
{kind=link}
[ad_1]
Within the previous days, it was a tedious job to gather knowledge, and generally very costly. Machine studying tasks can not stay with out knowledge. Fortunately, we’ve lots of knowledge on the net for our disposal these days. We are able to copy knowledge from the online to create our dataset. We are able to obtain recordsdata and save to the disk. However we are able to do it extra effectively by automating the info harvesting. There are a number of instruments in Python that may assist the automation.
After ending this tutorial, you’ll be taught
- Tips on how to use requests library to learn on-line knowledge utilizing HTTP
- Tips on how to learn tables on net pages utilizing pandas
- Tips on how to use Selenium to emulate browser operations
Let’s get began!

Net Crawling in Python
Photograph by Ray Bilcliff. Some rights reserved.
Overview
This tutorial is split into three components:
- Utilizing the requests library
- Studying tables on the net utilizing pandas
- Studying dynamic content material with Selenium
Utilizing the requests library
After we speak about writing a Python program to learn from the online, it’s inevitable to keep away from the requests library. It’s good to set up it (in addition to BeautifulSoup and lxml that we’ll cowl later):
|
pip set up requests beautifulsoup4 lxml |
and it supplies you an interface to assist you to work together with the online simply.
The quite simple use case can be to learn an online web page from a URL:
|
import requests
# Lat-Lon of New York URL = “https://climate.com/climate/at present/l/40.75,-73.98” resp = requests.get(URL) print(resp.status_code) print(resp.textual content) |
|
200 <!doctype html><html dir=”ltr” lang=”en-US”><head> <meta data-react-helmet=”true” charset=”utf-8″/><meta data-react-helmet=”true” identify=”viewport” content material=”width=device-width, initial-scale=1, viewport-fit=cowl”/> … |
In the event you’re conversant in HTTP, in all probability you may recall {that a} standing code of 200 means the request is efficiently fulfilled. Then we are able to learn the response. In above, we learn the textual response and get the HTML of the online web page. Ought to or not it’s a CSV or another textual knowledge, we are able to get them within the textual content attribute of the response object. For instance, that is how we are able to learn a CSV from the Federal Reserve Economics Knowledge:
|
import io import pandas as pd import requests
URL = “https://fred.stlouisfed.org/graph/fredgraph.csv?id=T10YIE&cosd=2017-04-14&coed=2022-04-14” resp = requests.get(URL) if resp.status_code == 200: csvtext = resp.textual content csvbuffer = io.StringIO(csvtext) df = ppd.read_csv(csvbuffer) print(df) |
|
DATE T10YIE 0 2017-04-17 1.88 1 2017-04-18 1.85 2 2017-04-19 1.85 3 2017-04-20 1.85 4 2017-04-21 1.84 … … … 1299 2022-04-08 2.87 1300 2022-04-11 2.91 1301 2022-04-12 2.86 1302 2022-04-13 2.8 1303 2022-04-14 2.89
[1304 rows x 2 columns] |
If the info is within the type of JSON, we are able to learn it as textual content and even let requests to decode it for you. For instance, the next is to tug some knowledge from GitHub in JSON format and convert it into Python dictionary:
|
import requests
URL = “https://api.github.com/customers/jbrownlee” resp = requests.get(URL) if resp.status_code == 200: knowledge = resp.json() print(knowledge) |
|
{‘login’: ‘jbrownlee’, ‘id’: 12891, ‘node_id’: ‘MDQ6VXNlcjEyODkx’, ‘avatar_url’: ‘https://avatars.githubusercontent.com/u/12891?v=4’, ‘gravatar_id’: ”, ‘url’: ‘https://api.github.com/customers/jbrownlee’, ‘html_url’: ‘https://github.com/jbrownlee’, … ‘firm’: ‘Machine Studying Mastery’, ‘weblog’: ‘http://MachineLearningMastery.com’, ‘location’: None, ‘electronic mail’: None, ‘hireable’: None, ‘bio’: ‘Making builders superior at machine studying.’, ‘twitter_username’: None, ‘public_repos’: 5, ‘public_gists’: 0, ‘followers’: 1752, ‘following’: 0, ‘created_at’: ‘2008-06-07T02:20:58Z’, ‘updated_at’: ‘2022-02-22T19:56:27Z’ } |
But when the URL provides you some binary knowledge, akin to a ZIP file or an JPEG picture, it’s good to get them within the content material attribute as an alternative as this might be the binary knowledge. For instance, that is how we are able to obtain a picture (the emblem of Wikipedia):
|
import requests
URL = “https://en.wikipedia.org/static/pictures/project-logos/enwiki.png” wikilogo = requests.get(URL) if wikilogo.status_code == 200: with open(“enwiki.png”, “wb”) as fp: fp.write(wikilogo.content material) |
Given we already obtained the online web page, how ought to we extract the info? That is past the requests library can present to us however we are able to use a distinct library to assist. There are two methods we are able to do it, relies on how can we wish to specify the info.
First method is to contemplate the HTML as a type of XML doc and use the XPath language to extract the ingredient. On this case, we are able to make use of the lxml library to first create a doc object mannequin (DOM) after which search by XPath:
|
... from lxml import etree
# Create DOM from HTML textual content dom = etree.HTML(resp.textual content) # Seek for the temperature ingredient and get the content material components = dom.xpath(“//span[@data-testid=’TemperatureValue’ and contains(@class,’CurrentConditions’)]”) print(components[0].textual content) |
XPath is a string that specifies on learn how to discover a component. The lxml object supplies a perform xpath() to look the DOM for components that match the XPath string, which could be a number of matches. The XPath above means to discover a HTML ingredient anyplace with the <span> tag and with the attribute data-testid matches “TemperatureValue” and class begins with “CurrentConditions“. We are able to be taught this from the developer instruments of the browser (e.g., the Chrome screenshot under), by inspecting the HTML supply.
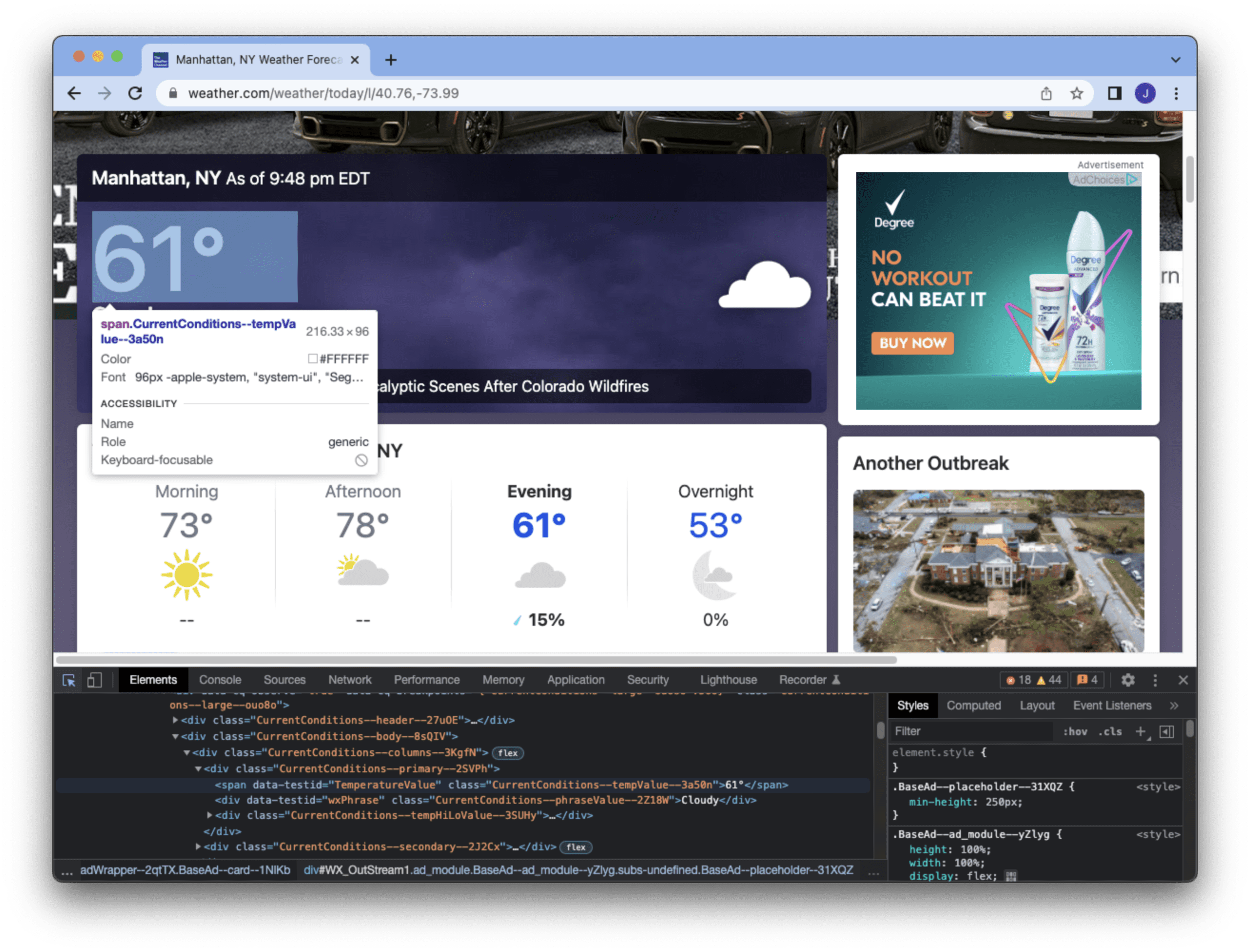
This instance is to seek out the temperature of New York Metropolis, supplied by this specific ingredient we get from this net web page. We all know the primary ingredient matched by the XPath is what we want and we are able to learn the textual content contained in the <span> tag.
The opposite method is to make use of CSS selectors on the HTML doc, which we are able to make use of the BeautifulSoup library:
|
... from bs4 import BeautifulSoup
soup = BeautifulSoup(resp.textual content, “lxml”) components = soup.choose(‘span[data-testid=”TemperatureValue”][class^=”CurrentConditions”]’) print(components[0].textual content) |
In above, we first move our HTML textual content to BeautifulSoup. BeautifulSoup helps varied HTML parsers, every with completely different capabilities. Within the above, we use the lxml library because the parser as beneficial by BeautifulSoup (and it is usually typically the quickest). CSS selector is a distinct mini-language, which has execs and cons in comparison with XPath. The selector above is similar to the XPath we used within the earlier instance. Due to this fact, we are able to get the identical temperature from the primary matched ingredient.
The next is an entire code to print the present temperature of New York in line with the real-time data on the net:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import requests from lxml import etree
# Studying temperature of New York URL = “https://climate.com/climate/at present/l/40.75,-73.98” resp = requests.get(URL)
if resp.status_code == 200: # Utilizing lxml dom = etree.HTML(resp.textual content) components = dom.xpath(“//span[@data-testid=’TemperatureValue’ and contains(@class,’CurrentConditions’)]”) print(components[0].textual content)
# Utilizing BeautifulSoup soup = BeautifulSoup(resp.textual content, “lxml”) components = soup.choose(‘span[data-testid=”TemperatureValue”][class^=”CurrentConditions”]’) print(components[0].textual content) |
As you may think about, you may accumulate a time sequence of the temperature by operating this script in common schedule. Equally, we are able to accumulate knowledge robotically from varied web pages. That is how we are able to acquire knowledge for our machine studying tasks.
Studying tables on the net utilizing pandas
Fairly often, net pages will use tables to hold knowledge. If the web page is easy sufficient, we might even skip inspecting it to seek out out the XPath or CSS selector however to make use of pandas to get all tables on the web page in a single shot. It’s easy sufficient to be performed in a single line:
|
import pandas as pd
tables = pd.read_html(“https://www.federalreserve.gov/releases/h15/”) print(tables) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
[ Instruments 2022Apr7 2022Apr8 2022Apr11 2022Apr12 2022Apr13 0 Federal funds (effective) 1 2 3 0.33 0.33 0.33 0.33 0.33 1 Commercial Paper 3 4 5 6 NaN NaN NaN NaN NaN 2 Nonfinancial NaN NaN NaN NaN NaN 3 1-month 0.30 0.34 0.36 0.39 0.39 4 2-month n.a. 0.48 n.a. n.a. n.a. 5 3-month n.a. n.a. n.a. 0.78 0.78 6 Financial NaN NaN NaN NaN NaN 7 1-month 0.49 0.45 0.46 0.39 0.46 8 2-month n.a. n.a. 0.60 0.71 n.a. 9 3-month 0.85 0.81 0.75 n.a. 0.86 10 Bank prime loan 2 3 7 3.50 3.50 3.50 3.50 3.50 11 Discount window primary credit 2 8 0.50 0.50 0.50 0.50 0.50 12 U.S. government securities NaN NaN NaN NaN NaN 13 Treasury bills (secondary market) 3 4 NaN NaN NaN NaN NaN 14 4-week 0.21 0.20 0.21 0.19 0.23 15 3-month 0.68 0.69 0.78 0.74 0.75 16 6-month 1.12 1.16 1.22 1.18 1.17 17 1-year 1.69 1.72 1.75 1.67 1.67 18 Treasury constant maturities NaN NaN NaN NaN NaN 19 Nominal 9 NaN NaN NaN NaN NaN 20 1-month 0.21 0.20 0.22 0.21 0.26 21 3-month 0.68 0.70 0.77 0.74 0.75 22 6-month 1.15 1.19 1.23 1.20 1.20 23 1-year 1.78 1.81 1.85 1.77 1.78 24 2-year 2.47 2.53 2.50 2.39 2.37 25 3-year 2.66 2.73 2.73 2.58 2.57 26 5-year 2.70 2.76 2.79 2.66 2.66 27 7-year 2.73 2.79 2.84 2.73 2.71 28 10-year 2.66 2.72 2.79 2.72 2.70 29 20-year 2.87 2.94 3.02 2.99 2.97 30 30-year 2.69 2.76 2.84 2.82 2.81 31 Inflation indexed 10 NaN NaN NaN NaN NaN 32 5-year -0.56 -0.57 -0.58 -0.65 -0.59 33 7-year -0.34 -0.33 -0.32 -0.36 -0.31 34 10-year -0.16 -0.15 -0.12 -0.14 -0.10 35 20-year 0.09 0.11 0.15 0.15 0.18 36 30-year 0.21 0.23 0.27 0.28 0.30 37 Inflation-indexed long-term average 11 0.23 0.26 0.30 0.30 0.33, 0 1 0 n.a. Not available.] |
The read_html() perform in pandas reads a URL and discover all tables on the web page. Every desk is transformed right into a pandas DataFrame, after which return all of them in an inventory. On this instance, we’re studying the assorted rates of interest from the Federal Reserve, which occurs to have just one desk on this web page. The desk columns are recognized by pandas robotically.
Chances are high that not all tables are what we have an interest. Typically the online web page will use desk merely as a solution to format the web page however pandas possibly not good sufficient to inform. Therefore we have to take a look at and cherry-pick the end result returned by the read_html() perform.
Studying dynamic content material with Selenium
A good portion of recent day net pages are filled with JavaScripts. This offers us fancier expertise however turns into a hurdle to make use of a program to extract knowledge. One instance is Yahoo’s dwelling web page, which if we simply load the web page and discover all information headline, there are far fewer than what we are able to see on the browser:
|
import requests
# Learn Yahoo dwelling web page URL = “https://www.yahoo.com/” resp = requests.get(URL) dom = etree.HTML(resp.textual content)
# Print information headlines components = dom.xpath(“//h3/a[u[@class=”StretchedBox”]]”) for elem in components: print(etree.tostring(elem, technique=“textual content”, encoding=“unicode”)) |
It is because net pages like this depend on JavaScript to populate the content material. Well-known net frameworks akin to AngularJS or React are behind powering this class. The Python library akin to requests doesn’t perceive JavaScript. Due to this fact you will note the end result in a different way. If the info you wish to fetch from the online are considered one of them, you may research how the JavaScript is invoked and mimic the browser’s conduct in your program. However this in all probability too tedious to make it work.
The opposite method is to ask an actual browser to learn the online web page quite than utilizing requests. That is the place Selenium can do. Earlier than we are able to use it, we have to set up the library:
However Selenium is barely a framework to manage browsers. It’s good to have the browser put in in your pc in addition to the driving force to attach Selenium to the browser. In the event you supposed to make use of Chrome, it’s good to obtain and set up ChromeDriver too. What it’s good to do is just put the driving force within the executable path so Selenium can invoke it like a standard command. For instance, in Linux, you simply have to get the chromedriver executable from the ZIP file downloaded and put it in /usr/native/bin.
Equally, should you’re utilizing Firefox, you want the GeckoDriver. For extra particulars on establishing Selenium, you need to consult with its documentation.
Afterwards, you may utilizing Python script to manage the browser conduct. For instance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import time from selenium import webdriver from selenium.webdriver.help.ui import WebDriverWait from selenium.webdriver.widespread.by import By
# Launch Chrome browser in headless mode choices = webdriver.ChromeOptions() choices.add_argument(“headless”) browser = webdriver.Chrome(choices=choices)
# Load net web page browser.get(“https://www.yahoo.com”) # Community transport takes time. Wait till the web page is totally loaded def is_ready(browser): return browser.execute_script(r“”“ return doc.readyState === ‘full’ ““”) WebDriverWait(browser, 30).till(is_ready)
# Scroll to backside of the web page to set off JavaScript motion browser.execute_script(“window.scrollTo(0, doc.physique.scrollHeight);”) time.sleep(1) WebDriverWait(browser, 30).till(is_ready)
# Seek for information headlines and print components = browser.find_elements(By.XPATH, “//h3/a[u[@class=”StretchedBox”]]”) for elem in components: print(elem.textual content)
# Shut the browser as soon as end browser.shut() |
The above code works as follows. We first launch the browser in headless mode, which means to ask Chrome to begin however not show on the display screen. That is essential if we wish to run our script remotely as there is probably not any GUI suppport. Be aware that each browser is developed in a different way and thus the choices syntax we used is particular to Chrome. If we use Firefox, the code needs to be this as an alternative:
|
choices = webdriver.FirefoxOptions() choices.set_headless() browser = webdriver.Firefox(firefox_options=choices) |
After we launched the browser, we give it a URL to load. However because it takes time for the community to ship the web page and the browser would take time to render it, we should always wait till the browser is prepared earlier than we proceed to subsequent operation. The way in which we detect if the browser has completed rendering is through the use of JavaScript. We make Selenium to run a JavaScript code for us and inform us the end result utilizing the execute_script() perform. We leverage Selenium’s WebDriverWait instrument to run it till it succeed, or till 30 second timeout. Because the web page is loaded, we scroll to the underside of the web page so the JavaScript could be triggered to load extra content material. Then we await one second unconditionally to ensure the browser triggered the JavaScript, then wait till the web page is prepared once more. Afterwards, we are able to extract the information headline ingredient utilizing XPath (or alternatively utilizing CSS selector). As a result of the browser is an exterior program, we’re accountable to shut it in our script.
Utilizing Selenium is completely different from utilizing requests library in a number of points. First you by no means have the online content material in your Python code straight. As a substitute, you might be referring to the content material within the browser everytime you want it. Therefore the online components returned by find_elements() perform are referring to things contained in the exterior browser, which we should not shut the browser earlier than we end consuming them. Secondly, all operation needs to be based mostly on browser interplay, quite than community requests. Thus it’s good to management the browser by emulating keyboard and mouse actions. However in return, you’ve gotten the full-featured browser with JavaScript help. For instance, you should use JavaScript to test the dimensions and place of a component on the web page, which you’ll know solely after the HTML components are rendered.
There are much more capabilities supplied by the Selenium framework that we are able to cowl right here. It’s highly effective however since it’s linked to the browser, utilizing it’s extra demanding than the requests library and far slower. Often that is the final resort for harvesting data from the online.
Additional Studying
One other well-known net crawling library in Python that we didn’t lined above is Scrapy. It’s like combining requests library with BeautifulSoup into one. The online protocol is complicated. Typically we have to handle net cookies or present further knowledge to the requests utilizing POST technique. All these could be performed with requests library with a distinct perform or further arguments. The next are some assets so that you can go deeper:
Articles
API documentations
Books
Abstract
On this tutorial, you noticed the instruments we are able to use to fetch content material from the online.
Particularly, you discovered:
- Tips on how to use the requests library to ship the HTTP request and extract knowledge from its response
- Tips on how to construct a doc object mannequin from HTML so we are able to discover some particular data on an online web page
- Tips on how to learn tables on an online web page fast and simply utilizing pandas
- Tips on how to use Selenium to manage a browser to deal with dynamic content material of an online web page
[ad_2]