
{kind=link}
[ad_1]
Reinforcement studying (RL) is an space of machine studying that focuses on studying from experiences to unravel determination making duties. Whereas the sector of RL has made nice progress, leading to spectacular empirical outcomes on advanced duties, similar to enjoying video video games, flying stratospheric balloons and designing {hardware} chips, it’s turning into more and more obvious that the present requirements for empirical analysis may give a false sense of quick scientific progress whereas slowing it down.
To that finish, in “Deep RL on the Fringe of the Statistical Precipice”, accepted as an oral presentation at NeurIPS 2021, we focus on how statistical uncertainty of outcomes must be thought-about, particularly when utilizing just a few coaching runs, to ensure that analysis in deep RL to be dependable. Particularly, the predominant observe of reporting level estimates ignores this uncertainty and hinders reproducibility of outcomes. Associated to this, tables with per-task scores, as are generally reported, could be overwhelming past just a few duties and infrequently omit commonplace deviations. Moreover, easy efficiency metrics just like the imply could be dominated by just a few outlier duties, whereas the median rating would stay unaffected even when as much as half of the duties had efficiency scores of zero. Thus, to extend the sector’s confidence in reported outcomes with a handful of runs, we suggest numerous statistical instruments, together with stratified bootstrap confidence intervals, efficiency profiles, and higher metrics, similar to interquartile imply and chance of enchancment. To assist researchers incorporate these instruments, we additionally launch an easy-to-use Python library RLiable with a quickstart colab.
Statistical Uncertainty in RL Analysis
Empirical analysis in RL depends on evaluating efficiency on a various suite of duties, similar to Atari 2600 video video games, to evaluate progress. Printed outcomes on deep RL benchmarks usually evaluate level estimates of the imply and median scores aggregated throughout duties. These scores are usually relative to some outlined baseline and optimum efficiency (e.g., random agent and “common” human efficiency on Atari video games, respectively) in order to make scores comparable throughout totally different duties.
In most RL experiments, there’s randomness within the scores obtained from totally different coaching runs, so reporting solely level estimates doesn’t reveal whether or not related outcomes could be obtained with new impartial runs. A small variety of coaching runs, coupled with the excessive variability in efficiency of deep RL algorithms, typically results in giant statistical uncertainty in such level estimates.
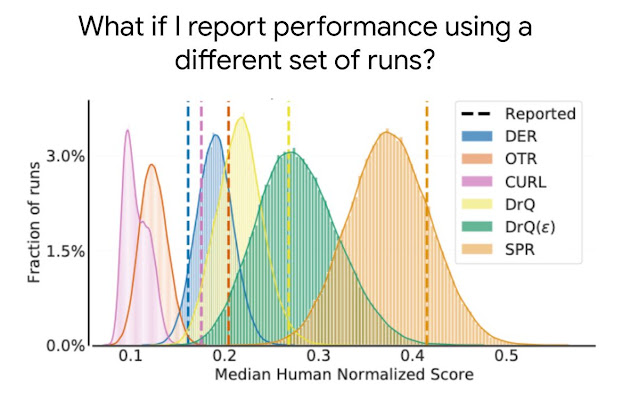 |
| The distribution of median human normalized scores on the Atari 100k benchmark, which accommodates 26 video games, for 5 just lately printed algorithms, DER, OTR, CURL, two variants of DrQ, and SPR. The reported level estimates of median scores primarily based on just a few runs in publications, as proven by dashed strains, don’t present details about the variability in median scores and usually overestimate (e.g., CURL, SPR, DrQ) or underestimate (e.g., DER) the anticipated median, which may end up in inaccurate conclusions. |
As benchmarks change into more and more extra advanced, evaluating various runs can be more and more demanding because of the elevated compute and information wanted to unravel such duties. For instance, 5 runs on 50 Atari video games for 200 million frames takes 1000+ GPU days. Thus, evaluating extra runs just isn’t a possible answer for decreasing statistical uncertainty on computationally demanding benchmarks. Whereas prior work has really helpful statistical significance assessments as an answer, such assessments are dichotomous in nature (both “important” or “not important”), so that they typically lack the granularity wanted to yield significant insights and are broadly misinterpreted.
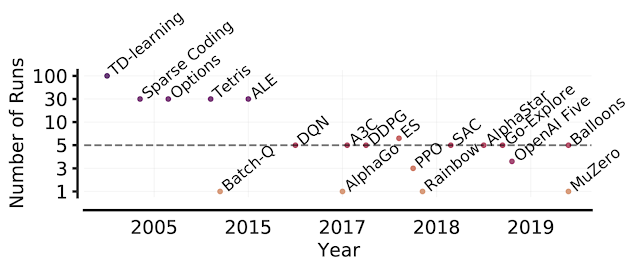 |
| Variety of runs in RL papers over time. Starting with the Arcade Studying Surroundings (ALE), the shift towards computationally-demanding benchmarks has led to the observe of evaluating solely a handful of runs per process, growing the statistical uncertainty in level estimates. |
Instruments for Dependable Analysis
Any mixture metric primarily based on a finite variety of runs is a random variable, so to take this under consideration, we advocate for reporting stratified bootstrap confidence intervals (CIs), which predict the possible values of mixture metrics if the identical experiment have been repeated with totally different runs. These CIs enable us to know the statistical uncertainty and reproducibility of outcomes. Such CIs use the scores on mixed runs throughout duties. For instance, evaluating 3 runs every on Atari 100k, which accommodates 26 duties, ends in 78 pattern scores for uncertainty estimation.
 |
| In every process, coloured balls denote scores on totally different runs. To compute statified bootstrap CIs utilizing the percentile methodology, bootstrap samples are created by randomly sampling scores with alternative proportionately from every process. Then, the distribution of mixture scores on these samples is the bootstrapping distribution, whose unfold across the middle provides us the boldness interval. |
Most deep RL algorithms typically carry out higher on some duties and coaching runs, however mixture efficiency metrics can conceal this variability, as proven beneath.
As a substitute, we advocate efficiency profiles, that are usually used for evaluating resolve occasions of optimization software program. These profiles plot the rating distribution throughout all runs and duties with uncertainty estimates utilizing stratified bootstrap confidence bands. These plots present the full runs throughout all duties that get hold of a rating above a threshold (𝝉) as a perform of the edge.
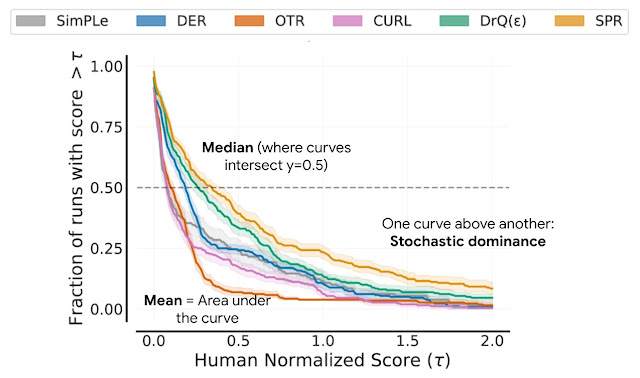 |
| Efficiency profiles correspond to the empirical tail distribution of scores on runs mixed throughout all duties. Shaded areas present 95% stratified bootstrap confidence bands. |
Such profiles enable for qualitative comparisons at a look. For instance, the curve for one algorithm above one other signifies that one algorithm is best than the opposite. We will additionally learn any rating percentile, e.g., the profiles intersect y = 0.5 (dotted line above) on the median rating. Moreover, the world underneath the profile corresponds to the imply rating.
Whereas efficiency profiles are helpful for qualitative comparisons, algorithms not often outperform different algorithms on all duties and thus their profiles typically intersect, so finer quantitative comparisons require mixture efficiency metrics. Nevertheless, present metrics have limitations: (1) a single excessive performing process could dominate the duty imply rating, whereas (2) the duty median is unaffected by zero scores on almost half of the duties and requires numerous coaching runs for small statistical uncertainty. To handle the above limitations, we advocate two options primarily based on sturdy statistics: the interquartile imply (IQM) and the optimality hole, each of which could be learn as areas underneath the efficiency profile, beneath.
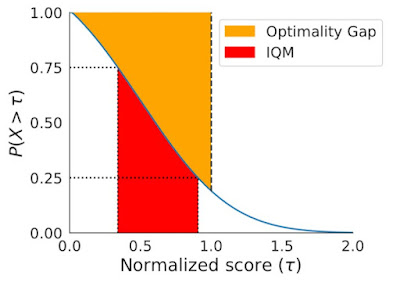 |
| IQM (pink) corresponds to the world underneath the efficiency profile, proven in blue, between the 25 and 75 percentile scores on the x-axis. Optimality hole (yellow) corresponds to the world between the profile and horizontal line at y = 1 (human efficiency), for scores lower than 1. |
As an alternative choice to median and imply, IQM corresponds to the imply rating of the center 50% of the runs mixed throughout all duties. It’s extra sturdy to outliers than imply, a greater indicator of total efficiency than median, and ends in smaller CIs, and so, requires fewer runs to say enhancements. One other various to imply, optimality hole measures how far an algorithm is from optimum efficiency.
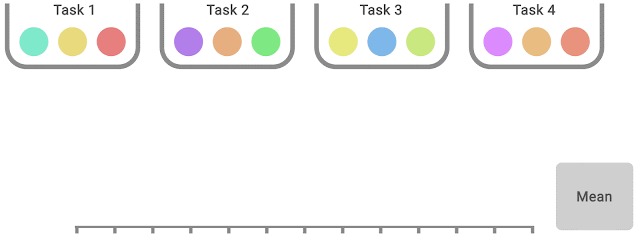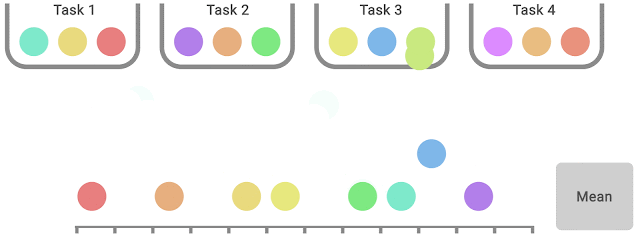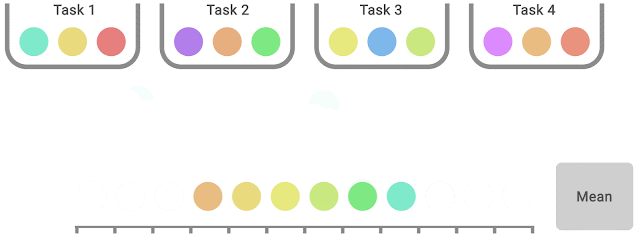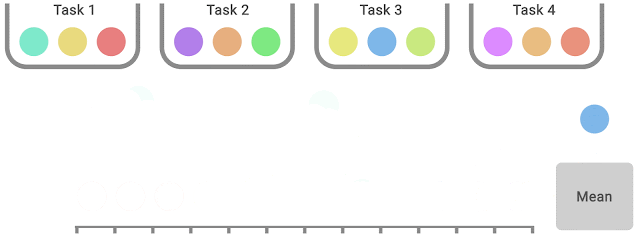 |
| IQM discards the bottom 25% and highest 25% of the mixed scores (coloured balls) and computes the imply of the remaining 50% scores. |
For immediately evaluating two algorithms, one other metric to think about is the common chance of enchancment, which describes how possible an enchancment over baseline is, no matter its measurement. This metric is computed utilizing the Mann-Whitney U-statistic, averaged throughout duties.
Re-evaluating Analysis
Utilizing the above instruments for analysis, we revisit efficiency evaluations of present algorithms on broadly used RL benchmarks, revealing inconsistencies in prior analysis. For instance, within the Arcade Studying Surroundings (ALE), a widely known RL benchmark, the efficiency rating of algorithms adjustments relying on the selection of mixture metric. Since efficiency profiles seize the complete image, they typically illustrate why such inconsistencies exist.
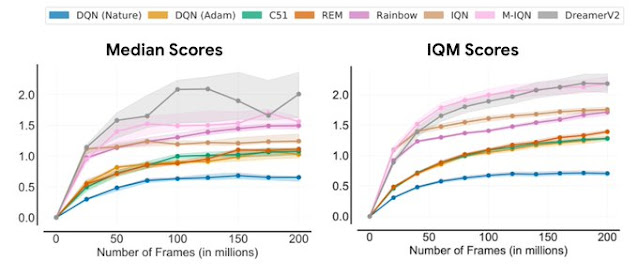 |
| Median (left) and IQM (proper) human normalized scores on the ALE as a perform of the variety of atmosphere frames seen throughout coaching. IQM ends in considerably smaller CIs than median scores. |
On DM Management, a well-liked steady management benchmark, there are giant overlaps in 95% CIs of imply normalized scores for many algorithms.
 |
| DM Management Suite outcomes, averaged throughout six duties, on the 100k and 500k step benchmark. Since scores are normalized utilizing most efficiency, imply scores correspond to at least one minus the optimality hole. The ordering of the algorithms is predicated on their claimed relative efficiency — all algorithms besides Dreamer claimed enchancment over no less than one algorithm positioned beneath them. Shaded areas present 95% CIs. |
Lastly, on Procgen, a benchmark for evaluating generalization in RL, the common chance of enchancment exhibits that some claimed enhancements are solely 50-70% possible, suggesting that some reported enhancements could possibly be spurious.
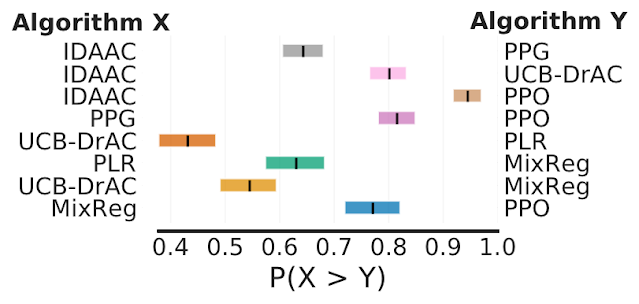 |
| Every row exhibits the chance that the algorithm X on the left outperforms algorithm Y on the appropriate, provided that X was claimed to be higher than Y. Shaded area denotes 95% stratified bootstrap CIs. |
Conclusion
Our findings on widely-used deep RL benchmarks present that statistical points can have a big affect on beforehand reported outcomes. On this work, we take a recent have a look at analysis to enhance the interpretation of reported outcomes and standardize experimental reporting. We’d like to emphasise the significance of printed papers offering outcomes for all runs to permit for future statistical analyses. To construct confidence in your outcomes, please take a look at our open-source library RLiable and the quickstart colab.
Acknowledgments
This work was accomplished in collaboration with Max Schwarzer, Aaron Courville and Marc G. Bellemare. We’d wish to thank Tom Small for an animated determine used on this put up. We’re additionally grateful for suggestions by a number of members of the Google Analysis, Mind Group and DeepMind.
[ad_2]