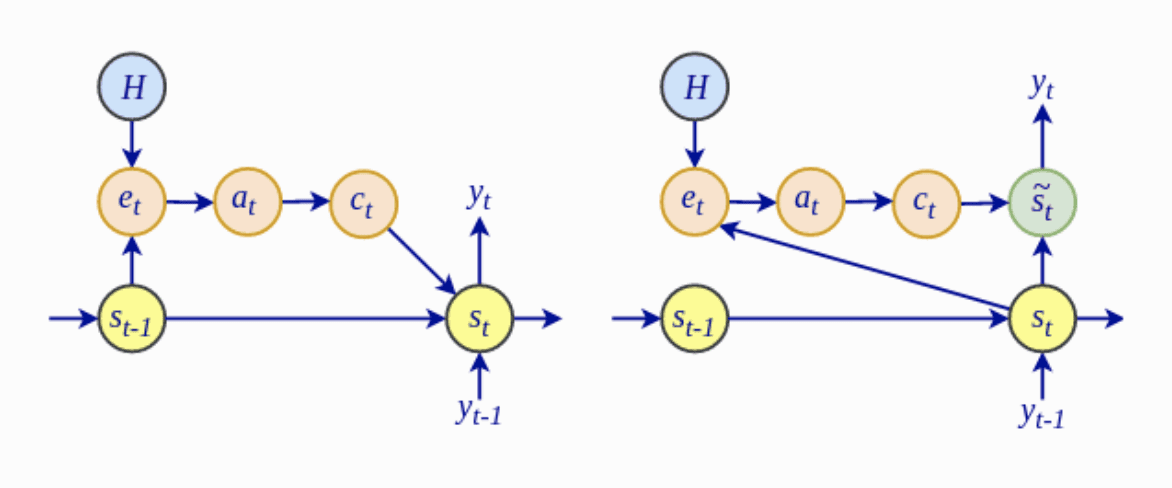
The Bahdanau Structure (Left) vs. the Luong Structure (Proper)
Taken from “Superior Deep Studying with Python“
- Luong et al. drop the bidirectional encoder in use by the Bahdanau mannequin, and as an alternative make the most of the hidden states on the high LSTM layers for each encoder and decoder.
- The worldwide attentional mannequin of Luong et al. investigates using multiplicative consideration, as a substitute for the Bahdanau additive consideration.
Additional Studying
This part supplies extra assets on the subject if you’re trying to go deeper.
Books
Papers
Abstract
On this tutorial, you found the Luong consideration mechanism for neural machine translation.
Particularly, you discovered:
- The operations carried out by the Luong consideration algorithm.
- How the worldwide and native attentional fashions work.
- How the Luong consideration compares to the Bahdanau consideration.
Do you may have any questions?
Ask your questions within the feedback under and I’ll do my greatest to reply.
[ad_2]