

{kind=link}
[ad_1]
AWS IoT Analytics is a completely managed service that you need to use to question and generate insights about your IoT information. You would possibly wish to use AWS IoT Analytics on information that’s not being despatched to the AWS IoT Core message dealer. Through the use of the AWS IoT Analytics BatchPutMessage API, you’ll be able to ingest information immediately into AWS IoT Analytics from different information sources. This weblog put up demonstrates how one can use the BatchPutMessage API to add information saved in Amazon S3 to AWS IoT Analytics. We’ll first stroll by some easy command-line examples. Then we’ll see how one can use AWS Lambda and Amazon Kinesis to ingest information recordsdata in an S3 bucket.
To observe alongside, you’ll want to put in the AWS CLI. Word that you could be want to put in the AWS CLI by way of pip3 as an alternative of pip to set up an up-to-date consumer that helps iotanalytics. Additionally, the steps on this put up have been written utilizing bash on macOS. In the event you use a distinct command-line interface, akin to Home windows PowerShell, you’ll want to regulate the instructions accordingly.
Earlier than we start, listed below are some essential AWS IoT Analytics ideas:
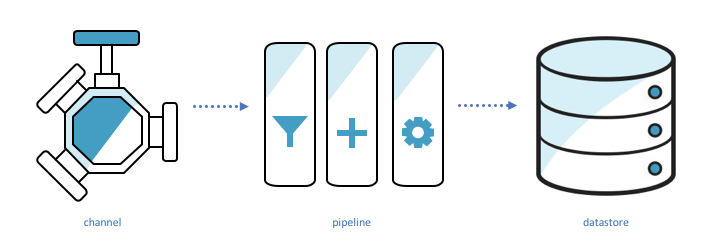
Channels ingest information, again it up, and publish it to a number of pipelines.
Pipelines ingest information from a channel and will let you course of the information by actions earlier than storing it in a knowledge retailer.
Knowledge shops retailer information. They’re scalable and queryable.
Datasets retrieve information from a datastore. They’re the results of some SQL question run in opposition to the information retailer.
Let’s stroll by a easy instance that demonstrates these ideas in motion. We’ll create a channel, pipeline, information retailer, and dataset. Then we’ll ship information to AWS IoT Analytics by BatchPutMessage and question for that information in our dataset.
Arrange AWS IoT Analytics
First, we’ll create the information retailer and channel.
aws iotanalytics create-datastore --datastore-name bpm_blog_datastore
aws iotanalytics create-channel --channel-name bpm_blog_channelTo create the pipeline, we’ll specify the pipeline configuration in a JSON file and move the file to the create-pipeline command.
Our pipeline might be quite simple as a result of we aren’t processing the information in any method. We’re simply ingesting the information from a channel and passing it to an information retailer. (That is the “Sink” exercise.) Save this JSON to a file named pipeline_config.json.
{
"pipelineName":"bpm_blog_pipeline",
"pipelineActivities":[
{
"channel":{
"name":"Source",
"channelName":"bpm_blog_channel",
"next":"Sink"
}
},
{
"datastore":{
"name":"Sink",
"datastoreName":"bpm_blog_datastore"
}
}
]
}Now move pipeline_config.json to create-pipeline.
aws iotanalytics create-pipeline --cli-input-json file://pipeline_config.jsonShip BatchPutMessage
Now we’ll use the CLI to ship our BatchPutMessage request. On this instance, we’ll specify some temperature information. Save the next to a file named batchPutMessage.json. It accommodates the 2 issues a BatchPutMessage request requires: the title of the channel the place we’re sending messages and a number of messages. A message accommodates the information we’re importing and an ID that identifies the message. The messageId should be distinctive relative to the opposite messages within the BatchPutMessage request. The “batch” in BatchPutMessage is the power to ship a number of messages at a time, as much as 1,000 complete messages per second per account.
{
"channelName":"bpm_blog_channel",
"messages":[
{
"messageId":"1",
"payload":"{"temp": 10}"
},
{
"messageId":"2",
"payload":"{"temp": 50}"
}
]
}Ship the BatchPutMessage request.
aws iotanalytics batch-put-message --cli-input-json file://batchPutMessage.jsonIf the command is profitable, the CLI will return the next response:
{
"batchPutMessageErrorEntries": []
}Question information
We will now question the information again from our information retailer. First, we’ll create a dataset that represents the output of a “choose temp from bpm_blog_datastore” question. Save the next JSON to a file named dataset_config.json.
{
"datasetName":"bpm_blog_dataset",
"actions":[
{
"actionName":"bpm_blog_action",
"queryAction":{
"sqlQuery":"select temp from bpm_blog_datastore"
}
}
]
}Now move the JSON file as enter to the create-dataset command.
aws iotanalytics create-dataset --cli-input-json file://dataset_config.jsonCreating the dataset won’t execute our question. We have to run create-dataset-content.
aws iotanalytics create-dataset-content --dataset-name bpm_blog_datasetFetch the question outcome with the get-dataset-content command. If the standing is “CREATING,” the question has not completed executing. Wait a second and check out once more.
aws iotanalytics get-dataset-content --dataset-name bpm_blog_dataset --version-id '$LATEST'After the question has been executed, the response will include a hyperlink. Visiting that hyperlink in our browser will obtain the results of our question.
{
"timestamp":1524498869.019,
"standing": {
"state": "SUCCEEDED"
},
"entries":[
{
"dataURI":"https://aws-iot-analytics-dataset-12dbc22a-96d6-466a-abff-e8239c32bfb2.s3.amazonaws.com/results/924a1629-ebb3-4b51-8ea4-715612aa6786.csv?X-Amz-Security-Token=ABCDEFG&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20180423T155542Z&X-Amz-SignedHeaders=host&X-Amz-Expires=7200&X-Amz-Credential=1234457689us-east-1%2Fs3%2Faws4_request&X-Amz-Signature=XXXX"
}
]
}For the needs of this weblog put up, we now have generated and uploaded some information, in .csv format, to the aws-iot-blog-assets bucket. The info is split into 5 folders, every with 20 recordsdata. The next is a JSON illustration of 1 datapoint in example_data_part_2.csv.
{
"deviceid":2,
"humidity":51,
"location":"B",
"rowid":575,
"temp":63,
"timestamp":"2018-04-18 19:04:35"
}Launch information ingestion template
We’ll ingest the information saved within the S3 bucket into AWS IoT Analytics through the use of two Lambda features and a Kinesis stream. One Lambda operate, “the launcher”, will iterate by our bucket and add every key to the stream. For every key ingested by the stream, a replica of the second Lambda operate might be invoked. That second Lambda operate, “the employee”, will obtain the information positioned at that S3 key and ship BatchPutMessage requests containing the information. If it encounters an error whereas doing so, will probably be invoked once more.
Deployment packages include the code for the Lambda features. We use deployment packages as a result of they permit us to add dependencies together with the the code. The operate definitions are displayed beneath.
Launcher Lambda:
import boto3
import json
from ratelimiter import RateLimiter
from break up import chop
MAX_RECORDS_PER_REQUEST = 500
MAX_REQUESTS_PER_SECOND = 2
def lambda_handler(occasion, context):
bucket = occasion["bucket"]
channel_name = occasion["channel_name"]
stream_name = occasion["stream_name"]
s3_client = boto3.consumer("s3")
kinesis_client = boto3.consumer("kinesis")
total_jobs = 0
paginator = s3_client.get_paginator("list_objects_v2")
page_iterator = paginator.paginate(Bucket=bucket, Prefix="IngestingDatafromS3byUsingBatchPutMessageAWSLambdaAmazonKinesis/information/")
for web page in page_iterator:
jobs = [{"key": object["Key"], "channel_name": channel_name, "bucket": bucket}
for object in web page["Contents"]]
for request_jobs in chop(MAX_RECORDS_PER_REQUEST, jobs):
data = [{"Data": json.dumps(request_job), "PartitionKey": request_job["key"]} for request_job in request_jobs]
put_records(kinesis_client, stream_name, data)
total_jobs += len(jobs)
return "{} keys despatched into {}".format(total_jobs, stream_name)
# 1 kinesis shard can ingest at most 1000 data per second
# we ratelimit to make sure we don't go over that price
@RateLimiter(max_calls= MAX_REQUESTS_PER_SECOND, interval=1)
def put_records(kinesis_client, stream_name, data):
kinesis_client.put_records(StreamName=stream_name, Information=data)Employee Lambda:
import base64
# as of 5/11/18, the model of boto3 utilized by lambda doesn't help iotanalytics
# so we included the most recent model of boto3 within the deployment package deal
import boto3
import csv
import json
from io import StringIO
from ratelimiter import RateLimiter
from break up import chop
MESSAGES_PER_REQUEST = 100
MAX_REQUESTS_PER_SECOND = 10
def lambda_handler(occasion, context):
# we'll solely recieve 1 occasion as a result of the set off BatchSize is 1 (set by way of the CloudFormation template)
document = occasion["Records"][0]
job_input = json.hundreds(base64.b64decode(document["kinesis"]["data"]))
key = job_input["key"]
bucket = job_input["bucket"]
channel_name = job_input["channel_name"]
print("Job Enter - Key: {} Bucket: {} Channel Identify: {}".format(key, bucket, channel_name))
s3_client = boto3.consumer("s3")
file_contents = s3_client.get_object(Bucket=bucket, Key=key)["Body"].learn().decode("utf-8")
serialized_rows = serialize_rows(file_contents)
messages = generate_messages(serialized_rows)
num_requests = 0
iot_analytics_client = boto3.consumer("iotanalytics")
for messages_batch in chop(MESSAGES_PER_REQUEST, messages):
send_batch_put_message(iot_analytics_client, channel_name, record(messages_batch))
num_requests += 1
return "{} batchPutMessage requests despatched for {}".format(num_requests, key)
# batchPutMessage can obtain at most 1000 messages per second per account
# so we ratelimit to make sure we don't ship greater than that
# when you allowed for concurrent employee invocations then you definitely would want to
# divide this worth by the max variety of concurrent staff
@RateLimiter(max_calls= MAX_REQUESTS_PER_SECOND, interval=1)
def send_batch_put_message(iot_analytics_client, channel_name, messages_batch):
iot_analytics_client.batch_put_message(channelName=channel_name, messages=messages_batch)
def serialize_rows(file_contents):
reader = csv.DictReader(StringIO(file_contents))
return (row for row in reader)
def generate_messages(serialized_rows):
for messageId, row in enumerate(serialized_rows):
yield {"payload": json.dumps(row), "messageId": str(messageId)}The next Launch Stack button goes to an AWS CloudFormation template that describes the Lambda features and Kinesis stream. It additionally describes IAM insurance policies and roles that let the Lambda features to do the next:
- Learn and record objects from S3 buckets.
- Ship information into the Kinesis stream.
- Be triggered by information ingestion into the Kinesis stream.
- Ship BatchPutMessage requests.
- Retailer logs.
Simply click on Launch Stack beneath to launch the template. The stack might be deployed to the us-east-1 area. You don’t want to specify values for the choices offered. As a substitute, select Subsequent 3 times. Then choose the I acknowledge that AWS CloudFormation would possibly create IAM assets test field and click on Create. You might need to refresh to see the brand new AWS CloudFormation stack.
![]()
When the companies have been fully arrange, the standing of the stack will change to CREATE_COMPLETE. Choose the stack after which select the Outputs tab. Word the names of the launcher Lambda operate and Kinesis stream.

Invoke the launcher Lambda operate with a payload that specifies the bucket it would iterate by, the title of the Kinesis stream it would ship the keys to, and the AWS IoT Analytics channel the information might be despatched to.
Save the payload to file known as lambdaPayload.json.
{
"stream_name":"EXAMPLE_KINESIS_STREAM",
"channel_name":"bpm_blog_channel",
"bucket":"aws-iot-blog-assets"
}Invoke the launcher Lambda operate.
aws lambda invoke --function-name EXAMPLE_FUNCTION_NAME --payload file://lambdaPayload.json --region us-east-1 --cli-binary-format raw-in-base64-out lambdaOutput.txtYou need to use the AWS Lambda console to observe the state of the Lambda features. Click on the Launcher operate after which select the Monitoring tab. From there, you’ll be able to, for instance, see a graph of the variety of invocations over time. It’s also possible to view hyperlinks to logs for every operate. You’ll know the information ingestion course of is full when the the employee has stopped being invoked. For the information utilized by this weblog, the method could take about quarter-hour.
Validating information
To validate the information ingested by AWS IoT Analytics, we will create datasets with queries we all know the right reply to. For instance, within the this dataset, we all know there have been two areas the place information was collected and 56,570 complete data. We will create a dataset that queries for these values.
Save the next to a file named validation_dataset_config.json.
{
"datasetName":"bpm_blog_validation_dataset",
"actions":[
{
"actionName":"bpm_blog_validation_action",
"queryAction":{
"sqlQuery":"SELECT count(DISTINCT location), count(DISTINCT rowid) from bpm_blog_datastore"
}
}
]
}Execute the next instructions to confirm that they report the anticipated results of 2 and 56570.
aws iotanalytics create-dataset --cli-input-json file://validation_dataset_config.json
aws iotanalytics create-dataset-content --dataset-name bpm_blog_validation_dataset
aws iotanalytics get-dataset-content --dataset-name bpm_blog_validation_dataset --version-id '$LATEST'We will additionally question for the information at a selected row. Save the next to validation_dataset_config2.json
{
"datasetName":"bpm_blog_validation_dataset2",
"actions":[
{
"actionName":"bpm_blog_validation_action2",
"queryAction":{
"sqlQuery":"select * from bpm_blog_datastore where rowid='575'"
}
}
]
}Then execute these instructions.
aws iotanalytics create-dataset --cli-input-json file://validation_dataset_config2.json
aws iotanalytics create-dataset-content --dataset-name bpm_blog_validation_dataset2
aws iotanalytics get-dataset-content --dataset-name bpm_blog_validation_dataset2 --version-id '$LATEST'The outcome ought to correspond to the row with the chosen rowid from the 1/example_data_part_2.csv excerpt proven right here.

Notes about this strategy and its alternate options
The method described on this put up just isn’t idempotent. That’s, when you run both Lambda operate with the identical enter a number of occasions, your information retailer won’t be in the identical finish state every time. A number of BatchPutMessage requests can be despatched for every row within the .csv file. As a result of information shops don’t impose uniqueness constraints on keys, a number of copies of the information for every key can be saved within the information retailer. Idempotency is related even when you don’t intend to rerun a Lambda a number of occasions with the identical enter as a result of it’s attainable for the Lambda operate to fail and be invoked once more.
Nonetheless, writing duplicate information to our information retailer is ok so long as we filter it out once we create our dataset. We will simply specify that we wish distinct outcomes and embrace the rowid key as one of many chosen objects. Consequently, every row from every .csv file can be included solely as soon as. For instance, a question counting complete data would seem like this:
SELECT depend(DISTINCT rowid) from DATASTORE_NAMEYou might scale back duplicate key processing by storing the already processed keys in a database and checking the database earlier than processing a key. That might end in much less house utilization for the information shops, quicker dataset creation, and presumably quicker runtime.
This strategy will run one employee Lambda operate at a time. You might enhance the processing pace by permitting the employee Lambda features to run concurrently. To try this you would want to extend the variety of shards utilized by the Kinesis stream as a result of you’ll be able to solely invoke one Lambda operate at a time per shard. You might enhance the variety of shards by enhancing the ShardCount worth outlined within the AWS CloudFormation template. You’ll additionally want to extend the variety of most allowed concurrent invocations. It’s set by the ReservedConcurrentExecutions worth within the AWS CloudFormation template. Lastly, you would want to divide the MAX_REQUESTS_PER_SECOND worth within the employee Lambda operate by the worth you assigned to ReservedConcurrentExecutions.
To launch an altered model of the AWS CloudFormation template, you would want to obtain it, make your changes, go to the CloudFormation Console, click on Create Stack, click on Select File, and specify your native copy of the template. To alter one of many AWS Lambda features, you would want to add a Deployment package deal containing your required code to a public Amazon S3 folder. You’ll then want to vary the S3Bucket and S3Key values within the template to level to that deployment package deal.
Lambda features execute for at most 5 minutes. If that weren’t sufficient time to iterate by all the keys within the bucket, then this strategy wouldn’t add information for the unvisited keys. Nonetheless, you can run the launcher code on an area machine. You might additionally invoke the launcher Lambda operate a number of occasions concurrently on totally different folders within the bucket. These invocations could possibly be created by a 3rd Lambda operate. Alternatively, you can restart the launcher Lambda operate by AWS Step Features till it had iterated by all the keys.
Lastly, Lambda features have a disk capability of 512 MB and at most 3 GB of reminiscence, so this strategy won’t work to be used circumstances that require processing massive recordsdata.
In the event you can not work inside these limitations, then you need to use AWS Glue, an ETL service that runs in a managed setting. You would want to edit the script it generated to have it ship BatchPutMessage requests.
Conclusion
AWS IoT Analytics lets you enrich and question IoT information. Through the use of the BatchPutMessage API, you’ll be able to ingest IoT information into AWS IoT Analytics with out first ingesting the information into AWS IoT Core. The template supplied on this weblog put up submits BatchPutMessage requests for information saved in S3 through the use of two AWS Lambda features and an Amazon Kinesis stream. You’ll be able to validate the ingested information by querying the information by dataset creation. Please learn the AWS IoT Analytics Person Information or different weblog posts for extra details about AWS IoT Analytics.
[ad_2]