
{kind=link}
[ad_1]
The rising complexity of code poses a key problem to productiveness in software program engineering. Code completion has been a necessary device that has helped mitigate this complexity in built-in growth environments (IDEs). Conventionally, code completion ideas are carried out with rule-based semantic engines (SEs), which generally have entry to the complete repository and perceive its semantic construction. Current analysis has demonstrated that enormous language fashions (e.g., Codex and PaLM) allow longer and extra complicated code ideas, and because of this, helpful merchandise have emerged (e.g., Copilot). Nonetheless, the query of how code completion powered by machine studying (ML) impacts developer productiveness, past perceived productiveness and accepted ideas, stays open.
Immediately we describe how we mixed ML and SE to develop a novel Transformer-based hybrid semantic ML code completion, now obtainable to inner Google builders. We focus on how ML and SEs may be mixed by (1) re-ranking SE single token ideas utilizing ML, (2) making use of single and multi-line completions utilizing ML and checking for correctness with the SE, or (3) utilizing single and multi-line continuation by ML of single token semantic ideas. We examine the hybrid semantic ML code completion of 10k+ Googlers (over three months throughout eight programming languages) to a management group and see a 6% discount in coding iteration time (time between builds and assessments) and a 7% discount in context switches (i.e., leaving the IDE) when uncovered to single-line ML completion. These outcomes reveal that the mix of ML and SEs can enhance developer productiveness. Presently, 3% of recent code (measured in characters) is now generated from accepting ML completion ideas.
Transformers for Completion
A standard strategy to code completion is to coach transformer fashions, which use a self-attention mechanism for language understanding, to allow code understanding and completion predictions. We deal with code much like language, represented with sub-word tokens and a SentencePiece vocabulary, and use encoder-decoder transformer fashions operating on TPUs to make completion predictions. The enter is the code that’s surrounding the cursor (~1000-2000 tokens) and the output is a set of ideas to finish the present or a number of traces. Sequences are generated with a beam search (or tree exploration) on the decoder.
Throughout coaching on Google’s monorepo, we masks out the rest of a line and a few follow-up traces, to imitate code that’s being actively developed. We prepare a single mannequin on eight languages (C++, Java, Python, Go, Typescript, Proto, Kotlin, and Dart) and observe improved or equal efficiency throughout all languages, eradicating the necessity for devoted fashions. Furthermore, we discover {that a} mannequin dimension of ~0.5B parameters offers a very good tradeoff for prime prediction accuracy with low latency and useful resource value. The mannequin strongly advantages from the standard of the monorepo, which is enforced by pointers and opinions. For multi-line ideas, we iteratively apply the single-line mannequin with realized thresholds for deciding whether or not to begin predicting completions for the next line.
 |
| Encoder-decoder transformer fashions are used to foretell the rest of the road or traces of code. |
Re-rank Single Token Strategies with ML
Whereas a person is typing within the IDE, code completions are interactively requested from the ML mannequin and the SE concurrently within the backend. The SE sometimes solely predicts a single token. The ML fashions we use predict a number of tokens till the top of the road, however we solely think about the primary token to match predictions from the SE. We determine the highest three ML ideas which can be additionally contained within the SE ideas and increase their rank to the highest. The re-ranked outcomes are then proven as ideas for the person within the IDE.
In follow, our SEs are operating within the cloud, offering language providers (e.g., semantic completion, diagnostics, and many others.) with which builders are acquainted, and so we collocated the SEs to run on the identical places because the TPUs performing ML inference. The SEs are based mostly on an inner library that provides compiler-like options with low latencies. As a result of design setup, the place requests are achieved in parallel and ML is often quicker to serve (~40 ms median), we don’t add any latency to completions. We observe a big high quality enchancment in actual utilization. For 28% of accepted completions, the rank of the completion is increased attributable to boosting, and in 0.4% of circumstances it’s worse. Moreover, we discover that customers sort >10% fewer characters earlier than accepting a completion suggestion.
Test Single / Multi-line ML Completions for Semantic Correctness
At inference time, ML fashions are sometimes unaware of code outdoors of their enter window, and code seen throughout coaching may miss current additions wanted for completions in actively altering repositories. This results in a standard downside of ML-powered code completion whereby the mannequin could recommend code that appears right, however doesn’t compile. Based mostly on inner person expertise analysis, this difficulty can result in the erosion of person belief over time whereas lowering productiveness beneficial properties.
We use SEs to carry out quick semantic correctness checks inside a given latency funds (<100ms for end-to-end completion) and use cached summary syntax bushes to allow a “full” structural understanding. Typical semantic checks embrace reference decision (i.e., does this object exist), technique invocation checks (e.g., confirming the strategy was known as with an accurate variety of parameters), and assignability checks (to verify the kind is as anticipated).
For instance, for the coding language Go, ~8% of ideas include compilation errors earlier than semantic checks. Nonetheless, the applying of semantic checks filtered out 80% of uncompilable ideas. The acceptance price for single-line completions improved by 1.9x over the primary six weeks of incorporating the characteristic, presumably attributable to elevated person belief. As a comparability, for languages the place we didn’t add semantic checking, we solely noticed a 1.3x enhance in acceptance.
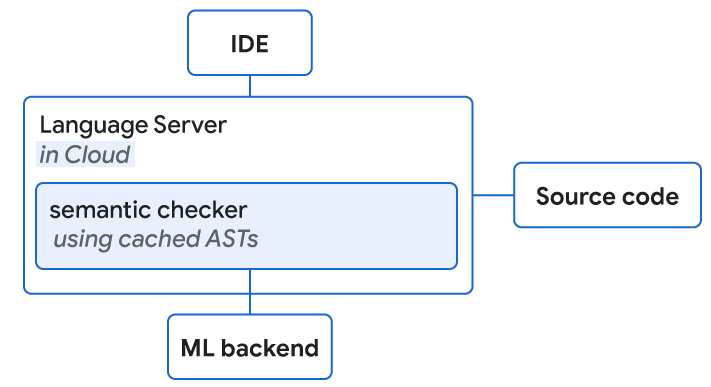 |
| Language servers with entry to supply code and the ML backend are collocated on the cloud. They each carry out semantic checking of ML completion ideas. |
Outcomes
With 10k+ Google-internal builders utilizing the completion setup of their IDE, we measured a person acceptance price of 25-34%. We decided that the transformer-based hybrid semantic ML code completion completes >3% of code, whereas lowering the coding iteration time for Googlers by 6% (at a 90% confidence stage). The dimensions of the shift corresponds to typical results noticed for transformational options (e.g., key framework) that sometimes have an effect on solely a subpopulation, whereas ML has the potential to generalize for many main languages and engineers.
| Fraction of all code added by ML | 2.6% |
| Discount in coding iteration period | 6% |
| Discount in variety of context switches | 7% |
| Acceptance price (for ideas seen for >750ms) | 25% |
| Common characters per settle for | 21 |
| Key metrics for single-line code completion measured in manufacturing for 10k+ Google-internal builders utilizing it of their day by day growth throughout eight languages. | ||||
| Fraction of all code added by ML (with >1 line in suggestion) | 0.6% |
| Common characters per settle for | 73 |
| Acceptance price (for ideas seen for >750ms) | 34% |
| Key metrics for multi-line code completion measured in manufacturing for 5k+ Google-internal builders utilizing it of their day by day growth throughout eight languages. | ||||
Offering Lengthy Completions whereas Exploring APIs
We additionally tightly built-in the semantic completion with full line completion. When the dropdown with semantic single token completions seems, we show inline the single-line completions returned from the ML mannequin. The latter signify a continuation of the merchandise that’s the focus of the dropdown. For instance, if a person appears at potential strategies of an API, the inline full line completions present the complete technique invocation additionally containing all parameters of the invocation.
 |
| Built-in full line completions by ML persevering with the semantic dropdown completion that’s in focus. |
 |
| Strategies of a number of line completions by ML. |
Conclusion and Future Work
We reveal how the mix of rule-based semantic engines and huge language fashions can be utilized to considerably enhance developer productiveness with higher code completion. As a subsequent step, we wish to make the most of SEs additional, by offering additional data to ML fashions at inference time. One instance may be for lengthy predictions to travel between the ML and the SE, the place the SE iteratively checks correctness and gives all potential continuations to the ML mannequin. When including new options powered by ML, we wish to be aware to transcend simply “good” outcomes, however guarantee a optimistic affect on productiveness.
Acknowledgements
This analysis is the result of a two-year collaboration between Google Core and Google Analysis, Mind Staff. Particular because of Marc Rasi, Yurun Shen, Vlad Pchelin, Charles Sutton, Varun Godbole, Jacob Austin, Danny Tarlow, Benjamin Lee, Satish Chandra, Ksenia Korovina, Stanislav Pyatykh, Cristopher Claeys, Petros Maniatis, Evgeny Gryaznov, Pavel Sychev, Chris Gorgolewski, Kristof Molnar, Alberto Elizondo, Ambar Murillo, Dominik Schulz, David Tattersall, Rishabh Singh, Manzil Zaheer, Ted Ying, Juanjo Carin, Alexander Froemmgen and Marcus Revaj for his or her contributions.
[ad_2]