

{kind=link}
[ad_1]
Written by IBM on behalf of ModelMesh and KServe contributors.
One of the crucial elementary elements of an AI software is mannequin serving, which is responding to a person request with an inference from an AI mannequin. With machine studying approaches turning into extra extensively adopted in organizations, there’s a development to deploy numerous fashions. For internet-scale AI functions like IBM Watson Assistant and IBM Watson Pure Language Understanding, there isn’t only one AI mannequin, there are actually a whole lot or hundreds which are working concurrently. As a result of AI fashions are computationally costly, it’s price prohibitive to load them all of sudden or to create a devoted container to serve each skilled mannequin. Additionally, many are hardly ever used or are successfully deserted.
When coping with numerous fashions, the ‘one mannequin, one server’ paradigm presents challenges on a Kubernetes cluster to deploy a whole lot of hundreds of fashions. To scale the variety of fashions, you will need to scale the variety of InferenceServices, one thing that may shortly problem the cluster’s limits:
- Compute Useful resource limitation (for instance, one mannequin per server usually averages to 1 CPU/1 GB overhead per mannequin)
- Most pod limitation (for instance, Kubernetes recommends at most 100 pods per node)
- Most IP tackle limitation (for instance, a cluster with 4096 IP can deploy about 1000 to 4000 fashions)
Asserting ModelMesh: A core mannequin inference platform in open supply
Enter ModelMesh, a mannequin serving administration layer for Watson merchandise. Now working efficiently in manufacturing for a number of years, ModelMesh underpins a lot of the Watson cloud providers, together with Watson Assistant, Watson Pure Language Understanding, and Watson Discovery. It’s designed for high-scale, high-density, and continuously altering mannequin use circumstances. ModelMesh intelligently masses and unloads AI fashions to and from reminiscence to strike an clever trade-off between responsiveness to customers and their computational footprint.
We’re excited to announce that we’re contributing ModelMesh to the open supply neighborhood. ModelMesh Serving is the controller for managing ModelMesh clusters by way of Kubernetes {custom} sources. Beneath we record a number of the core parts of ModelMesh.
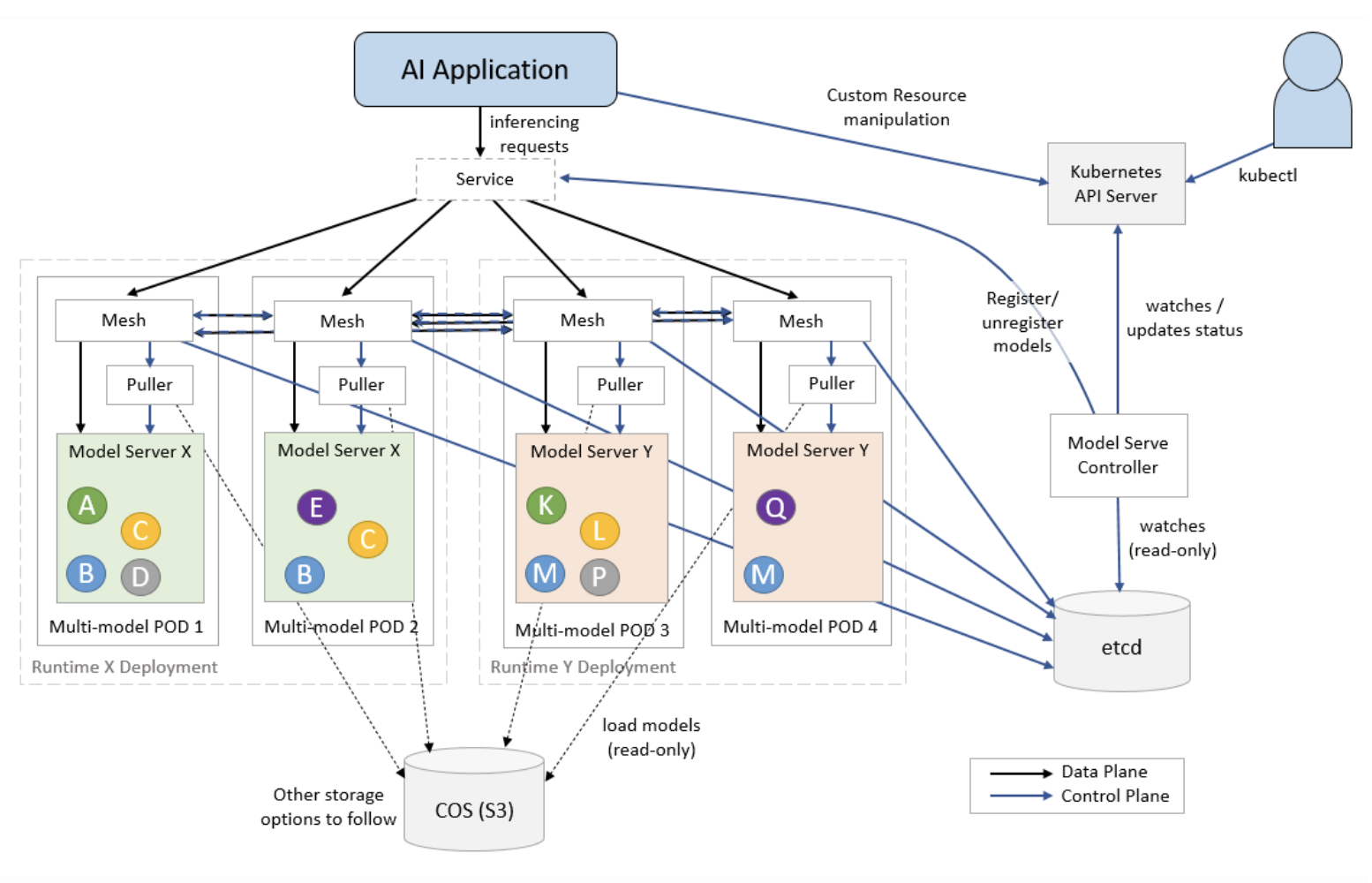
Core parts
- ModelMesh Serving: The mannequin serving controller
- ModelMesh: The ModelMesh containers which are used for orchestrating mannequin placement and routing
Runtime adapters
- modelmesh-runtime-adapter: The containers that run in every model-serving pod and act as an middleman between ModelMesh and third-party model-server containers. It additionally incorporates the “puller” logic that’s answerable for retrieving the fashions from storage
Mannequin-serving runtimes
ModelMesh Serving supplies out-of-the-box integration with the next mannequin servers:
You should utilize ServingRuntime {custom} sources so as to add assist for different current or custom-built mannequin servers. See the documentation on implementing a {custom} serving runtime.
ModelMesh options
Cache administration and HA
The clusters of multi-model server pods are managed as a distributed LRU cache, with accessible capability mechanically full of registered fashions. ModelMesh decides when and the place to load and unload copies of the fashions based mostly on utilization and present request volumes. For instance, if a specific mannequin is beneath heavy load, it is going to be scaled throughout extra pods.
It additionally acts as a router, balancing inference requests between all copies of the goal mannequin, coordinating just-in-time a great deal of fashions that aren’t at present in reminiscence, and retrying/rerouting failed requests.
Clever placement and loading
Placement of fashions into the prevailing model-server pods is finished in such a technique to stability each the “cache age” throughout the pods in addition to the request load. Closely used fashions are positioned on less-utilized pods and vice versa.
Concurrent mannequin masses are constrained/queued to reduce affect to runtime site visitors, and precedence queues are used to permit pressing requests to leap the road (that’s, cache misses the place an end-user request is ready).
Resiliency
Failed mannequin masses are mechanically retried in several pods and after longer intervals to facilitate computerized restoration, for instance, after a brief storage outage.
Operational simplicity
ModelMesh deployments could be upgraded as in the event that they had been homogeneous – it manages propagation of fashions to new pods throughout a rolling replace mechanically with none exterior orchestration required and with none affect to inference requests.
There isn’t any central controller concerned in mannequin administration choices. The logic is decentralized with light-weight coordination that makes use of etcd.
Secure “v-model” endpoints are used to supply a seamless transition between concrete mannequin variations. ModelMesh ensures that the brand new mannequin has loaded efficiently earlier than switching the pointer to route requests to the brand new model.
Scalability
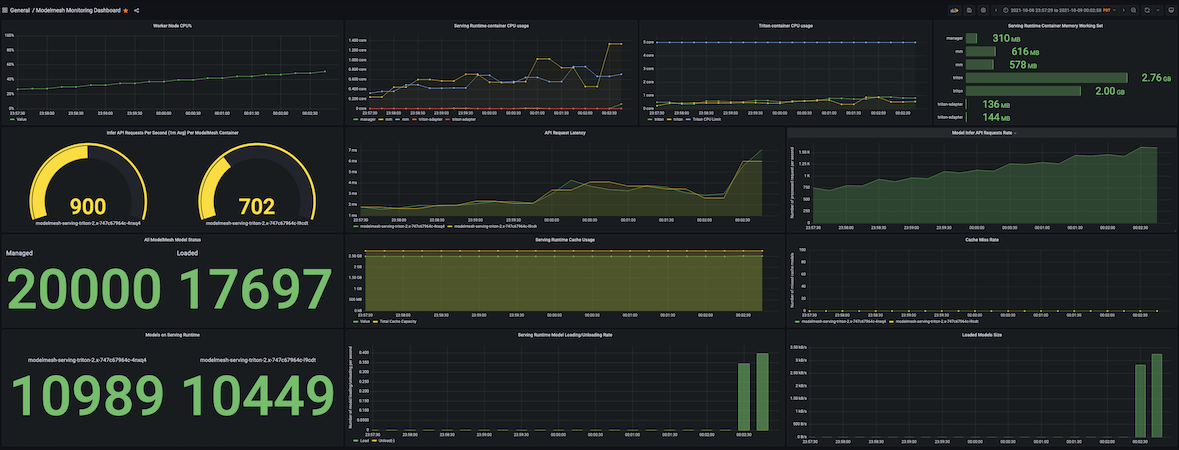
ModelMesh helps a whole lot of hundreds of fashions in a single manufacturing deployment of 8 pods by over-committing the mixture accessible sources and intelligently retaining a most-recently-used set of fashions loaded throughout them in a heterogeneous method. We did some pattern exams to find out the density and scalability for ModelMesh on an occasion deployed on a single employee node (8vCPU x 64GB) Kubernetes cluster. The exams had been in a position to pack 20K simple-string fashions into solely two serving runtime pods, which had been load examined by sending hundreds of concurrent inference requests to simulate a heavy-traffic situation. All loaded fashions responded with single-digit millisecond latency.
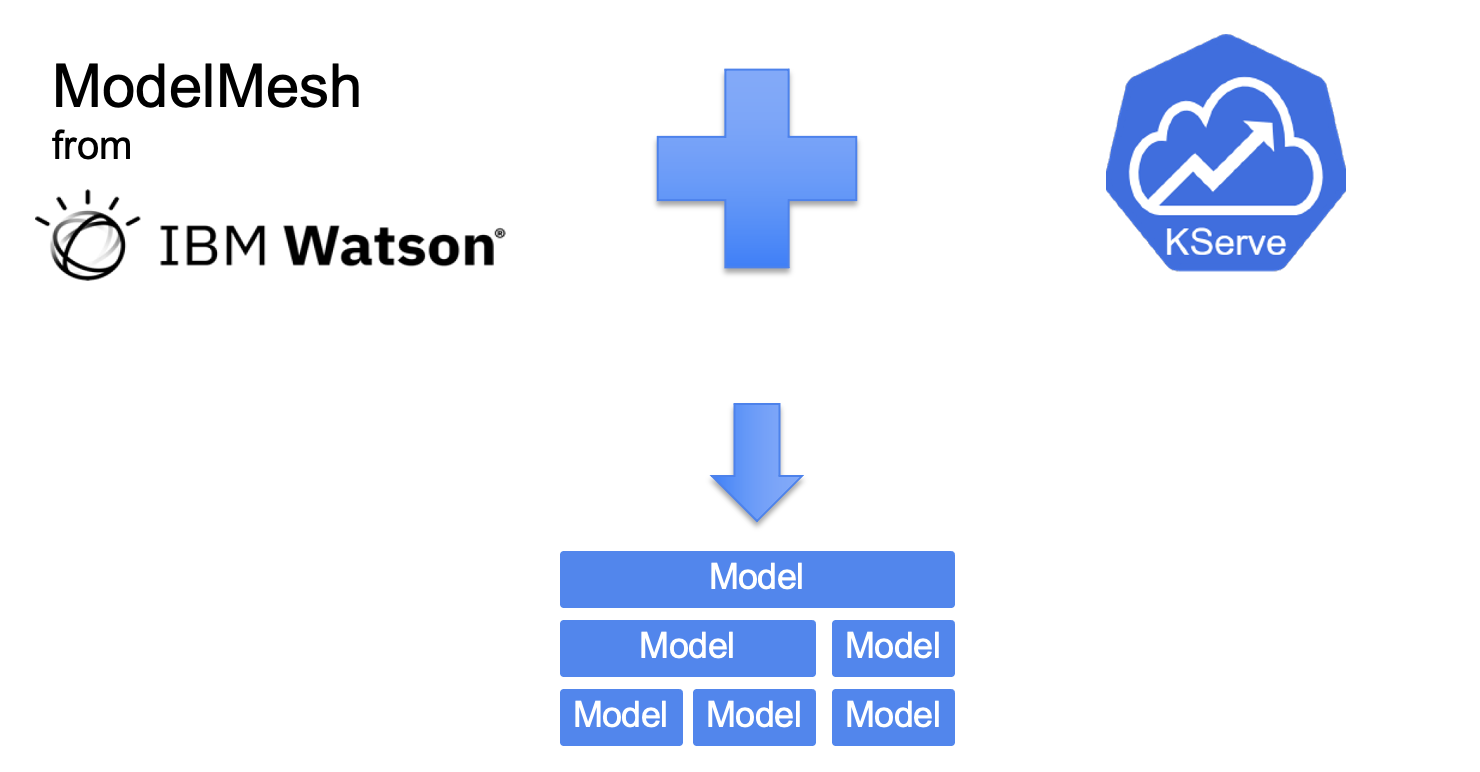
ModelMesh and KServe: Higher collectively
Developed collaboratively by Google, IBM, Bloomberg, NVIDIA, and Seldon in 2019, KFServing was printed as open supply in early 2019. Just lately, we introduced the following chapter for KFServing. The undertaking has additionally been renamed from KFServing to KServe, and the KFServing GitHub repository has been transferred to an impartial KServe GitHub group beneath the stewardship of the Kubeflow Serving Working Group leads.
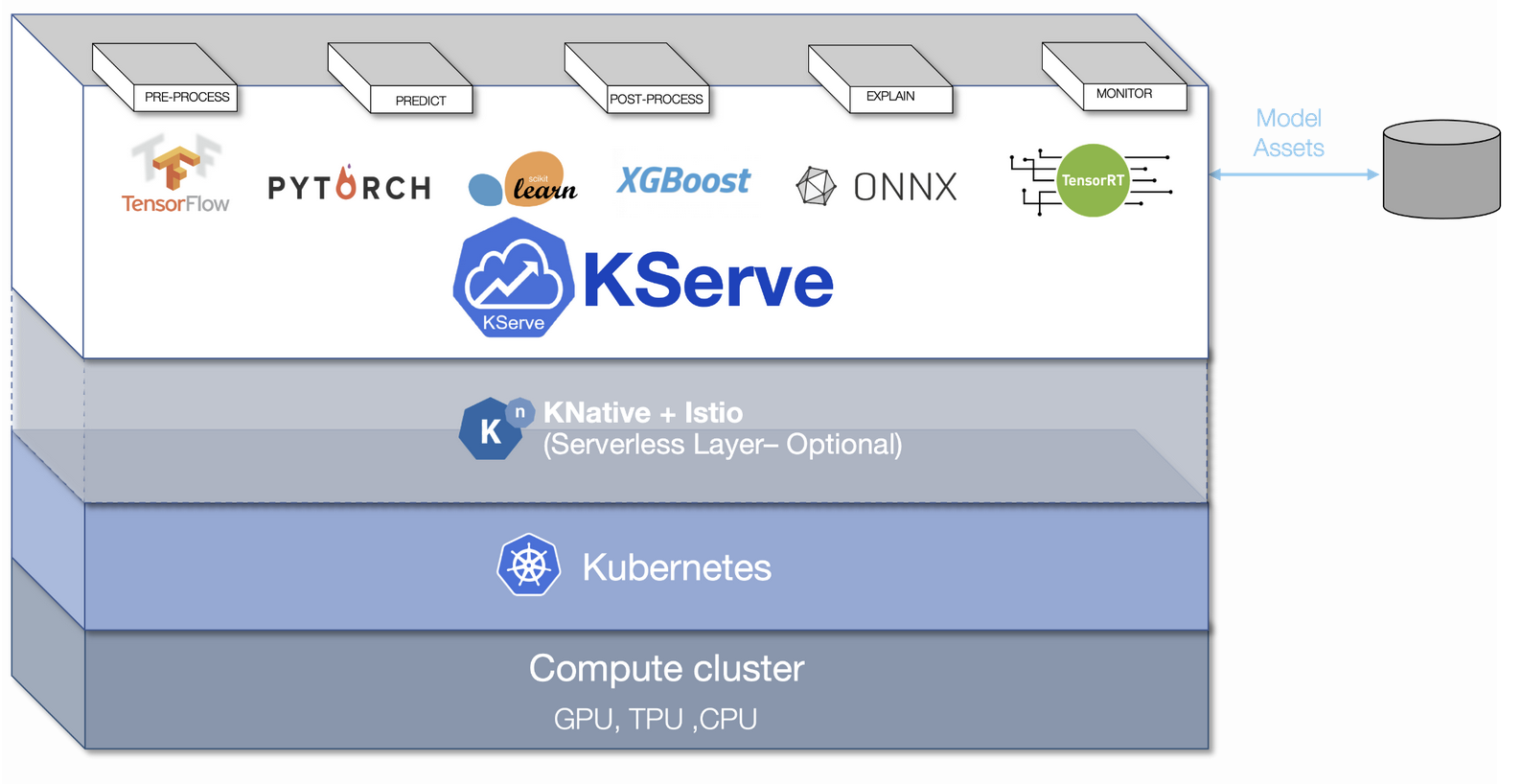
With each ModelMesh and KServe sharing a mission to create extremely scalable mannequin inferencing on Kubernetes, it made sense to carry these two tasks collectively. We’re excited to announce that ModelMesh will probably be evolving within the KServe GitHub group. KServe v0.7 has been launched with ModelMesh built-in because the again finish for Multi-Mannequin Serving.
“ModelMesh addresses the problem of deploying a whole lot or hundreds of machine studying fashions by way of an clever trade-off between latency and whole price of compute sources. We’re very enthusiastic about ModelMesh being contributed to the KServe undertaking and look ahead to collaboratively growing the unified KServe API for deploying each single mannequin and ModelMesh use circumstances.”
Dan Solar, KServe co-creator/Senior Software program Engineer at Bloomberg
Be a part of us to construct a trusted and scalable mannequin inference platform on Kubernetes
Please be a part of us on the ModelMesh and KServe GitHub repositories, strive it out, give us suggestions, and lift points. Moreover:
-
Belief and duty needs to be core rules of AI. The LF AI & Knowledge Trusted AI Committee is a world group that’s engaged on insurance policies, tips, instruments, and tasks to make sure the event of reliable AI options, and we’ve got built-in LFAI AI Equity 360, AI Explainability 360, and Adversarial Robustness 360 in KServe to supply trusted AI capabilities.
-
To contribute and construct an enterprise-grade, end-to-end machine studying platform on OpenShift and Kubernetes, please be a part of the Kubeflow neighborhood, and attain out with any questions, feedback, and suggestions.
-
If you’d like assist deploying and managing Kubeflow in your on-premises Kubernetes platform, OpenShift, or on IBM Cloud, please join with us.
[ad_2]