
{kind=link}
[ad_1]
Huge knowledge, labeled knowledge, noisy knowledge. Machine studying tasks all want to take a look at knowledge. Information is a vital facet of machine studying tasks and the way we deal with that knowledge is a crucial consideration for our undertaking. When the quantity of information grows and there are have to handle them, enable them to serve a number of tasks, or just have to have a greater technique to retrieve knowledge, it’s pure to think about the usage of a database system. It may be a relational database or a flat file format. It may be native or distant.
On this submit, we discover totally different codecs and libraries that you need to use to retailer and retrieve your knowledge in Python.
After finishing this tutorial, you’ll study:
- Managing knowledge utilizing SQLite, Python dbm library, Excel and Google Sheets
- The right way to use the info saved externally for coaching your machine studying mannequin
- What are the professionals and cons of utilizing a database in a machine studying undertaking
Let’s get began!

Managing Information with Python
Picture by Invoice Benzon. Some rights reserved.
Overview
This tutorial is split into seven elements:
- Managing knowledge in SQLite
- SQLite in motion
- Managing knowledge in dbm
- Utilizing dbm database in machine studying pipeline
- Managing knowledge in Excel
- Managing knowledge in Google Sheet
- Different use of the database
Managing knowledge in SQLite
Once we point out database, fairly often it means a relational database that shops knowledge in a tabular format.
To begin off, let’s seize a tabular dataset from sklearn.dataset (to study extra about getting datasets for machine studying, take a look at our earlier article).
|
# Learn dataset from OpenML from sklearn.datasets import fetch_openml dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] |
The above strains learn the “Pima Indians diabetes dataset” from OpenML and create a pandas DataFrame. This can be a classification dataset with a number of numerical options and one binary class label. We will discover the DataFrame with
|
print(kind(dataset)) print(dataset.head()) |
which provides us
|
<class ‘pandas.core.body.DataFrame’> preg plas pres pores and skin insu mass pedi age class 0 6.0 148.0 72.0 35.0 0.0 33.6 0.627 50.0 tested_positive 1 1.0 85.0 66.0 29.0 0.0 26.6 0.351 31.0 tested_negative 2 8.0 183.0 64.0 0.0 0.0 23.3 0.672 32.0 tested_positive 3 1.0 89.0 66.0 23.0 94.0 28.1 0.167 21.0 tested_negative 4 0.0 137.0 40.0 35.0 168.0 43.1 2.288 33.0 tested_positive |
This isn’t a really giant dataset however whether it is too giant, we might not match it in reminiscence. Relational database is a device to assist us handle tabular knowledge effectively with out preserving all the pieces in reminiscence. Often a relational database would perceive a dialect of SQL, which is a language to explain operation to the info. SQLite is a serverless database system that don’t want any arrange and we’ve got built-in library assist in Python. Within the following we are going to reveal how we are able to make use of SQLite to handle knowledge however utilizing a special database equivalent to MariaDB or PostgreSQL can be very comparable.
Now, let’s begin by creating an in-memory database in SQLite and getting a cursor object for us to execute queries to our new database:
|
import sqlite3
conn = sqlite3.join(“:reminiscence:”) cur = conn.cursor() |
If we need to retailer our knowledge on disk, in order that we are able to reuse it the opposite time or share with one other program, we are able to retailer the database in a database file as a substitute by changing the magic string :reminiscence: within the above code snippet with the filename (e.g., instance.db), as such
|
conn = sqlite3.join(“instance.db”) |
Now, let’s go forward and create a brand new desk for our diabetes knowledge.
|
... create_sql = “”“ CREATE TABLE diabetes( preg NUM, plas NUM, pres NUM, pores and skin NUM, insu NUM, mass NUM, pedi NUM, age NUM, class TEXT ) ““” cur.execute(create_sql) |
The cur.execute() technique executes the SQL question that we’ve got handed into it as an argument. On this case, the SQL question creates the diabetes desk with the totally different columns and their respective datatypes. The language of SQL isn’t described right here however it’s possible you’ll study extra from many database books and programs.
Subsequent, we are able to go forward and insert knowledge from our diabetes dataset, which is saved in a pandas DataFrame, into our newly created diabetes desk in our in-memory SQL database.
|
# Put together a parameterized SQL for insert insert_sql = “INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)” # execute the SQL a number of instances with every factor in dataset.to_numpy().tolist() cur.executemany(insert_sql, dataset.to_numpy().tolist()) |
Let’s break down the above code: dataset.to_numpy().tolist() provides us a listing of rows of the info in dataset, which we are going to go as an argument into cur.executemany(). Then, cur.executemany() runs the SQL assertion a number of instances, every time with a component from dataset.to_numpy().tolist(), which is a row of information from dataset. The parameterized SQL expects a listing of values every time, and therefore we must always go a listing of checklist into executemany(), which is what dataset.to_numpy().tolist() creates.
Now we are able to verify to substantiate that every one knowledge are saved within the database:
|
import pandas as pd
def cursor2dataframe(cur): “”“Learn the column header from the cursor after which the rows of knowledge from it. Afterwards, create a DataFrame”“” header = [x[0] for x in cur.description] # will get knowledge from the final executed SQL question knowledge = cur.fetchall() # convert the info right into a pandas DataFrame return pd.DataFrame(knowledge, columns=header)
# get 5 random rows from the diabetes desk select_sql = “SELECT * FROM diabetes ORDER BY random() LIMIT 5” cur.execute(select_sql) pattern = cursor2dataframe(cur) print(pattern) |
Within the above, we use the SELECT assertion in SQL to question the desk diabetes for five random rows. The outcome might be returned as a listing of tuples (one tuple for every row). Then we convert the checklist of tuples right into a pandas DataFrame by associating a reputation to every column. Working the above code snippet, we get this output.
|
preg plas pres pores and skin insu mass pedi age class 0 2 90 68 42 0 38.2 0.503 27 tested_positive 1 9 124 70 33 402 35.4 0.282 34 tested_negative 2 7 160 54 32 175 30.5 0.588 39 tested_positive 3 7 105 0 0 0 0.0 0.305 24 tested_negative 4 1 107 68 19 0 26.5 0.165 24 tested_negative |
Right here’s the entire code for creating, inserting, and retrieving a pattern from a relational database for the diabetes dataset utilizing sqlite3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
import sqlite3
import pandas as pd from sklearn.datasets import fetch_openml
# Learn dataset from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] print(“Information from OpenML:”) print(kind(dataset)) print(dataset.head())
# Create database conn = sqlite3.join(“:reminiscence:”) cur = conn.cursor() create_sql = “”“ CREATE TABLE diabetes( preg NUM, plas NUM, pres NUM, pores and skin NUM, insu NUM, mass NUM, pedi NUM, age NUM, class TEXT ) ““” cur.execute(create_sql)
# Insert knowledge into the desk utilizing a parameterized SQL insert_sql = “INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)” rows = dataset.to_numpy().tolist() cur.executemany(insert_sql, rows)
def cursor2dataframe(cur): “”“Learn the column header from the cursor after which the rows of knowledge from it. Afterwards, create a DataFrame”“” header = [x[0] for x in cur.description] # will get knowledge from the final executed SQL question knowledge = cur.fetchall() # convert the info right into a pandas DataFrame return pd.DataFrame(knowledge, columns=header)
# get 5 random rows from the diabetes desk select_sql = “SELECT * FROM diabetes ORDER BY random() LIMIT 5” cur.execute(select_sql) pattern = cursor2dataframe(cur) print(“Information from SQLite database:”) print(pattern)
# shut database connection conn.commit() conn.shut() |
The advantage of utilizing a database is pronounced when the dataset isn’t obtained from the Web however collected by you over time. For instance, it’s possible you’ll be gathering knowledge from sensors over many days. You might write the info you collected every hour into the database utilizing an automatic job. Then your machine studying undertaking can run utilizing the dataset from the database and you may even see a special outcome as your knowledge accumulates.
Let’s see how we are able to construct our relational database into our machine studying pipeline!
SQLite in motion
Now that we’ve explored retailer and retrieve knowledge from a relational database utilizing sqlite3, we is likely to be all for combine it into our machine studying pipeline.
Often on this state of affairs, we may have a course of to gather the info and write to database (e.g., learn from sensors over many days). This might be much like the code within the earlier part besides we would favor to put in writing the database into disk for persistent storage. Then we are going to learn from the database within the machine studying course of, both for coaching or for prediction. Is determined by the mannequin, there are other ways to make use of the info. Let’s think about a binary classification mannequin in Keras for the diabetes dataset. We might construct a generator to learn a random batch of information from the database:
|
def datagen(batch_size): conn = sqlite3.join(“diabetes.db”, check_same_thread=False) cur = conn.cursor() sql = f“”“ SELECT preg, plas, pres, pores and skin, insu, mass, pedi, age, class FROM diabetes ORDER BY random() LIMIT {batch_size} ““” whereas True: cur.execute(sql) knowledge = cur.fetchall() X = [row[:–1] for row in knowledge] y = [1 if row[–1]==“tested_positive” else 0 for row in knowledge] yield np.asarray(X), np.asarray(y) |
This above code is a generator perform that will get batch_size variety of rows from the SQLite database and return them as a NumPy array. We might use knowledge from this generator for coaching in our classification community:
|
from keras.fashions import Sequential from keras.layers import Dense
# create binary classification mannequin mannequin = Sequential() mannequin.add(Dense(16, input_dim=8, activation=‘relu’)) mannequin.add(Dense(8, activation=‘relu’)) mannequin.add(Dense(1, activation=‘sigmoid’)) mannequin.compile(loss=‘binary_crossentropy’, optimizer=‘adam’, metrics=[‘accuracy’])
# prepare mannequin historical past = mannequin.match(datagen(32), epochs=5, steps_per_epoch=2000) |
Working the above code provides us this output.
|
Epoch 1/5 2000/2000 [==============================] – 6s 3ms/step – loss: 2.2360 – accuracy: 0.6730 Epoch 2/5 2000/2000 [==============================] – 5s 2ms/step – loss: 0.5292 – accuracy: 0.7380 Epoch 3/5 2000/2000 [==============================] – 5s 2ms/step – loss: 0.4936 – accuracy: 0.7564 Epoch 4/5 2000/2000 [==============================] – 5s 2ms/step – loss: 0.4751 – accuracy: 0.7662 Epoch 5/5 2000/2000 [==============================] – 5s 2ms/step – loss: 0.4487 – accuracy: 0.7834 |
Be aware that within the generator perform, we learn solely the batch however not all the pieces. We depend on the database to offer us the info and we don’t concern how giant the dataset is within the database. Though SQLite isn’t a client-server database system and therefore it’s not scalable to networks, there are different database methods can try this. Therefore you’ll be able to think about a very giant dataset can be utilized whereas solely restricted quantity of reminiscence are offered for our machine studying software.
The next are the total code, from getting ready the database, to coaching a Keras mannequin utilizing knowledge learn in realtime from it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
import sqlite3
import numpy as np from sklearn.datasets import fetch_openml from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense
# Create database conn = sqlite3.join(“diabetes.db”) cur = conn.cursor() cur.execute(“DROP TABLE IF EXISTS diabetes”) create_sql = “”“ CREATE TABLE diabetes( preg NUM, plas NUM, pres NUM, pores and skin NUM, insu NUM, mass NUM, pedi NUM, age NUM, class TEXT ) ““” cur.execute(create_sql)
# Learn knowledge from OpenML, insert knowledge into the desk utilizing a parameterized SQL dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] insert_sql = “INSERT INTO diabetes VALUES (?,?,?,?,?,?,?,?,?)” rows = dataset.to_numpy().tolist() cur.executemany(insert_sql, rows)
# Decide to flush change to disk, then shut connection conn.commit() conn.shut()
# Create knowledge generator for Keras classifier mannequin def datagen(batch_size): “”“A generator to supply samples from database ““” # Tensorflow might run in numerous thread, thus wants check_same_thread=False conn = sqlite3.join(“diabetes.db”, check_same_thread=False) cur = conn.cursor() sql = f“”“ SELECT preg, plas, pres, pores and skin, insu, mass, pedi, age, class FROM diabetes ORDER BY random() LIMIT {batch_size} ““” whereas True: # Learn rows from database cur.execute(sql) knowledge = cur.fetchall() # Extract options X = [row[:–1] for row in knowledge] # Extract targets, encode into binary (0 or 1) y = [1 if row[–1]==“tested_positive” else 0 for row in knowledge] yield np.asarray(X), np.asarray(y)
# create binary classification mannequin mannequin = Sequential() mannequin.add(Dense(16, input_dim=8, activation=‘relu’)) mannequin.add(Dense(8, activation=‘relu’)) mannequin.add(Dense(1, activation=‘sigmoid’)) mannequin.compile(loss=‘binary_crossentropy’, optimizer=‘adam’, metrics=[‘accuracy’])
# prepare mannequin historical past = mannequin.match(datagen(32), epochs=5, steps_per_epoch=2000) |
Earlier than we transfer on to subsequent part, we must always emphasize that every one database is a bit totally different. The SQL assertion we use is probably not optimum in different database implementation. Additionally word that SQLite isn’t very superior as its goal is to be a database that requires no server arrange. Utilizing a big scale database and optimize the utilization is an enormous matter, however the idea demonstrated right here ought to nonetheless apply.
Managing knowledge in dbm
Relational database is nice for tabular knowledge, however not all dataset are in tabular construction. Generally, knowledge are greatest saved in a construction like Python’s dictionary, particularly, a key-value retailer. There are numerous key-value knowledge retailer. MongoDB might be probably the most well-known one and it wants a server deployment similar to PostgreSQL. GNU dbm is a serverless retailer similar to SQLite and it’s put in in nearly each Linux system. In Python’s customary library, we’ve got the dbm module to work with it.
Let’s discover Python’s dbm library. This library helps two totally different dbm implementation, the GNU dbm or ndbm. If neither is put in within the system, there’s a Python’s personal implementation as fall again. Regardless the underlying dbm implementation, the identical syntax is utilized in our Python program.
This time, we’ll reveal utilizing scikit-learn’s digits dataset:
|
import sklearn.datasets
# get digits dataset (8×8 photos of digits) digits = sklearn.datasets.load_digits() |
The dbm library makes use of a dictionary-like interface to retailer and retrieve knowledge from a dbm file, mapping keys to values the place each keys and values are strings. The code to retailer the digits dataset within the file digits.dbm is as follows:
|
import dbm import pickle
# create file if not exists, in any other case open for learn/write with dbm.open(“digits.dbm”, “c”) as db: for idx in vary(len(digits.goal)): db[str(idx)] = pickle.dumps((digits.photos[idx], digits.goal[idx])) |
The above code snippet creates a brand new file digits.dbm if it’s not exist but. Then we decide every digits picture (from digits.photos) and the label (from digits.goal) and create a tuple. We use the offset of the info as key and the pickled string of the tuple as worth to retailer into the database. Not like Python’s dictionary, dbm permits solely string keys and serialized values. Therefore we forged the important thing into string utilizing str(idx) and retailer solely the pickled knowledge.
You might study extra about serialized in our earlier article.
The next is how we are able to learn the info again from the database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import random import numpy as np
# variety of photos that we would like in our pattern batchsize = 4 photos = [] targets = []
# open the database and skim a pattern with dbm.open(“digits.dbm”, “r”) as db: # get all keys from the database keys = db.keys() # randomly samples n keys for key in random.pattern(keys, batchsize): # undergo every key within the random pattern picture, goal = pickle.hundreds(db[key]) photos.append(picture) targets.append(goal) print(np.asarray(photos), np.asarray(targets)) |
Within the above code snippet, we get 4 random keys from the database, then get their corresponding values and deserialize utilizing pickle.hundreds(). As we all know the deserialized knowledge can be a tuple, we assign them into the variables picture and goal after which acquire every of the random pattern within the checklist photos and targets. For comfort of coaching in scikit-learn or Keras, we normally favor to have your complete batch as a NumPy array.
Working the code above will get us the output:
|
[[[ 0. 0. 1. 9. 14. 11. 1. 0.] [ 0. 0. 10. 15. 9. 13. 5. 0.] [ 0. 3. 16. 7. 0. 0. 0. 0.] [ 0. 5. 16. 16. 16. 10. 0. 0.] [ 0. 7. 16. 11. 10. 16. 5. 0.] [ 0. 2. 16. 5. 0. 12. 8. 0.] [ 0. 0. 10. 15. 13. 16. 5. 0.] [ 0. 0. 0. 9. 12. 7. 0. 0.]] … ] [6 8 7 3] |
Placing all the pieces collectively, that is what the code for retrieving the digits dataset, then creating, inserting, and sampling from a dbm database seems like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
import dbm import pickle import random
import numpy as np import sklearn.datasets
# get digits dataset (8×8 photos of digits) digits = sklearn.datasets.load_digits()
# create file if not exists, in any other case open for learn/write with dbm.open(“digits.dbm”, “c”) as db: for idx in vary(len(digits.goal)): db[str(idx)] = pickle.dumps((digits.photos[idx], digits.goal[idx]))
# variety of photos that we would like in our pattern batchsize = 4 photos = [] targets = []
# open the database and skim a pattern with dbm.open(“digits.dbm”, “r”) as db: # get all keys from the database keys = db.keys() # randomly samples n keys for key in random.pattern(keys, batchsize): # undergo every key within the random pattern picture, goal = pickle.hundreds(db[key]) photos.append(picture) targets.append(goal) print(np.array(photos), np.array(targets)) |
Subsequent, let’s take a look at use the our newly created dbm database in our machine studying pipeline!
Utilizing dbm database in machine studying pipeline
At right here, in all probability you realized that we are able to create a generator and a Keras mannequin for digits classification, similar to what we did within the instance of SQLite database. Right here is how we are able to modify the code. First is our generator perform. We simply want to pick a random batch of keys in a loop and fetch knowledge from the dbm retailer:
|
def datagen(batch_size): “”“A generator to supply samples from database ““” with dbm.open(“digits.dbm”, “r”) as db: keys = db.keys() whereas True: photos = [] targets = [] for key in random.pattern(keys, batch_size): picture, goal = pickle.hundreds(db[key]) photos.append(picture) targets.append(goal) yield np.array(photos).reshape(–1,64), np.array(targets) |
Then, we are able to create a easy MLP mannequin for the info.
|
import tensorflow as tf from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense
mannequin = Sequential() mannequin.add(Dense(32, input_dim=64, activation=‘relu’)) mannequin.add(Dense(32, activation=‘relu’)) mannequin.add(Dense(10, activation=‘softmax’)) mannequin.compile(loss=“sparse_categorical_crossentropy”, optimizer=“adam”, metrics=[“sparse_categorical_accuracy”])
historical past = mannequin.match(datagen(32), epochs=5, steps_per_epoch=1000) |
Working the above code provides us the next output:
|
Epoch 1/5 1000/1000 [==============================] – 3s 2ms/step – loss: 0.6714 – sparse_categorical_accuracy: 0.8090 Epoch 2/5 1000/1000 [==============================] – 2s 2ms/step – loss: 0.1049 – sparse_categorical_accuracy: 0.9688 Epoch 3/5 1000/1000 [==============================] – 2s 2ms/step – loss: 0.0442 – sparse_categorical_accuracy: 0.9875 Epoch 4/5 1000/1000 [==============================] – 2s 2ms/step – loss: 0.0484 – sparse_categorical_accuracy: 0.9850 Epoch 5/5 1000/1000 [==============================] – 2s 2ms/step – loss: 0.0245 – sparse_categorical_accuracy: 0.9935 |
That is how we used our dbm database to coach our MLP for the digits dataset. The entire code for coaching the mannequin utilizing dbm is right here:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
import dbm import pickle import random
import numpy as np import sklearn.datasets from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense
# get digits dataset (8×8 photos of digits) digits = sklearn.datasets.load_digits()
# create file if not exists, in any other case open for learn/write with dbm.open(“digits.dbm”, “c”) as db: for idx in vary(len(digits.goal)): db[str(idx)] = pickle.dumps((digits.photos[idx], digits.goal[idx]))
# retrieving knowledge from database for mannequin def datagen(batch_size): “”“A generator to supply samples from database ““” with dbm.open(“digits.dbm”, “r”) as db: keys = db.keys() whereas True: photos = [] targets = [] for key in random.pattern(keys, batch_size): picture, goal = pickle.hundreds(db[key]) photos.append(picture) targets.append(goal) yield np.array(photos).reshape(–1,64), np.array(targets)
# Classification mannequin in Keras mannequin = Sequential() mannequin.add(Dense(32, input_dim=64, activation=‘relu’)) mannequin.add(Dense(32, activation=‘relu’)) mannequin.add(Dense(10, activation=‘softmax’)) mannequin.compile(loss=“sparse_categorical_crossentropy”, optimizer=“adam”, metrics=[“sparse_categorical_accuracy”])
# Prepare with knowledge from dbm retailer historical past = mannequin.match(datagen(32), epochs=5, steps_per_epoch=1000) |
In additional superior system equivalent to MongoDB or Couchbase, we might merely ask the database system to learn random data for us as a substitute of we decide random samples from the checklist of all keys. However the concept remains to be the identical, we are able to depend on exterior retailer to maintain our knowledge and handle our dataset slightly than doing in our Python script.
Managing knowledge in Excel
There are occasions that reminiscence isn’t the rationale we preserve our knowledge outdoors of our machine studying script, however as a result of there are higher instruments to control the info. Perhaps we need to have instruments to indicate us all knowledge on the display screen and permit us to scroll, with formatting and spotlight, and so forth. Or perhaps we need to share the info with another person who doesn’t care about our Python program. It’s fairly frequent to see folks utilizing Excel to handle knowledge in conditions the place relational database can be utilized. Whereas Excel can learn and export CSV information, likelihood is that we might need to cope with Excel information instantly.
In Python, there are a number of libraries to deal with Excel file and OpenPyXL is likely one of the most well-known. We have to set up this library earlier than we are able to use it:
Excel within the trendy days are utilizing the “Open XML Spreadsheet” format with the filename ending in .xlsx. The older Excel file are in a binary format with filename suffix .xls and it’s not supported by OpenPyXL (which you need to use xlrd and xlwt modules for studying and writing).
Let’s think about the identical instance as we demonstrated within the case of SQLite above, we are able to open a brand new Excel workbook and write our diabetes dataset as a worksheet:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
import pandas as pd from sklearn.datasets import fetch_openml import openpyxl
# Learn dataset from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] header = checklist(dataset.columns) knowledge = dataset.to_numpy().tolist()
# Create Excel workbook and write knowledge into the default worksheet wb = openpyxl.Workbook() sheet = wb.energetic # use the default worksheet sheet.title = “Diabetes” for n,colname in enumerate(header): sheet.cell(row=1, column=1+n, worth=colname) for n,row in enumerate(knowledge): for m,cell in enumerate(row): sheet.cell(row=2+n, column=1+m, worth=cell) # Save wb.save(“MLM.xlsx”) |
The code above is to organize knowledge for every cell within the worksheet (specified by the rows and columns). Once we create a brand new Excel file, there might be one worksheet by default. Then the cells are recognized by the row and column offset, start with 1. We write to a cell with the syntax
|
sheet.cell(row=3, column=4, worth=“my knowledge”) |
and to learn from a cell, we use
|
sheet.cell(row=3, column=4).worth |
Writing knowledge into Excel cell by cell is tedious and certainly we are able to add knowledge row by row. The next is how we are able to modify the code above to function in rows slightly than cells:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
import pandas as pd from sklearn.datasets import fetch_openml import openpyxl
# Learn dataset from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] header = checklist(dataset.columns) knowledge = dataset.to_numpy().tolist()
# Create Excel workbook and write knowledge into the default worksheet wb = openpyxl.Workbook() sheet = wb.create_sheet(“Diabetes”) # or wb.energetic for default sheet sheet.append(header) for row in knowledge: sheet.append(row) # Save wb.save(“MLM.xlsx”) |
As soon as we’ve got written our knowledge into the file, we might use Excel to visually browse the info, add formatting, and so forth: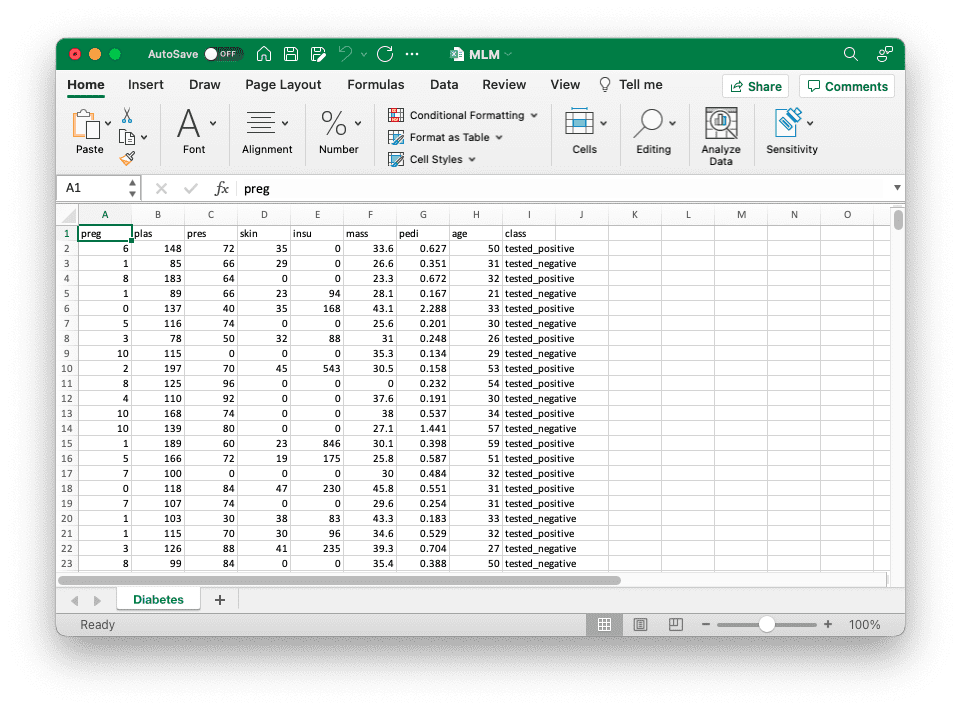
To make use of it for a machine studying undertaking isn’t any tougher than utilizing SQLite database. The next is similar binary classification mannequin in Keras however the generator is studying from the Excel file as a substitute:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
import random
import numpy as np import openpyxl from sklearn.datasets import fetch_openml from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense
# Learn knowledge from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] header = checklist(dataset.columns) rows = dataset.to_numpy().tolist()
# Create Excel workbook and write knowledge into the default worksheet wb = openpyxl.Workbook() sheet = wb.energetic sheet.title = “Diabetes” sheet.append(header) for row in rows: sheet.append(row) # Save wb.save(“MLM.xlsx”)
# Create knowledge generator for Keras classifier mannequin def datagen(batch_size): “”“A generator to supply samples from database ““” wb = openpyxl.load_workbook(“MLM.xlsx”, read_only=True) sheet = wb.energetic maxrow = sheet.max_row whereas True: # Learn rows from Excel file X = [] y = [] for _ in vary(batch_size): # knowledge begins at row 2 row_num = random.randint(2, maxrow) rowdata = [cell.value for cell in sheet[row_num]] X.append(rowdata[:–1]) y.append(1 if rowdata[–1]==“tested_positive” else 0) yield np.asarray(X), np.asarray(y)
# create binary classification mannequin mannequin = Sequential() mannequin.add(Dense(16, input_dim=8, activation=‘relu’)) mannequin.add(Dense(8, activation=‘relu’)) mannequin.add(Dense(1, activation=‘sigmoid’)) mannequin.compile(loss=‘binary_crossentropy’, optimizer=‘adam’, metrics=[‘accuracy’])
# prepare mannequin historical past = mannequin.match(datagen(32), epochs=5, steps_per_epoch=20) |
Within the above, we intentionally give argument steps_per_epoch=20 to the match() perform as a result of the code above might be extraordinarily sluggish. It is because OpenPyXL is applied in Python to maximise compatibility however traded off the pace {that a} compiled module can present. Therefore we higher keep away from studying knowledge row by row each time from Excel. If we have to use Excel, a greater possibility is to learn your complete knowledge into reminiscence in a single shot and use it instantly afterwards:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import random
import numpy as np import openpyxl from sklearn.datasets import fetch_openml from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense
# Learn knowledge from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] header = checklist(dataset.columns) rows = dataset.to_numpy().tolist()
# Create Excel workbook and write knowledge into the default worksheet wb = openpyxl.Workbook() sheet = wb.energetic sheet.title = “Diabetes” sheet.append(header) for row in rows: sheet.append(row) # Save wb.save(“MLM.xlsx”)
# Learn total worksheet from the Excel file wb = openpyxl.load_workbook(“MLM.xlsx”, read_only=True) sheet = wb.energetic X = [] y = [] for i, row in enumerate(sheet.rows): if i==0: proceed # skip the header row rowdata = [cell.value for cell in row] X.append(rowdata[:–1]) y.append(1 if rowdata[–1]==“tested_positive” else 0) X, y = np.asarray(X), np.asarray(y)
# create binary classification mannequin mannequin = Sequential() mannequin.add(Dense(16, input_dim=8, activation=‘relu’)) mannequin.add(Dense(8, activation=‘relu’)) mannequin.add(Dense(1, activation=‘sigmoid’)) mannequin.compile(loss=‘binary_crossentropy’, optimizer=‘adam’, metrics=[‘accuracy’])
# prepare mannequin historical past = mannequin.match(X, y, epochs=5) |
Managing knowledge in Google Sheet
In addition to Excel workbook, typically we might discover Google Sheet extra handy to deal with knowledge as a result of it’s “on the cloud”. We may additionally handle knowledge utilizing Google Sheet in the same logic as Excel. However to start, we have to set up some modules earlier than we are able to entry it in Python:
|
pip set up google-api-python-client google-auth-httplib2 google-auth-oauthlib |
Assume you’ve got a GMail account and also you created a Google Sheet. The URL you noticed on the tackle bar, proper earlier than the /edit half, tells you the ID of the sheet and we are going to use this ID later:
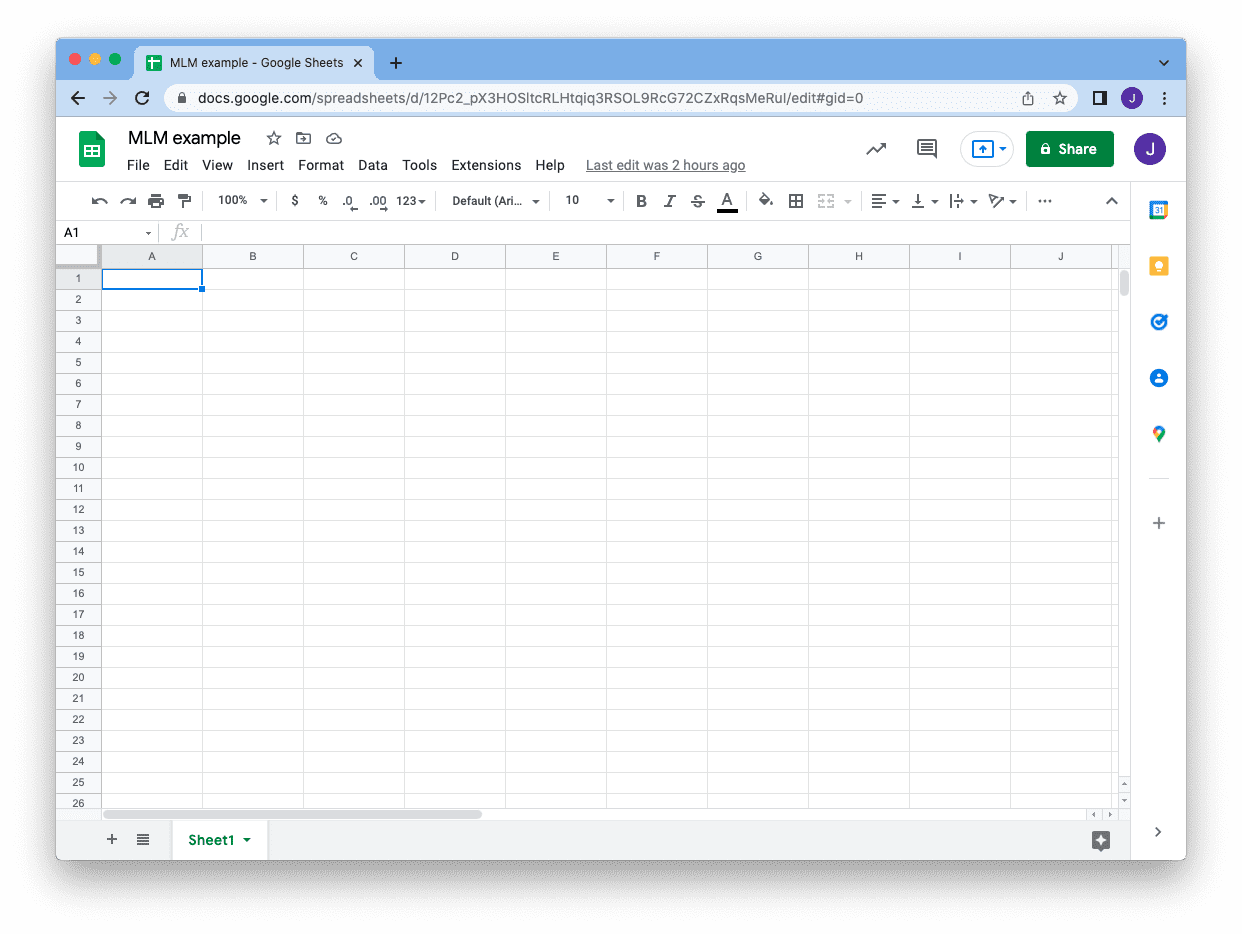
To entry this sheet from a Python program, it’s the greatest for those who create a service account to your code. This can be a machine-operable account that authenticates utilizing a key however manageable by the account proprietor. You’ll be able to management what this service account can do and when it’ll expire. You may additionally revoke the service account at anytime as it’s separated out of your GMail account.
To create a service account, first you’ll want to go to Google builders console, https://console.builders.google.com, and create a undertaking by clicking the “Create Challenge” button:
You must present a reputation after which you’ll be able to click on “Create”:
It’ll convey you again to the console however your undertaking identify will seem subsequent to the search field. The following step is to allow the APIs, by clicking “Allow APIs and Providers” beneath the search field:
Since we’re to create a service account to make use of Google Sheets, we seek for “sheets” on the search field:
after which click on on the Google Sheets API:
and allow it
Afterwards, we might be despatched again to the console important display screen and we are able to click on on “Create Credentials” on the high proper nook to create the service account:

There are several types of credentials, and we choose “Service Account”:
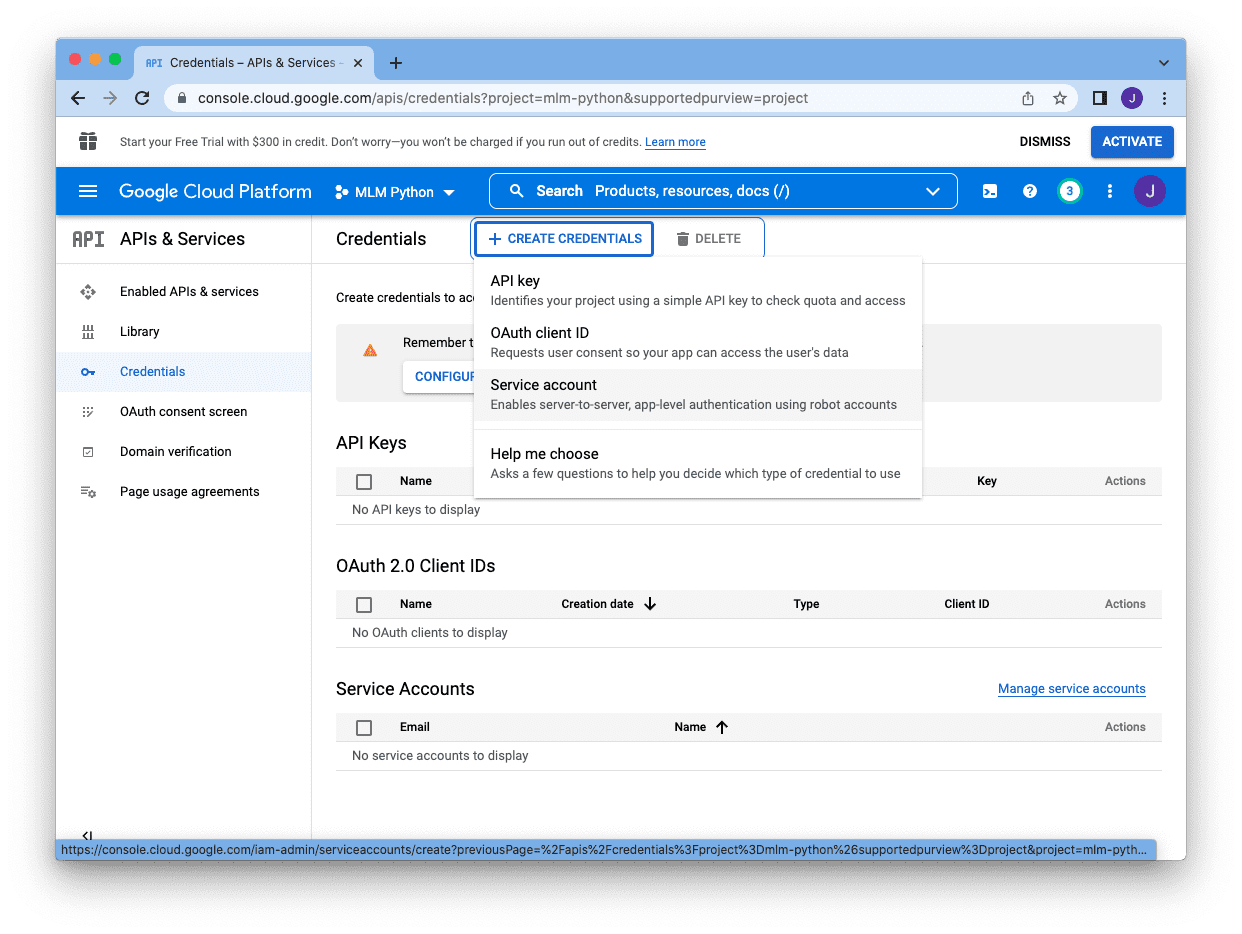
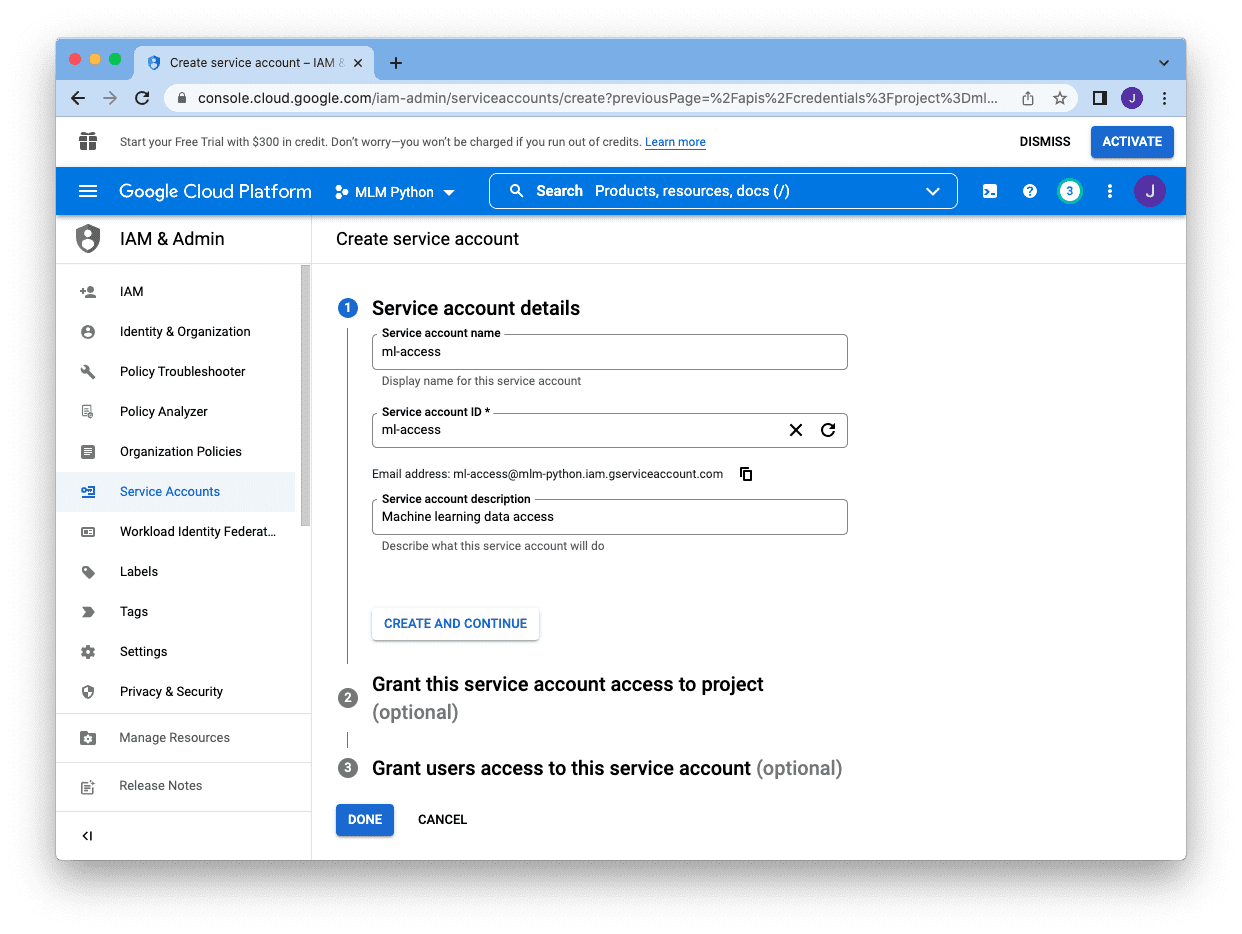
and we have to present a reputation (for our reference), an account ID (as a singular identifier within the undertaking), and an outline. The e-mail tackle displaying beneath the “Service account ID” field is the e-mail for this service account. Copy it and we are going to add it to our Google Sheet later. After we created all these, we are able to skip the remaining and click on “Performed”:
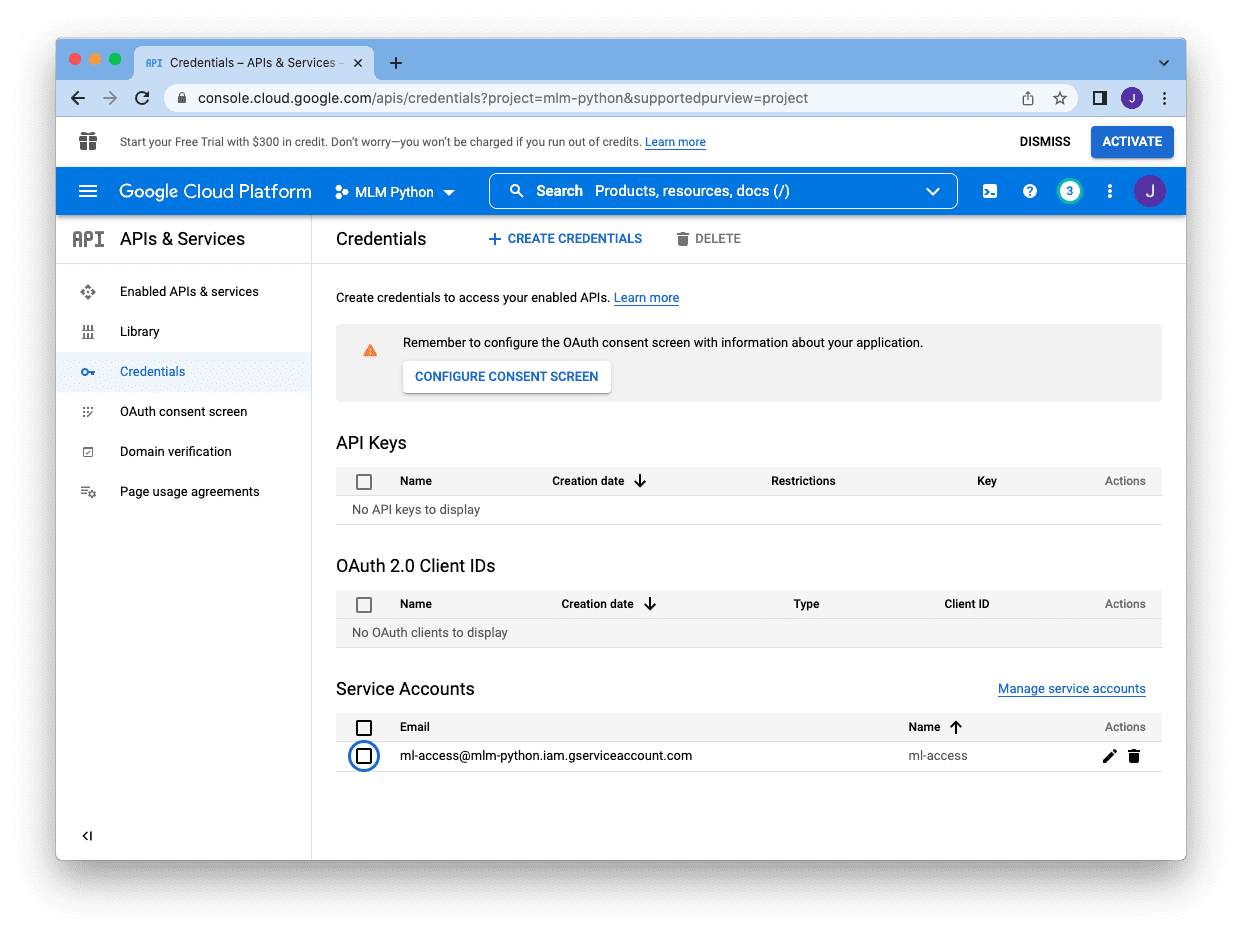
Once we end, we might be despatched again to the primary console display screen and we all know the service account is created if we see it below the “Service Account” part:
Subsequent we have to click on on the pencil icon on the proper of the account, which convey us to the next display screen:
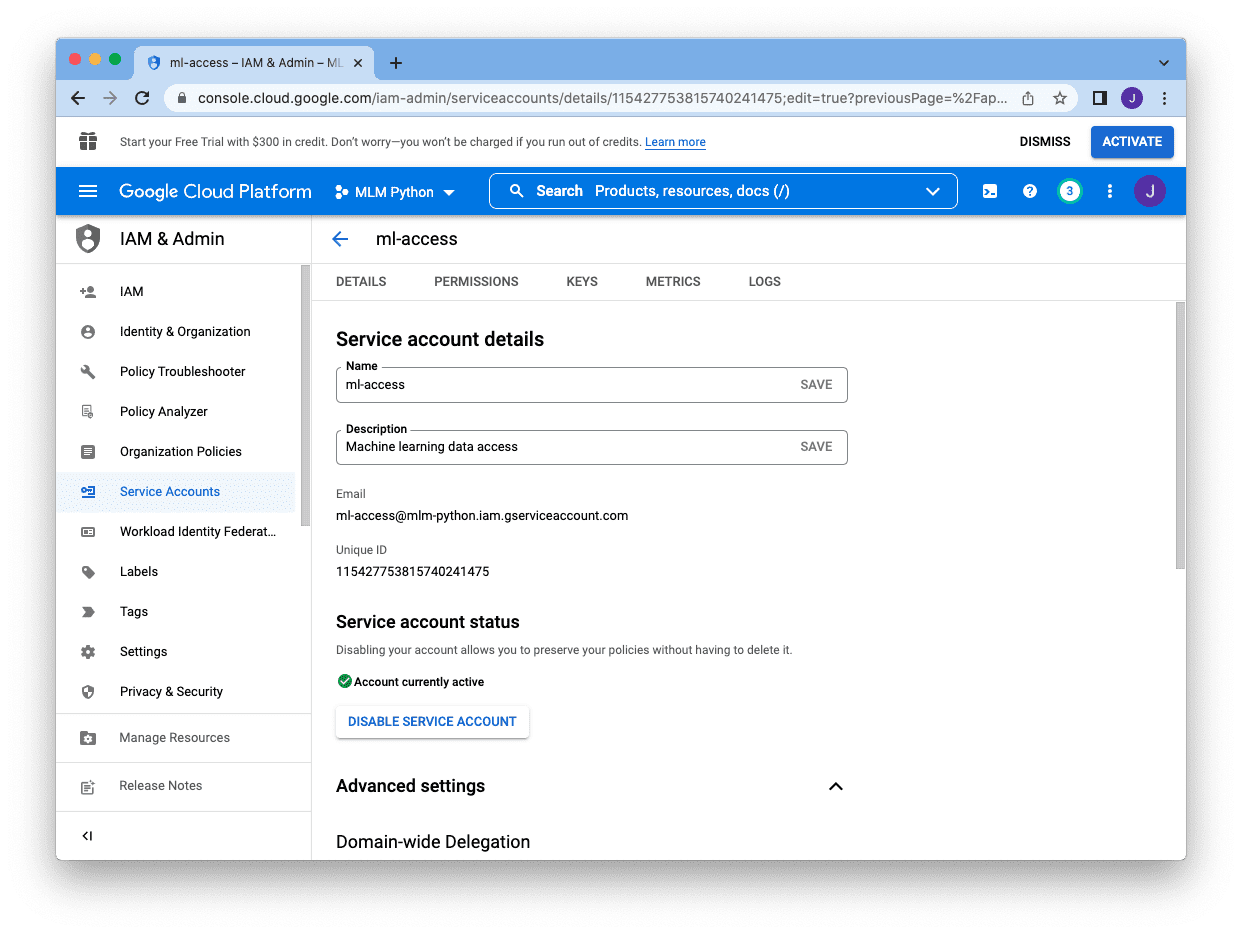
As a substitute of password, we have to create a key for this account. We click on on “Keys” web page at high, after which click on on “Add Key” and choose “Create new key”:
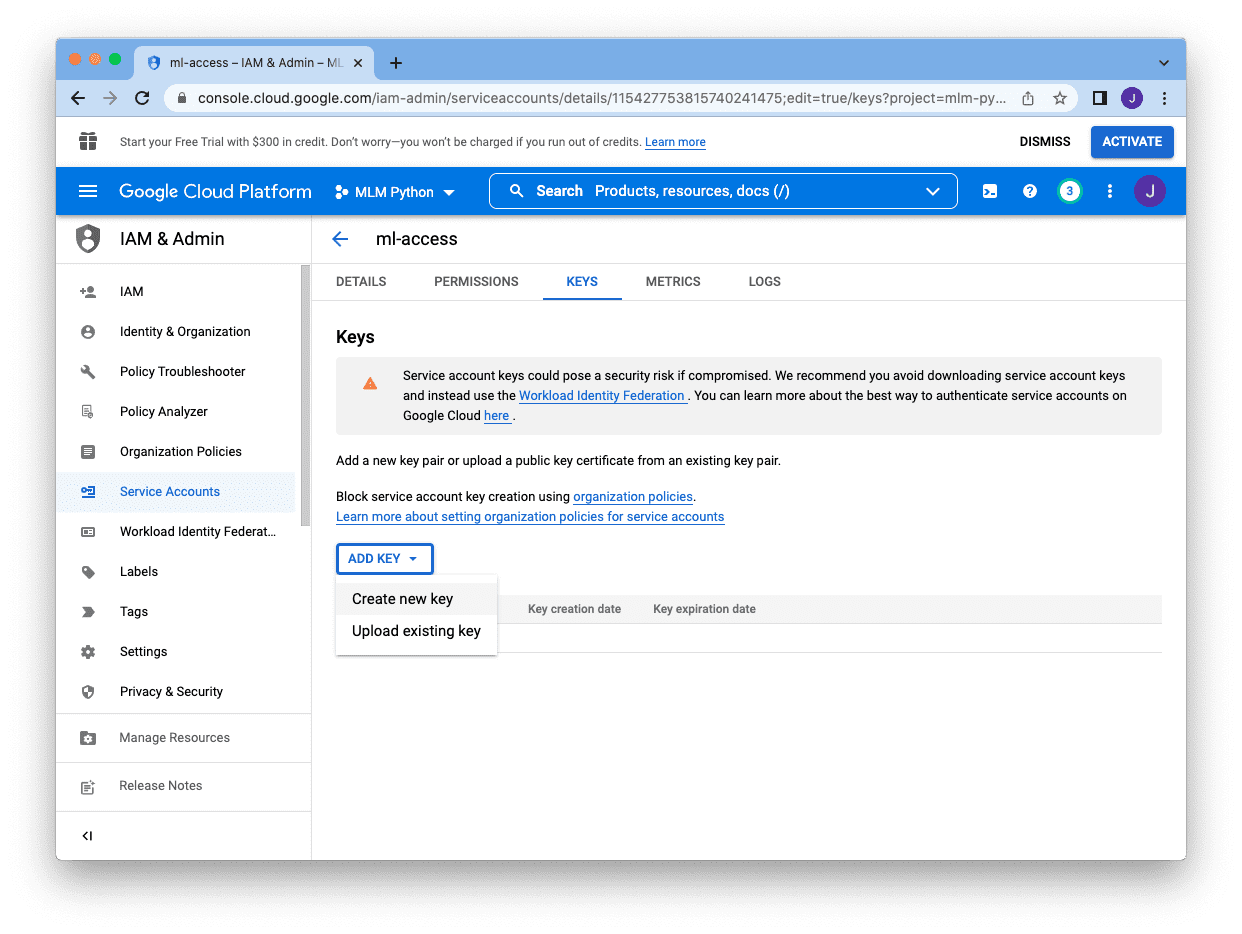
There are two totally different format for the keys and JSON is the popular one. Choosing JSON, and click on “Create” on the backside will obtain the important thing in a JSON file:
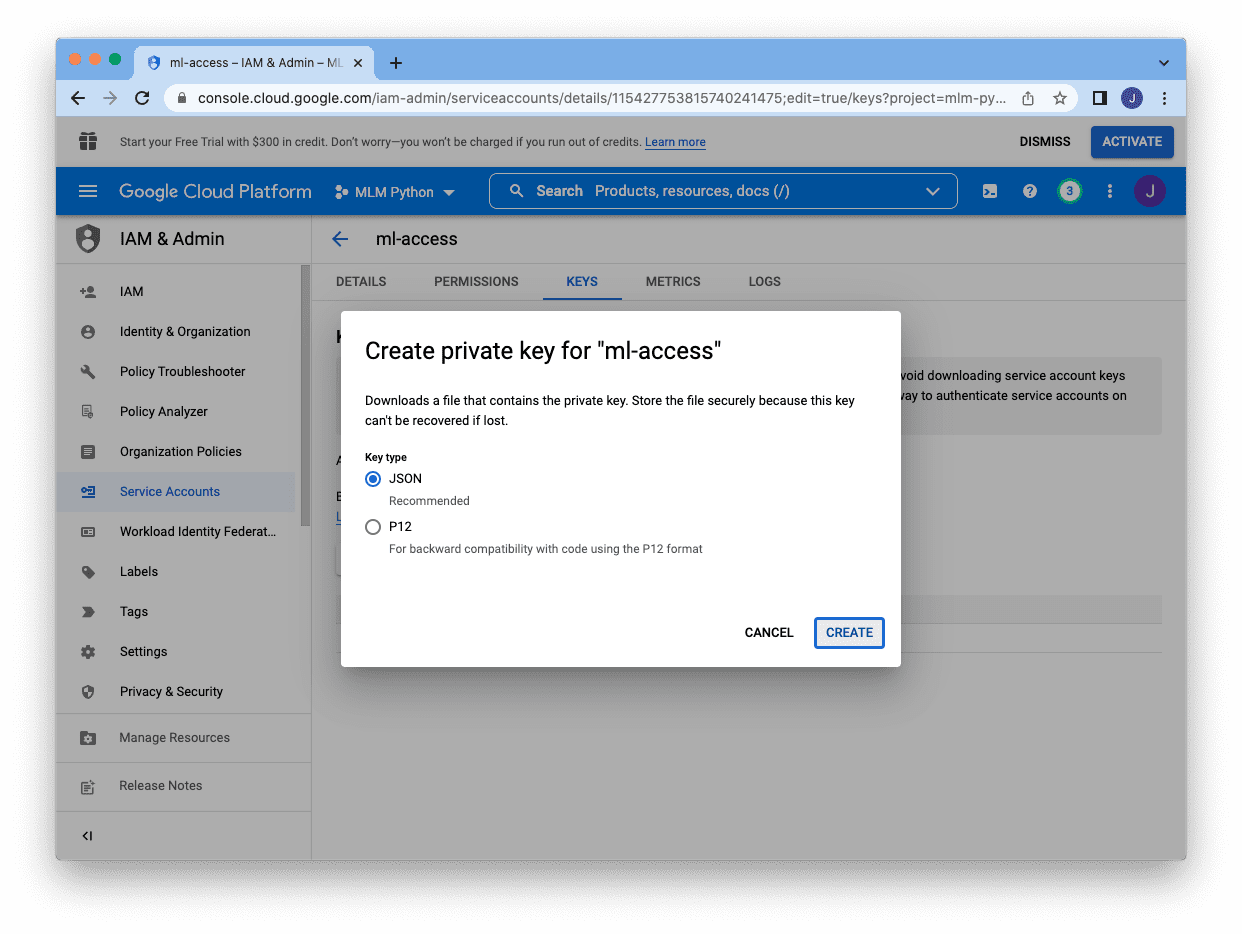
The JSON file might be like the next:
|
{ “kind”: “service_account”, “project_id”: “mlm-python”, “private_key_id”: “3863a6254774259a1249”, “private_key”: “—–BEGIN PRIVATE KEY—–n MIIEvgIBADANBgkqh… —–END PRIVATE KEY—–n”, “client_id”: “11542775381574”, “auth_uri”: “https://accounts.google.com/o/oauth2/auth”, “token_uri”: “https://oauth2.googleapis.com/token”, “auth_provider_x509_cert_url”: “https://www.googleapis.com/oauth2/v1/certs”, “client_x509_cert_url”: “https://www.googleapis.com/robotic/v1/metadata/x509/ml-accesspercent40mlm-python.iam.gserviceaccount.com” } |
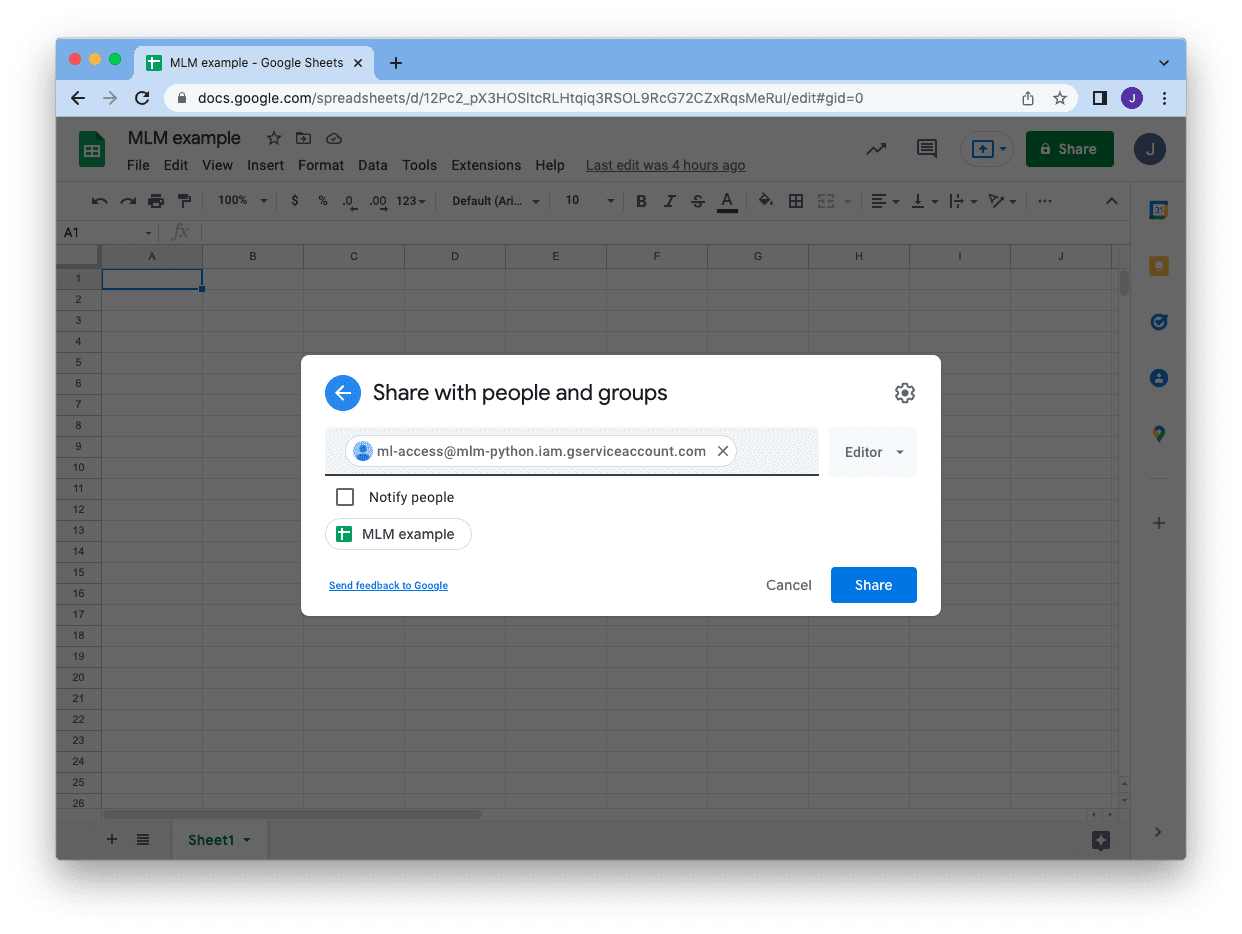
Saving the JSON file, then we are able to return to our Google Sheet and share the sheet with our service account. Click on on the “Share” button at high proper nook and enter the e-mail tackle of the service account. You’ll be able to skip the notification and simply click on “Share”. Then we’re all set!
At this level, we’re able to entry this explicit Google Sheet utilizing the service account from our Python program. To jot down to a Google Sheet, we are able to use the Google’s API. We rely on the JSON file we simply downloaded for the service account (mlm-python.json on this instance) to create a connection first:
|
from oauth2client.service_account import ServiceAccountCredentials from googleapiclient.discovery import construct from httplib2 import Http
cred_file = “mlm-python.json” scopes = [‘https://www.googleapis.com/auth/spreadsheets’] cred = ServiceAccountCredentials.from_json_keyfile_name(cred_file, scopes) service = construct(“sheets”, “v4”, http=cred.authorize(Http())) sheet = service.spreadsheets() |
If we simply created it, there ought to be just one sheet within the file and it has ID 0. All operation utilizing Google’s API is within the type of a JSON format. For instance, the next is how we are able to delete all the pieces on your complete sheet utilizing the connection we simply created:
|
...
sheet_id = ’12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul’ physique = { “requests”: [{ “deleteRange”: { “range”: { “sheetId”: 0 }, “shiftDimension”: “ROWS” } }] } motion = sheet.batchUpdate(spreadsheetId=sheet_id, physique=physique) motion.execute() |
Assume we learn the diabetes dataset right into a DataFrame as in our first instance above, we are able to write your complete dataset into the Google Sheet in a single shot. To take action, we have to create a listing of lists to replicate the 2D array construction of the cells on the sheet, then put the info into the API question:
|
... rows = [list(dataset.columns)] rows += dataset.to_numpy().tolist() maxcol = max(len(row) for row in rows) maxcol = chr(ord(“A”) – 1 + maxcol) motion = sheet.values().append( spreadsheetId = sheet_id, physique = {“values”: rows}, valueInputOption = “RAW”, vary = “Sheet1!A1:%s” % maxcol ) motion.execute() |
Within the above, we assumed the sheet has the identify “Sheet1” (the default, and as you’ll be able to see on the backside of the display screen). We’ll write our knowledge aligned on the high left nook, filling cell A1 (high left nook) onwards. We used dataset.to_numpy().tolist() to gather all knowledge into a listing of lists however we additionally added the column header as the additional row in the beginning.
Studying the info again from the Google Sheet is analogous. The next is how we are able to learn a random row of information.
|
... # Verify the sheets sheet_properties = sheet.get(spreadsheetId=sheet_id).execute()[“sheets”] print(sheet_properties) # Learn it again maxrow = sheet_properties[0][“properties”][“gridProperties”][“rowCount”] maxcol = sheet_properties[0][“properties”][“gridProperties”][“columnCount”] maxcol = chr(ord(“A”) – 1 + maxcol) row = random.randint(1, maxrow) readrange = f“A{row}:{maxcol}{row}” knowledge = sheet.values().get(spreadsheetId=sheet_id, vary=readrange).execute() |
Firstly, we are able to inform what number of rows within the sheet by checking its properties. The print() assertion above will produce the next:
|
[{‘properties’: {‘sheetId’: 0, ‘title’: ‘Sheet1’, ‘index’: 0, ‘sheetType’: ‘GRID’, ‘gridProperties’: {‘rowCount’: 769, ‘columnCount’: 9}}}] |
As we’ve got just one sheet, the checklist incorporates just one properties dictionary. Utilizing this data, we are able to choose a random row, and specify the vary to learn. The variable knowledge above might be a dictionary like the next and the info might be within the type of checklist of lists, and might be accessed utilizing knowledge["values"]:
|
{‘vary’: ‘Sheet1!A536:I536’, ‘majorDimension’: ‘ROWS’, ‘values’: [[‘1’, ’77’, ’56’, ’30’, ’56’, ‘33.3’, ‘1.251’, ’24’, ‘tested_negative’]]} |
Tying all these collectively, the next is the entire code to load knowledge into Google Sheet and skim a random row from it: (make sure to change the sheet_id while you run it)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
import random
from googleapiclient.discovery import construct from httplib2 import Http from oauth2client.service_account import ServiceAccountCredentials from sklearn.datasets import fetch_openml
# Connect with Google Sheet cred_file = “mlm-python.json” scopes = [‘https://www.googleapis.com/auth/spreadsheets’] cred = ServiceAccountCredentials.from_json_keyfile_name(cred_file, scopes) service = construct(“sheets”, “v4”, http=cred.authorize(Http())) sheet = service.spreadsheets()
# Google Sheet ID, as granted entry to the service account sheet_id = ’12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul’
# Delete all the pieces on spreadsheet 0 physique = { “requests”: [{ “deleteRange”: { “range”: { “sheetId”: 0 }, “shiftDimension”: “ROWS” } }] } motion = sheet.batchUpdate(spreadsheetId=sheet_id, physique=physique) motion.execute()
# Learn dataset from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] rows = [list(dataset.columns)] # column headers rows += dataset.to_numpy().tolist() # rows of information
# Write to spreadsheet 0 maxcol = max(len(row) for row in rows) maxcol = chr(ord(“A”) – 1 + maxcol) motion = sheet.values().append( spreadsheetId = sheet_id, physique = {“values”: rows}, valueInputOption = “RAW”, vary = “Sheet1!A1:%s” % maxcol ) motion.execute()
# Verify the sheets sheet_properties = sheet.get(spreadsheetId=sheet_id).execute()[“sheets”] print(sheet_properties)
# Learn a random row of information maxrow = sheet_properties[0][“properties”][“gridProperties”][“rowCount”] maxcol = sheet_properties[0][“properties”][“gridProperties”][“columnCount”] maxcol = chr(ord(“A”) – 1 + maxcol) row = random.randint(1, maxrow) readrange = f“A{row}:{maxcol}{row}” knowledge = sheet.values().get(spreadsheetId=sheet_id, vary=readrange).execute() print(knowledge) |
Undeniably, accessing Google sheet on this approach is simply too verbose. Therefore we’ve got a third-party module gspread obtainable to simplify the operation. After we set up the module, we are able to verify the dimensions of the spreadsheet so simple as the next:
|
import gspread
cred_file = “mlm-python.json” gc = gspread.service_account(filename=cred_file) sheet = gc.open_by_key(sheet_id) spreadsheet = sheet.get_worksheet(0) print(spreadsheet.row_count, spreadsheet.col_count) |
and to clear the sheet, write rows into it, and skim a random row might be finished as follows:
|
... # Clear all knowledge spreadsheet.clear() # Write to spreadsheet spreadsheet.append_rows(rows) # Learn a random row of information maxcol = chr(ord(“A”) – 1 + spreadsheet.col_count) row = random.randint(2, spreadsheet.row_count) readrange = f“A{row}:{maxcol}{row}” knowledge = spreadsheet.get(readrange) print(knowledge) |
Therefore the earlier instance might be simplified into the next, a lot shorter:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
import random
import gspread from sklearn.datasets import fetch_openml
# Google Sheet ID, as granted entry to the service account sheet_id = ’12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul’
# Connect with Google Sheet cred_file = “mlm-python.json” gc = gspread.service_account(filename=cred_file) sheet = gc.open_by_key(sheet_id) spreadsheet = sheet.get_worksheet(0)
# Clear all knowledge spreadsheet.clear()
# Learn dataset from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] rows = [list(dataset.columns)] # column headers rows += dataset.to_numpy().tolist() # rows of information
# Write to spreadsheet spreadsheet.append_rows(rows)
# Verify the variety of rows and columns within the spreadsheet print(spreadsheet.row_count, spreadsheet.col_count)
# Learn a random row of information maxcol = chr(ord(“A”) – 1 + spreadsheet.col_count) row = random.randint(2, spreadsheet.row_count) readrange = f“A{row}:{maxcol}{row}” knowledge = spreadsheet.get(readrange) print(knowledge) |
Much like the case of studying Excel, to make use of the dataset saved in a Google Sheet is healthier to learn it in a single shot slightly than studying row by row in the course of the coaching loop. It is because each time you learn, you’re sending a community request and ready for the reply from Google’ server. This can’t be quick and therefore higher prevented. The next is an instance of how we are able to mix knowledge from Google Sheet with Keras code for coaching:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
import random
import numpy as np import gspread from sklearn.datasets import fetch_openml from tensorflow.keras.fashions import Sequential from tensorflow.keras.layers import Dense
# Google Sheet ID, as granted entry to the service account sheet_id = ’12Pc2_pX3HOSltcRLHtqiq3RSOL9RcG72CZxRqsMeRul’
# Connect with Google Sheet cred_file = “mlm-python.json” gc = gspread.service_account(filename=cred_file) sheet = gc.open_by_key(sheet_id) spreadsheet = sheet.get_worksheet(0)
# Clear all knowledge spreadsheet.clear()
# Learn dataset from OpenML dataset = fetch_openml(“diabetes”, model=1, as_frame=True, return_X_y=False)[“frame”] rows = [list(dataset.columns)] # column headers rows += dataset.to_numpy().tolist() # rows of information
# Write to spreadsheet spreadsheet.append_rows(rows)
# Learn your complete spreadsheet, besides header maxrow = spreadsheet.row_count maxcol = chr(ord(“A”) – 1 + spreadsheet.col_count) knowledge = spreadsheet.get(f“A2:{maxcol}{maxrow}”) X = [row[:–1] for row in knowledge] y = [1 if row[–1]==“tested_positive” else 0 for row in knowledge] X, y = np.asarray(X).astype(float), np.asarray(y)
# create binary classification mannequin mannequin = Sequential() mannequin.add(Dense(16, input_dim=8, activation=‘relu’)) mannequin.add(Dense(8, activation=‘relu’)) mannequin.add(Dense(1, activation=‘sigmoid’)) mannequin.compile(loss=‘binary_crossentropy’, optimizer=‘adam’, metrics=[‘accuracy’])
# prepare mannequin historical past = mannequin.match(X, y, epochs=5) |
Different use of the database
The examples above are displaying you entry a database of a spreadsheet. We assume dataset is saved and it’s consumed by a machine studying mannequin in coaching loop. Whereas that is a method of utilizing an exterior knowledge storage, however not the one approach. Another use case of database can be:
- As a storage for logs to maintain file of element of this system, e.g., at what time some script is executed. That is notably helpful to maintain monitor of adjustments if the script goes to mutate one thing, e.g., downloading some file and overwriting the previous model
- As a device to gather knowledge. Identical to we might use
GridSearchCVfrom scikit-learn, fairly often we’d consider the mannequin efficiency with totally different mixture of hyperparameters. If the mannequin is giant and complicated, we might need to distribute the analysis to totally different machines and acquire the outcome. It might be useful if we are able to add a couple of strains on the finish of this system to put in writing the cross validation outcome to a database of spreadsheet so we are able to tabulate the outcome with the hyperparameters chosen. Having these knowledge saved in a structural format permits us to report our conclusion later. - As a device to configure the mannequin. As a substitute of writing the hyperparameters mixture and the validation rating, we are able to use it as a device to offer us the hyperparameter choice on working our program. Ought to we determined to alter the parameters, we are able to merely open up a Google Sheet, for instance, to make the change as a substitute of modifying the code.
Additional Studying
The next are some assets so that you can go deeper:
Books
APIs and Libraries
Articles
Software program
Abstract
On this tutorial, you the way you need to use exterior knowledge storages, together with a database or a spreadsheet.
Particularly, you realized:
- How one can make your Python program entry a relational database equivalent to SQLite utilizing SQL statements
- How you need to use dbm as a key-value retailer and use it like a Python dictionary
- The right way to learn from Excel information and write to it
- The right way to entry Google Sheet over the Web
- How we are able to use all these to host dataset and use them in our machine studying undertaking
[ad_2]