
{kind=link}
[ad_1]
When constructing a deep mannequin for a brand new machine studying software, researchers typically start with present community architectures, corresponding to ResNets or EfficientNets. If the preliminary mannequin’s accuracy isn’t excessive sufficient, a bigger mannequin could also be a tempting various, however might not really be one of the best answer for the duty at hand. As an alternative, higher efficiency doubtlessly may very well be achieved by designing a brand new mannequin that’s optimized for the duty. Nonetheless, such efforts may be difficult and often require appreciable assets.
In “Knowledge of Committees: An Neglected Method to Quicker and Extra Correct Fashions”, we talk about mannequin ensembles and a subset known as mannequin cascades, each of that are easy approaches that assemble new fashions by amassing present fashions and mixing their outputs. We display that ensembles of even a small variety of fashions which might be simply constructed can match or exceed the accuracy of state-of-the-art fashions whereas being significantly extra environment friendly.
What Are Mannequin Ensembles and Cascades?
Ensembles and cascades are associated approaches that leverage the benefits of a number of fashions to realize a greater answer. Ensembles execute a number of fashions in parallel after which mix their outputs to make the ultimate prediction. Cascades are a subset of ensembles, however execute the collected fashions sequentially, and merge the options as soon as the prediction has a excessive sufficient confidence. For easy inputs, cascades use much less computation, however for extra advanced inputs, might find yourself calling on a higher variety of fashions, leading to greater computation prices.
 |
| Overview of ensembles and cascades. Whereas this instance exhibits 2-model combos for each ensembles and cascades, any variety of fashions can doubtlessly be used. |
In comparison with a single mannequin, ensembles can present improved accuracy if there’s selection within the collected fashions’ predictions. For instance, nearly all of pictures in ImageNet are straightforward for modern picture recognition fashions to categorise, however there are various pictures for which predictions fluctuate between fashions and that may profit most from an ensemble.
Whereas ensembles are well-known, they’re typically not thought of a core constructing block of deep mannequin architectures and are not often explored when researchers are growing extra environment friendly fashions (with a couple of notable exceptions [1, 2, 3]). Due to this fact, we conduct a complete evaluation of ensemble effectivity and present {that a} easy ensemble or cascade of off-the-shelf pre-trained fashions can improve each the effectivity and accuracy of state-of-the-art fashions.
To encourage the adoption of mannequin ensembles, we display the next useful properties:
- Easy to construct: Ensembles don’t require sophisticated strategies (e.g., early exit coverage studying).
- Simple to keep up: Ensembles are skilled independently, making them straightforward to keep up and deploy.
- Reasonably priced to coach: The overall coaching value of fashions in an ensemble is usually decrease than a equally correct single mannequin.
- On-device speedup: The discount in computation value (FLOPS) efficiently interprets to a speedup on actual {hardware}.
Effectivity and Coaching Pace
It’s not shocking that ensembles can enhance accuracy, however utilizing a number of fashions in an ensemble might introduce additional computational value at runtime. So, we examine whether or not an ensemble may be extra correct than a single mannequin that has the identical computational value. We analyze a collection of fashions, EfficientNet-B0 to EfficientNet-B7, which have completely different ranges of accuracy and FLOPS when utilized to ImageNet inputs. The ensemble predictions are computed by averaging the predictions of every particular person mannequin.
We discover that ensembles are considerably more cost effective within the giant computation regime (>5B FLOPS). For instance, an ensemble of two EfficientNet-B5 fashions matches the accuracy of a single EfficientNet-B7 mannequin, however does so utilizing ~50% fewer FLOPS. This demonstrates that as an alternative of utilizing a big mannequin, on this scenario, one ought to use an ensemble of a number of significantly smaller fashions, which can scale back computation necessities whereas sustaining accuracy. Furthermore, we discover that the coaching value of an ensemble may be a lot decrease (e.g., two B5 fashions: 96 TPU days whole; one B7 mannequin: 160 TPU days). In apply, mannequin ensemble coaching may be parallelized utilizing a number of accelerators resulting in additional reductions. This sample holds for the ResNet and MobileNet households as nicely.
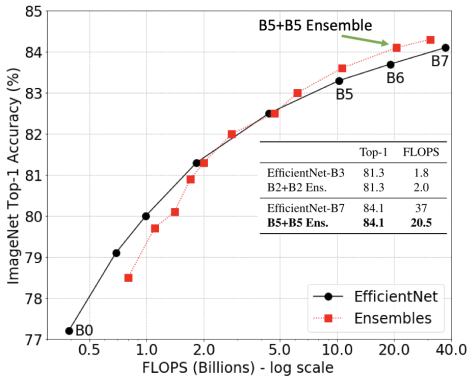 |
| Ensembles outperform single fashions within the giant computation regime (>5B FLOPS). |
Energy and Simplicity of Cascades
Whereas we’ve demonstrated the utility of mannequin ensembles, making use of an ensemble is usually wasteful for simple inputs the place a subset of the ensemble will give the right reply. In these conditions, cascades save computation by permitting for an early exit, doubtlessly stopping and outputting a solution earlier than all fashions are used. The problem is to find out when to exit from the cascade.
To spotlight the sensible good thing about cascades, we deliberately select a easy heuristic to measure the boldness of the prediction — we take the boldness of the mannequin to be the utmost of the chances assigned to every class. For instance, if the anticipated possibilities for a picture being both a cat, canine, or horse have been 20%, 80% and 20%, respectively, then the boldness of the mannequin’s prediction (canine) could be 0.8. We use a threshold on the confidence rating to find out when to exit from the cascade.
To check this strategy, we construct mannequin cascades for the EfficientNet, ResNet, and MobileNetV2 households to match both computation prices or accuracy (limiting the cascade to a most of 4 fashions). By design in cascades, some inputs incur extra FLOPS than others, as a result of tougher inputs undergo extra fashions within the cascade than simpler inputs. So we report the typical FLOPS computed over all take a look at pictures. We present that cascades outperform single fashions in all computation regimes (when FLOPS vary from 0.15B to 37B) and may improve accuracy or scale back the FLOPS (typically each) for all fashions examined.
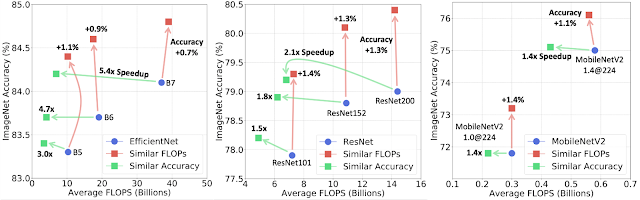 |
| Cascades of EfficientNet (left), ResNet (center) and MobileNetV2 (proper) fashions on ImageNet. When utilizing related FLOPS, cascades receive a better accuracy than single fashions (proven by the purple arrows pointing up). Cascades may match the accuracy of single fashions with considerably fewer FLOPS e.g., 5.4x for B7 (inexperienced arrows pointing left). |
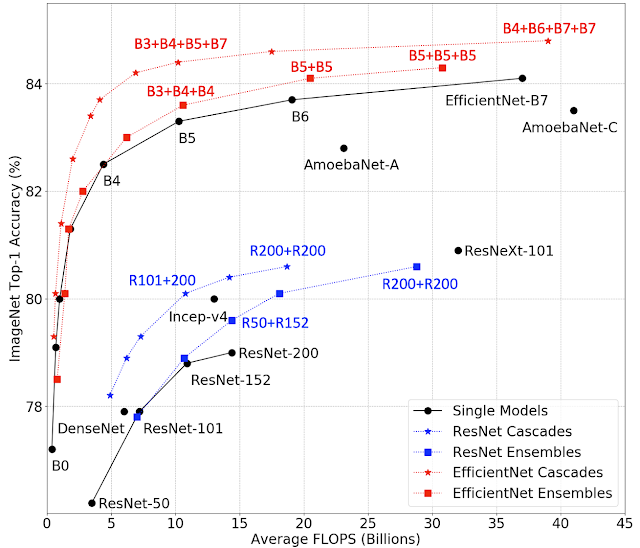 |
| Abstract of accuracy vs. FLOPS for ensembles and cascades. Squares and stars symbolize ensembles and cascades, respectively,, and the “+” notation signifies the fashions that comprise the ensemble or cascade. For instance, ”B3+B4+B5+B7” at a star refers to a cascade of EfficientNet-B3, B4, B5 and B7 fashions. |
In some instances it’s not the typical computation value however the worst-case value that’s the limiting issue. By including a easy constraint to the cascade constructing process, one can assure an higher sure to the computation value of the cascade. See the paper for extra particulars.
Apart from convolutional neural networks, we additionally take into account a Transformer-based structure, ViT. We construct a cascade of ViT-Base and ViT-Giant fashions to match the typical computation or accuracy of a single state-of-the-art ViT-Giant mannequin, and present that the advantage of cascades additionally generalizes to Transformer-based architectures.
| Single Fashions | Cascades – Related Throughput | Cascades – Related Accuracy | ||||||
| High-1 (%) | Throughput | High-1 (%) | Throughput | △High-1 | High-1 (%) | Throughput | SpeedUp | |
| ViT-L-224 | 82.0 | 192 | 83.1 | 221 | 1.1 | 82.3 | 409 | 2.1x |
| ViT-L-384 | 85.0 | 54 | 86.0 | 69 | 1.0 | 85.2 | 125 | 2.3x |
| Cascades of ViT fashions on ImageNet. “224” and “384” point out the picture decision on which the mannequin is skilled. Throughput is measured because the variety of pictures processed per second. Our cascades can obtain a 1.0% greater accuracy than ViT-L-384 with an identical throughput or obtain a 2.3x speedup over that mannequin whereas matching its accuracy. |
Earlier works on cascades have additionally proven effectivity enhancements for state-of-the-art fashions, however right here we display {that a} easy strategy with a handful of fashions is enough.
Inference Latency
Within the above evaluation, we common FLOPS to measure the computational value. Additionally it is essential to confirm that the FLOPS discount obtained by cascades really interprets into speedup on {hardware}. We study this by evaluating on-device latency and speed-up for equally performing single fashions versus cascades. We discover a discount within the common on-line latency on TPUv3 of as much as 5.5x for cascades of fashions from the EfficientNet household in comparison with single fashions with comparable accuracy. As fashions develop into bigger the extra speed-up we discover with comparable cascades.
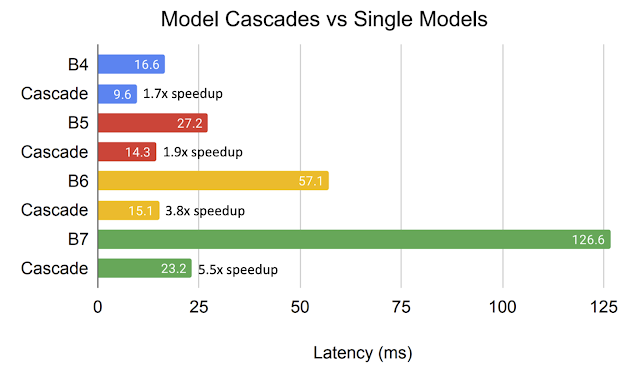 |
| Common latency of cascades on TPUv3 for on-line processing. Every pair of similar coloured bars has comparable accuracy. Discover that cascades present drastic latency discount. |
Constructing Cascades from Giant Swimming pools of Fashions
Above, we restrict the mannequin varieties and solely take into account ensembles/cascades of at most 4 fashions. Whereas this highlights the simplicity of utilizing ensembles, it additionally permits us to test all combos of fashions in little or no time so we are able to discover optimum mannequin collections with just a few CPU hours on a held out set of predictions.
When a big pool of fashions exists, we’d count on cascades to be much more environment friendly and correct, however brute drive search shouldn’t be possible. Nonetheless, environment friendly cascade search strategies have been proposed. For instance, the algorithm of Streeter (2018), when utilized to a big pool of fashions, produced cascades that matched the accuracy of state-of-the-art neural structure search–based mostly ImageNet fashions with considerably fewer FLOPS, for a variety of mannequin sizes.
Conclusion
As we’ve seen, ensemble/cascade-based fashions receive superior effectivity and accuracy over state-of-the-art fashions from a number of commonplace structure households. In our paper we present extra outcomes for different fashions and duties. For practitioners, this outlines a easy process to spice up accuracy whereas retaining effectivity utilizing off-the-shelf fashions. We encourage you to strive it out!
Acknowledgement
This weblog presents analysis finished by Xiaofang Wang (whereas interning at Google Analysis), Dan Kondratyuk, Eric Christiansen, Kris M. Kitani, Yair Alon (prev. Movshovitz-Attias), and Elad Eban. We thank Sergey Ioffe, Shankar Krishnan, Max Moroz, Josh Dillon, Alex Alemi, Jascha Sohl-Dickstein, Rif A Saurous, and Andrew Helton for his or her precious assist and suggestions.
[ad_2]