

{kind=link}
[ad_1]
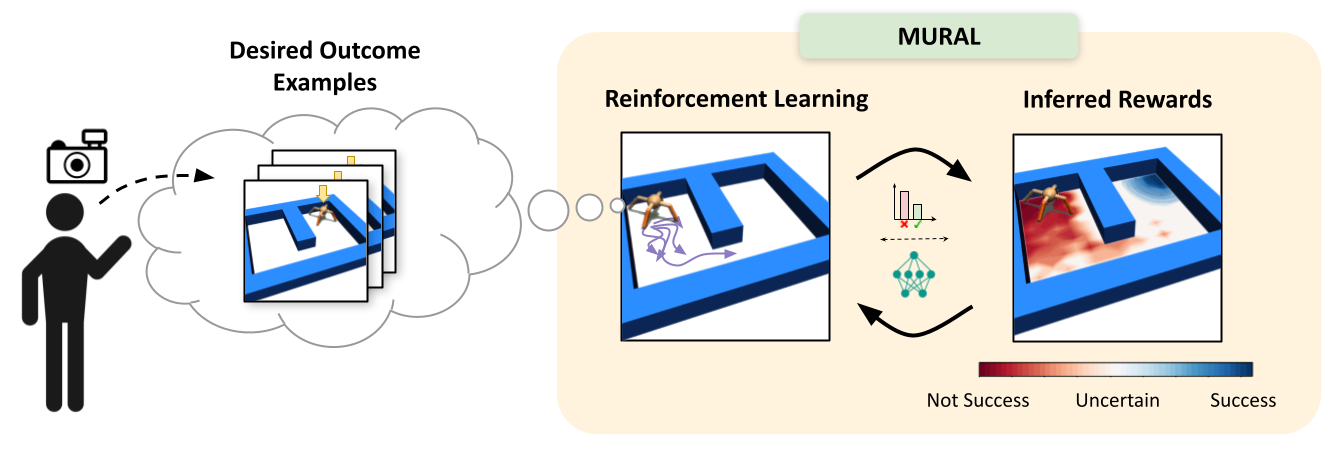
Diagram of MURAL, our methodology for studying uncertainty-aware rewards for RL. After the consumer supplies a couple of examples of desired outcomes, MURAL routinely infers a reward perform that takes under consideration these examples and the agent’s uncertainty for every state.
Though reinforcement studying has proven success in domains such as robotics, chip placement and enjoying video video games, it’s often intractable in its most normal type. Specifically, deciding when and tips on how to go to new states within the hopes of studying extra in regards to the setting will be difficult, particularly when the reward sign is uninformative. These questions of reward specification and exploration are intently related — the extra directed and “effectively formed” a reward perform is, the better the issue of exploration turns into. The reply to the query of tips on how to discover most successfully is prone to be intently knowledgeable by the actual alternative of how we specify rewards.
For unstructured downside settings resembling robotic manipulation and navigation — areas the place RL holds substantial promise for enabling higher real-world clever brokers — reward specification is usually the important thing issue stopping us from tackling harder duties. The problem of efficient reward specification is two-fold: we require reward capabilities that may be laid out in the true world with out considerably instrumenting the setting, but in addition successfully information the agent to unravel tough exploration issues. In our latest work, we deal with this problem by designing a reward specification approach that naturally incentivizes exploration and allows brokers to discover environments in a directed method.
Consequence Pushed RL and Classifier Based mostly Rewards
Whereas RL in its most normal type will be fairly tough to sort out, we are able to contemplate a extra managed set of subproblems that are extra tractable whereas nonetheless encompassing a major set of fascinating issues. Specifically, we contemplate a subclass of issues which has been known as consequence pushed RL. In consequence pushed RL issues, the agent isn’t merely tasked with exploring the setting till it possibilities upon reward, however as an alternative is supplied with examples of profitable outcomes within the setting. These profitable outcomes can then be used to deduce an appropriate reward perform that may be optimized to unravel the specified issues in new situations.
Extra concretely, in consequence pushed RL issues, a human supervisor first supplies a set of profitable consequence examples  , representing states through which the specified activity has been completed. Given these consequence examples, an appropriate reward perform
, representing states through which the specified activity has been completed. Given these consequence examples, an appropriate reward perform  will be inferred that encourages an agent to attain the specified consequence examples. In some ways, this downside is analogous to that of inverse reinforcement studying, however solely requires examples of profitable states fairly than full knowledgeable demonstrations.
will be inferred that encourages an agent to attain the specified consequence examples. In some ways, this downside is analogous to that of inverse reinforcement studying, however solely requires examples of profitable states fairly than full knowledgeable demonstrations.
When fascinated with tips on how to truly infer the specified reward perform from profitable consequence examples , the best approach that involves thoughts is to easily deal with the reward inference downside as a classification downside – “Is the present state a profitable consequence or not?” Prior work has carried out this instinct, inferring rewards by coaching a easy binary classifier to differentiate whether or not a selected state  is a profitable consequence or not, utilizing the set of supplied purpose states as positives, and all on-policy samples as negatives. The algorithm then assigns rewards to a selected state utilizing the success possibilities from the classifier. This has been proven to have a detailed connection to the framework of inverse reinforcement studying.
is a profitable consequence or not, utilizing the set of supplied purpose states as positives, and all on-policy samples as negatives. The algorithm then assigns rewards to a selected state utilizing the success possibilities from the classifier. This has been proven to have a detailed connection to the framework of inverse reinforcement studying.
Classifier-based strategies present a way more intuitive solution to specify desired outcomes, eradicating the necessity for hand-designed reward capabilities or demonstrations:
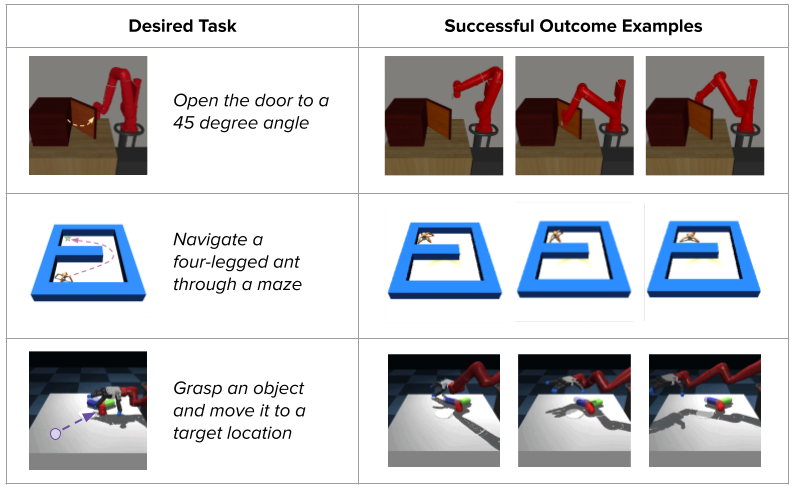
These classifier-based strategies have achieved promising outcomes on robotics duties resembling material placement, mug pushing, bead and screw manipulation, and extra. Nonetheless, these successes are typically restricted to easy shorter-horizon duties, the place comparatively little exploration is required to seek out the purpose.
What’s Lacking?
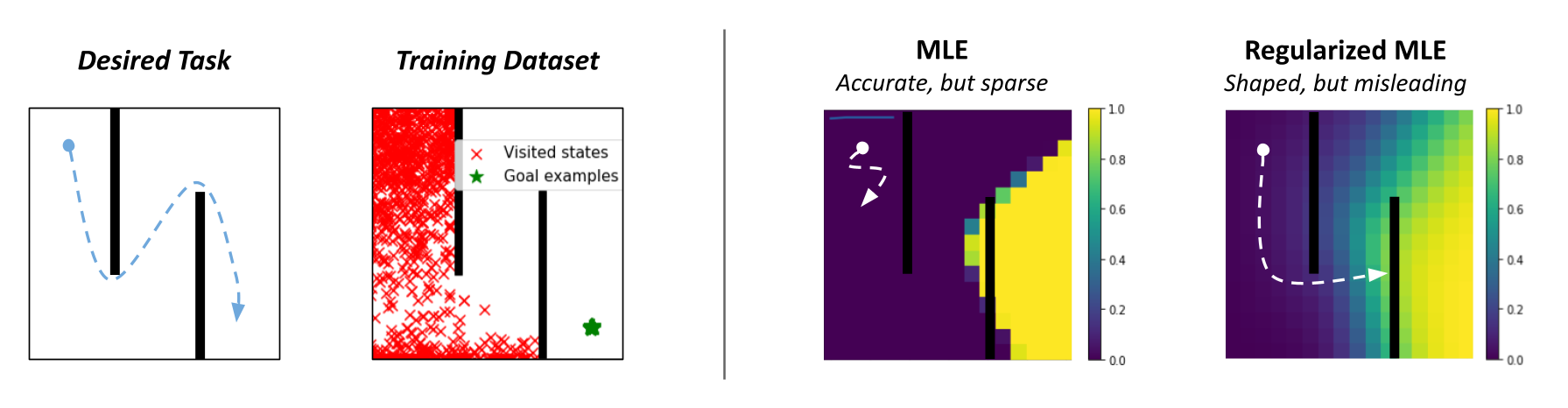
Normal success classifiers in RL endure from the important thing difficulty of overconfidence, which prevents them from offering helpful shaping for arduous exploration duties. To grasp why, let’s contemplate a toy 2D maze setting the place the agent should navigate in a zigzag path from the highest left to the underside proper nook. Throughout coaching, classifier-based strategies would label all on-policy states as negatives and user-provided consequence examples as positives. A typical neural community classifier would simply assign success possibilities of 0 to all visited states, leading to uninformative rewards within the intermediate levels when the purpose has not been reached.
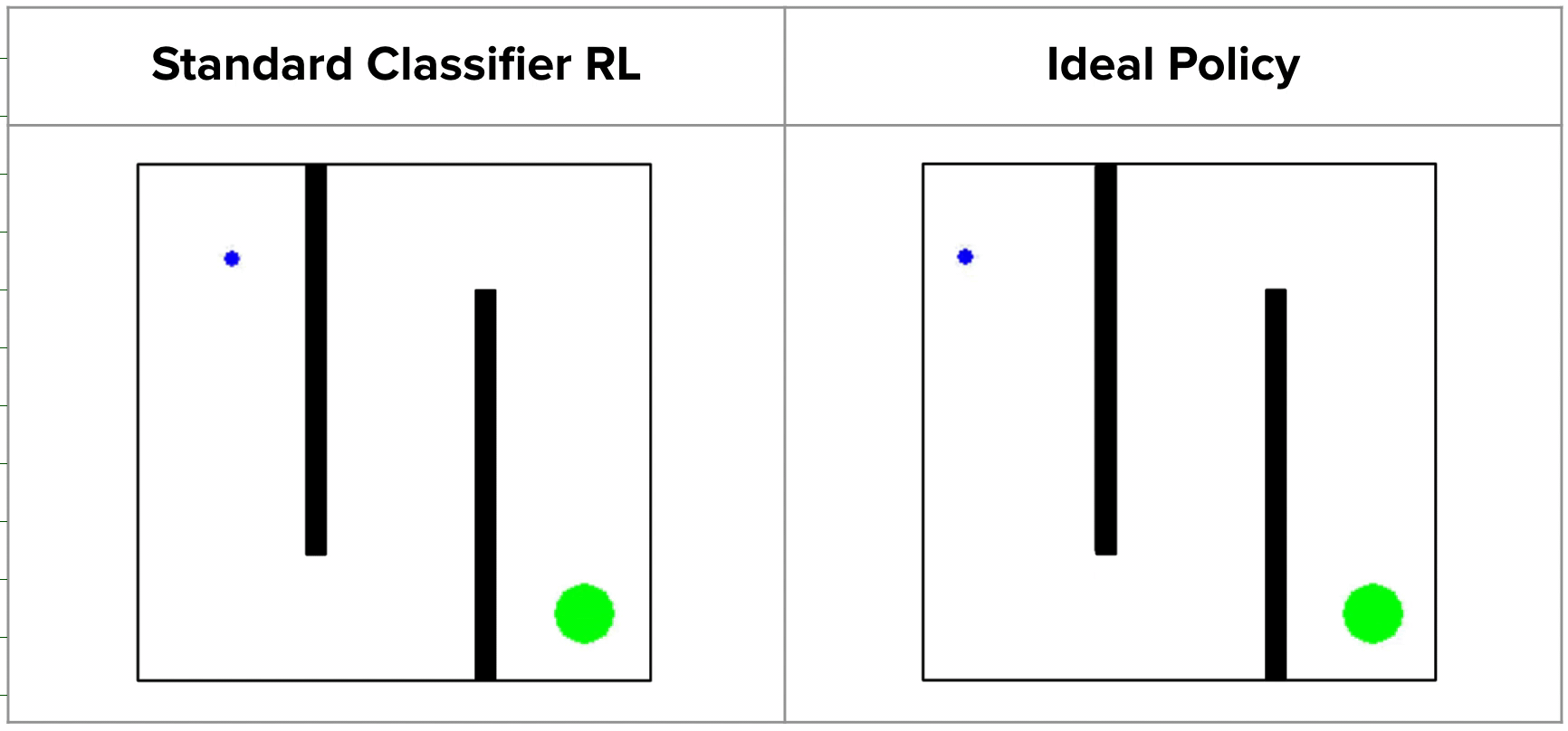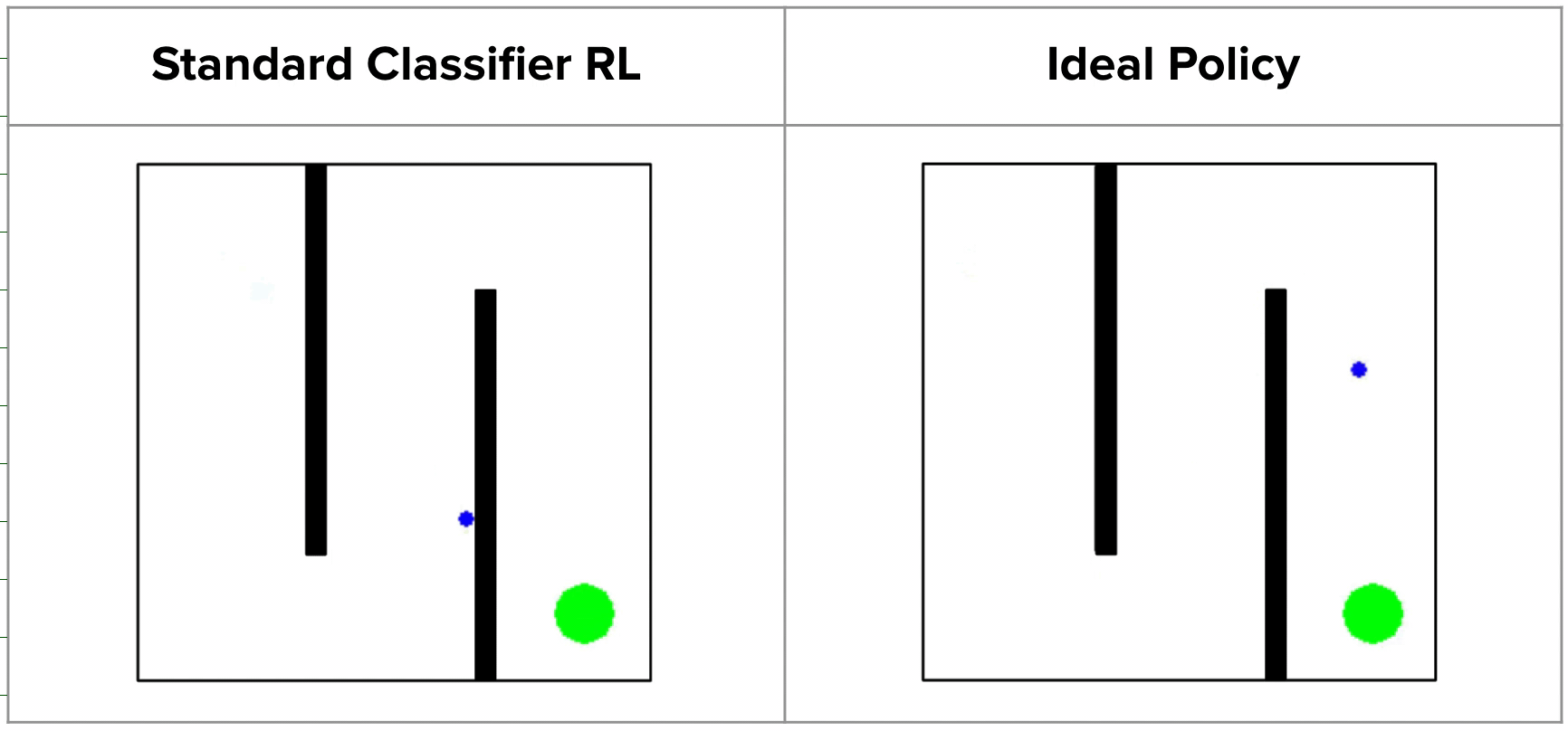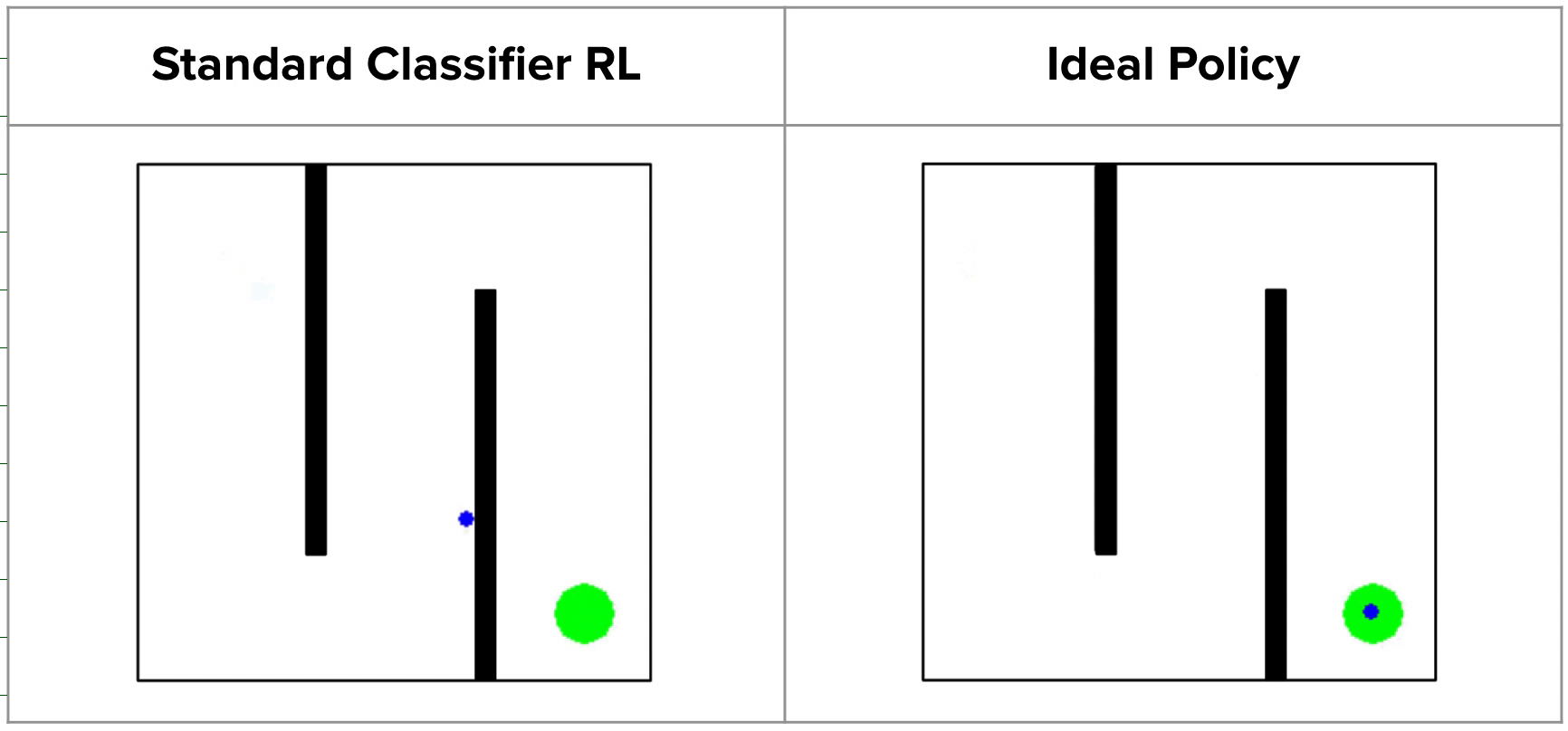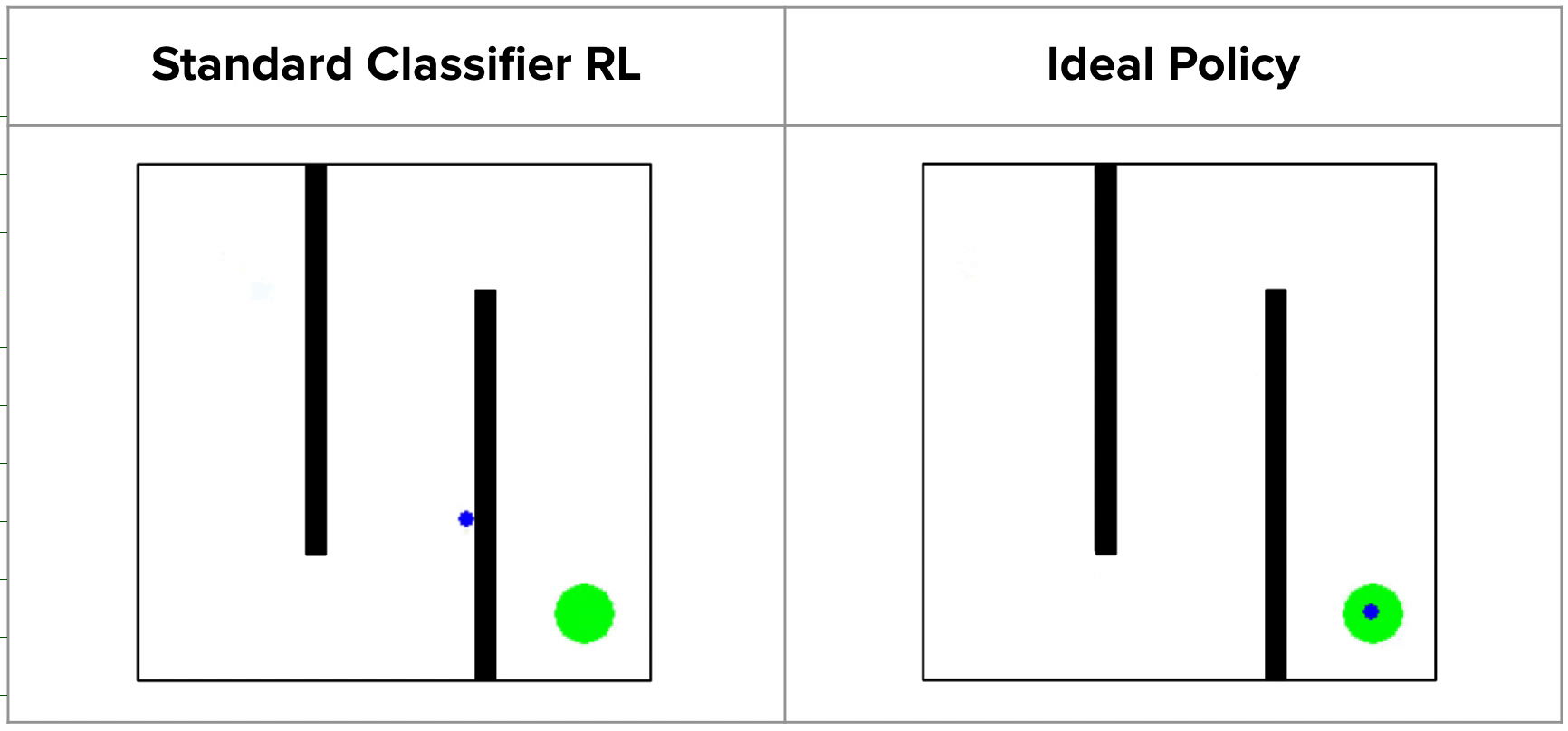
Since such rewards wouldn’t be helpful for guiding the agent in any specific course, prior works are inclined to regularize their classifiers utilizing strategies like weight decay or mixup, which permit for extra easily growing rewards as we strategy the profitable consequence states. Nonetheless, whereas this works on many shorter-horizon duties, such strategies can truly produce very deceptive rewards. For instance, on the 2D maze, a regularized classifier would assign comparatively excessive rewards to states on the other facet of the wall from the true purpose, since they’re near the purpose in x-y area. This causes the agent to get caught in a neighborhood optima, by no means bothering to discover past the ultimate wall!
In reality, that is precisely what occurs in follow:
Uncertainty-Conscious Rewards by way of CNML
As mentioned above, the important thing difficulty with unregularized success classifiers for RL is overconfidence — by instantly assigning rewards of 0 to all visited states, we shut off many paths that may ultimately result in the purpose. Ideally, we want our classifier to have an acceptable notion of uncertainty when outputting success possibilities, in order that we are able to keep away from excessively low rewards with out affected by the deceptive native optima that outcome from regularization.
Conditional Normalized Most Chance (CNML)
One methodology significantly well-suited for this activity is Conditional Normalized Most Chance (CNML). The idea of normalized most chance (NML) has sometimes been used within the Bayesian inference literature for mannequin choice, to implement the minimal description size precept. In newer work, NML has been tailored to the conditional setting to provide fashions which are significantly better calibrated and preserve a notion of uncertainty, whereas attaining optimum worst case classification remorse. Given the challenges of overconfidence described above, this is a perfect alternative for the issue of reward inference.
Moderately than merely coaching fashions through most chance, CNML performs a extra complicated inference process to provide likelihoods for any level that’s being queried for its label. Intuitively, CNML constructs a set of various most chance issues by labeling a selected question level  with each potential label worth that it would take, then outputs a ultimate prediction primarily based on how simply it was in a position to adapt to every of these proposed labels given all the dataset noticed to date. Given a selected question level , and a previous dataset
with each potential label worth that it would take, then outputs a ultimate prediction primarily based on how simply it was in a position to adapt to every of these proposed labels given all the dataset noticed to date. Given a selected question level , and a previous dataset ![mathcal{D} = left[x_0, y_0, … x_N, y_Nright]](https://robohub.org/wp-content/ql-cache/quicklatex.com-4dcaa729b4b1f9b287b123cbf4415d4e_l3.png "Rendered by QuickLaTeX.com") , CNML solves okay completely different most chance issues and normalizes them to provide the specified label chance
, CNML solves okay completely different most chance issues and normalizes them to provide the specified label chance  , the place
, the place  represents the variety of potential values that the label might take. Formally, given a mannequin
represents the variety of potential values that the label might take. Formally, given a mannequin  , loss perform
, loss perform  , coaching dataset
, coaching dataset  with lessons
with lessons  , and a brand new question level
, and a brand new question level  , CNML solves the next most chance issues:
, CNML solves the next most chance issues:
![[theta_i = text{arg}max_{theta} mathbb{E}_{mathcal{D} cup (x_q, C_i)}left[ mathcal{L}(f_{theta}(x), y)right]]](https://robohub.org/wp-content/ql-cache/quicklatex.com-f23601c051d52449da93909391be7caa_l3.png "Rendered by QuickLaTeX.com")
It then generates predictions for every of the lessons utilizing their corresponding fashions, and normalizes the outcomes for its ultimate output:
![[p_text{CNML}(C_i|x) = frac{f_{theta_i}(x)}{sum limits_{j=1}^k f_{theta_j}(x)}]](https://robohub.org/wp-content/ql-cache/quicklatex.com-ade6f974bec34a8a39b292fc099a2bee_l3.png "Rendered by QuickLaTeX.com")
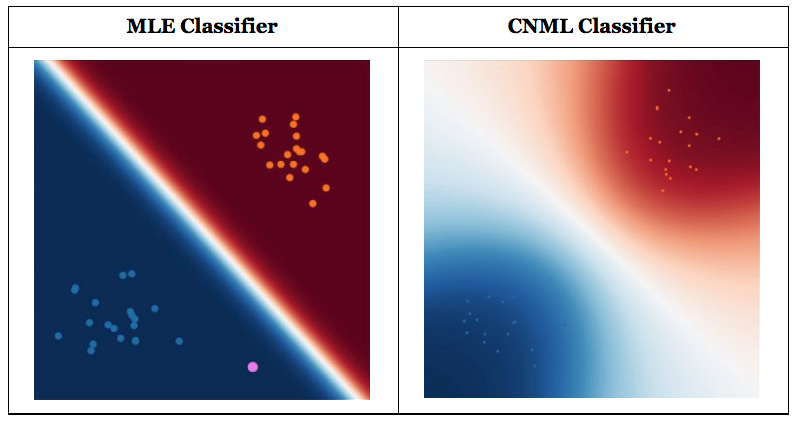
Comparability of outputs from a typical classifier and a CNML classifier. CNML outputs extra conservative predictions on factors which are removed from the coaching distribution, indicating uncertainty about these factors’ true outputs. (Credit score: Aurick Zhou, BAIR Weblog)
Intuitively, if the question level is farther from the unique coaching distribution represented by D, CNML will have the ability to extra simply adapt to any arbitrary label in , making the ensuing predictions nearer to uniform. On this method, CNML is ready to produce higher calibrated predictions, and preserve a transparent notion of uncertainty primarily based on which information level is being queried.
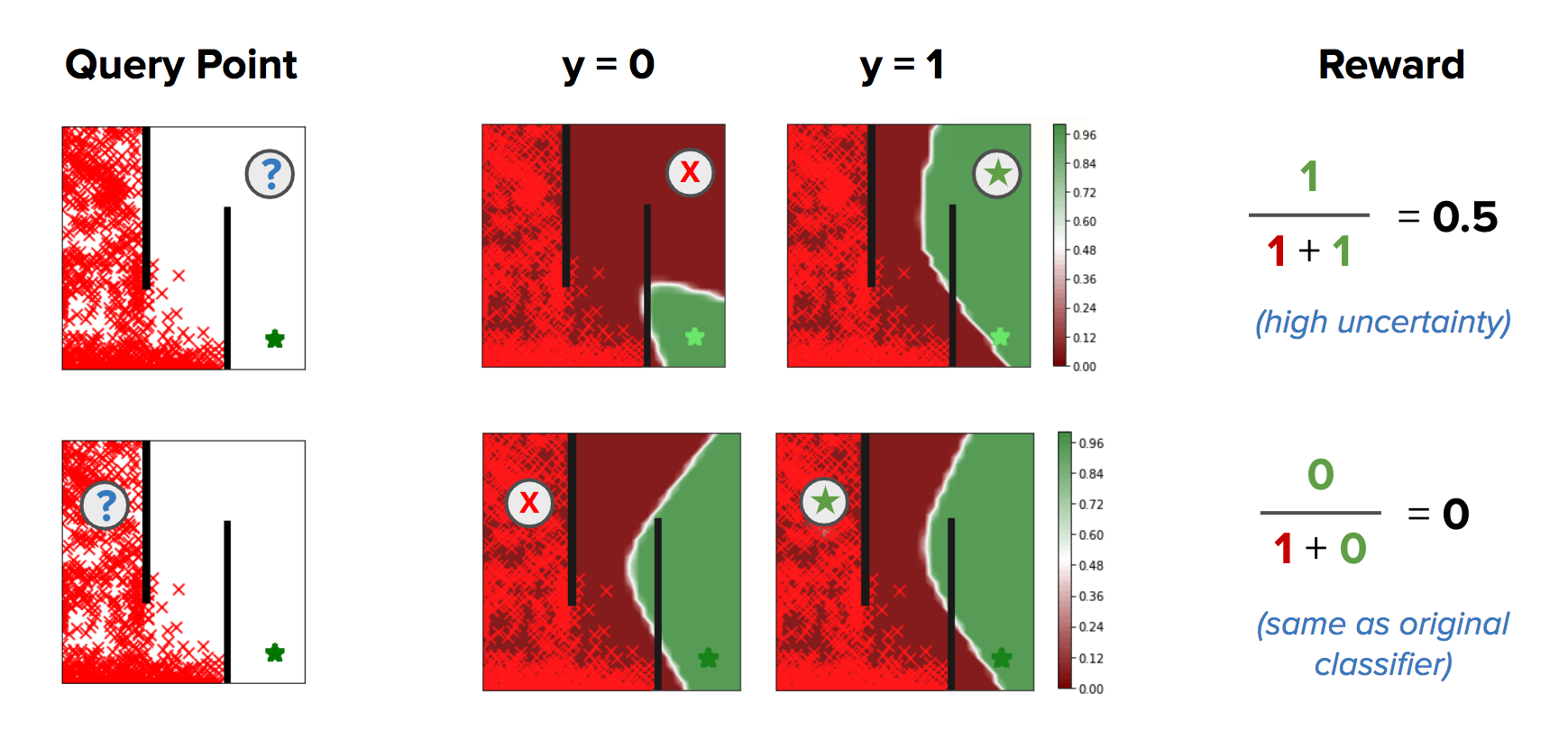
Leveraging CNML-based classifiers for Reward Inference
Given the above background on CNML as a way to provide higher calibrated classifiers, it turns into clear that this supplies us an easy solution to deal with the overconfidence downside with classifier primarily based rewards in consequence pushed RL. By changing a typical most chance classifier with one educated utilizing CNML, we’re in a position to seize a notion of uncertainty and acquire directed exploration for consequence pushed RL. In reality, within the discrete case, CNML corresponds to imposing a uniform prior on the output area — in an RL setting, that is equal to utilizing a count-based exploration bonus because the reward perform. This seems to offer us a really acceptable notion of uncertainty within the rewards, and solves most of the exploration challenges current in classifier primarily based RL.
Nonetheless, we don’t often function within the discrete case. Normally, we use expressive perform approximators and the ensuing representations of various states on the earth share similarities. When a CNML primarily based classifier is discovered on this situation, with expressive perform approximation, we see that it may well present extra than simply activity agnostic exploration. In reality, it may well present a directed notion of reward shaping, which guides an agent in the direction of the purpose fairly than merely encouraging it to increase the visited area naively. As visualized beneath, CNML encourages exploration by giving optimistic success possibilities in less-visited areas, whereas additionally offering higher shaping in the direction of the purpose.

As we’ll present in our experimental outcomes, this instinct scales to increased dimensional issues and extra complicated state and motion areas, enabling CNML primarily based rewards to unravel considerably more difficult duties than is feasible with typical classifier primarily based rewards.
Nonetheless, on nearer inspection of the CNML process, a serious problem turns into obvious. Every time a question is made to the CNML classifier, completely different most chance issues must be solved to convergence, then normalized to provide the specified chance. As the dimensions of the dataset will increase, because it naturally does in reinforcement studying, this turns into a prohibitively sluggish course of. In reality, as seen in Desk 1, RL with customary CNML primarily based rewards takes round 4 hours to coach a single epoch (1000 timesteps). Following this process blindly would take over a month to coach a single RL agent, necessitating a extra time environment friendly resolution. That is the place we discover meta-learning to be a vital instrument.
Meta-learning is a instrument that has seen a variety of use circumstances in few-shot studying for picture classification, studying faster optimizers and even studying extra environment friendly RL algorithms. In essence, the concept behind meta-learning is to leverage a set of “meta-training” duties to be taught a mannequin (and infrequently an adaptation process) that may in a short time adapt to a brand new activity drawn from the identical distribution of issues.
Meta-learning methods are significantly effectively suited to our class of computational issues because it entails shortly fixing a number of completely different most chance issues to judge the CNML chance. Every the utmost chance issues share important similarities with one another, enabling a meta-learning algorithm to in a short time adapt to provide options for every particular person downside. In doing so, meta-learning supplies us an efficient instrument for producing estimates of normalized most chance considerably extra shortly than potential earlier than.
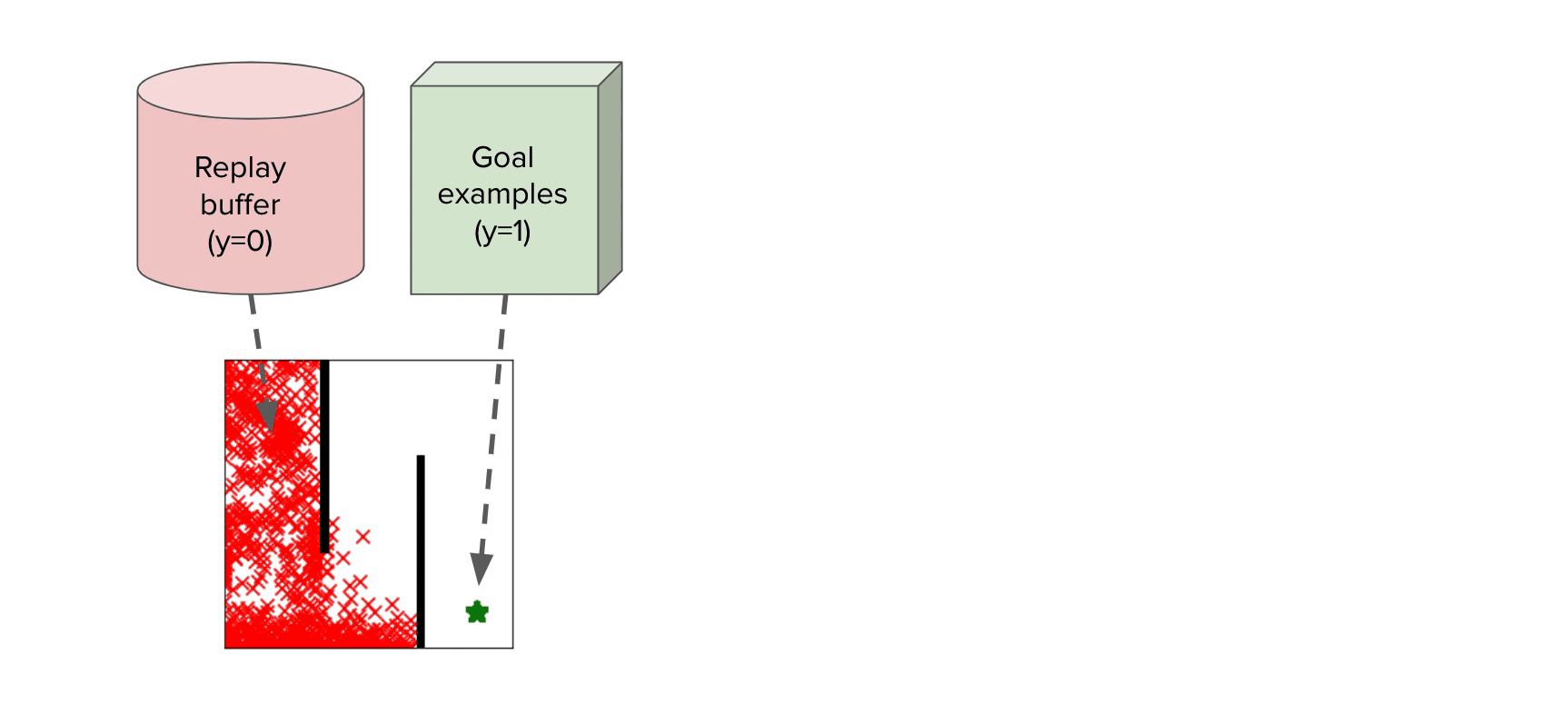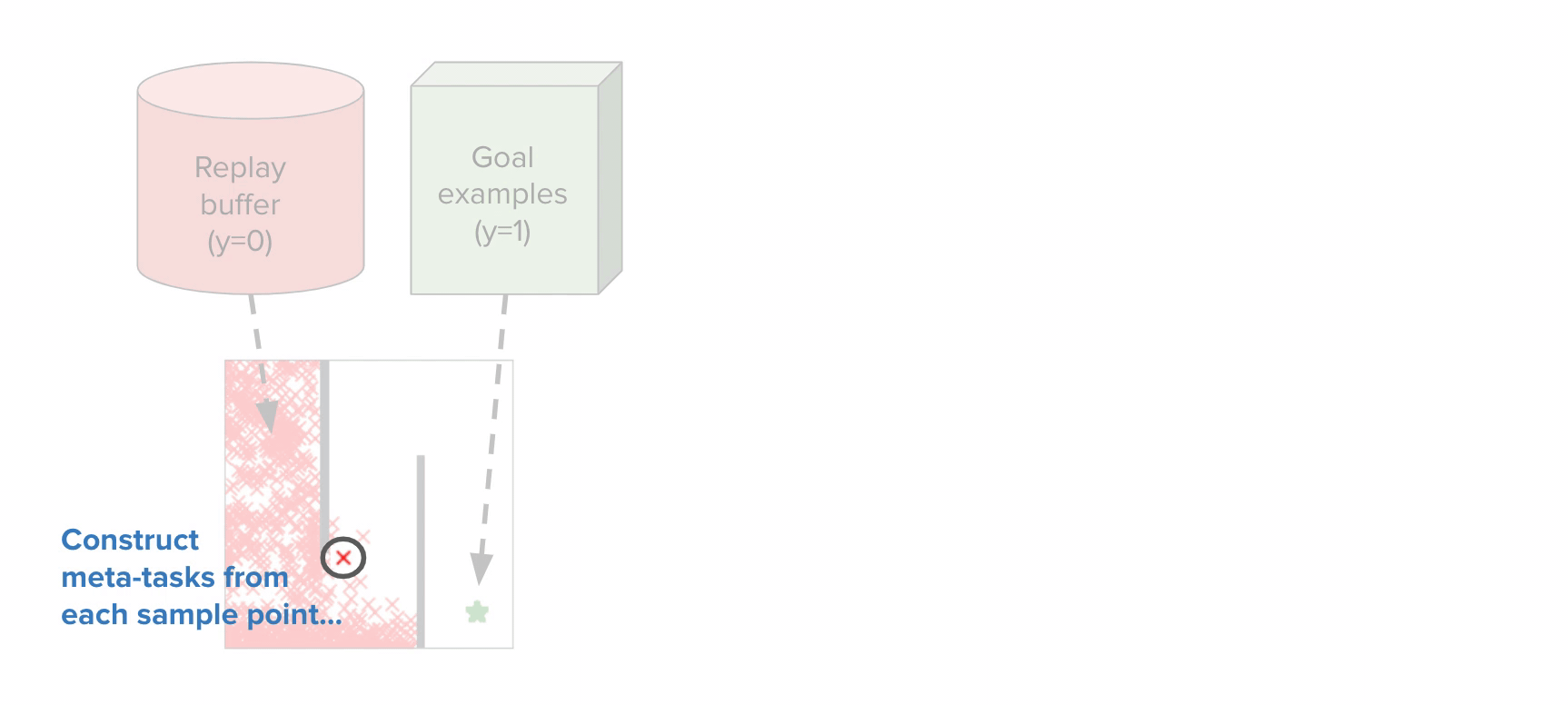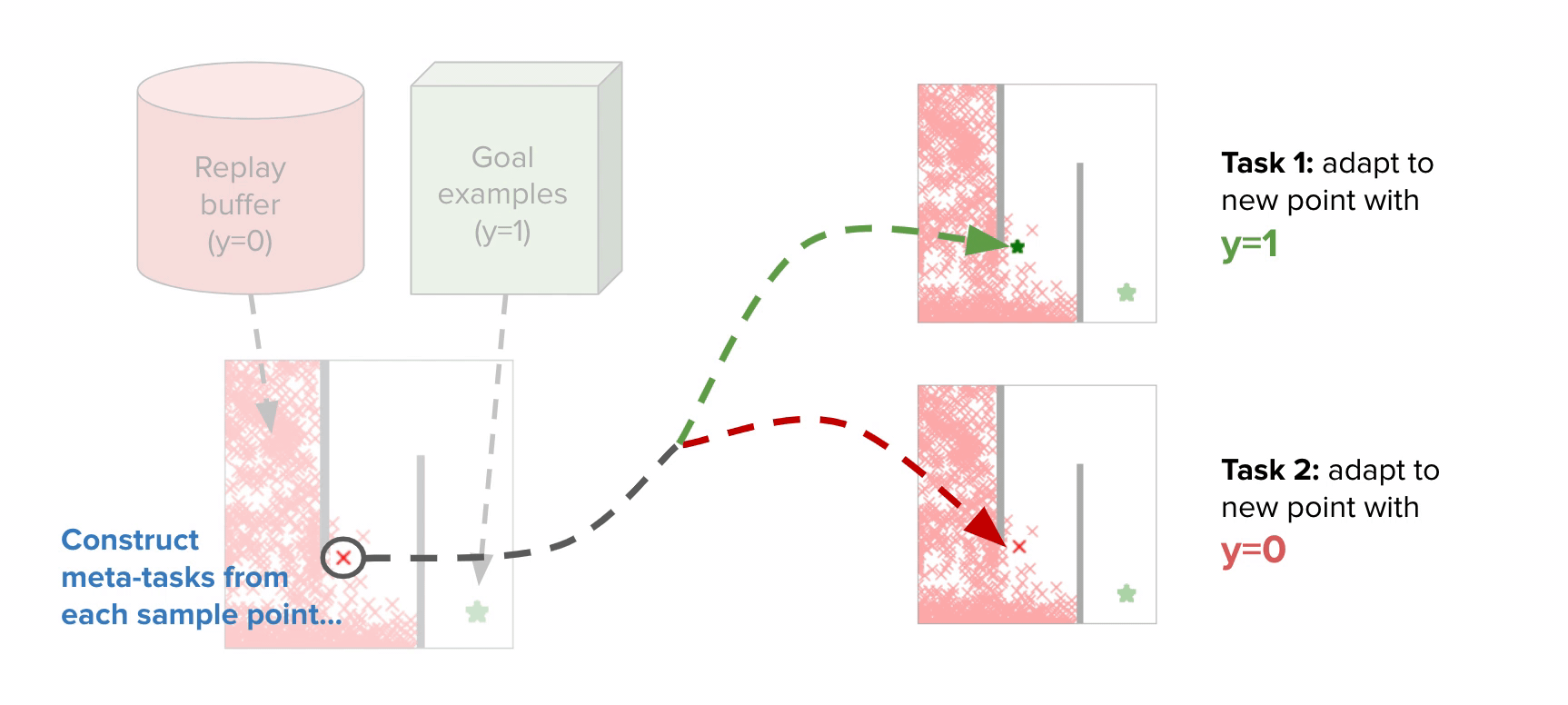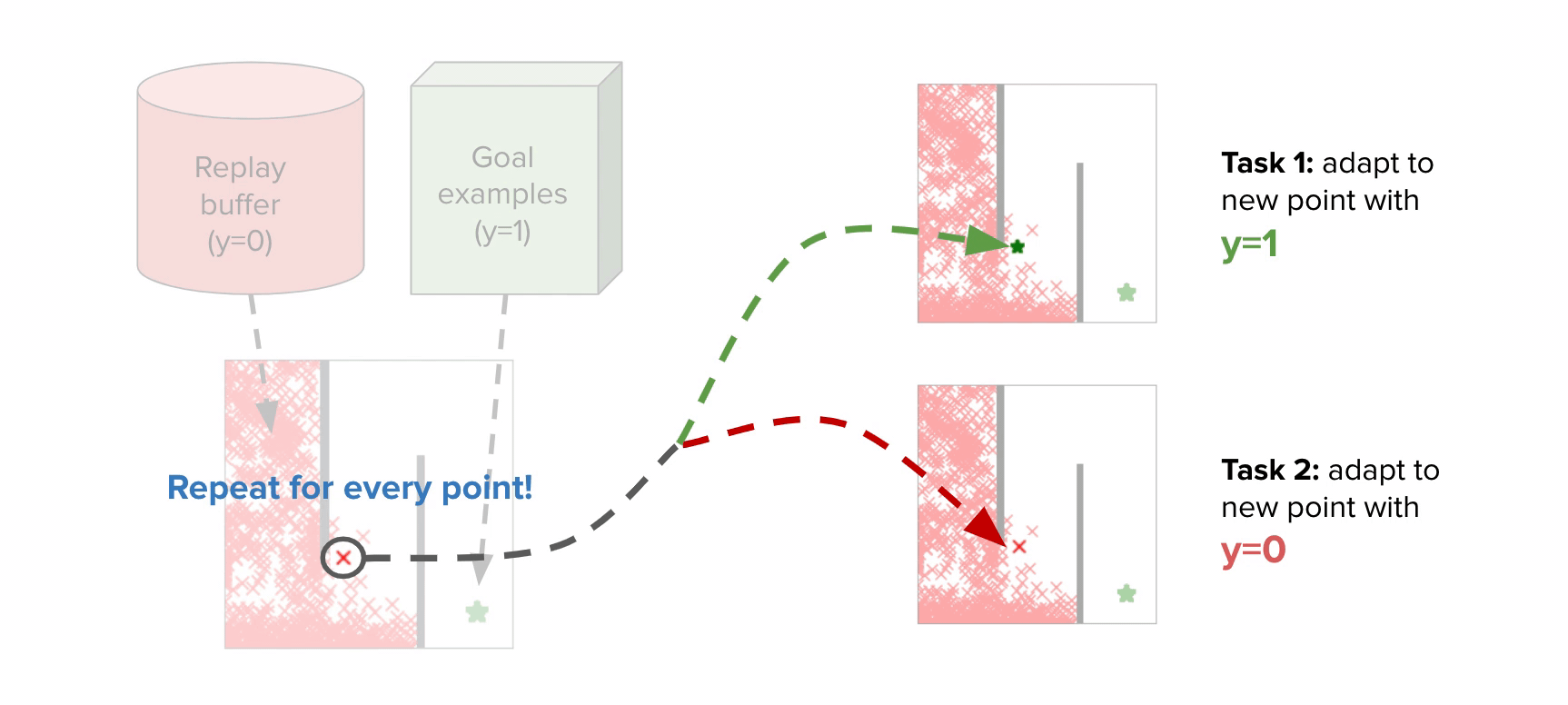
The instinct behind tips on how to apply meta-learning to the CNML (meta-NML) will be understood by the graphic above. For a data-set of  factors, meta-NML would first assemble
factors, meta-NML would first assemble  duties, comparable to the constructive and damaging most chance issues for every datapoint within the dataset. Given these constructed duties as a (meta) coaching set, a meta–studying algorithm will be utilized to be taught a mannequin that may in a short time be tailored to provide options to any of those most chance issues. Outfitted with this scheme to in a short time resolve most chance issues, producing CNML predictions round
duties, comparable to the constructive and damaging most chance issues for every datapoint within the dataset. Given these constructed duties as a (meta) coaching set, a meta–studying algorithm will be utilized to be taught a mannequin that may in a short time be tailored to provide options to any of those most chance issues. Outfitted with this scheme to in a short time resolve most chance issues, producing CNML predictions round  x quicker than potential earlier than. Prior work studied this downside from a Bayesian strategy, however we discovered that it usually scales poorly for the issues we thought-about.
x quicker than potential earlier than. Prior work studied this downside from a Bayesian strategy, however we discovered that it usually scales poorly for the issues we thought-about.
Outfitted with a instrument for effectively producing predictions from the CNML distribution, we are able to now return to the purpose of fixing outcome-driven RL with uncertainty conscious classifiers, leading to an algorithm we name MURAL.
To extra successfully resolve consequence pushed RL issues, we incorporate meta-NML into the usual classifier primarily based process as follows: After every epoch of RL, we pattern a batch of  factors from the replay buffer and use them to assemble
factors from the replay buffer and use them to assemble  meta-tasks. We then run
meta-tasks. We then run  iteration of meta-training on our mannequin.
iteration of meta-training on our mannequin.
We assign rewards utilizing NML, the place the NML outputs are approximated utilizing just one gradient step for every enter level.
The ensuing algorithm, which we name MURAL, replaces the classifier portion of ordinary classifier-based RL algorithms with a meta-NML mannequin as an alternative. Though meta-NML can solely consider enter factors one after the other as an alternative of in batches, it’s considerably quicker than naive CNML, and MURAL remains to be comparable in runtime to straightforward classifier-based RL, as proven in Desk 1 beneath.
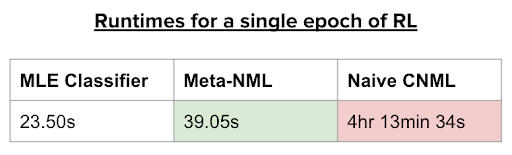
Desk 1. Runtimes for a single epoch of RL on the 2D maze activity.
We consider MURAL on a wide range of navigation and robotic manipulation duties, which current a number of challenges together with native optima and tough exploration. MURAL solves all of those duties efficiently, outperforming prior classifier-based strategies in addition to customary RL with exploration bonuses.

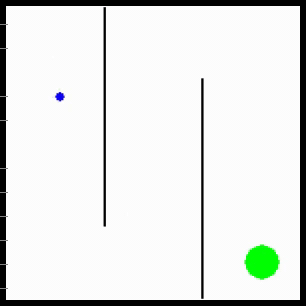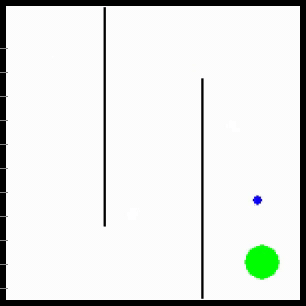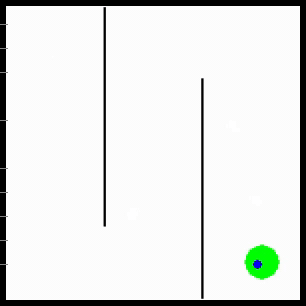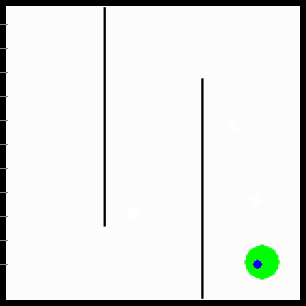
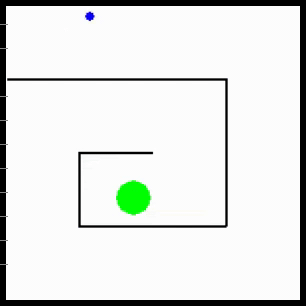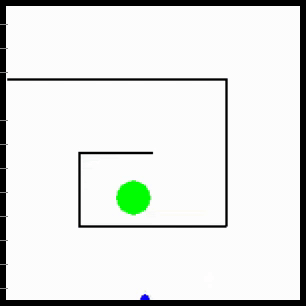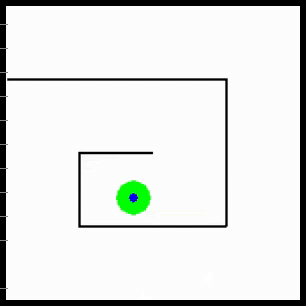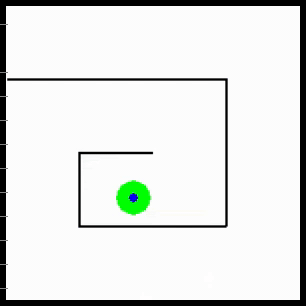




Visualization of behaviors discovered by MURAL. MURAL is ready to carry out a wide range of behaviors in navigation and manipulation duties, inferring rewards from consequence examples.
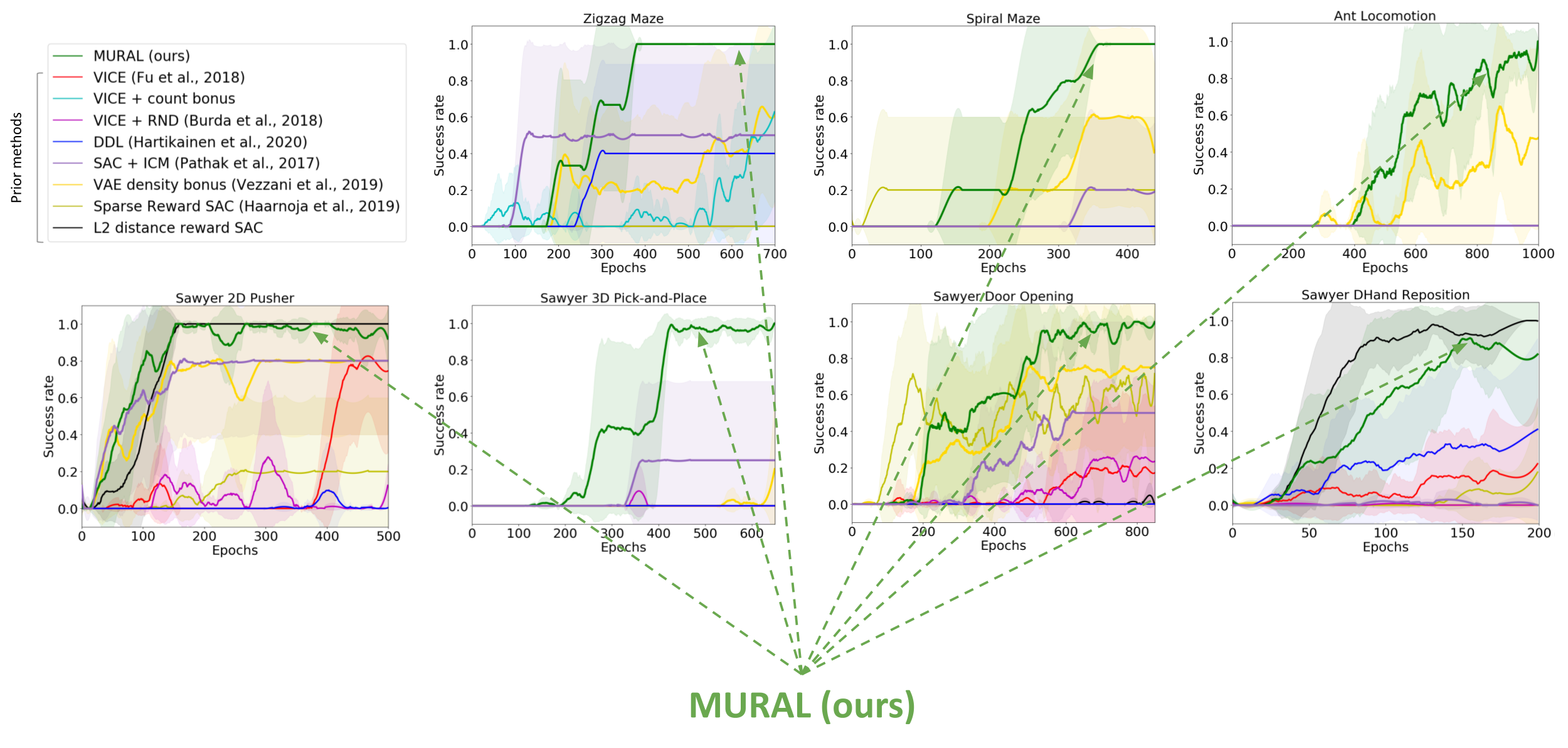
Quantitative comparability of MURAL to baselines. MURAL is ready to outperform baselines which carry out task-agnostic exploration, customary most chance classifiers.
This means that utilizing meta-NML primarily based classifiers for consequence pushed RL supplies us an efficient method to offer rewards for RL issues, offering advantages each when it comes to exploration and directed reward shaping.
Takeaways
In conclusion, we confirmed how consequence pushed RL can outline a category of extra tractable RL issues. Normal strategies utilizing classifiers can usually fall brief in these settings as they’re unable to offer any advantages of exploration or steerage in the direction of the purpose. Leveraging a scheme for coaching uncertainty conscious classifiers through conditional normalized most chance permits us to extra successfully resolve this downside, offering advantages when it comes to exploration and reward shaping in the direction of profitable outcomes. The overall ideas outlined on this work counsel that contemplating tractable approximations to the final RL downside might permit us to simplify the problem of reward specification and exploration in RL whereas nonetheless encompassing a wealthy class of management issues.
This submit is predicated on the paper “MURAL: Meta-Studying Uncertainty-Conscious Rewards for Consequence-Pushed Reinforcement Studying”, which was introduced at ICML 2021. You may see outcomes on our web site, and we present code to breed our experiments.
tags: c-Analysis-Innovation

BAIR Weblog
is the official weblog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.
BAIR Weblog
is the official weblog of the Berkeley Synthetic Intelligence Analysis (BAIR) Lab.
[ad_2]