
{kind=link}
[ad_1]
Final Up to date on July 15, 2022
Loss metric is essential for neural networks. As all machine studying mannequin is a optimization downside or one other, the loss is the target perform to reduce. In neural networks, the optimization is finished with gradient descent and backpropagation. However what are loss features and the way are they affecting our neural networks?
On this put up, we’ll cowl what loss features are and go into some generally used loss features and how one can apply them to your neural networks.
After studying this text, you’ll be taught:
- What are loss features and the way they’re completely different from metrics
- Frequent loss features for regression and classification issues
- Easy methods to use loss features in your TensorFlow mannequin
Let’s get began!

Loss features in TensorFlow.
Picture by Ian Taylor. Some rights reserved.
Overview
This text is cut up into 5 part; they’re:
- What are loss features?
- Imply absolute error
- Imply squared error
- Categorical cross-entropy
- Loss features in apply
What are loss features?
In neural networks, loss features assist optimize the efficiency of the mannequin. They’re often used to measure some penalty that the mannequin is incurring on its predictions, such because the deviation of the prediction away from the bottom reality label. Loss features are often differentiable throughout their area (however it’s allowed that the gradient is undefined just for very particular factors, akin to x = 0, which is principally ignored in apply). Within the coaching loop, we differentiate them with respect to parameters and used these gradients for our backpropagation and gradient descent steps to optimize our mannequin on the coaching set.
Loss features are additionally barely completely different from metrics. Whereas loss features can inform us the efficiency of our mannequin, they may not be of direct curiosity or simply explainable by people. That is the place metrics are available in. Metrics akin to accuracy are far more helpful for people to grasp the efficiency of a neural community despite the fact that they may not be good decisions for loss features since they may not be differentiable.
Within the following, let’s discover some widespread loss features, specifically, the imply absolute error, imply squared error, and categorical cross entropy.
Imply Absolute Error
The imply absolute error (MAE) measures absolutely the distinction between predicted values and the bottom reality labels and takes the imply of the distinction throughout all coaching examples. Mathematically, it is the same as $frac{1}{m}sum_{i=1}^mlverthat{y}_i–y_irvert$ the place $m$ is the variety of coaching examples, $y_i$ and $hat{y}_i$ are the bottom reality and predicted values respectively, and we’re averaging over all coaching examples. The MAE is rarely destructive, however it will be zero provided that the prediction matched the bottom reality completely. It’s an intuitive loss perform and may additionally be used as considered one of our metrics, specifically for regression issues since we might wish to decrease the error in our predictions.
Let’s have a look at what the imply absolute error loss perform appears like graphically:
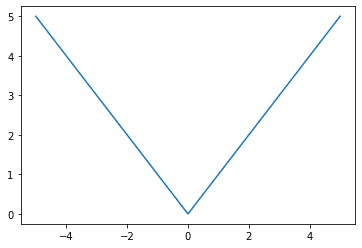
Imply absolute error loss perform, floor reality at x = 0 and x-axis characterize the anticipated worth
Just like activation features, we’re often additionally inquisitive about what the gradient of the loss perform appears like since we’re utilizing the gradient afterward to do backpropagation to coach our mannequin’s parameters.
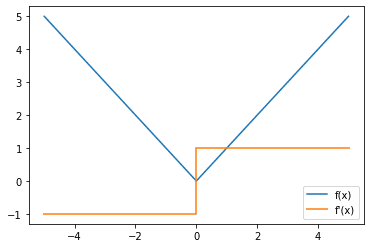
Imply absolute error loss perform (blue) and gradient (orange)
We discover that there’s a discontinuity within the gradient perform for the imply absolute loss perform however we are inclined to ignore it because it happens solely at x = 0 which in apply not often occurs since it’s the chance of a single level in a steady distribution.
Let’s check out implement this loss perform in TensorFlow utilizing the the Keras losses module:
|
import tensorflow as tf from tensorflow.keras.losses import MeanAbsoluteError
y_true = [1., 0.] y_pred = [2., 3.]
mae_loss = MeanAbsoluteError()
print(mae_loss(y_true, y_pred).numpy()) |
which provides us 2.0 because the output as anticipated, since $ frac{1}{2}(lvert 2-1rvert + lvert 3-0rvert) = frac{1}{2}(4) = 4 $. Subsequent, let’s discover one other loss perform for regression fashions with barely completely different properties, the imply squared error.
Imply Squared Error
One other common loss perform for regression fashions is the imply squared error (MSE), which is the same as $frac{1}{m}sum_{i=1}^m(hat{y}_i–y_i)^2$. It’s just like the imply absolute error because it additionally measures the deviation of the anticipated worth from the bottom reality worth. Nevertheless, the imply squared error squares this distinction (at all times non-negative since sq. of actual numbers are at all times non-negative), which provides it barely completely different properties.
One notable one is that the imply squared error favors numerous small errors over a small variety of giant errors, which results in fashions which have much less outliers or not less than outliers which might be much less extreme than fashions skilled with a imply absolute error. It’s because a big error would have a considerably bigger affect on the error, and consequently the gradient of the error, when in comparison with a small error.
Graphically,
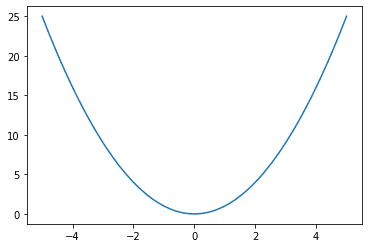
Imply squared error loss perform, floor reality at x = 0 and x-axis characterize the anticipated worth
Then, trying on the gradient,

Imply squared error loss perform (blue) and gradient (orange)
Discover that bigger errors would result in a bigger magnitude for the gradient and likewise a bigger loss. Therefore, for instance, two coaching examples that deviate from their floor truths by 1 unit would result in a lack of 2, whereas a single coaching instance that deviates from its floor reality by 2 items would result in a lack of 4, therefore having a bigger affect.
Let’s have a look at implement the imply squared loss in TensorFlow.
|
import tensorflow as tf from tensorflow.keras.losses import MeanSquaredError
y_true = [1., 0.] y_pred = [2., 3.]
mse_loss = MeanSquaredError()
print(mse_loss(y_true, y_pred).numpy()) |
which provides the output 5.0 as anticipated since $frac{1}{2}[(2-1)^2 + (3-0)^2] = frac{1}{2}(10) = 5$. Discover that the second instance with a predicted worth of three and precise worth of 0 contributes 90% of the error below the imply squared error vs 75% of the error below imply absolute error.
Typically, you may even see individuals use root imply squared error (RMSE) as a metric. That is to take the sq. root of MSE. From the angle of a loss perform, MSE and RMSE are equal.
Each MAE and MSE are measuring values in a steady vary. Therefore they’re for regression issues. For classification issues, we will use categorical cross-entropy.
Categorical Cross-entropy
The earlier two loss features are for regression fashions, the place the output may very well be any actual quantity. Nevertheless, for classification issues, there’s a small, discrete set of numbers that the output might take. Moreover, the quantity that we use to label-encode the lessons are arbitrary, and with no semantic that means (e.g. if we used the labels 0 for cat, 1 for canine, and a pair of for horse, it doesn’t characterize {that a} canine is half cat and half horse). Due to this fact it shouldn’t have an effect on the efficiency of the mannequin.
In a classification downside, the mannequin’s output is a vector of chance for every class. In Keras fashions, often we anticipate this vector to be “logits”, i.e., actual numbers to be reworked to chance utilizing softmax perform, or the output of a softmax activation perform.
The cross-entropy between two chance distributions is a measure of the distinction between the 2 chance distributions. Exactly, it’s $-sum_i P(X = x_i) log Q(X = x_i)$ for chance $P$ and $Q$. In machine studying, we often have the chance $P$ offered by the coaching knowledge and $Q$ predicted by the mannequin, which $P$ is 1 for the proper class and 0 for each different class. The anticipated chance $Q$, nevertheless, is often valued between 0 and 1. Therefore when used for classification issues in machine studying, this formulation might be simplified into: $$textual content{categorical cross entropy} = – log p_{gt}$$ the place $p_{gt}$ is the model-predicted chance of the bottom reality class for that exact pattern.
Cross-entropy metric have a destructive signal as a result of $log(x)$ tends to destructive infinity as $x$ tends to zero. We wish a better loss when the chance approaches 0 and a decrease loss when the chance approaches 1. Graphically,
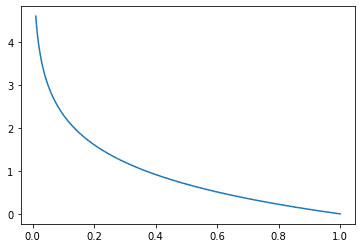
Categorical cross entropy loss perform, the place x is the anticipated chance of the bottom reality class
Discover that the loss is precisely 0 if the chance of the bottom reality class is 1 as desired. Additionally, because the chance of the bottom reality class tends to 0, the loss tends to optimistic infinity as properly, therefore considerably penalizing unhealthy predictions. You would possibly acknowledge this loss perform for logistic regression, and they’re related besides the logistic regression loss is restricted to the case of binary lessons.
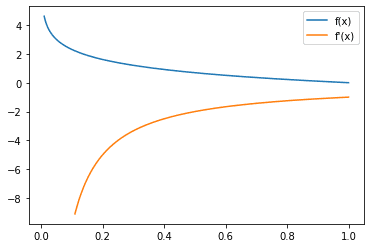
Categorical cross entropy loss perform (blue) and gradient (orange)
Now, trying on the gradient of the cross entropy loss,
Trying on the gradient, we will see that the gradient is usually destructive which can also be anticipated since to lower this loss, we might need the chance on the bottom reality class to be as excessive as attainable, and recall that gradient descent goes in the wrong way of the gradient.
There are two alternative ways to implement categorical cross entropy in TensorFlow. The primary methodology takes in one-hot vectors as enter,
|
import tensorflow as tf from tensorflow.keras.losses import CategoricalCrossentropy
# utilizing one sizzling vector illustration y_true = [[0, 1, 0], [1, 0, 0]] y_pred = [[0.15, 0.75, 0.1], [0.75, 0.15, 0.1]]
cross_entropy_loss = CategoricalCrossentropy()
print(cross_entropy_loss(y_true, y_pred).numpy()) |
This provides the output as 0.2876821 which is the same as $-log(0.75)$ as anticipated. The opposite method of implementing the explicit cross entropy loss in TensorFlow is utilizing a label-encoded illustration for the category, the place the category is represented by a single non-negative integer indicating the bottom reality class as an alternative.
|
import tensorflow as tf from tensorflow.keras.losses import SparseCategoricalCrossentropy
y_true = [1, 0] y_pred = [[0.15, 0.75, 0.1], [0.75, 0.15, 0.1]]
cross_entropy_loss = SparseCategoricalCrossentropy()
print(cross_entropy_loss(y_true, y_pred).numpy()) |
which likewise offers the output 0.2876821.
Now that we’ve explored loss features for each regression and classification fashions, let’s check out how we use loss features in our machine studying fashions.
Loss Features in Follow
Let’s discover how we will use loss features in apply. We’ll discover this by a easy dense mannequin on the MNIST digit classification dataset.
First, we get the obtain the info from Keras datasets module,
|
import tensorflow.keras as keras
(trainX, trainY), (testX, testY) = keras.datasets.mnist.load_data() |
Then, we construct our mannequin,
|
from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense, Enter, Flatten
mannequin = Sequential([ Input(shape=(28,28,1,)), Flatten(), Dense(units=84, activation=“relu”), Dense(units=10, activation=“softmax”), ])
print (mannequin.abstract()) |
And we have a look at the mannequin structure outputted from the above code,
|
_________________________________________________________________ Layer (kind) Output Form Param # ================================================================= flatten_1 (Flatten) (None, 784) 0
dense_2 (Dense) (None, 84) 65940
dense_3 (Dense) (None, 10) 850
================================================================= Whole params: 66,790 Trainable params: 66,790 Non-trainable params: 0 _________________________________________________________________ |
We are able to then compile our mannequin, which can also be the place we introduce the loss perform. Since it is a classification downside, we’ll use the cross entropy loss. Particularly, because the MNIST dataset in Keras datasets is represented as a label as an alternative of an one-hot vector, we’ll use the SparseCategoricalCrossEntropy loss.
|
mannequin.compile(optimizer=“adam”, loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=“acc”) |
And eventually, we practice our mannequin.
|
historical past = mannequin.match(x=trainX, y=trainY, batch_size=256, epochs=10, validation_data=(testX, testY)) |
And our mannequin efficiently trains with the next output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Epoch 1/10 235/235 [==============================] – 2s 6ms/step – loss: 7.8607 – acc: 0.8184 – val_loss: 1.7445 – val_acc: 0.8789 Epoch 2/10 235/235 [==============================] – 1s 6ms/step – loss: 1.1011 – acc: 0.8854 – val_loss: 0.9082 – val_acc: 0.8821 Epoch 3/10 235/235 [==============================] – 1s 6ms/step – loss: 0.5729 – acc: 0.8998 – val_loss: 0.6689 – val_acc: 0.8927 Epoch 4/10 235/235 [==============================] – 1s 5ms/step – loss: 0.3911 – acc: 0.9203 – val_loss: 0.5406 – val_acc: 0.9097 Epoch 5/10 235/235 [==============================] – 1s 6ms/step – loss: 0.3016 – acc: 0.9306 – val_loss: 0.5024 – val_acc: 0.9182 Epoch 6/10 235/235 [==============================] – 1s 6ms/step – loss: 0.2443 – acc: 0.9405 – val_loss: 0.4571 – val_acc: 0.9242 Epoch 7/10 235/235 [==============================] – 1s 5ms/step – loss: 0.2076 – acc: 0.9469 – val_loss: 0.4173 – val_acc: 0.9282 Epoch 8/10 235/235 [==============================] – 1s 5ms/step – loss: 0.1852 – acc: 0.9514 – val_loss: 0.4335 – val_acc: 0.9287 Epoch 9/10 235/235 [==============================] – 1s 6ms/step – loss: 0.1576 – acc: 0.9577 – val_loss: 0.4217 – val_acc: 0.9342 Epoch 10/10 235/235 [==============================] – 1s 5ms/step – loss: 0.1455 – acc: 0.9597 – val_loss: 0.4151 – val_acc: 0.9344 |
And that’s one instance of use a loss perform in a TensorFlow mannequin.
Additional Studying
Under are the documentation of the loss features from TensorFlow/Keras:
Conclusion
On this put up, you will have seen loss features and the function that they play in a neural community. You have got additionally seen some common loss features utilized in regression and classification fashions, in addition to use the cross entropy loss perform in a TensorFlow mannequin.
Particularly, you realized:
- What are loss features and the way they’re completely different from metrics
- Frequent loss features for regression and classification issues
- Easy methods to use loss features in your TensorFlow mannequin
Develop Deep Studying Tasks with Python!

What If You May Develop A Community in Minutes
…with just some strains of Python
Uncover how in my new Book:
Deep Studying With Python
It covers end-to-end tasks on matters like:
Multilayer Perceptrons, Convolutional Nets and Recurrent Neural Nets, and extra…
Lastly Carry Deep Studying To
Your Personal Tasks
Skip the Lecturers. Simply Outcomes.
[ad_2]