

{kind=link}
[ad_1]
Nvidia AI Enterprise is an end-to-end AI software program stack. It contains software program to scrub information and put together it for coaching, carry out the coaching of neural networks, convert the mannequin to a extra environment friendly type for inference, and deploy it to an inference server.
As well as, the Nvidia AI software program suite contains GPU, DPU (information processing unit), and accelerated community assist for Kubernetes (the cloud-native deployment layer on the diagram beneath), and optimized assist for shared units on VMware vSphere with Tanzu. Tanzu Fundamental permits you to run and handle Kubernetes in vSphere. (VMware Tanzu Labs is the brand new identify for Pivotal Labs.)
Nvidia LaunchPad is a trial program that provides AI and information science groups short-term entry to the whole Nvidia AI stack operating on personal compute infrastructure. Nvidia LaunchPad gives curated labs for Nvidia AI Enterprise, with entry to Nvidia specialists and coaching modules.
Nvidia AI Enterprise is an try to take AI mannequin coaching and deployment out of the realm of educational analysis and of the largest tech corporations, which have already got PhD-level information scientists and information facilities stuffed with GPUs, and into the realm of bizarre enterprises that want to use AI for operations, product improvement, advertising, HR, and different areas. LaunchPad is a free approach for these corporations to let their IT directors and AI practitioners achieve hands-on expertise with the Nvidia AI Enterprise stack on supported {hardware}.
The commonest various to Nvidia AI Enterprise and LaunchPad is to make use of the GPUs (and different mannequin coaching accelerators, reminiscent of TPUs and FPGAs) and AI software program accessible from the hyperscale cloud suppliers, mixed with the programs, fashions, and labs provided by the cloud distributors and the AI framework open supply communities.
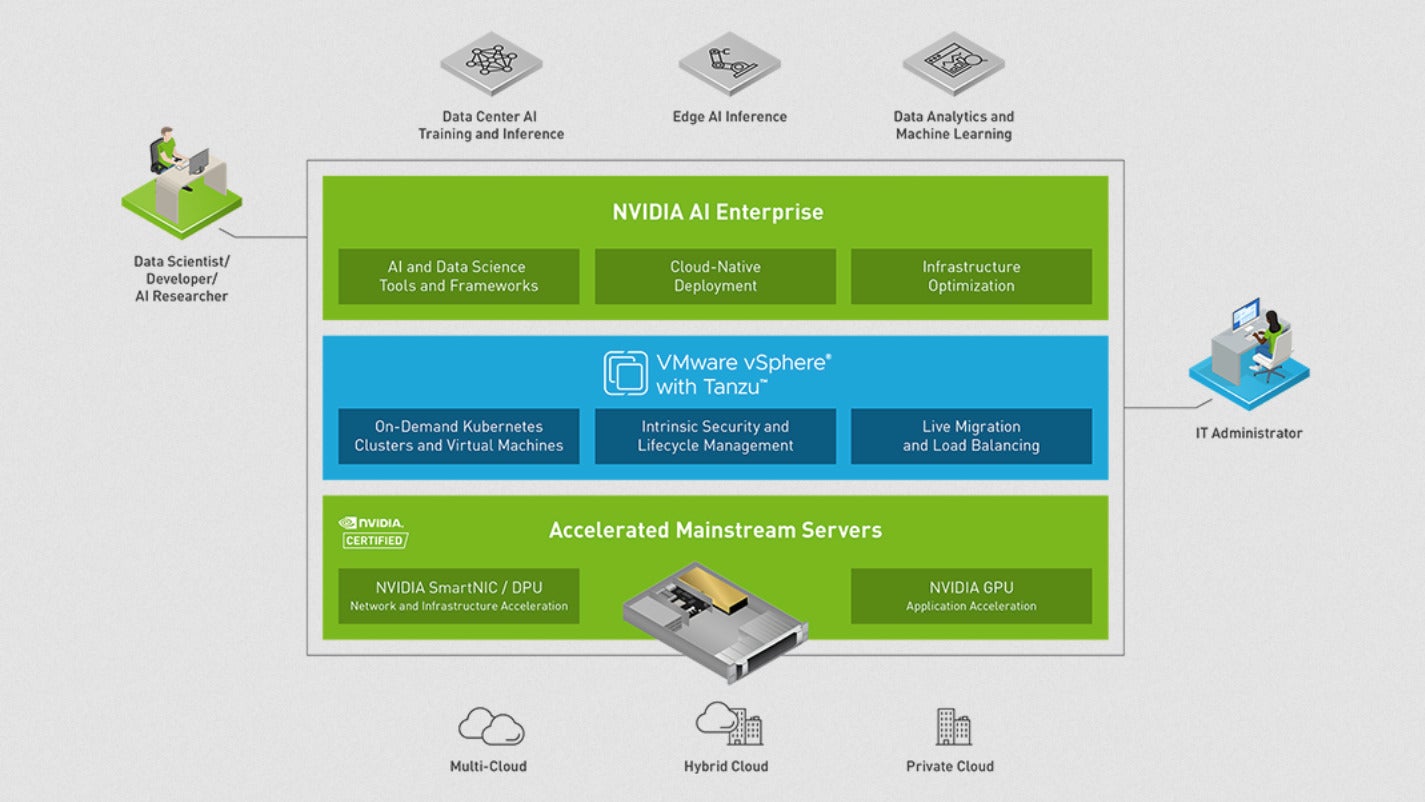 Nvidia
NvidiaThe Nvidia AI Enterprise stack, starting from acceleration {hardware} on the backside to information science instruments and frameworks on the high.
What’s in Nvidia AI Enterprise
Nvidia AI Enterprise gives an built-in infrastructure layer for the event and deployment of AI options. It contains pre-trained fashions, GPU-aware software program for information prep (RAPIDS), GPU-aware deep studying frameworks reminiscent of TensorFlow and PyTorch, software program to transform fashions to a extra environment friendly type for inference (TensorRT), and a scalable inference server (Triton).
A library of pre-trained fashions is accessible by Nvidia’s NGC catalog to be used with the Nvidia AI Enterprise software program suite; these fashions might be fine-tuned in your datasets utilizing Nvidia AI Enterprise TensorFlow Containers, for instance. The deep studying frameworks provided, whereas primarily based on their open supply variations, have been optimized for Nvidia GPUs.
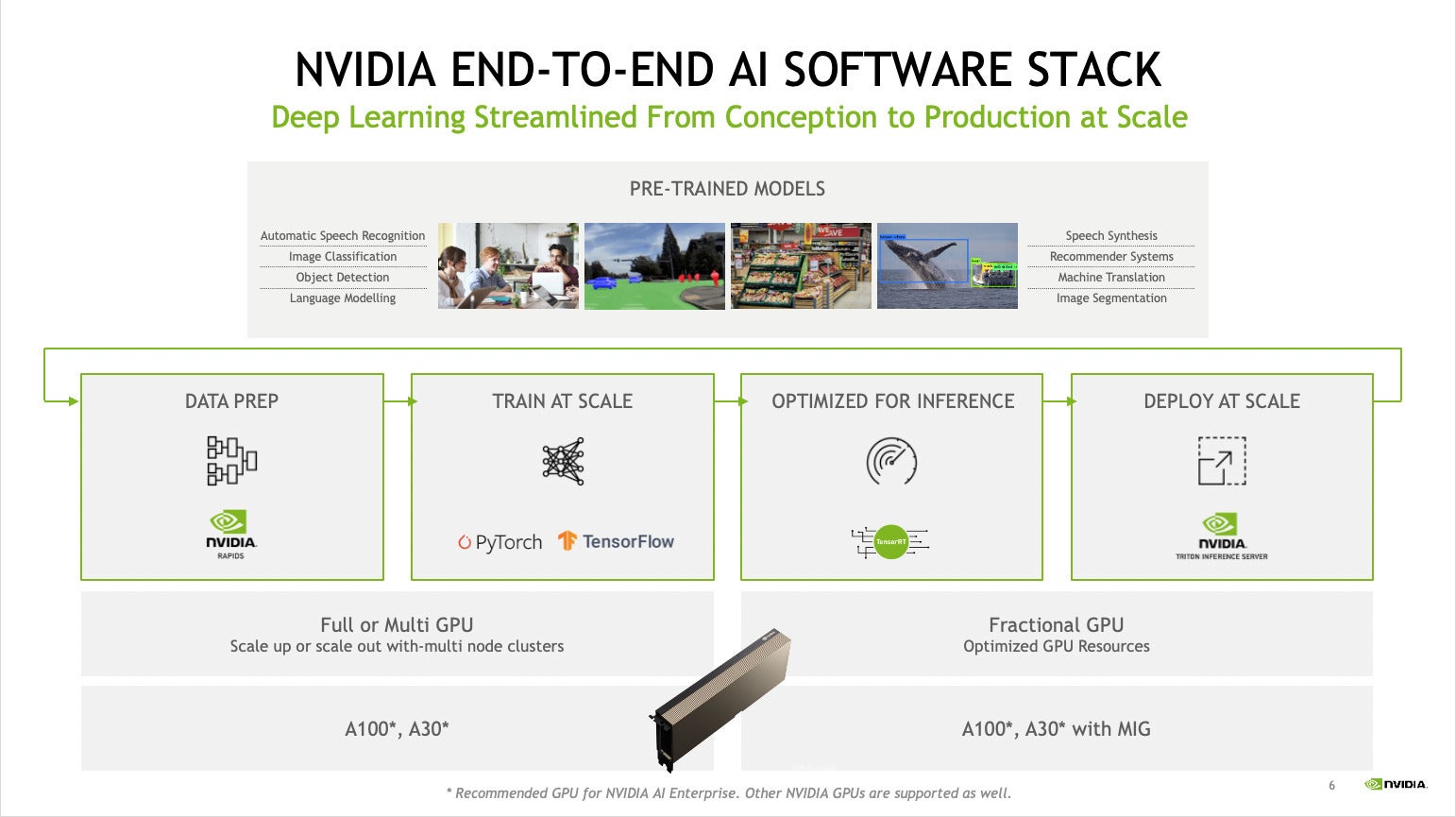 Nvidia
NvidiaNvidia AI software program stack circulation diagram. The {hardware} notes on the backside left are for coaching; the notes on the backside proper are for inference.
Nvidia AI Enterprise and LaunchPad {hardware}
Nvidia has been making lots of noise about DGX methods, which have 4 to 16 A100 GPUs in numerous type components, starting from a tower workgroup equipment to rack-based methods designed to be used in information facilities. Whereas the corporate remains to be dedicated to DGX for giant installations, for the needs of Nvidia AI Enterprise trials beneath the LaunchPad applications, the corporate has assembled smaller 1U to 2U rack-mounted methods with commodity servers primarily based on twin Intel Xeon Gold 6354 CPUs, single Nvidia T4 or A30 GPUs, and Nvidia DPUs (information processing models). 9 Equinix colocation areas worldwide every have 20 such rack-mounted servers to be used by Nvidia prospects who qualify for LaunchPad trials.
Nvidia recommends the identical methods for enterprise deployments of Nvidia AI Enterprise. These methods can be found for hire or lease along with buy.
 Nvidia
NvidiaServer {hardware} to assist LaunchPad and Nvidia AI Enterprise. Whereas the LaunchPad servers are all Dell R750s, that was a matter of availability slightly than choice. All the corporations listed on the suitable manufacture servers supported by Nvidia for Nvidia AI Enterprise.
Take a look at driving Nvidia AI Enterprise
Nvidia gives three totally different trial applications to assist prospects get began with Nvidia AI Enterprise. For AI practitioners who simply need to get their toes moist, there’s a check drive demo that features predicting New York Metropolis taxi fares and attempting BERT query answering in TensorFlow. The check drive requires about an hour of hands-on work, and gives 48 hours of entry.
LaunchPad is barely extra in depth. It gives hands-on labs for AI practitioners and IT workers, requiring about eight hours of hands-on work, with entry to the methods for 2 weeks, with an non-compulsory extension to 4 weeks.
The third trial program is a 90-day on-premises analysis, enough to carry out a POC (proof of idea). The shopper wants to provide (or hire) an Nvidia-certified system with VMware vSphere 7 u2 (or later), and Nvidia gives free analysis licenses.
 Nvidia
NvidiaThere are 3 ways to trial Nvidia AI Enterprise: a one-hour check drive demo with 48-hour entry; the Nvidia LaunchPad’s eight-hour labs with two weeks of entry; and a 90-day analysis license to be used on-prem.
Nvidia LaunchPad demo for IT directors
As I’m extra focused on information science than I’m in IT administration, I merely watched a demo of the hands-on administration lab, though I had entry to it later. The primary screenshot beneath reveals the start of the lab directions; the second reveals a web page from the VMware vSphere consumer internet interface. Based on Nvidia, many of the IT admins they prepare are already aware of vSphere and Home windows, however are much less aware of Ubuntu Linux.
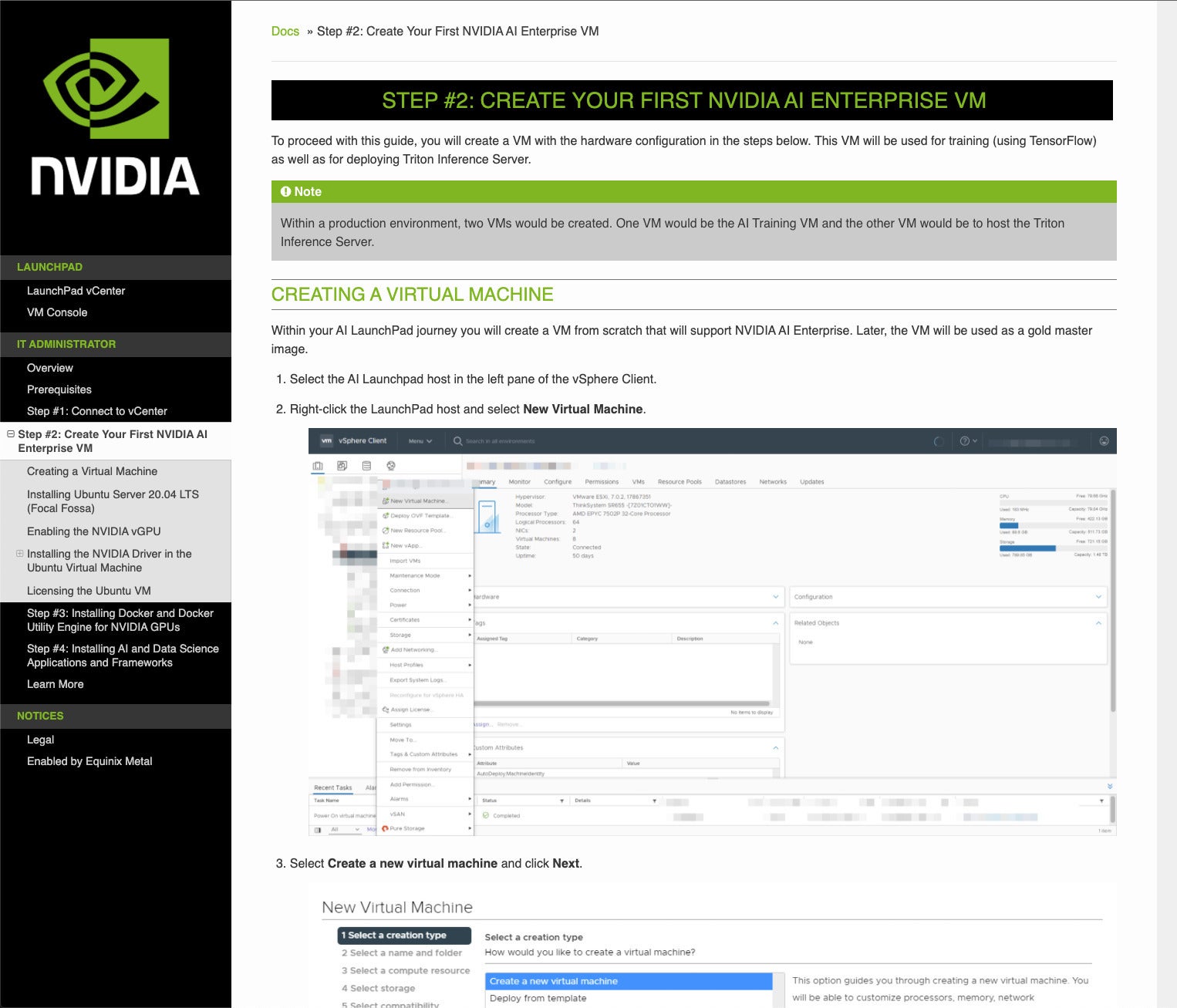 IDG
IDGThis display screen presents the directions for creating an Nvidia AI Enterprise digital machine utilizing VMware vSphere. It’s a part of the IT admin coaching.
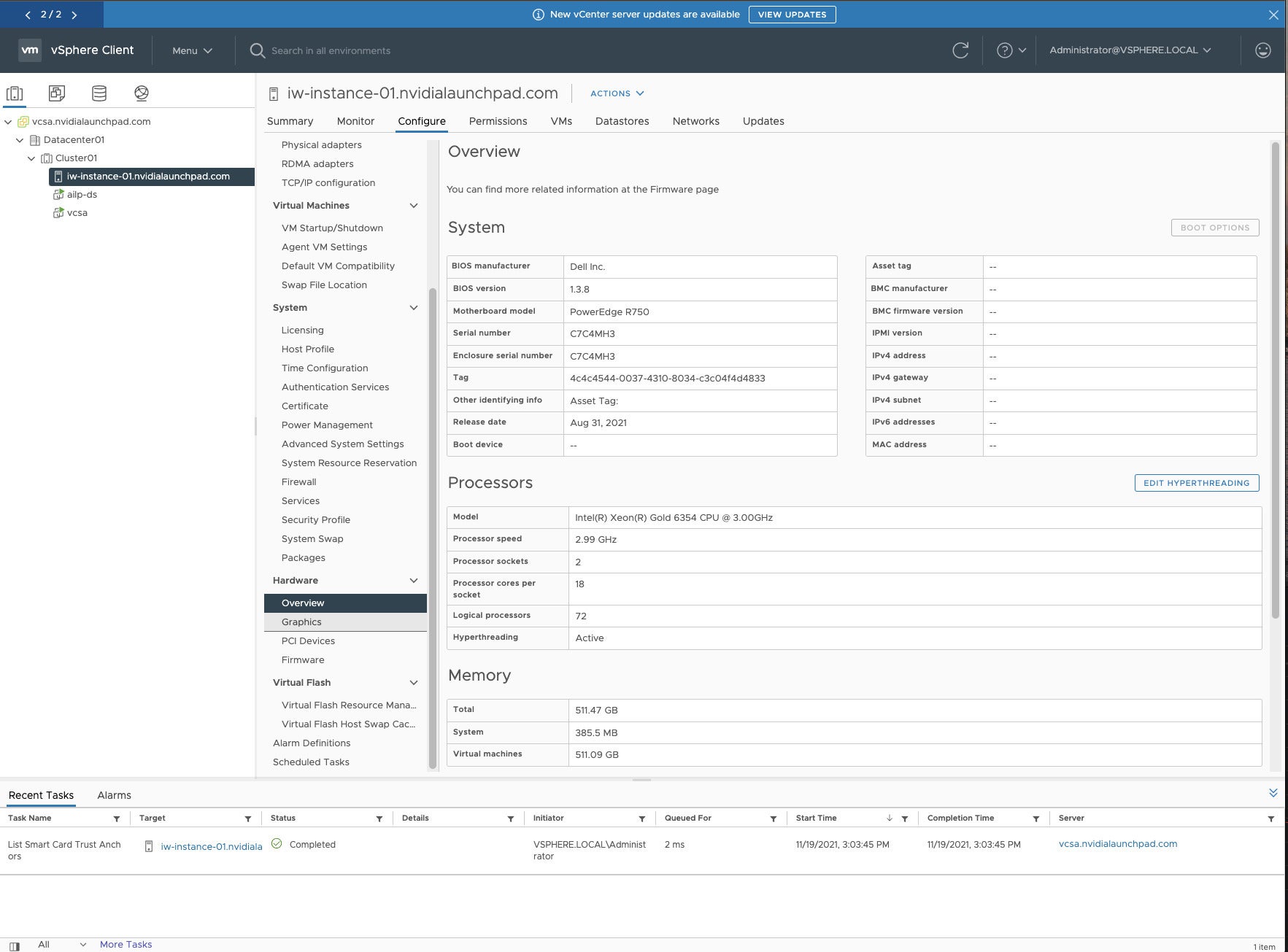 IDG
IDGThis display screen reveals the {hardware} overview for the Nvidia AI Enterprise digital machine created for tutorial functions in VMware vSphere.
Launchpad lab for AI practitioners
I spent most of a day going by the LaunchPad lab for AI practitioners, delivered primarily as a Jupyter Pocket book. The parents at Nvidia advised me it was a 400-level tutorial; it actually would have been if I needed to write the code myself. Because it was, all of the code was already written, there was a skilled base BERT mannequin to fine-tune, and all of the coaching and check information for fine-tuning was provided from SQuAD (Stanford Query Answering Dataset).
The A30 GPU within the server provided for the LaunchPad bought a exercise after I bought to the fine-tuning step, which took 97 minutes. With out the GPU, it will have taken for much longer. To coach the BERT mannequin from scratch on, say, the contents of Wikipedia, is a serious enterprise requiring many GPUs and a very long time (in all probability weeks).
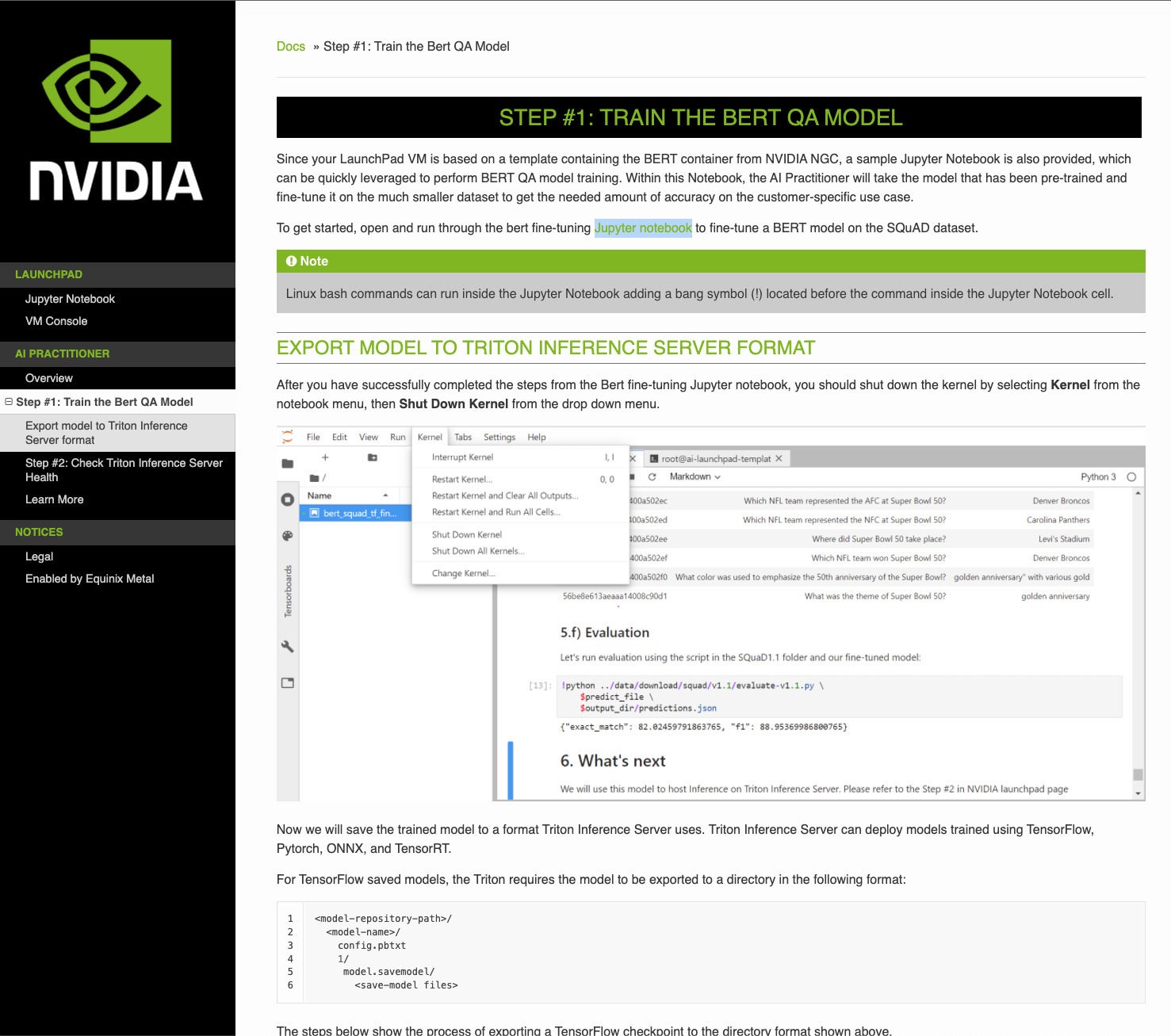 IDG
IDGThe higher part of this web page sends the consumer to a Jupyter Pocket book that fine-tunes a BERT mannequin for customer support. The decrease part explains tips on how to export the skilled mannequin to the inference server. By the best way, for those who neglect to close down the kernel after the fine-tuning step, the export step will fail with mysterious error tracebacks. Don’t ask me how I do know that.
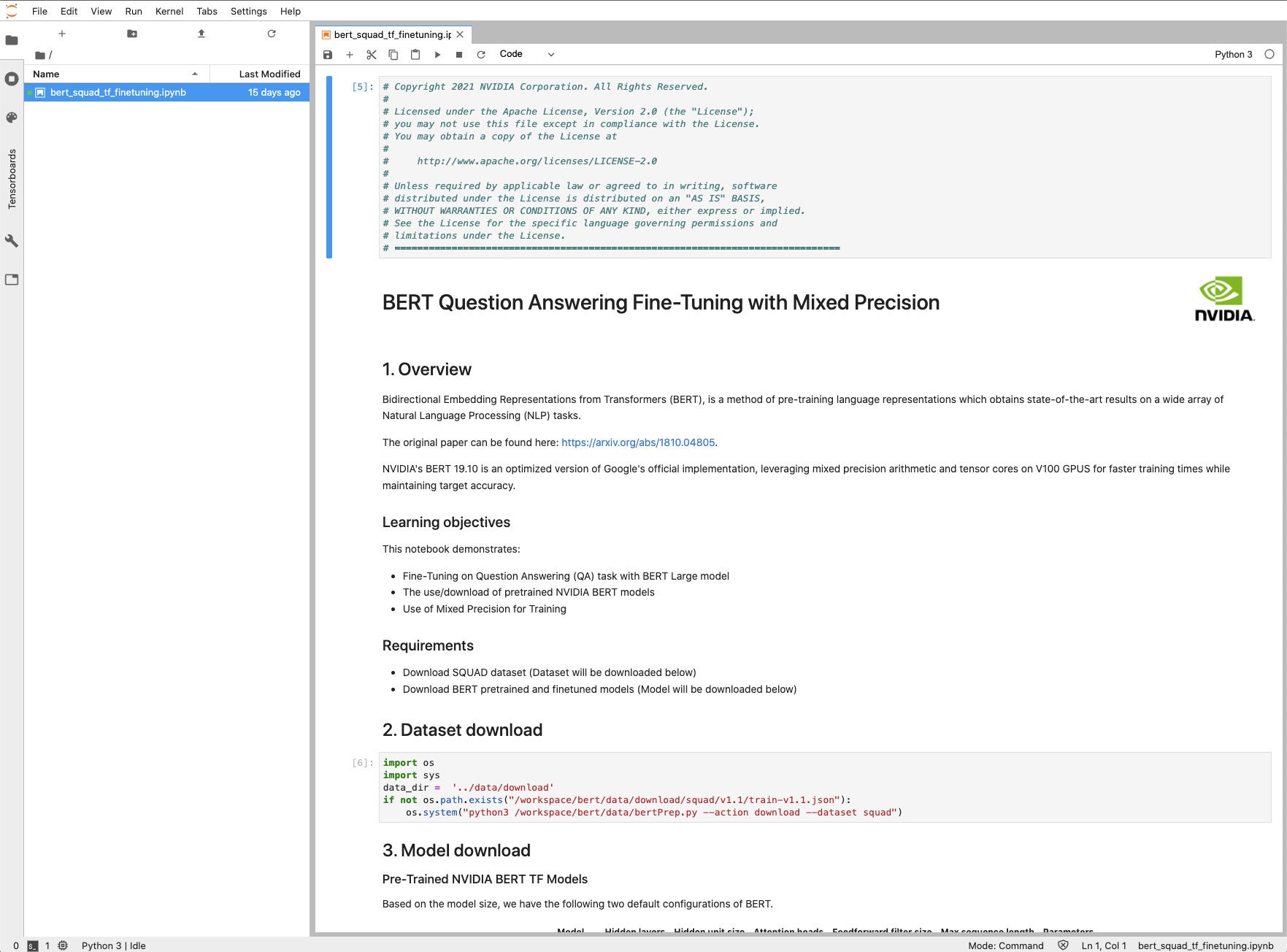 IDG
IDGThat is the start of the Jupyter Pocket book that implements step one of the AI Practitioner course. It makes use of a pre-trained BERT TensorFlow mannequin, downloaded in step 3, after which fine-tunes it for a smaller, targeted dataset, downloaded in step 2.
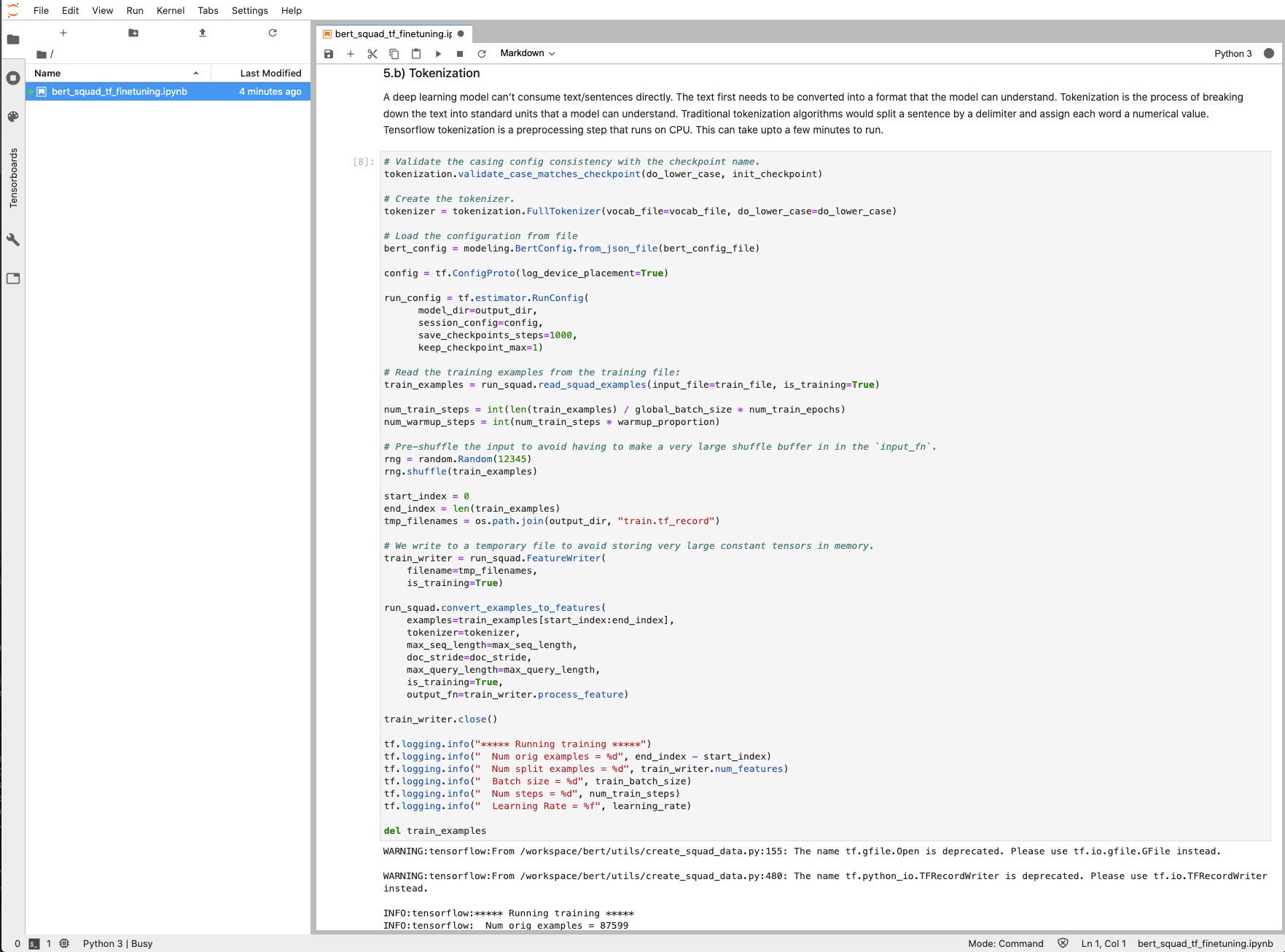 IDG
IDGThis step makes use of TensorFlow to transform instance sentences to tokenized type. It takes a couple of minutes to run on the CPUs.
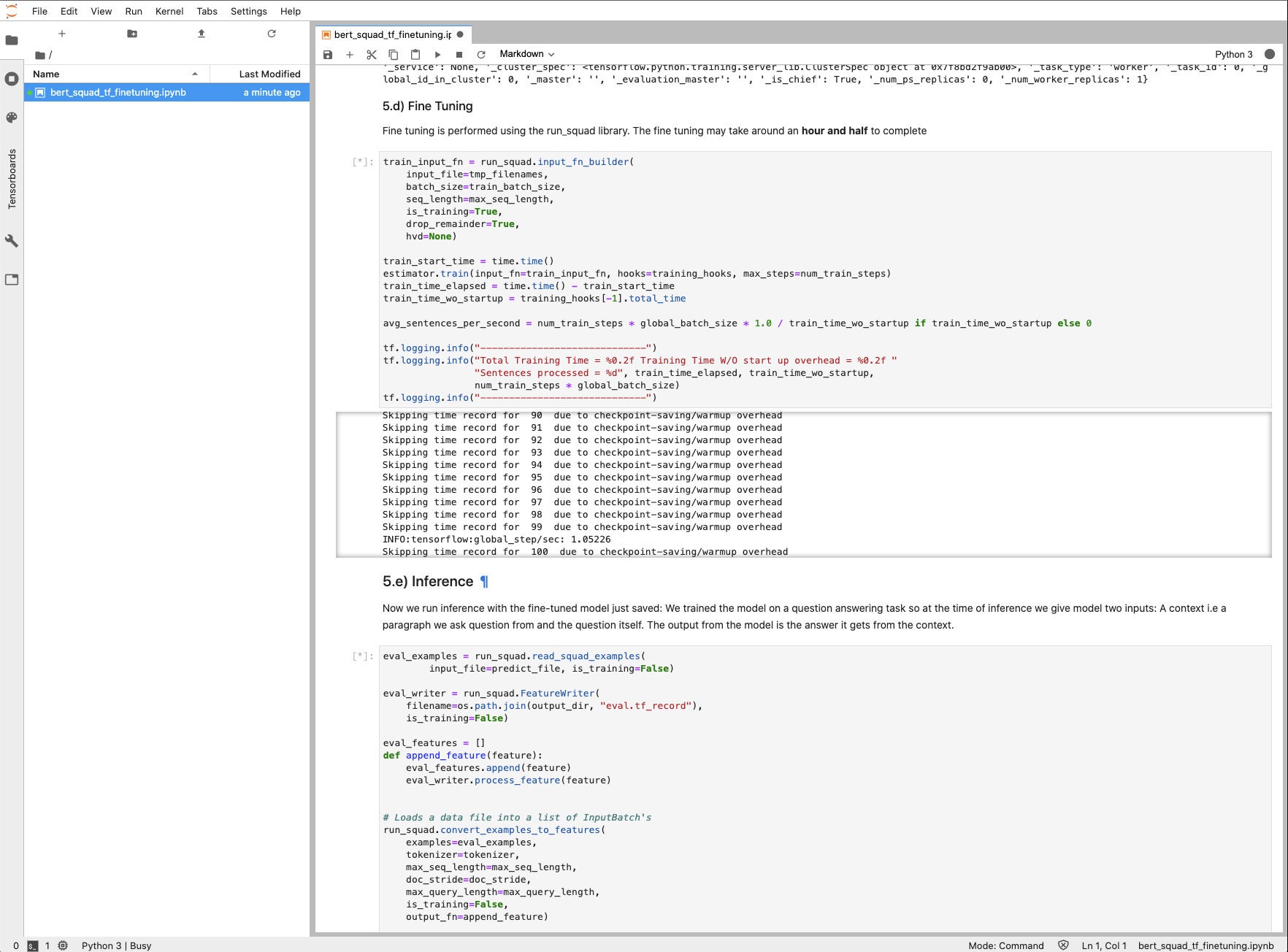 IDG
IDGThe fine-tuning step ought to take about 90 minutes utilizing the A30 GPU. Right here we’re simply starting the coaching on the estimator.prepare(…) name.
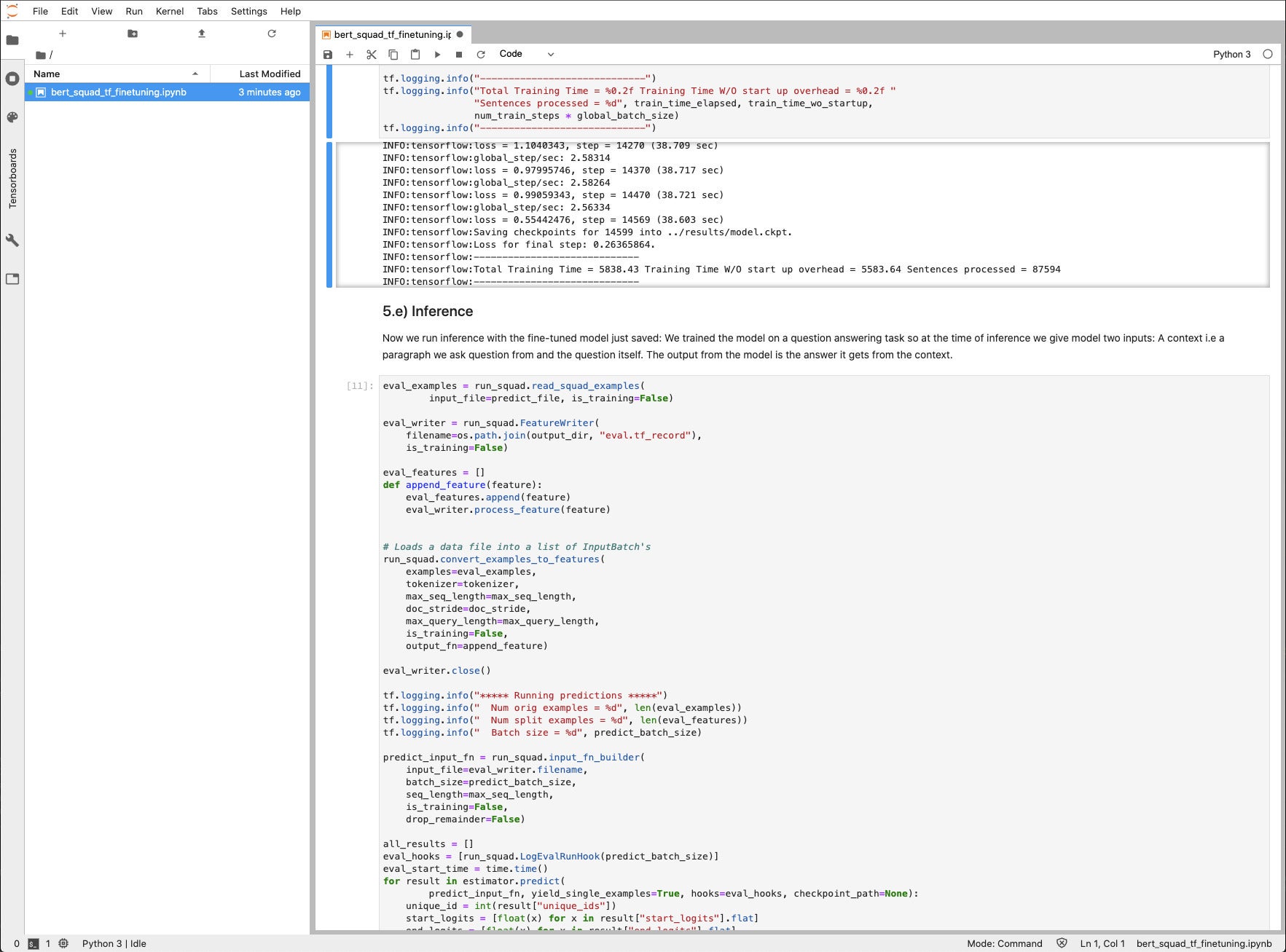 IDG
IDGThe fine-tuning coaching step is lastly carried out, in 5838 seconds (97 minutes) whole. About 4 minutes was used for start-up overhead.
 IDG
IDGThe Jupyter Pocket book continues with an inference check and an analysis step, each utilizing the fine-tuned TensorFlow BERT mannequin. After this step we shut down the Jupyter Pocket book and begin the Triton inference server within the VM, then check the Triton server from a Jupyter console.
Total, Nvidia AI Enterprise is an excellent {hardware}/software program package deal for tackling AI issues, and LaunchPad is a handy method to grow to be aware of Nvidia AI Enterprise. I used to be struck by how nicely the deep studying software program takes benefit of the newest improvements in Ampere GPUs, reminiscent of combined precision arithmetic and tensor cores. I observed how a lot better the expertise was attempting the Nvidia AI Enterprise hands-on labs on Nvidia’s server occasion than different experiences I’ve had operating TensorFlow and PyTorch samples alone {hardware} and on cloud VMs and AI providers.
All the main public clouds supply entry to Nvidia GPUs, in addition to to TPUs (Google), FPGAs (Azure), and customised accelerators reminiscent of Habana Gaudi chips for coaching (on AWS EC2 DL1 situations) and AWS Inferentia chips for inference (on Amazon EC2 Inf1 situations). You may even entry TPUs and GPUs free of charge in Google Colab. The cloud suppliers even have variations of TensorFlow, PyTorch, and different frameworks which can be optimized for his or her clouds.
Assuming that you’ll be able to entry Nvidia LaunchPad for Nvidia AI Enterprise and check it efficiently, the next step if you wish to proceed ought to more than likely be to arrange a proof of idea for an AI software that has a excessive worth to your organization, with administration buy-in and assist. You possibly can hire a small Nvidia-certified server with an Ampere-class GPU and make the most of Nvidia’s free 90-day analysis license for Nvidia AI Enterprise to perform the POC with minimal price and danger.
Copyright © 2022 IDG Communications, Inc.
[ad_2]