
{kind=link}
[ad_1]
In recent times, there was rising curiosity in making use of deep studying to medical imaging duties, with thrilling progress in varied functions like radiology, pathology and dermatology. Regardless of the curiosity, it stays difficult to develop medical imaging fashions, as a result of high-quality labeled information is usually scarce as a result of time-consuming effort wanted to annotate medical pictures. Given this, switch studying is a well-liked paradigm for constructing medical imaging fashions. With this method, a mannequin is first pre-trained utilizing supervised studying on a big labeled dataset (like ImageNet) after which the realized generic illustration is fine-tuned on in-domain medical information.
Different more moderen approaches which have confirmed profitable in pure picture recognition duties, particularly when labeled examples are scarce, use self-supervised contrastive pre-training, adopted by supervised fine-tuning (e.g., SimCLR and MoCo). In pre-training with contrastive studying, generic representations are realized by concurrently maximizing settlement between in another way reworked views of the identical picture and minimizing settlement between reworked views of various pictures. Regardless of their successes, these contrastive studying strategies have obtained restricted consideration in medical picture evaluation and their efficacy is but to be explored.
In “Massive Self-Supervised Fashions Advance Medical Picture Classification”, to seem on the Worldwide Convention on Laptop Imaginative and prescient (ICCV 2021), we research the effectiveness of self-supervised contrastive studying as a pre-training technique throughout the area of medical picture classification. We additionally suggest Multi-Occasion Contrastive Studying (MICLe), a novel method that generalizes contrastive studying to leverage particular traits of medical picture datasets. We conduct experiments on two distinct medical picture classification duties: dermatology situation classification from digital digital camera pictures (27 classes) and multilabel chest X-ray classification (5 classes). We observe that self-supervised studying on ImageNet, adopted by extra self-supervised studying on unlabeled domain-specific medical pictures, considerably improves the accuracy of medical picture classifiers. Particularly, we exhibit that self-supervised pre-training outperforms supervised pre-training, even when the total ImageNet dataset (14M pictures and 21.8K lessons) is used for supervised pre-training.
SimCLR and Multi Occasion Contrastive Studying (MICLe)
Our method consists of three steps: (1) self-supervised pre-training on unlabeled pure pictures (utilizing SimCLR); (2) additional self-supervised pre-training utilizing unlabeled medical information (utilizing both SimCLR or MICLe); adopted by (3) task-specific supervised fine-tuning utilizing labeled medical information.
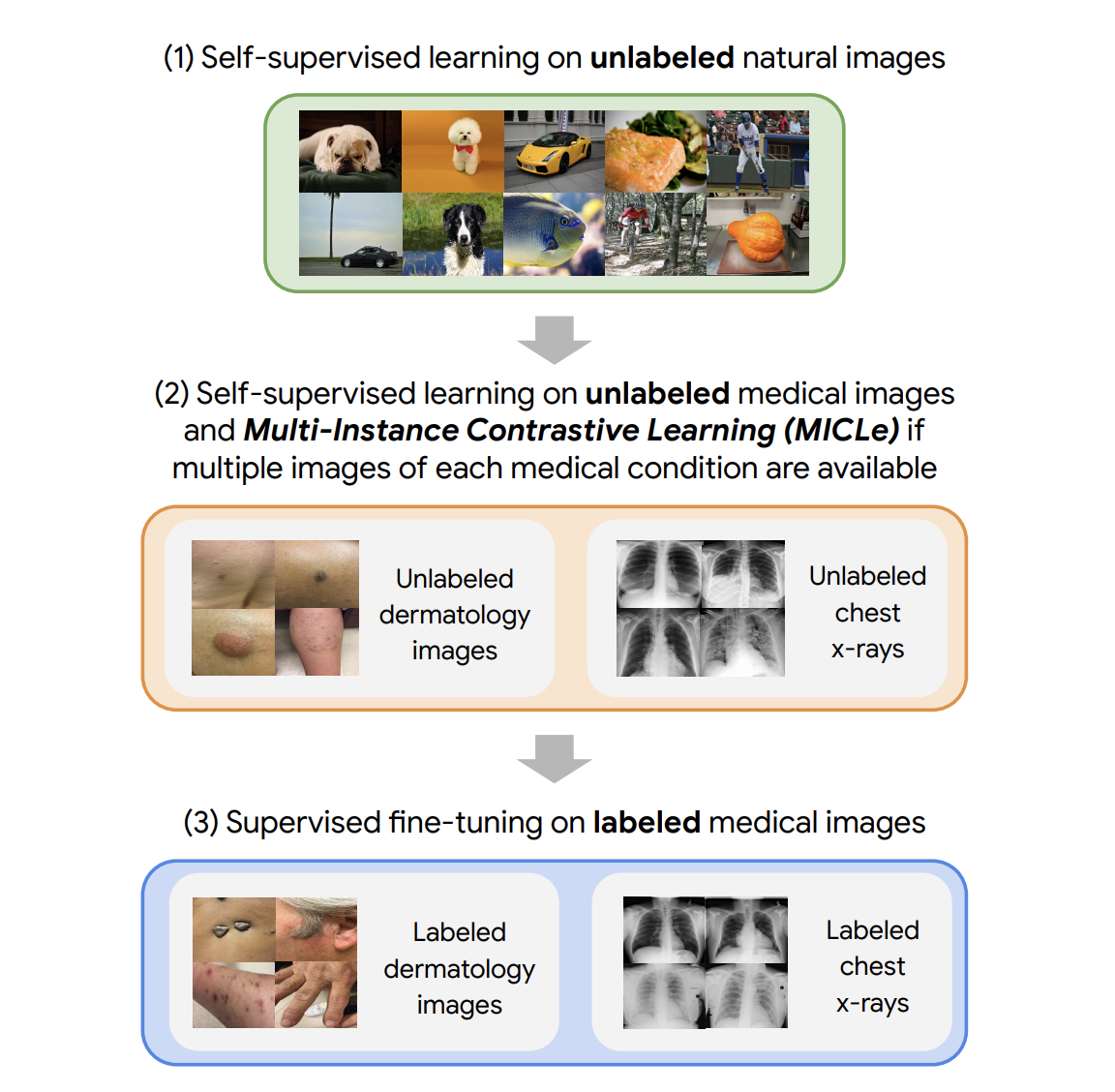 |
| Our method contains three steps: (1) Self-supervised pre-training on unlabeled ImageNet utilizing SimCLR (2) Further self-supervised pre-training utilizing unlabeled medical pictures. If a number of pictures of every medical situation can be found, a novel Multi-Occasion Contrastive Studying (MICLe) technique is used to assemble extra informative optimistic pairs based mostly on totally different pictures. (3) Supervised fine-tuning on labeled medical pictures. Be aware that not like step (1), steps (2) and (3) are process and dataset particular. |
After the preliminary pre-training with SimCLR on unlabeled pure pictures is full, we prepare the mannequin to seize the particular traits of medical picture datasets. This, too, will be finished with SimCLR, however this methodology constructs optimistic pairs solely by augmentation and doesn’t readily leverage sufferers’ meta information for optimistic pair development. Alternatively, we use MICLe, which makes use of a number of pictures of the underlying pathology for every affected person case, when out there, to assemble extra informative optimistic pairs for self-supervised studying. Such multi-instance information is usually out there in medical imaging datasets — e.g., frontal and lateral views of mammograms, retinal fundus pictures from every eye, and so on.
Given a number of pictures of a given affected person case, MICLe constructs a optimistic pair for self-supervised contrastive studying by drawing two crops from two distinct pictures from the identical affected person case. Such pictures could also be taken from totally different viewing angles and present totally different physique components with the identical underlying pathology. This presents an excellent alternative for self-supervised studying algorithms to be taught representations which are sturdy to modifications of viewpoint, imaging circumstances, and different confounding elements in a direct means. MICLe doesn’t require class label info and solely depends on totally different pictures of an underlying pathology, the kind of which can be unknown.
 |
| MICLe generalizes contrastive studying to leverage particular traits of medical picture datasets (affected person metadata) to create reasonable augmentations, yielding additional efficiency enhance of picture classifiers. |
Combining these self-supervised studying methods, we present that even in a extremely aggressive manufacturing setting we are able to obtain a large achieve of 6.7% in top-1 accuracy on dermatology pores and skin situation classification and an enchancment of 1.1% in imply AUC on chest X-ray classification, outperforming robust supervised baselines pre-trained on ImageNet (the prevailing protocol for coaching medical picture evaluation fashions). As well as, we present that self-supervised fashions are sturdy to distribution shift and may be taught effectively with solely a small variety of labeled medical pictures.
Comparability of Supervised and Self-Supervised Pre-training
Regardless of its simplicity, we observe that pre-training with MICLe persistently improves the efficiency of dermatology classification over the unique methodology of pre-training with SimCLR underneath totally different pre-training dataset and base community structure decisions. Utilizing MICLe for pre-training, interprets to (1.18 ± 0.09)% improve in top-1 accuracy for dermatology classification over utilizing SimCLR. The outcomes exhibit the profit accrued from using extra metadata or area information to assemble extra semantically significant augmentations for contrastive pre-training. As well as, our outcomes counsel that wider and deeper fashions yield larger efficiency good points, with ResNet-152 (2x width) fashions typically outperforming ResNet-50 (1x width) fashions or smaller counterparts.
 |
| Comparability of supervised and self-supervised pre-training, adopted by supervised fine-tuning utilizing two architectures on dermatology and chest X-ray classification. Self-supervised studying makes use of unlabeled domain-specific medical pictures and considerably outperforms supervised ImageNet pre-training. |
Improved Generalization with Self-Supervised Fashions
For every process we carry out pretraining and fine-tuning utilizing the in-domain unlabeled and labeled information respectively. We additionally use one other dataset obtained in a special scientific setting as a shifted dataset to additional consider the robustness of our methodology to out-of-domain information. For the chest X-ray process, we be aware that self-supervised pre-training with both ImageNet or CheXpert information improves generalization, however stacking them each yields additional good points. As anticipated, we additionally be aware that when solely utilizing ImageNet for self-supervised pre-training, the mannequin performs worse in comparison with utilizing solely in-domain information for pre-training.
To check the efficiency underneath distribution shift, for every process, we held out extra labeled datasets for testing that had been collected underneath totally different scientific settings. We discover that the efficiency enchancment within the distribution-shifted dataset (ChestX-ray14) by utilizing self-supervised pre-training (each utilizing ImageNet and CheXpert information) is extra pronounced than the unique enchancment on the CheXpert dataset. This can be a precious discovering, as generalization underneath distribution shift is of paramount significance to scientific functions. On the dermatology process, we observe comparable traits for a separate shifted dataset that was collected in pores and skin most cancers clinics and had a better prevalence of malignant circumstances. This demonstrates that the robustness of the self-supervised representations to distribution shifts is constant throughout duties.
 |
| Analysis of fashions on distribution-shifted datasets for the chest-xray interpretation process. We use the mannequin skilled on in-domain information to make predictions on a further shifted dataset with none additional fine-tuning (zero-shot switch studying). We observe that self-supervised pre-training results in higher representations which are extra sturdy to distribution shifts. |
 |
| Analysis of fashions on distribution-shifted datasets for the dermatology process. Our outcomes typically counsel that self-supervised pre-trained fashions can generalize higher to distribution shifts with MICLe pre-training resulting in probably the most good points. |
Improved Label Effectivity
We additional examine the label-efficiency of the self-supervised fashions for medical picture classification by fine-tuning the fashions on totally different fractions of labeled coaching information. We use label fractions starting from 10% to 90% for each Derm and CheXpert coaching datasets and look at how the efficiency varies utilizing the totally different out there label fractions for the dermatology process. First, we observe that pre-training utilizing self-supervised fashions can compensate for low label effectivity for medical picture classification, and throughout the sampled label fractions, self-supervised fashions persistently outperform the supervised baseline. These outcomes additionally counsel that MICLe yields proportionally larger good points when fine-tuning with fewer labeled examples. In actual fact, MICLe is ready to match baselines utilizing solely 20% of the coaching information for ResNet-50 (4x) and 30% of the coaching information for ResNet152 (2x).
 |
| High-1 accuracy for dermatology situation classification for MICLe, SimCLR, and supervised fashions underneath totally different unlabeled pre-training datasets and assorted sizes of label fractions. MICLe is ready to match baselines utilizing solely 20% of the coaching information for ResNet-50 (4x). |
Conclusion
Supervised pre-training on pure picture datasets is often used to enhance medical picture classification. We examine an alternate technique based mostly on self-supervised pre-training on unlabeled pure and medical pictures and discover that it may considerably enhance upon supervised pre-training, the usual paradigm for coaching medical picture evaluation fashions. This method can result in fashions which are extra correct and label environment friendly and are sturdy to distribution shifts. As well as, our proposed Multi-Occasion Contrastive Studying methodology (MICLe) permits using extra metadata to create reasonable augmentations, yielding additional efficiency enhance of picture classifiers.
Self-supervised pre-training is way more scalable than supervised pre-training as a result of class label annotation will not be required. We hope this paper will assist popularize using self-supervised approaches in medical picture evaluation yielding label environment friendly and sturdy fashions fitted to scientific deployment at scale in the true world.
Acknowledgements
This work concerned collaborative efforts from a multidisciplinary workforce of researchers, software program engineers, clinicians, and cross-functional contributors throughout Google Well being and Google Mind. We thank our co-authors: Basil Mustafa, Fiona Ryan, Zach Beaver, Jan Freyberg, Jon Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, Vivek Natarajan, and Mohammad Norouzi. We additionally thank Yuan Liu from Google Well being for precious suggestions and our companions for entry to the datasets used within the analysis.
[ad_2]