
{kind=link}
[ad_1]
Illiteracy impacts at the least 773 million folks globally, each younger and outdated. For these people, studying info from unfamiliar sources or on unfamiliar subjects might be extraordinarily tough. Sadly, these inequalities have been additional magnified by the worldwide pandemic on account of unequal entry to training in studying and writing. In reality, UNESCO experiences that over 100 million youngsters are falling behind the minimal proficiency degree in studying on account of COVID-related faculty closures.
With growing world-wide entry to know-how, studying on a tool, comparable to a pill or telephone, has largely taken the place of conventional codecs. This gives a novel alternative to watch studying interactions, e.g., how a reader scrolls via a textual content, which may inform our understanding of what could make textual content tough to learn. This understanding is essential when designing instructional functions for low-proficiency readers and language learners, as a result of it may be used to match learners with appropriately leveled texts in addition to to help readers in understanding texts past their studying degree.
In “Predicting Textual content Readability from Scrolling Interactions”, offered at CoNLL 2021, we present that knowledge from on-device studying interactions can be utilized to foretell how readable a textual content is. This novel strategy gives insights into subjective readability — whether or not a person reader has discovered a textual content accessible — and demonstrates that current readability fashions might be improved by together with suggestions from scroll-based studying interactions. So as to encourage analysis on this space and to assist allow extra customized instruments for language studying and textual content simplification, we’re releasing the dataset of studying interactions generated from our scrolling conduct–based mostly readability evaluation of English-language texts.
Understanding Textual content Issue
There are a number of elements of a textual content that impression how tough it’s to learn, together with the vocabulary degree, the syntactic construction, and general coherence. Conventional machine studying approaches to measure readability have completely relied on such linguistic options. Nevertheless, utilizing these options alone doesn’t work properly for on-line content material, as a result of such content material usually accommodates abbreviations, emojis, damaged textual content, and quick passages, which detrimentally impression the efficiency of readability fashions.
To deal with this, we investigated whether or not combination knowledge concerning the studying interactions of a bunch can be utilized to foretell how tough a textual content is, in addition to how studying interactions might differ based mostly on a readers’ understanding. When studying on a tool, readers sometimes work together with textual content by scrolling in a vertical vogue, which we hypothesize can be utilized as a rough proxy for studying comprehension. With this in thoughts, we recruited 518 paid members and requested them to learn English-language texts of various problem ranges. We recorded the studying interactions by measuring totally different options of the members’ scrolling conduct, such because the velocity, acceleration and variety of occasions areas of textual content have been revisited. We then used this info to supply a set of options for a readability classifier.
Predicting Textual content Issue from Scrolling Conduct
We investigated which forms of scrolling behaviors have been most impacted by textual content problem and examined the importance utilizing linear combined impact fashions. In our arrange, we’ve repeated measures, as a number of members learn the identical texts and every participant reads multiple textual content. Utilizing linear mixed-effect fashions offers us the next confidence that the variations in interactions we’re observing are due to the textual content problem, and never different random results.
Our outcomes confirmed that a number of studying behaviors differed considerably based mostly on the textual content degree, for instance, the common, most and minimal acceleration of scrolling. We discovered probably the most important options to be the overall learn time and the utmost studying speeds.
We then used these options as inputs to a machine studying algorithm. We designed and skilled a help vector machine (i.e., a binary classifier) to foretell whether or not a textual content is both superior or elementary based mostly solely on scrolling behaviors as people interacted with it. The dataset on which the mannequin was skilled accommodates 60 articles, every of which have been learn by a mean of 17 members. From these interactions we produced combination options by taking the imply of the numerous measures throughout members.

We measured the accuracy of the strategy utilizing a metric referred to as f-score, which measures how correct the mannequin is at classifying a textual content as both “straightforward” or “tough” (the place 1.0 displays excellent classification accuracy). We’re in a position to obtain an f-score of 0.77 on this job, utilizing interplay options alone. That is the primary work to point out that it’s potential to foretell the readability of a textual content utilizing solely interplay options.
Enhancing Readability Fashions
So as to reveal the worth of making use of readability measures from scrolling behaviors to current readability fashions, we built-in scroll-based options into the state-of-the-art automated readability evaluation device, which was launched as a part of the OneStopEnglish corpus. We discovered that the addition of interplay options improves the f-score of this mannequin from 0.84 to 0.88. As well as, we have been in a position to considerably outperform this technique through the use of interplay info with easy vocabulary options, such because the variety of phrases within the textual content, reaching a powerful f-score of 0.96.
In our research, we recorded comprehension scores to judge the understanding and readability of textual content for people. Members have been requested three questions per article to evaluate the reader’s understanding of what they’d learn. The interplay options of a person’s scrolling conduct was represented as a excessive dimensional vector. To discover this knowledge, we visualized the studying interplay options for every participant utilizing t-distributed stochastic neighbor embeddings, which is a statistical technique for visualizing high-dimensional knowledge. The outcomes revealed clusters within the comprehension rating based mostly on how properly people understood the textual content. This reveals that there’s implicit info in studying interactions concerning the probability that an particular person has understood a given textual content. We seek advice from this phenomenon as subjective readability. This info might be very helpful for instructional functions or for simplifying on-line content material.
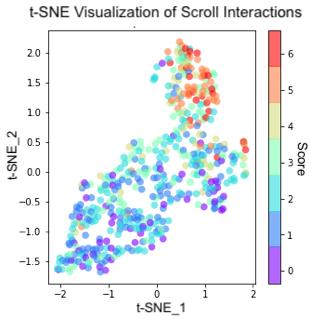 |
| Plot exhibiting t-SNE projection of scroll interactions in 2-dimensions. The colour of every knowledge level corresponds to the comprehension rating. Clusters of comprehension scores point out that there are correlations between studying behaviors and comprehension. |
Lastly, we investigated the extent to which studying interactions differ throughout audiences. We in contrast the common scrolling velocity throughout totally different reader teams, overlaying studying proficiency and the reader’s first language. We discovered that the velocity distribution varies relying on the proficiency and first language of the viewers. This helps the case that first language and proficiency alter the studying behaviors of audiences, which permits us to contextualize the studying conduct of teams and higher perceive which areas of textual content could also be tougher for them to learn.
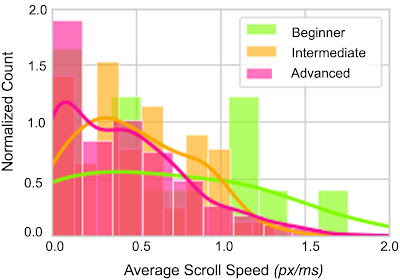 |
| Histogram exhibiting the common speeds of scrolling (in vertical pixels per millisecond) throughout readers of various proficiency ranges (newbie, intermediate and superior), with traces exhibiting the smoothed development for every group. The next common scroll velocity signifies sooner studying occasions. For instance, a more difficult textual content that corresponds to slower scroll speeds by superior readers is related to increased scroll speeds by freshmen as a result of they interact with the textual content solely superficially. |
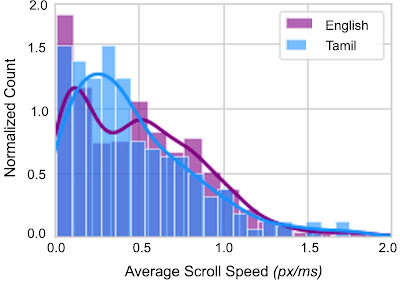 |
| Histogram exhibiting the common speeds of scrolling (in vertical pixels per millisecond) throughout audiences by first language of the readers, Tamil or English, with traces exhibiting the smoothed development for every group. The next common scroll velocity signifies sooner studying occasions. Darkish blue bars are the place the histograms overlap. |
Conclusion
This work is the primary to point out that studying interactions, comparable to scrolling conduct, can be utilized to foretell the readability of textual content, which may yield quite a few advantages. Such measures are language agnostic, unobtrusive, and sturdy to noisy textual content. Implicit consumer suggestions permits perception into readability at a person degree, thereby permitting for a extra inclusive and personalisable evaluation of textual content problem. Moreover, having the ability to choose the subjective readability of textual content advantages language studying and academic apps. We performed a 518 participant research to research the impression of textual content readability on studying interactions and are releasing a novel dataset of the related studying interactions. We affirm that there are statistically important variations in the best way that readers work together with superior and elementary texts, and that the comprehension scores of people correlate with particular measures of scrolling interplay. For extra info our convention presentation is obtainable to view.
Acknowledgements
We thank our collaborators Yevgeni Berzak, Tony Mak and Matt Sharifi, in addition to Dmitry Lagun and Blaise Aguera y Arcas for his or her useful suggestions on the paper.
[ad_2]