

{kind=link}
[ad_1]
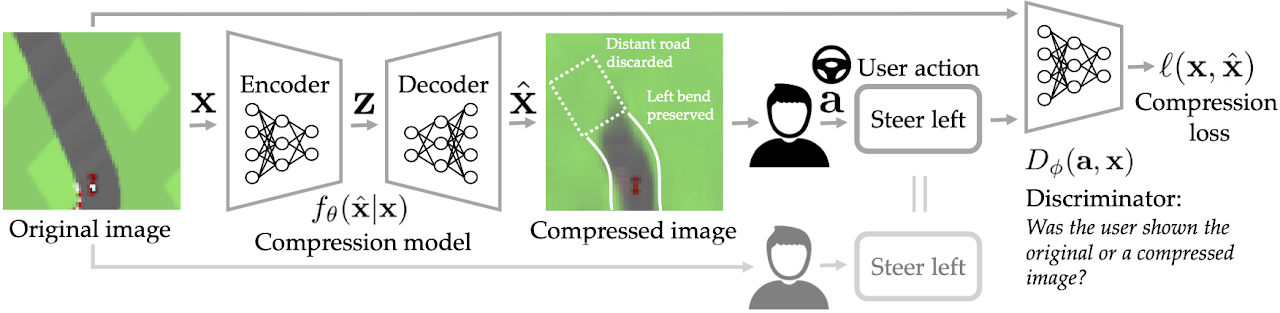
Fig. 1: Given the unique picture $mathbf{x}$, we wish to generate a compressed picture $hat{mathbf{x}}$ such that the person’s motion $mathbf{a}$ upon seeing the compressed picture is much like what it could have been had the person seen the unique picture as an alternative. In a 2D top-down automobile racing online game with a particularly excessive compression fee (50%), our compression mannequin learns to protect bends and discard the highway farther forward.
Think about remotely working a Mars rover from a desk on Earth. The low-bandwidth community connection could make it difficult for the teleoperation system to offer the person with high-dimensional observations like photos. One method to this drawback is to make use of information compression to reduce the variety of bits that have to be communicated over the community: for instance, the rover can compress the photographs it takes on Mars earlier than sending them to the human operator on Earth. Normal lossy picture compression algorithms would try to protect the picture’s look. Nevertheless, at low bitrates, this method can waste valuable bits on data that the person doesn’t really want in an effort to carry out their present process. For instance, when deciding the place to steer and the way a lot to speed up, the person in all probability solely pays consideration to a small subset of visible options, comparable to obstacles and landmarks. Our perception is that we must always deal with preserving these options that have an effect on person habits, as an alternative of options that solely have an effect on visible look (e.g., the colour of the sky). On this publish, we define a pragmatic compression algorithm known as PICO that achieves decrease bitrates by deliberately permitting reconstructed photos to deviate drastically from the visible look of their originals, and as an alternative optimizing reconstructions for the downstream duties that the person desires to carry out with them (see Fig. 1).
Pragmatic Compression
The easy method to optimizing reconstructions for a selected process could be to coach the compression mannequin to immediately decrease the loss operate for that process. For instance, if the person’s process is to categorise MNIST digits, then one may practice the compression mannequin to generate reconstructions that decrease the cross-entropy lack of the person’s picture classification coverage. Nevertheless, this method requires prior data of how you can consider the utility of the person’s actions (e.g., the cross-entropy loss for digit labels), and the flexibility to suit an correct mannequin of the person’s decision-making coverage (e.g., a picture classifier). The important thing thought in our work is that we are able to keep away from these limitations by framing the issue extra usually: as an alternative of making an attempt to optimize for a selected process, we goal to produce a compressed picture that induces the person to take the identical motion that they might have taken had they seen the unique picture. Moreover, we goal to take action within the streaming setting (e.g., real-time video video games), the place we don’t assume entry to ground-truth motion labels for the unique photos, and therefore can’t evaluate the person’s motion upon seeing the compressed picture to some ground-truth motion. To perform this, we use an adversarial studying process that includes coaching a discriminator to detect whether or not a person’s motion was taken in response to the compressed picture or the unique. We name our technique PragmatIc COmpression (PICO).
Maximizing Practical Similarity of Photographs by way of Human-in-the-Loop Adversarial Studying
Let $mathbf{x}$ denote the unique picture, $hat{mathbf{x}}$ the compressed picture, $mathbf{a}$ the person’s motion, $pi$ the person’s decision-making coverage, and $f_{theta}$ the compression mannequin. PICO goals to reduce the divergence of the person’s coverage evaluated on the compressed picture $pi(mathbf{a} | hat{mathbf{x}})$ from the person’s coverage evaluated on the unique picture $pi(mathbf{a} | mathbf{x})$. For the reason that person’s coverage $pi$ is unknown, we roughly decrease the divergence utilizing conditional generative adversarial networks, the place the aspect data is the unique picture $mathbf{x}$, the generator is the compression mannequin $f_{theta}(hat{mathbf{x}} | mathbf{x})$, and the discriminator $D(mathbf{a}, mathbf{x})$ tries to discriminate the motion $mathbf{a}$ that the person takes after seeing the generated picture $hat{mathbf{x}}$ (see Fig. 1).
To coach the motion discriminator $D(mathbf{a}, mathbf{x})$, we want optimistic and detrimental examples of person habits; in our case, examples of person habits with and with out compression. To gather these examples, we randomize whether or not the person sees the compressed picture or the unique earlier than taking an motion. When the person sees the unique $mathbf{x}$ and takes motion $mathbf{a}$, and we report the pair $(mathbf{a}, mathbf{x})$ as a optimistic instance of person habits. When the person sees the compressed picture $hat{mathbf{x}}$ and takes motion $mathbf{a}$, we report $(mathbf{a}, mathbf{x})$ as a detrimental instance. We then practice an motion discriminator $D_{phi}(mathbf{a}, mathbf{x})$ to reduce the usual binary cross-entropy loss. Observe that this motion discriminator is conditioned on the unique picture $mathbf{x}$ and the person motion $mathbf{a}$, however not the compressed picture $hat{mathbf{x}}$—this ensures that the motion discriminator captures variations in person habits brought on by compression, whereas ignoring variations between the unique and compressed photos that don’t have an effect on person habits.
Distilling the Discriminator and Coaching the Compression Mannequin
The motion discriminator $D_{phi}(mathbf{a}, mathbf{x})$ offers us a approach to roughly consider the person’s coverage divergence. Nevertheless, we can’t practice the compression mannequin $f_{theta}(hat{mathbf{x}}|mathbf{x})$ to optimize this loss immediately, since $D_{phi}$ doesn’t take the compressed picture $hat{mathbf{x}}$ as enter. To handle this concern, we distill the skilled motion discriminator $D_{phi}(mathbf{a}, mathbf{x})$, which captures variations in person habits brought on by compression, into a picture discriminator $D_{psi}(hat{mathbf{x}}, mathbf{x})$ that hyperlinks the compressed photos to those behavioral variations. Particulars might be present in Part 3.2 of the full paper.
Structured Compression utilizing Generative Fashions
One method to representing the compression mannequin $f_{theta}$ may very well be to construction it as a variational autoencoder (VAE), and practice the VAE finish to finish on PICO’s adversarial loss operate as an alternative of the usual reconstruction error loss. This method is totally basic, however requires coaching a separate mannequin for every desired bitrate, and may require intensive exploration of the pixel output house earlier than it discovers an efficient compression mannequin. To simplify variable-rate compression and exploration in our experiments, we forgo end-to-end coaching: we first practice a generative mannequin on a batch of photos with out the human within the loop by optimizing a task-agnostic perceptual loss, then practice our compression mannequin to pick out which subset of latent options to transmit for any given picture. We use quite a lot of completely different generative fashions in our experiments, together with VAE, $beta$-VAE, NVAE, and StyleGAN2 fashions.
Person Research
We consider our technique by way of experiments with human contributors on 4 duties: studying handwritten digits, shopping a web-based buying catalogue of vehicles, verifying photographs of faces, and taking part in a automobile racing online game. The outcomes present that our technique learns to match the person’s actions with and with out compression at decrease bitrates than baseline strategies, and adapts the compression mannequin to the person’s habits.
Transcribing Handwritten Digits
For customers performing a digit studying process, PICO discovered to protect the digit quantity, whereas a baseline compression technique that optimizes perceptual similarity learns to protect task-irrelevant particulars like line thickness and pose angle.

Fig. 2: Left: the y-axis represents the speed of settlement of person actions (digit labels) upon seeing a compressed picture with person actions upon seeing the unique model of that picture. Proper: every of the 5 columns within the two teams of compressed photos represents a special pattern from the stochastic compression mannequin $f(hat{mathbf{x}}|mathbf{x})$ at bitrate 0.011.
Automotive Procuring and Surveying
We requested one group of contributors to carry out a “buying” process, wherein we instructed them to pick out photos of vehicles that they understand to be inside their price range. For these customers, PICO discovered to protect the sportiness and perceived worth of the automobile, whereas randomizing shade and background.
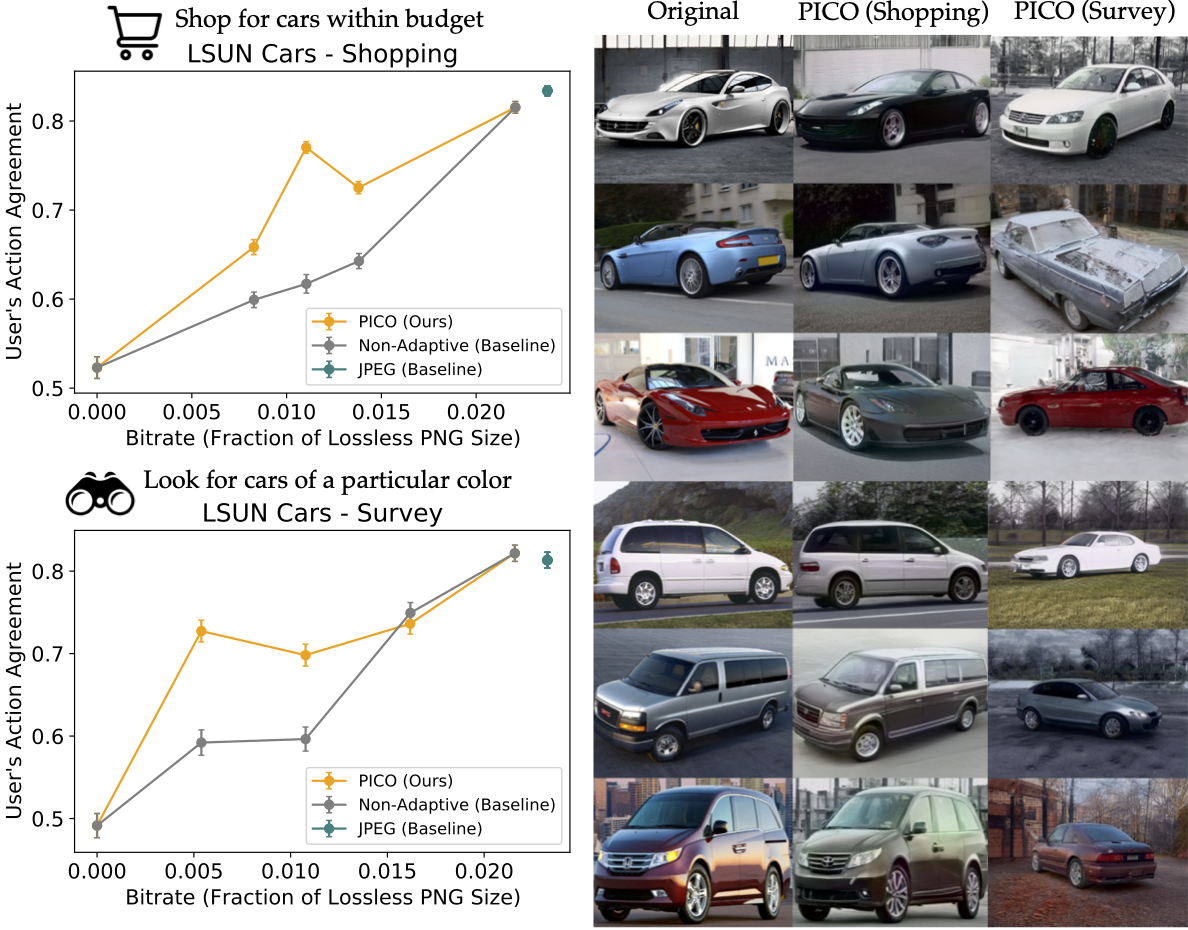
Fig. 3
To check whether or not PICO can adapt the compression mannequin to the particular wants of various downstream duties in the identical area, we requested one other group of contributors to carry out a special process with the identical automobile photos: survey paint jobs (whereas ignoring perceived worth and different options). For these customers, PICO discovered to protect the colour of the automobile, whereas randomizing the mannequin and pose of the automobile.
Picture Attribute Verification
For customers performing a photograph verification process that includes checking for eyeglasses, PICO discovered to protect eyeglasses whereas randomizing faces, hats, and different task-irrelevant options. Once we modified the duty to checking for hats, PICO tailored to preserving hats whereas randomizing eyeglasses.
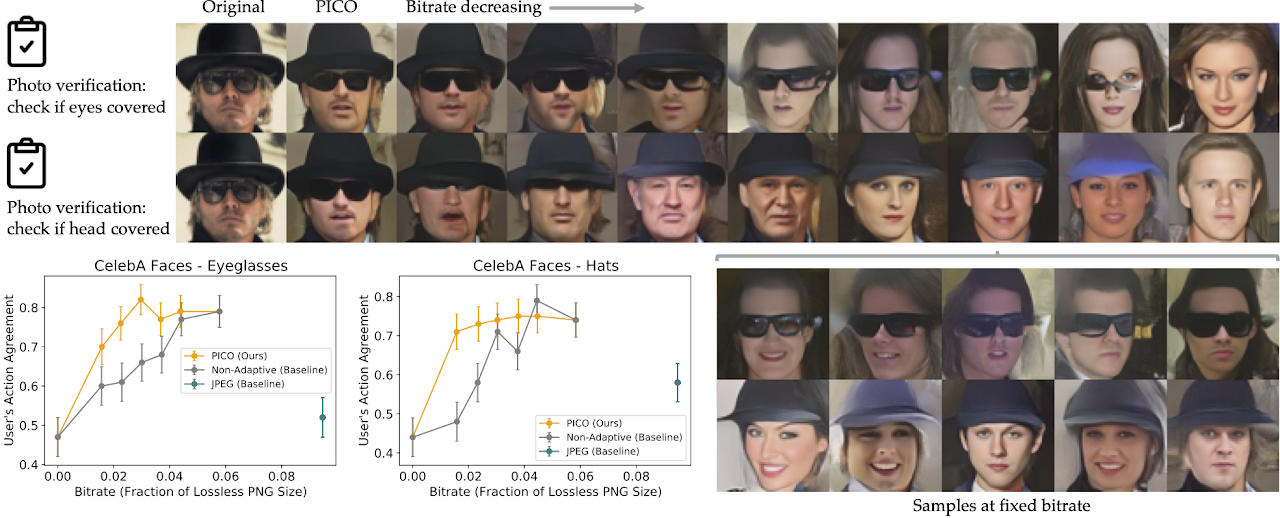
Fig. 4
Automotive Racing Video Recreation
For customers taking part in a 2D automobile racing online game with a particularly excessive compression fee (50%), PICO discovered to protect bends within the highway higher than baseline strategies, enabling customers to drive extra safely and keep off the grass.


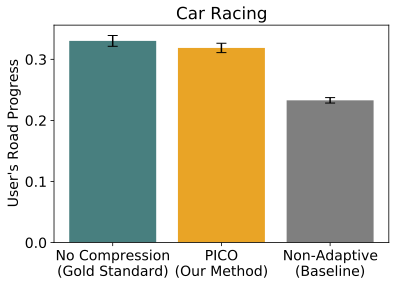
Fig. 5: Left: what is definitely occurring (uncompressed). Proper: what the person sees (compressed with PICO).
What’s Subsequent?
This work is a proof of idea that makes use of pre-trained generative fashions to hurry up human-in-the-loop studying throughout our small-scale person research. Nevertheless, end-to-end coaching of the compression mannequin could also be sensible for real-world internet companies and different purposes, the place massive numbers of customers already frequently work together with the system. PICO’s adversarial coaching process, which includes randomizing whether or not customers see compressed or uncompressed photos, might be carried out in a simple method utilizing customary A/B testing frameworks. Moreover, in our experiments, we consider on extraordinarily excessive compression charges in an effort to spotlight variations between PICO and different strategies, which ends up in massive visible distortions—in real-world settings with decrease compression charges, we might probably see smaller distortions.
Continued enhancements to generative mannequin architectures for video, audio, and textual content may unlock a variety of real-world purposes for pragmatic compression, together with video compression for robotic house exploration, audio compression for listening to aids, and spatial compression for digital actuality. We’re particularly enthusiastic about utilizing PICO to shorten media for human consumption: for instance, summarizing textual content in such a method {that a} person who solely reads the abstract can reply studying comprehension questions simply as precisely as if they’d learn the complete textual content, or trimming a podcast to get rid of pauses and filler phrases that don’t talk helpful data.
If you wish to be taught extra, try our pre-print on arXiv: Siddharth Reddy, Anca D. Dragan, Sergey Levine, Pragmatic Picture Compression for Human-in-the-Loop Resolution-Making, arXiv, 2021.
To encourage replication and extensions, we’ve launched our code. Extra movies can be found by way of the venture web site.
[ad_2]