
{kind=link}
[ad_1]
A whole lot of thousands and thousands of individuals use spreadsheets, and formulation in these spreadsheets permit customers to carry out subtle analyses and transformations on their knowledge. Though components languages are easier than general-purpose programming languages, writing these formulation can nonetheless be tedious and error-prone, particularly for end-users. We have beforehand developed instruments to grasp patterns in spreadsheet knowledge to robotically fill lacking values in a column, however they weren’t constructed to assist the method of writing formulation.
In “SpreadsheetCoder: Formulation Prediction from Semi-structured Context“, revealed at ICML 2021, we describe a brand new mannequin that learns to robotically generate formulation based mostly on the wealthy context round a goal cell. When a person begins writing a components with the “=” sign up a goal cell, the system generates potential related formulation for that cell by studying patterns of formulation in historic spreadsheets. The mannequin makes use of the information current in neighboring rows and columns of the goal cell in addition to the header row as context. It does this by first embedding the contextual construction of a spreadsheet desk, consisting of neighboring and header cells, after which generates the specified spreadsheet components utilizing this contextual embedding. The components is generated as two parts: 1) the sequence of operators (e.g., SUM, IF, and so on.), and a couple of) the corresponding ranges on which the operators are utilized (e.g., “A2:A10”). The characteristic based mostly on this mannequin is now typically accessible to Google Sheets customers.
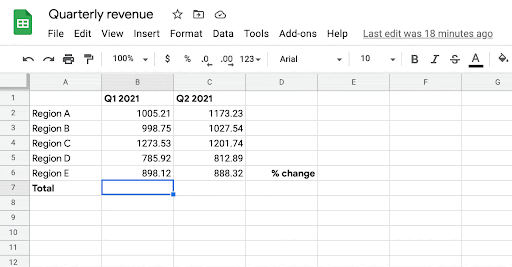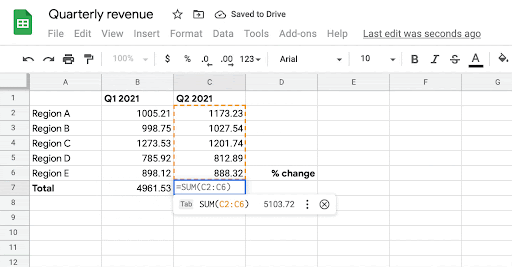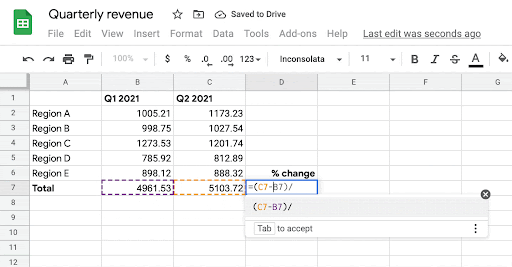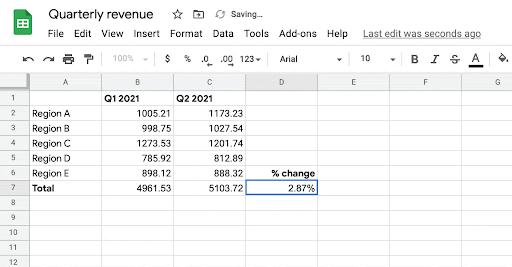 |
| Given the person’s intent to enter a components in cells B7, C7, and D7, the system robotically infers the most probably components the person may need to write in these cells. |
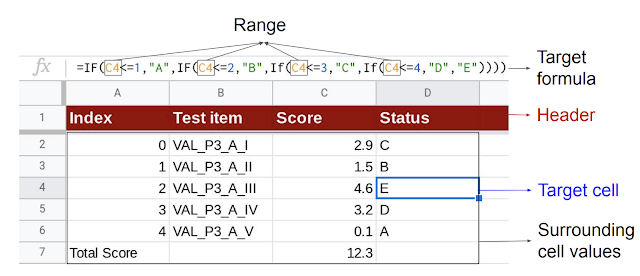 |
| Given the goal cell (D4), the mannequin makes use of the header and surrounding cell values as context to generate the goal components consisting of the corresponding sequence of operators and vary. |
Mannequin Structure
The mannequin makes use of an encoder-decoder structure that enables the flexibleness to embed a number of kinds of contextual info (akin to that contained in neighboring rows, columns, headers, and so on.) within the encoder, which the decoder can use to generate desired formulation. To compute the embedding of the tabular context, it first makes use of a BERT-based structure to encode a number of rows above and under the goal cell (along with the header row). The content material in every cell consists of its knowledge sort (akin to numeric, string, and so on.) and its worth, and the cell contents current in the identical row are concatenated collectively right into a token sequence to be embedded utilizing the BERT encoder. Equally, it encodes a number of columns to the left and to the appropriate of the goal cell. Lastly, it performs a row-wise and column-wise convolution on the 2 BERT encoders to compute an aggregated illustration of the context.
The decoder makes use of a lengthy short-term reminiscence (LSTM) structure to generate the specified goal components as a sequence of tokens by first predicting a formula-sketch (consisting of components operators with out ranges) after which producing the corresponding ranges utilizing cell addresses relative to the goal cell. It moreover leverages an consideration mechanism to compute consideration vectors over the header and cell knowledge, that are concatenated to the LSTM output layer earlier than making the predictions.
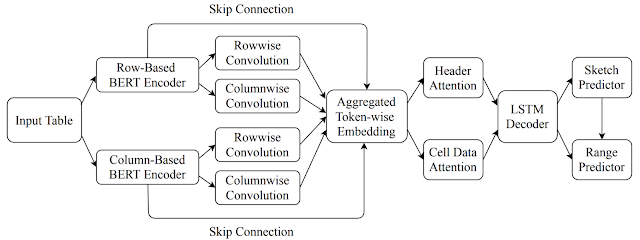 |
| The general structure of the components prediction mannequin. |
Along with the information current in neighboring rows and columns, the mannequin additionally leverages further info from the high-level sheet construction, akin to headers. Utilizing TPUs for mannequin predictions, we guarantee low latency on producing components options and are in a position to deal with extra requests on fewer machines.
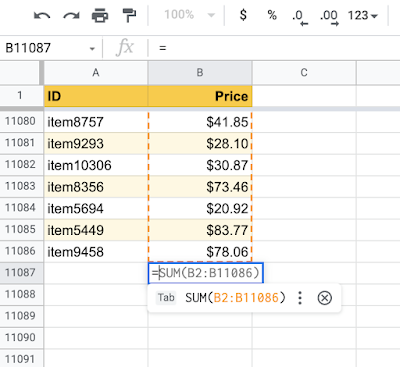 |
| Leveraging the high-level spreadsheet construction, the mannequin can study ranges that span hundreds of rows. |
Outcomes
Within the paper, we educated the mannequin on a corpus of spreadsheets created by and shared with Googlers. We break up 46k Google Sheets with formulation into 42k for coaching, 2.3k for validation, and 1.7k for testing. The mannequin achieves a 42.5% top-1 full-formula accuracy, and 57.4% top-1 formula-sketch accuracy, each of which we discover excessive sufficient to be virtually helpful in our preliminary person research. We carry out an ablation research, through which we take a look at a number of simplifications of the mannequin by eradicating completely different parts, and discover that having row- and column-based context embedding in addition to header info is necessary for fashions to carry out properly.
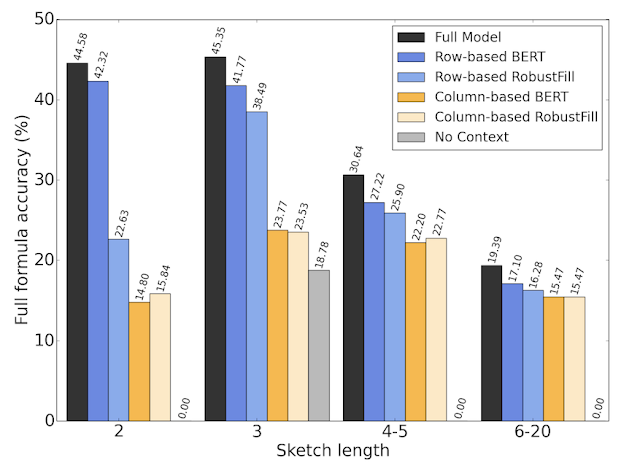 |
| The efficiency of various ablations of our mannequin with growing lengths of the goal components. |
Conclusion
Our mannequin illustrates the advantages of studying to signify the two-dimensional relational construction of the spreadsheet tables along with high-level structural info, akin to desk headers, to facilitate components predictions. There are a number of thrilling analysis instructions, each by way of designing new mannequin architectures to include extra tabular construction in addition to extending the mannequin to assist extra functions akin to bug detection and automatic chart creation in spreadsheets. We’re additionally wanting ahead to seeing how customers use this characteristic and studying from suggestions for future enhancements.
Acknowledgements
We gratefully acknowledge the important thing contributions of the opposite group members, together with Alexander Burmistrov, Xinyun Chen, Hanjun Dai, Prashant Khurana, Petros Maniatis, Rahul Srinivasan, Charles Sutton, Amanuel Taddesse, Peilun Zhang, and Denny Zhou.
[ad_2]